Purdue Online Writing Lab Purdue OWL® College of Liberal Arts

In-Text Citations: The Basics

Welcome to the Purdue OWL
This page is brought to you by the OWL at Purdue University. When printing this page, you must include the entire legal notice.
Copyright ©1995-2018 by The Writing Lab & The OWL at Purdue and Purdue University. All rights reserved. This material may not be published, reproduced, broadcast, rewritten, or redistributed without permission. Use of this site constitutes acceptance of our terms and conditions of fair use.
Note: This page reflects the latest version of the APA Publication Manual (i.e., APA 7), which released in October 2019. The equivalent resource for the older APA 6 style can be found here .
Reference citations in text are covered on pages 261-268 of the Publication Manual. What follows are some general guidelines for referring to the works of others in your essay.
Note: On pages 117-118, the Publication Manual suggests that authors of research papers should use the past tense or present perfect tense for signal phrases that occur in the literature review and procedure descriptions (for example, Jones (1998) found or Jones (1998) has found ...). Contexts other than traditionally-structured research writing may permit the simple present tense (for example, Jones (1998) finds ).
APA Citation Basics
When using APA format, follow the author-date method of in-text citation. This means that the author's last name and the year of publication for the source should appear in the text, like, for example, (Jones, 1998). One complete reference for each source should appear in the reference list at the end of the paper.
If you are referring to an idea from another work but NOT directly quoting the material, or making reference to an entire book, article or other work, you only have to make reference to the author and year of publication and not the page number in your in-text reference.
On the other hand, if you are directly quoting or borrowing from another work, you should include the page number at the end of the parenthetical citation. Use the abbreviation “p.” (for one page) or “pp.” (for multiple pages) before listing the page number(s). Use an en dash for page ranges. For example, you might write (Jones, 1998, p. 199) or (Jones, 1998, pp. 199–201). This information is reiterated below.
Regardless of how they are referenced, all sources that are cited in the text must appear in the reference list at the end of the paper.
In-text citation capitalization, quotes, and italics/underlining
- Always capitalize proper nouns, including author names and initials: D. Jones.
- If you refer to the title of a source within your paper, capitalize all words that are four letters long or greater within the title of a source: Permanence and Change . Exceptions apply to short words that are verbs, nouns, pronouns, adjectives, and adverbs: Writing New Media , There Is Nothing Left to Lose .
( Note: in your References list, only the first word of a title will be capitalized: Writing new media .)
- When capitalizing titles, capitalize both words in a hyphenated compound word: Natural-Born Cyborgs .
- Capitalize the first word after a dash or colon: "Defining Film Rhetoric: The Case of Hitchcock's Vertigo ."
- If the title of the work is italicized in your reference list, italicize it and use title case capitalization in the text: The Closing of the American Mind ; The Wizard of Oz ; Friends .
- If the title of the work is not italicized in your reference list, use double quotation marks and title case capitalization (even though the reference list uses sentence case): "Multimedia Narration: Constructing Possible Worlds;" "The One Where Chandler Can't Cry."
Short quotations
If you are directly quoting from a work, you will need to include the author, year of publication, and page number for the reference (preceded by "p." for a single page and “pp.” for a span of multiple pages, with the page numbers separated by an en dash).
You can introduce the quotation with a signal phrase that includes the author's last name followed by the date of publication in parentheses.
If you do not include the author’s name in the text of the sentence, place the author's last name, the year of publication, and the page number in parentheses after the quotation.
Long quotations
Place direct quotations that are 40 words or longer in a free-standing block of typewritten lines and omit quotation marks. Start the quotation on a new line, indented 1/2 inch from the left margin, i.e., in the same place you would begin a new paragraph. Type the entire quotation on the new margin, and indent the first line of any subsequent paragraph within the quotation 1/2 inch from the new margin. Maintain double-spacing throughout, but do not add an extra blank line before or after it. The parenthetical citation should come after the closing punctuation mark.
Because block quotation formatting is difficult for us to replicate in the OWL's content management system, we have simply provided a screenshot of a generic example below.

Formatting example for block quotations in APA 7 style.
Quotations from sources without pages
Direct quotations from sources that do not contain pages should not reference a page number. Instead, you may reference another logical identifying element: a paragraph, a chapter number, a section number, a table number, or something else. Older works (like religious texts) can also incorporate special location identifiers like verse numbers. In short: pick a substitute for page numbers that makes sense for your source.
Summary or paraphrase
If you are paraphrasing an idea from another work, you only have to make reference to the author and year of publication in your in-text reference and may omit the page numbers. APA guidelines, however, do encourage including a page range for a summary or paraphrase when it will help the reader find the information in a longer work.
Appropriate Level of Citation
The number of sources you cite in your paper depends on the purpose of your work. For most papers, cite one or two of the most representative sources for each key point. Literature review papers, however, typically include a more exhaustive list of references.
Provide appropriate credit to the source (e.g., by using an in-text citation) whenever you do the following:
- paraphrase (i.e., state in your own words) the ideas of others
- directly quote the words of others
- refer to data or data sets
- reprint or adapt a table or figure, even images from the internet that are free or licensed in the Creative Commons
- reprint a long text passage or commercially copyrighted test item
Avoid both undercitation and overcitation. Undercitation can lead to plagiarism and/or self-plagiarism . Overcitation can be distracting and is unnecessary.
For example, it is considered overcitation to repeat the same citation in every sentence when the source and topic have not changed. Instead, when paraphrasing a key point in more than one sentence within a paragraph, cite the source in the first sentence in which it is relevant and do not repeat the citation in subsequent sentences as long as the source remains clear and unchanged.
Figure 8.1 in Chapter 8 of the Publication Manual provides an example of an appropriate level of citation.
Determining the appropriate level of citation is covered in the seventh edition APA Style manuals in the Publication Manual Section 8.1 and the Concise Guide Section 8.1
Related handouts
- In-Text Citation Checklist (PDF, 227KB)
- Six Steps to Proper Citation (PDF, 112KB)
From the APA Style blog

How to cite your own translations
If you translate a passage from one language into another on your own in your paper, your translation is considered a paraphrase, not a direct quotation.

Key takeaways from the Psi Chi webinar So You Need to Write a Literature Review
This blog post describes key tasks in writing an effective literature review and provides strategies for approaching those tasks.

How to cite a work with a nonrecoverable source
In most cases, nonrecoverable sources such as personal emails, nonarchived social media livestreams (or deleted and unarchived social media posts), classroom lectures, unrecorded webinars or presentations, and intranet sources should be cited only in the text as personal communications.

The “outdated sources” myth
The “outdated sources” myth is that sources must have been published recently, such as the last 5 to 10 years. There is no timeliness requirement in APA Style.

From COVID-19 to demands for social justice: Citing contemporary sources for current events
The guidance in the seventh edition of the Publication Manual makes the process of citing contemporary sources found online easier than ever before.

Citing classical and religious works
A classical or religious work is cited as either a book or a webpage, depending on what version of the source you are using. This post includes details and examples.
Academic Writer—APA’s essential teaching resource for higher education instructors
Academic Writer’s advanced authoring technology and digital learning tools allow students to take a hands-on approach to learning the scholarly research and writing process.

APA Style webinar on citing works in text
Attend the webinar, “Citing Works in Text Using Seventh Edition APA Style,” on July 14, 2020, to learn the keys to accurately and consistently citing sources in APA Style.

- Joyner Library
- Laupus Health Sciences Library
- Music Library
- Digital Collections
- Special Collections
- North Carolina Collection
- Teaching Resources
- The ScholarShip Institutional Repository
- Country Doctor Museum
APA Citation Style, 7th Edition: In-Text Citations & Paraphrasing
- APA 6/7 Comparison Guide
- New & Notable Changes
- Student Paper Layout
- Journal Article with One Author
- Journal Article with Two Authors
- Journal Article with Three or more Authors
- Help?! I can't find the DOI
- One Author/Editor
- Two Authors/Editors
- Chapter in a Book
- Electronic Books
- Social Media Posts
- YouTube or other streaming video
- Podcast or other audio works
- Infographic, Powerpoint, or other visual works
- Government Websites & Publications, & Gray Literature
- Legislative (US & State House & Senate) Bills
- StatPearls, UpToDate, DynaMedex
- Dissertations & Thesis
- Interviews & Emails
- Magazine Articles
- Newspaper Articles
- Datasets, Software, & Tests
- Posters & Conference Sessions
- Photographs, Tables, & PDF's
- Canvas Posts & Class Discussion Boards
- In-Text Citations & Paraphrasing
- References Page
- Free APA 7th edition Resources, Handouts, & Tutorials
When do I use in-text citations?
When should you add in-text citations in your paper .
There are several rules of thumb you can follow to make sure that you are citing your paper correctly in APA 7 format.
- Think of your paper broken up into paragraphs. When you start a paragraph, the first time you add a sentence that has been paraphrased from a reference -> that's when you need to add an in-text citation.
- Continue writing your paragraph, you do NOT need to add another in-text citation until: 1) You are paraphrasing from a NEW source, which means you need to cite NEW information OR 2) You need to cite a DIRECT quote, which includes a page number, paragraph number or Section title.
- Important to remember : You DO NOT need to add an in-text citation after EVERY sentence of your paragraph.

What do in-text citations look like?
In-text citation styles: .
| (Forbes, 2020) | Forbes (2020) stated... | |
| (Bennet & Miller, 2019) | Bennet and Miller (2019) concluded that... | |
| (Jones et al., 2020) | Jones et al. (2020) shared two different... | |
| (East Carolina University, 2020) | East Carolina University (2020) found... |
Let's look at these examples if they were written in text:
An example with 1 author:
Parenthetical citation: Following American Psychological Association (APA) style guidelines will help you to cultivate your own unique academic voice as an expert in your field (Forbes, 2020).
Narrative citation : Forbes (2020) shared that by following American Psychological Association (APA) guidelines, students would learn to find their own voice as experts in the field of nursing.
An example with 2 authors:
Parenthetical citation: Research on the use of progressive muscle relaxation for stress reduction has demonstrated the efficacy of the method (Bennett & Miller, 2019).
Narrative citation: As shared by Bennett and Miller (2019), research on the use of progressive muscle relaxation for stress reduction has demonstrated the efficacy of the method.
An example with 3 authors:
Parenthetical citation: Guided imagery has also been shown to reduce stress, length of hospital stay, and symptoms related to medical and psychological conditions (Jones et al., 2020).
Narrative citation: Jones et al. (2020) shared that guided imagery has also been shown to reduce stress, length of hospital stay, and symptoms related to medical and psychological conditions.
An example with a group/corporate author:
Parenthetical citation: Dr. Philip G. Rogers, senior vice president at the American Council on Education, was recently elected as the newest chancellor of the university (East Carolina University, 2020).
Narrative citation: Recently shared on the East Carolina University (2020) website, Dr. Philip G. Rogers, senior vice president at the American Council on Education, was elected as the newest chancellor.
Tips on Paraphrasing
Paraphrasing is recreating someone else's ideas into your own words & thoughts, without changing the original meaning (gahan, 2020). .
Here are some best practices when you are paraphrasing:
- How do I learn to paraphrase? IF you are thoroughly reading and researching articles or book chapters for a paper, you will start to take notes in your own words . Those notes are the beginning of paraphrased information.
- Read the original information, PUT IT AWAY, then rewrite the ideas in your own words . This is hard to do at first, it takes practice, but this is how you start to paraphrase.
- It's usually better to paraphrase, than to use too many direct quotes.
- When you start to paraphrase, cite your source.
- Make sure not to use language that is TOO close to the original, so that you are not committing plagiarism.
- Use theasaurus.com to help you come up with like/similar phrases if you are struggling.
- Paraphrasing (vs. using direct quotes) is important because it shows that YOU ACTUALLY UNDERSTAND the information you are reading.
- Paraphrasing ALLOWS YOUR VOICE to be prevalent in your writing.
- The best time to use direct quotes is when you need to give an exact definition, provide specific evidence, or if you need to use the original writer's terminology.
- BEST PRACTICE PER PARAGRAPH: On your 1st paraphrase of a source, CITE IT. There is no need to add another in-text citation until you use a different source, OR, until you use a direct quote.
References :
Gahan, C. (2020, October 15). How to paraphrase sources . Scribbr.com . https://tinyurl.com/y7ssxc6g
Citing Direct Quotes
When should i use a direct quote in my paper .
Direct quotes should only be used occasionally:
- When you need to share an exact definition
- When you want to provide specific evidence or information that cannot be paraphrased
- When you want to use the original writer's terminology
From: https://americanlibrariesmagazine.org/whaddyamean/
Definitions of direct quotes:
| , around the quote, are incorporated into the text of the paper. | (Shayden, 2016, p. 202) | |
| (by indenting 0.5" or 1 tab) beneath the text of the paragraph. | (Miller et al., 2016, p. 136) | |
| , therefore you need a different way to cite the information for a direct quote. There are two ways to do this: | (Jones, 2014, para. 4) (Scotts, 2019, Resources section) |
- Western Oregon University's APA Guidelines on Direct Quotes This is an excellent quick tutorial on how to format direct quotes in APA 7th edition. Bookmark this page for future reference!
Carrie Forbes, MLS

Chat with a Librarian

Chat with a librarian is available during Laupus Library's open hours .
Need to contact a specific librarian? Find your liaison.
Call us: 1-888-820-0522 (toll free)
252-744-2230
Text us: 252-303-2343
- << Previous: Canvas Posts & Class Discussion Boards
- Next: References Page >>
- Last Updated: Jan 12, 2024 10:05 AM
- URL: https://libguides.ecu.edu/APA7

APA Style (7th ed.)
- Cite: Why? When?
- Book, eBook, Dissertation
- Article or Report
- Business Sources
- Artificial Intelligence (AI) Tools
- In-Text Citation
- Format Your Paper
Learn why citing with APA matters
Watch the following video: .

How to cite in APA Style (7th edition)
(Looking for the old 6th edition guide?)
Most academic writing cites others' ideas and research, for several reasons:
- Sources that support your ideas give your paper authority and credibility
- Shows you have researched your topic thoroughly
- Crediting sources protects you from plagiarism
- A list of sources can be a useful record for further research
Different academic disciplines prefer different citation styles, most commonly APA and MLA styles.
Besides these styles, there are Chicago , Turabian , AAA , AP , and more. Only use the most current edition of the citation style.
Ask your instructors which citation style they want you to use for assignments.
Prefer an interactive, video-based tutorial? Click the image below:

More questions? Check out the authoritative source: APA style blog
When to cite.
To avoid plagiarism, provide a citation for ideas that are not your own:
- Direct quotation
- Paraphrasing of a quotation, passage, or idea
- Summary of another's idea or research
- Specific reference to a fact, figure, or phrase
You do not need to cite common knowledge (ex. George Washington was the first President of the United States) or proverbs unless you are using a direct quotation. When in doubt, cite your source.
- Next: Reference Examples >>
- Last Updated: Jun 17, 2024 12:51 PM
- URL: https://libguides.uww.edu/apa
University Library
Start your research.
- Research Process
- Find Background Info
- Find Sources through the Library
- Evaluate Your Info
- Cite Your Sources
- Evaluate, Write & Cite

- is the right thing to do to give credit to those who had the idea
- shows that you have read and understand what experts have had to say about your topic
- helps people find the sources that you used in case they want to read more about the topic
- provides evidence for your arguments
- is professional and standard practice for students and scholars
What is a Citation?
A citation identifies for the reader the original source for an idea, information, or image that is referred to in a work.
- In the body of a paper, the in-text citation acknowledges the source of information used.
- At the end of a paper, the citations are compiled on a References or Works Cited list. A basic citation includes the author, title, and publication information of the source.

From: Lemieux Library, University of Seattle
Why Should You Cite?
Quoting Are you quoting two or more consecutive words from a source? Then the original source should be cited and the words or phrase placed in quotes.
Paraphrasing If an idea or information comes from another source, even if you put it in your own words , you still need to credit the source. General vs. Unfamiliar Knowledge You do not need to cite material which is accepted common knowledge. If in doubt whether your information is common knowledge or not, cite it. Formats We usually think of books and articles. However, if you use material from web sites, films, music, graphs, tables, etc. you'll also need to cite these as well.
Plagiarism is presenting the words or ideas of someone else as your own without proper acknowledgment of the source. When you work on a research paper and use supporting material from works by others, it's okay to quote people and use their ideas, but you do need to correctly credit them. Even when you summarize or paraphrase information found in books, articles, or Web pages, you must acknowledge the original author.
Citation Style Help
Helpful links:
- MLA , Works Cited : A Quick Guide (a template of core elements)
- CSE (Council of Science Editors)
For additional writing resources specific to styles listed here visit the Purdue OWL Writing Lab
Citation and Bibliography Resources

- How to Write an Annotated Bibliography
- << Previous: Evaluate Your Info
- Next: Evaluate, Write & Cite >>

Creative Commons Attribution 3.0 License except where otherwise noted.

Land Acknowledgement
The land on which we gather is the unceded territory of the Awaswas-speaking Uypi Tribe. The Amah Mutsun Tribal Band, comprised of the descendants of indigenous people taken to missions Santa Cruz and San Juan Bautista during Spanish colonization of the Central Coast, is today working hard to restore traditional stewardship practices on these lands and heal from historical trauma.
The land acknowledgement used at UC Santa Cruz was developed in partnership with the Amah Mutsun Tribal Band Chairman and the Amah Mutsun Relearning Program at the UCSC Arboretum .
Home / Guides / Citation Guides / How to Cite Sources
How to Cite Sources
Here is a complete list for how to cite sources. Most of these guides present citation guidance and examples in MLA, APA, and Chicago.
If you’re looking for general information on MLA or APA citations , the EasyBib Writing Center was designed for you! It has articles on what’s needed in an MLA in-text citation , how to format an APA paper, what an MLA annotated bibliography is, making an MLA works cited page, and much more!
MLA Format Citation Examples
The Modern Language Association created the MLA Style, currently in its 9th edition, to provide researchers with guidelines for writing and documenting scholarly borrowings. Most often used in the humanities, MLA style (or MLA format ) has been adopted and used by numerous other disciplines, in multiple parts of the world.
MLA provides standard rules to follow so that most research papers are formatted in a similar manner. This makes it easier for readers to comprehend the information. The MLA in-text citation guidelines, MLA works cited standards, and MLA annotated bibliography instructions provide scholars with the information they need to properly cite sources in their research papers, articles, and assignments.
- Book Chapter
- Conference Paper
- Documentary
- Encyclopedia
- Google Images
- Kindle Book
- Memorial Inscription
- Museum Exhibit
- Painting or Artwork
- PowerPoint Presentation
- Sheet Music
- Thesis or Dissertation
- YouTube Video
APA Format Citation Examples
The American Psychological Association created the APA citation style in 1929 as a way to help psychologists, anthropologists, and even business managers establish one common way to cite sources and present content.
APA is used when citing sources for academic articles such as journals, and is intended to help readers better comprehend content, and to avoid language bias wherever possible. The APA style (or APA format ) is now in its 7th edition, and provides citation style guides for virtually any type of resource.
Chicago Style Citation Examples
The Chicago/Turabian style of citing sources is generally used when citing sources for humanities papers, and is best known for its requirement that writers place bibliographic citations at the bottom of a page (in Chicago-format footnotes ) or at the end of a paper (endnotes).
The Turabian and Chicago citation styles are almost identical, but the Turabian style is geared towards student published papers such as theses and dissertations, while the Chicago style provides guidelines for all types of publications. This is why you’ll commonly see Chicago style and Turabian style presented together. The Chicago Manual of Style is currently in its 17th edition, and Turabian’s A Manual for Writers of Research Papers, Theses, and Dissertations is in its 8th edition.
Citing Specific Sources or Events
- Declaration of Independence
- Gettysburg Address
- Martin Luther King Jr. Speech
- President Obama’s Farewell Address
- President Trump’s Inauguration Speech
- White House Press Briefing
Additional FAQs
- Citing Archived Contributors
- Citing a Blog
- Citing a Book Chapter
- Citing a Source in a Foreign Language
- Citing an Image
- Citing a Song
- Citing Special Contributors
- Citing a Translated Article
- Citing a Tweet
6 Interesting Citation Facts
The world of citations may seem cut and dry, but there’s more to them than just specific capitalization rules, MLA in-text citations , and other formatting specifications. Citations have been helping researches document their sources for hundreds of years, and are a great way to learn more about a particular subject area.
Ever wonder what sets all the different styles apart, or how they came to be in the first place? Read on for some interesting facts about citations!
1. There are Over 7,000 Different Citation Styles
You may be familiar with MLA and APA citation styles, but there are actually thousands of citation styles used for all different academic disciplines all across the world. Deciding which one to use can be difficult, so be sure to ask you instructor which one you should be using for your next paper.
2. Some Citation Styles are Named After People
While a majority of citation styles are named for the specific organizations that publish them (i.e. APA is published by the American Psychological Association, and MLA format is named for the Modern Language Association), some are actually named after individuals. The most well-known example of this is perhaps Turabian style, named for Kate L. Turabian, an American educator and writer. She developed this style as a condensed version of the Chicago Manual of Style in order to present a more concise set of rules to students.
3. There are Some Really Specific and Uniquely Named Citation Styles
How specific can citation styles get? The answer is very. For example, the “Flavour and Fragrance Journal” style is based on a bimonthly, peer-reviewed scientific journal published since 1985 by John Wiley & Sons. It publishes original research articles, reviews and special reports on all aspects of flavor and fragrance. Another example is “Nordic Pulp and Paper Research,” a style used by an international scientific magazine covering science and technology for the areas of wood or bio-mass constituents.
4. More citations were created on EasyBib.com in the first quarter of 2018 than there are people in California.
The US Census Bureau estimates that approximately 39.5 million people live in the state of California. Meanwhile, about 43 million citations were made on EasyBib from January to March of 2018. That’s a lot of citations.
5. “Citations” is a Word With a Long History
The word “citations” can be traced back literally thousands of years to the Latin word “citare” meaning “to summon, urge, call; put in sudden motion, call forward; rouse, excite.” The word then took on its more modern meaning and relevance to writing papers in the 1600s, where it became known as the “act of citing or quoting a passage from a book, etc.”
6. Citation Styles are Always Changing
The concept of citations always stays the same. It is a means of preventing plagiarism and demonstrating where you relied on outside sources. The specific style rules, however, can and do change regularly. For example, in 2018 alone, 46 new citation styles were introduced , and 106 updates were made to exiting styles. At EasyBib, we are always on the lookout for ways to improve our styles and opportunities to add new ones to our list.
Why Citations Matter
Here are the ways accurate citations can help your students achieve academic success, and how you can answer the dreaded question, “why should I cite my sources?”
They Give Credit to the Right People
Citing their sources makes sure that the reader can differentiate the student’s original thoughts from those of other researchers. Not only does this make sure that the sources they use receive proper credit for their work, it ensures that the student receives deserved recognition for their unique contributions to the topic. Whether the student is citing in MLA format , APA format , or any other style, citations serve as a natural way to place a student’s work in the broader context of the subject area, and serve as an easy way to gauge their commitment to the project.
They Provide Hard Evidence of Ideas
Having many citations from a wide variety of sources related to their idea means that the student is working on a well-researched and respected subject. Citing sources that back up their claim creates room for fact-checking and further research . And, if they can cite a few sources that have the converse opinion or idea, and then demonstrate to the reader why they believe that that viewpoint is wrong by again citing credible sources, the student is well on their way to winning over the reader and cementing their point of view.
They Promote Originality and Prevent Plagiarism
The point of research projects is not to regurgitate information that can already be found elsewhere. We have Google for that! What the student’s project should aim to do is promote an original idea or a spin on an existing idea, and use reliable sources to promote that idea. Copying or directly referencing a source without proper citation can lead to not only a poor grade, but accusations of academic dishonesty. By citing their sources regularly and accurately, students can easily avoid the trap of plagiarism , and promote further research on their topic.
They Create Better Researchers
By researching sources to back up and promote their ideas, students are becoming better researchers without even knowing it! Each time a new source is read or researched, the student is becoming more engaged with the project and is developing a deeper understanding of the subject area. Proper citations demonstrate a breadth of the student’s reading and dedication to the project itself. By creating citations, students are compelled to make connections between their sources and discern research patterns. Each time they complete this process, they are helping themselves become better researchers and writers overall.
When is the Right Time to Start Making Citations?
Make in-text/parenthetical citations as you need them.
As you are writing your paper, be sure to include references within the text that correspond with references in a works cited or bibliography. These are usually called in-text citations or parenthetical citations in MLA and APA formats. The most effective time to complete these is directly after you have made your reference to another source. For instance, after writing the line from Charles Dickens’ A Tale of Two Cities : “It was the best of times, it was the worst of times…,” you would include a citation like this (depending on your chosen citation style):
(Dickens 11).
This signals to the reader that you have referenced an outside source. What’s great about this system is that the in-text citations serve as a natural list for all of the citations you have made in your paper, which will make completing the works cited page a whole lot easier. After you are done writing, all that will be left for you to do is scan your paper for these references, and then build a works cited page that includes a citation for each one.
Need help creating an MLA works cited page ? Try the MLA format generator on EasyBib.com! We also have a guide on how to format an APA reference page .
2. Understand the General Formatting Rules of Your Citation Style Before You Start Writing
While reading up on paper formatting may not sound exciting, being aware of how your paper should look early on in the paper writing process is super important. Citation styles can dictate more than just the appearance of the citations themselves, but rather can impact the layout of your paper as a whole, with specific guidelines concerning margin width, title treatment, and even font size and spacing. Knowing how to organize your paper before you start writing will ensure that you do not receive a low grade for something as trivial as forgetting a hanging indent.
Don’t know where to start? Here’s a formatting guide on APA format .
3. Double-check All of Your Outside Sources for Relevance and Trustworthiness First
Collecting outside sources that support your research and specific topic is a critical step in writing an effective paper. But before you run to the library and grab the first 20 books you can lay your hands on, keep in mind that selecting a source to include in your paper should not be taken lightly. Before you proceed with using it to backup your ideas, run a quick Internet search for it and see if other scholars in your field have written about it as well. Check to see if there are book reviews about it or peer accolades. If you spot something that seems off to you, you may want to consider leaving it out of your work. Doing this before your start making citations can save you a ton of time in the long run.
Finished with your paper? It may be time to run it through a grammar and plagiarism checker , like the one offered by EasyBib Plus. If you’re just looking to brush up on the basics, our grammar guides are ready anytime you are.
How useful was this post?
Click on a star to rate it!
We are sorry that this post was not useful for you!
Let us improve this post!
Tell us how we can improve this post?
Citation Basics
Harvard Referencing
Plagiarism Basics
Plagiarism Checker
Upload a paper to check for plagiarism against billions of sources and get advanced writing suggestions for clarity and style.
Get Started
- Directories
- What are citations and why should I use them?
- When should I use a citation?
- Why are there so many citation styles?
Which citation style should I use?
- Chicago Notes Style
- Chicago Author-Date Style
- AMA Style (medicine)
- Bluebook (law)
- Additional Citation Styles
- Built-in Citation Tools
- Quick Citation Generators
- Citation Management Software
- Start Your Research
- Research Guides
- University of Washington Libraries
- Library Guides
- UW Libraries
- Citing Sources
Citing Sources: Which citation style should I use?
The citation style you choose will largely be dictated by the discipline in which you're writing. For many assignments your instructor will suggest or require a certain style. If you're not sure which one to use, it's always best to check with your instructor or, if you are submitting a manuscript, the publisher to see if they require a certain style. In many cases, you may not be required to use any particular style as long as you pick one and use it consistently. If you have some flexibility, use the guide below to help you decide.
Disciplinary Citation Styles
- Social Sciences
- Sciences & Medicine
- Engineering
When in doubt, try: Chicago Notes
- Architecture & Landscape Architecture → try Chicago Notes or Chicago Author-Date
- Art → try Chicago Notes
- Art History → use Chicago Notes
- Dance → try Chicago Notes or MLA
- Drama → try Chicago Notes or MLA
- Ethnomusicology → try Chicago Notes
- Music → try Chicago Notes
- Music History → use Chicago Notes
- Urban Design & Planning → try Chicago Notes or Chicago Author-Date
When in doubt, try: MLA
- Cinema Studies → try MLA
- Classics → try Chicago Notes
- English → use MLA
- History → use Chicago Notes
- Linguistics → try MLA
- Languages → try MLA
- Literatures → use MLA
- Philosophy → try MLA
- Religion → try Chicago Notes
When in doubt, try: APA or Chicago Notes
- Anthropology → try Chicago Author-Date
- Business → try APA (see also Citing Business Information from Foster Library)
- Communication → try APA
- Criminology & Criminal Justice → try Chicago Author-Date
- Economics → try APA
- Education → try APA
- Geography → try APA
- Government & Law (for non-law students) → try Chicago Notes
- History → try Chicago Notes
- Informatics → try APA
- Law (for law students) → use Bluebook
- Library & Information Science → try APA
- Museology → try Chicago Notes
- Political Science → try Chicago Notes
- Psychology → use APA
- Social Work → try APA
- Sociology → use ASA or Chicago Author-Date
When in doubt, try: CSE Name-Year or CSE Citation-Sequence
- Aquatic & Fisheries Sciences → try CSE Name-Year or APA
- Astronomy → try AIP or CSE Citation-Sequence
- Biology & Life Sciences → try CSE Name-Year or APA
- Chemistry → try ACS
- Earth & Space Sciences → try CSE Name-Year or APA
- Environmental Sciences → try CSE Name-Year or APA
- Forest Sciences → try CSE Name-Year or APA
- Health Sciences: Public Health, Medicine, & Nursing → use AMA or NLM
- Marine Sciences → try CSE Name-Year or APA
- Mathematics → try AMS or CSE Citation-Sequence
- Oceanography → try CSE Name-Year or APA
- Physics → try AIP or CSE Citation-Sequence
- Psychology → use APA
When in doubt, try: CSE Name-Year or IEEE
- Aeronautics and Astronautics → try CSE Citation-Sequence
- Bioengineering → try AMA or NLM
- Chemical Engineering → try ACS
- Civil and Environmental Engineering → try CSE Name-Year
- Computational Linguistics → try CSE Citation-Sequence
- Computer Science & Engineering → try IEEE
- Electrical and Computer Engineering → try IEEE
- Engineering (general) → try IEEE or CSE Name-Year
- Human Centered Design & Engineering → try IEEE
- Human-Computer Interaction + Design → try IEEE
- Industrial and Systems Engineering → try CSE Name-Yea r
- Mechanical Engineering → try Chicago Notes or Chicago Author-Date
See also: Additional Citation Styles , for styles used by specific engineering associations.
Pro Tip: Citation Tools Save Time & Stress!
If you’re enrolled in classes that each require a different citation style, it can get confusing really fast! The tools on the Quick Citation Generators section can help you format citations quickly in many different styles.
- << Previous: Why are there so many citation styles?
- Next: Citation Style Guides >>
- Last Updated: May 1, 2024 12:48 PM
- URL: https://guides.lib.uw.edu/research/citations
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Referencing
A Quick Guide to Harvard Referencing | Citation Examples
Published on 14 February 2020 by Jack Caulfield . Revised on 15 September 2023.
Referencing is an important part of academic writing. It tells your readers what sources you’ve used and how to find them.
Harvard is the most common referencing style used in UK universities. In Harvard style, the author and year are cited in-text, and full details of the source are given in a reference list .
| In-text citation | Referencing is an essential academic skill (Pears and Shields, 2019). |
| Reference list entry | Pears, R. and Shields, G. (2019) 11th edn. London: MacMillan. |
Harvard Reference Generator
Instantly correct all language mistakes in your text
Be assured that you'll submit flawless writing. Upload your document to correct all your mistakes.

Table of contents
Harvard in-text citation, creating a harvard reference list, harvard referencing examples, referencing sources with no author or date, frequently asked questions about harvard referencing.
A Harvard in-text citation appears in brackets beside any quotation or paraphrase of a source. It gives the last name of the author(s) and the year of publication, as well as a page number or range locating the passage referenced, if applicable:
Note that ‘p.’ is used for a single page, ‘pp.’ for multiple pages (e.g. ‘pp. 1–5’).
An in-text citation usually appears immediately after the quotation or paraphrase in question. It may also appear at the end of the relevant sentence, as long as it’s clear what it refers to.
When your sentence already mentions the name of the author, it should not be repeated in the citation:
Sources with multiple authors
When you cite a source with up to three authors, cite all authors’ names. For four or more authors, list only the first name, followed by ‘ et al. ’:
| Number of authors | In-text citation example |
|---|---|
| 1 author | (Davis, 2019) |
| 2 authors | (Davis and Barrett, 2019) |
| 3 authors | (Davis, Barrett and McLachlan, 2019) |
| 4+ authors | (Davis , 2019) |
Sources with no page numbers
Some sources, such as websites , often don’t have page numbers. If the source is a short text, you can simply leave out the page number. With longer sources, you can use an alternate locator such as a subheading or paragraph number if you need to specify where to find the quote:
Multiple citations at the same point
When you need multiple citations to appear at the same point in your text – for example, when you refer to several sources with one phrase – you can present them in the same set of brackets, separated by semicolons. List them in order of publication date:
Multiple sources with the same author and date
If you cite multiple sources by the same author which were published in the same year, it’s important to distinguish between them in your citations. To do this, insert an ‘a’ after the year in the first one you reference, a ‘b’ in the second, and so on:
Prevent plagiarism, run a free check.
A bibliography or reference list appears at the end of your text. It lists all your sources in alphabetical order by the author’s last name, giving complete information so that the reader can look them up if necessary.
The reference entry starts with the author’s last name followed by initial(s). Only the first word of the title is capitalised (as well as any proper nouns).

Sources with multiple authors in the reference list
As with in-text citations, up to three authors should be listed; when there are four or more, list only the first author followed by ‘ et al. ’:
| Number of authors | Reference example |
|---|---|
| 1 author | Davis, V. (2019) … |
| 2 authors | Davis, V. and Barrett, M. (2019) … |
| 3 authors | Davis, V., Barrett, M. and McLachlan, F. (2019) … |
| 4+ authors | Davis, V. (2019) … |
Reference list entries vary according to source type, since different information is relevant for different sources. Formats and examples for the most commonly used source types are given below.
- Entire book
- Book chapter
- Translated book
- Edition of a book
| Format | Author surname, initial. (Year) . City: Publisher. |
| Example | Smith, Z. (2017) . London: Penguin. |
| Notes |
| Format | Author surname, initial. (Year) ‘Chapter title’, in Editor name (ed(s).) . City: Publisher, page range. |
| Example | Greenblatt, S. (2010) ‘The traces of Shakespeare’s life’, in De Grazia, M. and Wells, S. (eds.) . Cambridge: Cambridge University Press, pp. 1–14. |
| Notes |
| Format | Author surname, initial. (Year) . Translated from the [language] by Translator name. City: Publisher. |
| Example | Tokarczuk, O. (2019) . Translated from the Polish by A. Lloyd-Jones. London: Fitzcarraldo. |
| Notes |
| Format | Author surname, initial. (Year) . Edition. City: Publisher. |
| Example | Danielson, D. (ed.) (1999) . 2nd edn. Cambridge: Cambridge University Press. |
| Notes |
Journal articles
- Print journal
- Online-only journal with DOI
- Online-only journal with no DOI
| Format | Author surname, initial. (Year) ‘Article title’, , Volume(Issue), pp. page range. |
| Example | Thagard, P. (1990) ‘Philosophy and machine learning’, , 20(2), pp. 261–276. |
| Notes |
| Format | Author surname, initial. (Year) ‘Article title’, , Volume(Issue), page range. DOI. |
| Example | Adamson, P. (2019) ‘American history at the foreign office: Exporting the silent epic Western’, , 31(2), pp. 32–59. doi: https://10.2979/filmhistory.31.2.02. |
| Notes | if available. |
| Format | Author surname, initial. (Year) ‘Article title’, , Volume(Issue), page range. Available at: URL (Accessed: Day Month Year). |
| Example | Theroux, A. (1990) ‘Henry James’s Boston’, , 20(2), pp. 158–165. Available at: https://www.jstor.org/stable/20153016 (Accessed: 13 February 2020). |
| Notes |
- General web page
- Online article or blog
- Social media post
| Format | Author surname, initial. (Year) . Available at: URL (Accessed: Day Month Year). |
| Example | Google (2019) . Available at: https://policies.google.com/terms?hl=en-US (Accessed: 27 January 2020). |
| Notes |
| Format | Author surname, initial. (Year) ‘Article title’, , Date. Available at: URL (Accessed: Day Month Year). |
| Example | Leafstedt, E. (2020) ‘Russia’s constitutional reform and Putin’s plans for a legacy of stability’, , 29 January. Available at: https://blog.politics.ox.ac.uk/russias-constitutional-reform-and-putins-plans-for-a-legacy-of-stability/ (Accessed: 13 February 2020). |
| Notes |
| Format | Author surname, initial. [username] (Year) or text [Website name] Date. Available at: URL (Accessed: Day Month Year). |
| Example | Dorsey, J. [@jack] (2018) We’re committing Twitter to help increase the collective health, openness, and civility of public conversation … [Twitter] 1 March. Available at: https://twitter.com/jack/status/969234275420655616 (Accessed: 13 February 2020). |
| Notes |
Sometimes you won’t have all the information you need for a reference. This section covers what to do when a source lacks a publication date or named author.
No publication date
When a source doesn’t have a clear publication date – for example, a constantly updated reference source like Wikipedia or an obscure historical document which can’t be accurately dated – you can replace it with the words ‘no date’:
| In-text citation | (Scribbr, no date) |
| Reference list entry | Scribbr (no date) . Available at: https://www.scribbr.co.uk/category/thesis-dissertation/ (Accessed: 14 February 2020). |
Note that when you do this with an online source, you should still include an access date, as in the example.
When a source lacks a clearly identified author, there’s often an appropriate corporate source – the organisation responsible for the source – whom you can credit as author instead, as in the Google and Wikipedia examples above.
When that’s not the case, you can just replace it with the title of the source in both the in-text citation and the reference list:
| In-text citation | (‘Divest’, no date) |
| Reference list entry | ‘Divest’ (no date) Available at: https://www.merriam-webster.com/dictionary/divest (Accessed: 27 January 2020). |
The only proofreading tool specialized in correcting academic writing
The academic proofreading tool has been trained on 1000s of academic texts and by native English editors. Making it the most accurate and reliable proofreading tool for students.

Correct my document today
Harvard referencing uses an author–date system. Sources are cited by the author’s last name and the publication year in brackets. Each Harvard in-text citation corresponds to an entry in the alphabetised reference list at the end of the paper.
Vancouver referencing uses a numerical system. Sources are cited by a number in parentheses or superscript. Each number corresponds to a full reference at the end of the paper.
| Harvard style | Vancouver style | |
|---|---|---|
| In-text citation | Each referencing style has different rules (Pears and Shields, 2019). | Each referencing style has different rules (1). |
| Reference list | Pears, R. and Shields, G. (2019). . 11th edn. London: MacMillan. | 1. Pears R, Shields G. Cite them right: The essential referencing guide. 11th ed. London: MacMillan; 2019. |
A Harvard in-text citation should appear in brackets every time you quote, paraphrase, or refer to information from a source.
The citation can appear immediately after the quotation or paraphrase, or at the end of the sentence. If you’re quoting, place the citation outside of the quotation marks but before any other punctuation like a comma or full stop.
In Harvard referencing, up to three author names are included in an in-text citation or reference list entry. When there are four or more authors, include only the first, followed by ‘ et al. ’
| In-text citation | Reference list | |
|---|---|---|
| 1 author | (Smith, 2014) | Smith, T. (2014) … |
| 2 authors | (Smith and Jones, 2014) | Smith, T. and Jones, F. (2014) … |
| 3 authors | (Smith, Jones and Davies, 2014) | Smith, T., Jones, F. and Davies, S. (2014) … |
| 4+ authors | (Smith , 2014) | Smith, T. (2014) … |
Though the terms are sometimes used interchangeably, there is a difference in meaning:
- A reference list only includes sources cited in the text – every entry corresponds to an in-text citation .
- A bibliography also includes other sources which were consulted during the research but not cited.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Caulfield, J. (2023, September 15). A Quick Guide to Harvard Referencing | Citation Examples. Scribbr. Retrieved 24 June 2024, from https://www.scribbr.co.uk/referencing/harvard-style/
Is this article helpful?

Jack Caulfield
Other students also liked, harvard in-text citation | a complete guide & examples, harvard style bibliography | format & examples, referencing books in harvard style | templates & examples, scribbr apa citation checker.
An innovative new tool that checks your APA citations with AI software. Say goodbye to inaccurate citations!

- Privacy Policy
Home » How to Cite Research Paper – All Formats and Examples
How to Cite Research Paper – All Formats and Examples
Table of Contents

Research Paper Citation
Research paper citation refers to the act of acknowledging and referencing a previously published work in a scholarly or academic paper . When citing sources, researchers provide information that allows readers to locate the original source, validate the claims or arguments made in the paper, and give credit to the original author(s) for their work.
The citation may include the author’s name, title of the publication, year of publication, publisher, and other relevant details that allow readers to trace the source of the information. Proper citation is a crucial component of academic writing, as it helps to ensure accuracy, credibility, and transparency in research.
How to Cite Research Paper
There are several formats that are used to cite a research paper. Follow the guide for the Citation of a Research Paper:
Last Name, First Name. Title of Book. Publisher, Year of Publication.
Example : Smith, John. The History of the World. Penguin Press, 2010.
Journal Article
Last Name, First Name. “Title of Article.” Title of Journal, vol. Volume Number, no. Issue Number, Year of Publication, pp. Page Numbers.
Example : Johnson, Emma. “The Effects of Climate Change on Agriculture.” Environmental Science Journal, vol. 10, no. 2, 2019, pp. 45-59.
Research Paper
Last Name, First Name. “Title of Paper.” Conference Name, Location, Date of Conference.
Example : Garcia, Maria. “The Importance of Early Childhood Education.” International Conference on Education, Paris, 5-7 June 2018.
Author’s Last Name, First Name. “Title of Webpage.” Website Title, Publisher, Date of Publication, URL.
Example : Smith, John. “The Benefits of Exercise.” Healthline, Healthline Media, 1 March 2022, https://www.healthline.com/health/benefits-of-exercise.
News Article
Last Name, First Name. “Title of Article.” Name of Newspaper, Date of Publication, URL.
Example : Robinson, Sarah. “Biden Announces New Climate Change Policies.” The New York Times, 22 Jan. 2021, https://www.nytimes.com/2021/01/22/climate/biden-climate-change-policies.html.
Author, A. A. (Year of publication). Title of book. Publisher.
Example: Smith, J. (2010). The History of the World. Penguin Press.
Author, A. A., Author, B. B., & Author, C. C. (Year of publication). Title of article. Title of Journal, volume number(issue number), page range.
Example: Johnson, E., Smith, K., & Lee, M. (2019). The Effects of Climate Change on Agriculture. Environmental Science Journal, 10(2), 45-59.
Author, A. A. (Year of publication). Title of paper. In Editor First Initial. Last Name (Ed.), Title of Conference Proceedings (page numbers). Publisher.
Example: Garcia, M. (2018). The Importance of Early Childhood Education. In J. Smith (Ed.), Proceedings from the International Conference on Education (pp. 60-75). Springer.
Author, A. A. (Year, Month Day of publication). Title of webpage. Website name. URL
Example: Smith, J. (2022, March 1). The Benefits of Exercise. Healthline. https://www.healthline.com/health/benefits-of-exercise
Author, A. A. (Year, Month Day of publication). Title of article. Newspaper name. URL.
Example: Robinson, S. (2021, January 22). Biden Announces New Climate Change Policies. The New York Times. https://www.nytimes.com/2021/01/22/climate/biden-climate-change-policies.html
Chicago/Turabian style
Please note that there are two main variations of the Chicago style: the author-date system and the notes and bibliography system. I will provide examples for both systems below.
Author-Date system:
- In-text citation: (Author Last Name Year, Page Number)
- Reference list: Author Last Name, First Name. Year. Title of Book. Place of publication: Publisher.
- In-text citation: (Smith 2005, 28)
- Reference list: Smith, John. 2005. The History of America. New York: Penguin Press.
Notes and Bibliography system:
- Footnote/Endnote citation: Author First Name Last Name, Title of Book (Place of publication: Publisher, Year), Page Number.
- Bibliography citation: Author Last Name, First Name. Title of Book. Place of publication: Publisher, Year.
- Footnote/Endnote citation: John Smith, The History of America (New York: Penguin Press, 2005), 28.
- Bibliography citation: Smith, John. The History of America. New York: Penguin Press, 2005.
JOURNAL ARTICLES:
- Reference list: Author Last Name, First Name. Year. “Article Title.” Journal Title Volume Number (Issue Number): Page Range.
- In-text citation: (Johnson 2010, 45)
- Reference list: Johnson, Mary. 2010. “The Impact of Social Media on Society.” Journal of Communication 60(2): 39-56.
- Footnote/Endnote citation: Author First Name Last Name, “Article Title,” Journal Title Volume Number, Issue Number (Year): Page Range.
- Bibliography citation: Author Last Name, First Name. “Article Title.” Journal Title Volume Number, Issue Number (Year): Page Range.
- Footnote/Endnote citation: Mary Johnson, “The Impact of Social Media on Society,” Journal of Communication 60, no. 2 (2010): 39-56.
- Bibliography citation: Johnson, Mary. “The Impact of Social Media on Society.” Journal of Communication 60, no. 2 (2010): 39-56.
RESEARCH PAPERS:
- Reference list: Author Last Name, First Name. Year. “Title of Paper.” Conference Proceedings Title, Location, Date. Publisher, Page Range.
- In-text citation: (Jones 2015, 12)
- Reference list: Jones, David. 2015. “The Effects of Climate Change on Agriculture.” Proceedings of the International Conference on Climate Change, Paris, France, June 1-3, 2015. Springer, 10-20.
- Footnote/Endnote citation: Author First Name Last Name, “Title of Paper,” Conference Proceedings Title, Location, Date (Place of publication: Publisher, Year), Page Range.
- Bibliography citation: Author Last Name, First Name. “Title of Paper.” Conference Proceedings Title, Location, Date. Place of publication: Publisher, Year.
- Footnote/Endnote citation: David Jones, “The Effects of Climate Change on Agriculture,” Proceedings of the International Conference on Climate Change, Paris, France, June 1-3, 2015 (New York: Springer, 10-20).
- Bibliography citation: Jones, David. “The Effects of Climate Change on Agriculture.” Proceedings of the International Conference on Climate Change, Paris, France, June 1-3, 2015. New York: Springer, 10-20.
- In-text citation: (Author Last Name Year)
- Reference list: Author Last Name, First Name. Year. “Title of Webpage.” Website Name. URL.
- In-text citation: (Smith 2018)
- Reference list: Smith, John. 2018. “The Importance of Recycling.” Environmental News Network. https://www.enn.com/articles/54374-the-importance-of-recycling.
- Footnote/Endnote citation: Author First Name Last Name, “Title of Webpage,” Website Name, URL (accessed Date).
- Bibliography citation: Author Last Name, First Name. “Title of Webpage.” Website Name. URL (accessed Date).
- Footnote/Endnote citation: John Smith, “The Importance of Recycling,” Environmental News Network, https://www.enn.com/articles/54374-the-importance-of-recycling (accessed April 8, 2023).
- Bibliography citation: Smith, John. “The Importance of Recycling.” Environmental News Network. https://www.enn.com/articles/54374-the-importance-of-recycling (accessed April 8, 2023).
NEWS ARTICLES:
- Reference list: Author Last Name, First Name. Year. “Title of Article.” Name of Newspaper, Month Day.
- In-text citation: (Johnson 2022)
- Reference list: Johnson, Mary. 2022. “New Study Finds Link Between Coffee and Longevity.” The New York Times, January 15.
- Footnote/Endnote citation: Author First Name Last Name, “Title of Article,” Name of Newspaper (City), Month Day, Year.
- Bibliography citation: Author Last Name, First Name. “Title of Article.” Name of Newspaper (City), Month Day, Year.
- Footnote/Endnote citation: Mary Johnson, “New Study Finds Link Between Coffee and Longevity,” The New York Times (New York), January 15, 2022.
- Bibliography citation: Johnson, Mary. “New Study Finds Link Between Coffee and Longevity.” The New York Times (New York), January 15, 2022.
Harvard referencing style
Format: Author’s Last name, First initial. (Year of publication). Title of book. Publisher.
Example: Smith, J. (2008). The Art of War. Random House.
Journal article:
Format: Author’s Last name, First initial. (Year of publication). Title of article. Title of journal, volume number(issue number), page range.
Example: Brown, M. (2012). The impact of social media on business communication. Harvard Business Review, 90(12), 85-92.
Research paper:
Format: Author’s Last name, First initial. (Year of publication). Title of paper. In Editor’s First initial. Last name (Ed.), Title of book (page range). Publisher.
Example: Johnson, R. (2015). The effects of climate change on agriculture. In S. Lee (Ed.), Climate Change and Sustainable Development (pp. 45-62). Springer.
Format: Author’s Last name, First initial. (Year, Month Day of publication). Title of page. Website name. URL.
Example: Smith, J. (2017, May 23). The history of the internet. Encyclopedia Britannica. https://www.britannica.com/topic/history-of-the-internet
News article:
Format: Author’s Last name, First initial. (Year, Month Day of publication). Title of article. Title of newspaper, page number (if applicable).
Example: Thompson, E. (2022, January 5). New study finds coffee may lower risk of dementia. The New York Times, A1.
IEEE Format
Author(s). (Year of Publication). Title of Book. Publisher.
Smith, J. K. (2015). The Power of Habit: Why We Do What We Do in Life and Business. Random House.
Journal Article:
Author(s). (Year of Publication). Title of Article. Title of Journal, Volume Number (Issue Number), page numbers.
Johnson, T. J., & Kaye, B. K. (2016). Interactivity and the Future of Journalism. Journalism Studies, 17(2), 228-246.
Author(s). (Year of Publication). Title of Paper. Paper presented at Conference Name, Location.
Jones, L. K., & Brown, M. A. (2018). The Role of Social Media in Political Campaigns. Paper presented at the 2018 International Conference on Social Media and Society, Copenhagen, Denmark.
- Website: Author(s) or Organization Name. (Year of Publication or Last Update). Title of Webpage. Website Name. URL.
Example: National Aeronautics and Space Administration. (2019, August 29). NASA’s Mission to Mars. NASA. https://www.nasa.gov/topics/journeytomars/index.html
- News Article: Author(s). (Year of Publication). Title of Article. Name of News Source. URL.
Example: Johnson, M. (2022, February 16). Climate Change: Is it Too Late to Save the Planet? CNN. https://www.cnn.com/2022/02/16/world/climate-change-planet-scn/index.html
Vancouver Style
In-text citation: Use superscript numbers to cite sources in the text, e.g., “The study conducted by Smith and Johnson^1 found that…”.
Reference list citation: Format: Author(s). Title of book. Edition if any. Place of publication: Publisher; Year of publication.
Example: Smith J, Johnson L. Introduction to Molecular Biology. 2nd ed. New York: Wiley-Blackwell; 2015.
In-text citation: Use superscript numbers to cite sources in the text, e.g., “Several studies have reported that^1,2,3…”.
Reference list citation: Format: Author(s). Title of article. Abbreviated name of journal. Year of publication; Volume number (Issue number): Page range.
Example: Jones S, Patel K, Smith J. The effects of exercise on cardiovascular health. J Cardiol. 2018; 25(2): 78-84.
In-text citation: Use superscript numbers to cite sources in the text, e.g., “Previous research has shown that^1,2,3…”.
Reference list citation: Format: Author(s). Title of paper. In: Editor(s). Title of the conference proceedings. Place of publication: Publisher; Year of publication. Page range.
Example: Johnson L, Smith J. The role of stem cells in tissue regeneration. In: Patel S, ed. Proceedings of the 5th International Conference on Regenerative Medicine. London: Academic Press; 2016. p. 68-73.
In-text citation: Use superscript numbers to cite sources in the text, e.g., “According to the World Health Organization^1…”.
Reference list citation: Format: Author(s). Title of webpage. Name of website. URL [Accessed Date].
Example: World Health Organization. Coronavirus disease (COVID-19) advice for the public. World Health Organization. https://www.who.int/emergencies/disease/novel-coronavirus-2019/advice-for-public [Accessed 3 March 2023].
In-text citation: Use superscript numbers to cite sources in the text, e.g., “According to the New York Times^1…”.
Reference list citation: Format: Author(s). Title of article. Name of newspaper. Year Month Day; Section (if any): Page number.
Example: Jones S. Study shows that sleep is essential for good health. The New York Times. 2022 Jan 12; Health: A8.
Author(s). Title of Book. Edition Number (if it is not the first edition). Publisher: Place of publication, Year of publication.
Example: Smith, J. Chemistry of Natural Products. 3rd ed.; CRC Press: Boca Raton, FL, 2015.
Journal articles:
Author(s). Article Title. Journal Name Year, Volume, Inclusive Pagination.
Example: Garcia, A. M.; Jones, B. A.; Smith, J. R. Selective Synthesis of Alkenes from Alkynes via Catalytic Hydrogenation. J. Am. Chem. Soc. 2019, 141, 10754-10759.
Research papers:
Author(s). Title of Paper. Journal Name Year, Volume, Inclusive Pagination.
Example: Brown, H. D.; Jackson, C. D.; Patel, S. D. A New Approach to Photovoltaic Solar Cells. J. Mater. Chem. 2018, 26, 134-142.
Author(s) (if available). Title of Webpage. Name of Website. URL (accessed Month Day, Year).
Example: National Institutes of Health. Heart Disease and Stroke. National Heart, Lung, and Blood Institute. https://www.nhlbi.nih.gov/health-topics/heart-disease-and-stroke (accessed April 7, 2023).
News articles:
Author(s). Title of Article. Name of News Publication. Date of Publication. URL (accessed Month Day, Year).
Example: Friedman, T. L. The World is Flat. New York Times. April 7, 2023. https://www.nytimes.com/2023/04/07/opinion/world-flat-globalization.html (accessed April 7, 2023).
In AMA Style Format, the citation for a book should include the following information, in this order:
- Title of book (in italics)
- Edition (if applicable)
- Place of publication
- Year of publication
Lodish H, Berk A, Zipursky SL, et al. Molecular Cell Biology. 4th ed. New York, NY: W. H. Freeman; 2000.
In AMA Style Format, the citation for a journal article should include the following information, in this order:
- Title of article
- Abbreviated title of journal (in italics)
- Year of publication; volume number(issue number):page numbers.
Chen H, Huang Y, Li Y, et al. Effects of mindfulness-based stress reduction on depression in adolescents and young adults: a systematic review and meta-analysis. JAMA Netw Open. 2020;3(6):e207081. doi:10.1001/jamanetworkopen.2020.7081
In AMA Style Format, the citation for a research paper should include the following information, in this order:
- Title of paper
- Name of journal or conference proceeding (in italics)
- Volume number(issue number):page numbers.
Bredenoord AL, Kroes HY, Cuppen E, Parker M, van Delden JJ. Disclosure of individual genetic data to research participants: the debate reconsidered. Trends Genet. 2011;27(2):41-47. doi:10.1016/j.tig.2010.11.004
In AMA Style Format, the citation for a website should include the following information, in this order:
- Title of web page or article
- Name of website (in italics)
- Date of publication or last update (if available)
- URL (website address)
- Date of access (month day, year)
Centers for Disease Control and Prevention. How to protect yourself and others. CDC. Published February 11, 2022. Accessed February 14, 2022. https://www.cdc.gov/coronavirus/2019-ncov/prevent-getting-sick/prevention.html
In AMA Style Format, the citation for a news article should include the following information, in this order:
- Name of newspaper or news website (in italics)
- Date of publication
Gorman J. Scientists use stem cells from frogs to build first living robots. The New York Times. January 13, 2020. Accessed January 14, 2020. https://www.nytimes.com/2020/01/13/science/living-robots-xenobots.html
Bluebook Format
One author: Daniel J. Solove, The Future of Reputation: Gossip, Rumor, and Privacy on the Internet (Yale University Press 2007).
Two or more authors: Martha Nussbaum and Saul Levmore, eds., The Offensive Internet: Speech, Privacy, and Reputation (Harvard University Press 2010).
Journal article
One author: Daniel J. Solove, “A Taxonomy of Privacy,” University of Pennsylvania Law Review 154, no. 3 (January 2006): 477-560.
Two or more authors: Ethan Katsh and Andrea Schneider, “The Emergence of Online Dispute Resolution,” Journal of Dispute Resolution 2003, no. 1 (2003): 7-19.
One author: Daniel J. Solove, “A Taxonomy of Privacy,” GWU Law School Public Law Research Paper No. 113, 2005.
Two or more authors: Ethan Katsh and Andrea Schneider, “The Emergence of Online Dispute Resolution,” Cyberlaw Research Paper Series Paper No. 00-5, 2000.
WebsiteElectronic Frontier Foundation, “Surveillance Self-Defense,” accessed April 8, 2023, https://ssd.eff.org/.
News article
One author: Mark Sherman, “Court Deals Major Blow to Net Neutrality Rules,” ABC News, January 14, 2014, https://abcnews.go.com/Politics/wireStory/court-deals-major-blow-net-neutrality-rules-21586820.
Two or more authors: Siobhan Hughes and Brent Kendall, “AT&T Wins Approval to Buy Time Warner,” Wall Street Journal, June 12, 2018, https://www.wsj.com/articles/at-t-wins-approval-to-buy-time-warner-1528847249.
In-Text Citation: (Author’s last name Year of Publication: Page Number)
Example: (Smith 2010: 35)
Reference List Citation: Author’s last name First Initial. Title of Book. Edition. Place of publication: Publisher; Year of publication.
Example: Smith J. Biology: A Textbook. 2nd ed. New York: Oxford University Press; 2010.
Example: (Johnson 2014: 27)
Reference List Citation: Author’s last name First Initial. Title of Article. Abbreviated Title of Journal. Year of publication;Volume(Issue):Page Numbers.
Example: Johnson S. The role of dopamine in addiction. J Neurosci. 2014;34(8): 2262-2272.
Example: (Brown 2018: 10)
Reference List Citation: Author’s last name First Initial. Title of Paper. Paper presented at: Name of Conference; Date of Conference; Place of Conference.
Example: Brown R. The impact of social media on mental health. Paper presented at: Annual Meeting of the American Psychological Association; August 2018; San Francisco, CA.
Example: (World Health Organization 2020: para. 2)
Reference List Citation: Author’s last name First Initial. Title of Webpage. Name of Website. URL. Published date. Accessed date.
Example: World Health Organization. Coronavirus disease (COVID-19) pandemic. WHO website. https://www.who.int/emergencies/disease-coronavirus-2019. Updated August 17, 2020. Accessed September 5, 2021.
Example: (Smith 2019: para. 5)
Reference List Citation: Author’s last name First Initial. Title of Article. Title of Newspaper or Magazine. Year of publication; Month Day:Page Numbers.
Example: Smith K. New study finds link between exercise and mental health. The New York Times. 2019;May 20: A6.
Purpose of Research Paper Citation
The purpose of citing sources in a research paper is to give credit to the original authors and acknowledge their contribution to your work. By citing sources, you are also demonstrating the validity and reliability of your research by showing that you have consulted credible and authoritative sources. Citations help readers to locate the original sources that you have referenced and to verify the accuracy and credibility of your research. Additionally, citing sources is important for avoiding plagiarism, which is the act of presenting someone else’s work as your own. Proper citation also shows that you have conducted a thorough literature review and have used the existing research to inform your own work. Overall, citing sources is an essential aspect of academic writing and is necessary for building credibility, demonstrating research skills, and avoiding plagiarism.
Advantages of Research Paper Citation
There are several advantages of research paper citation, including:
- Giving credit: By citing the works of other researchers in your field, you are acknowledging their contribution and giving credit where it is due.
- Strengthening your argument: Citing relevant and reliable sources in your research paper can strengthen your argument and increase its credibility. It shows that you have done your due diligence and considered various perspectives before drawing your conclusions.
- Demonstrating familiarity with the literature : By citing various sources, you are demonstrating your familiarity with the existing literature in your field. This is important as it shows that you are well-informed about the topic and have done a thorough review of the available research.
- Providing a roadmap for further research: By citing relevant sources, you are providing a roadmap for further research on the topic. This can be helpful for future researchers who are interested in exploring the same or related issues.
- Building your own reputation: By citing the works of established researchers in your field, you can build your own reputation as a knowledgeable and informed scholar. This can be particularly helpful if you are early in your career and looking to establish yourself as an expert in your field.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Research Paper Conclusion – Writing Guide and...

How to Publish a Research Paper – Step by Step...

Research Paper Format – Types, Examples and...

Theoretical Framework – Types, Examples and...

Research Paper Outline – Types, Example, Template

Research Design – Types, Methods and Examples
- PRO Courses Guides New Tech Help Pro Expert Videos About wikiHow Pro Upgrade Sign In
- EDIT Edit this Article
- EXPLORE Tech Help Pro About Us Random Article Quizzes Request a New Article Community Dashboard This Or That Game Popular Categories Arts and Entertainment Artwork Books Movies Computers and Electronics Computers Phone Skills Technology Hacks Health Men's Health Mental Health Women's Health Relationships Dating Love Relationship Issues Hobbies and Crafts Crafts Drawing Games Education & Communication Communication Skills Personal Development Studying Personal Care and Style Fashion Hair Care Personal Hygiene Youth Personal Care School Stuff Dating All Categories Arts and Entertainment Finance and Business Home and Garden Relationship Quizzes Cars & Other Vehicles Food and Entertaining Personal Care and Style Sports and Fitness Computers and Electronics Health Pets and Animals Travel Education & Communication Hobbies and Crafts Philosophy and Religion Work World Family Life Holidays and Traditions Relationships Youth
- Browse Articles
- Learn Something New
- Quizzes Hot
- This Or That Game
- Train Your Brain
- Explore More
- Support wikiHow
- About wikiHow
- Log in / Sign up
- Education and Communications
- College University and Postgraduate
- Academic Writing
- Research Papers
How to Cite a Research Paper
Last Updated: March 29, 2024 Fact Checked
This article was reviewed by Gerald Posner and by wikiHow staff writer, Jennifer Mueller, JD . Gerald Posner is an Author & Journalist based in Miami, Florida. With over 35 years of experience, he specializes in investigative journalism, nonfiction books, and editorials. He holds a law degree from UC College of the Law, San Francisco, and a BA in Political Science from the University of California-Berkeley. He’s the author of thirteen books, including several New York Times bestsellers, the winner of the Florida Book Award for General Nonfiction, and has been a finalist for the Pulitzer Prize in History. He was also shortlisted for the Best Business Book of 2020 by the Society for Advancing Business Editing and Writing. There are 8 references cited in this article, which can be found at the bottom of the page. This article has been fact-checked, ensuring the accuracy of any cited facts and confirming the authority of its sources. This article has been viewed 417,300 times.
When writing a paper for a research project, you may need to cite a research paper you used as a reference. The basic information included in your citation will be the same across all styles. However, the format in which that information is presented is somewhat different depending on whether you're using American Psychological Association (APA), Modern Language Association (MLA), Chicago, or American Medical Association (AMA) style.
Referencing a Research Paper
- In APA style, cite the paper: Last Name, First Initial. (Year). Title. Publisher.
- In Chicago style, cite the paper: Last Name, First Name. “Title.” Publisher, Year.
- In MLA style, cite the paper: Last Name, First Name. “Title.” Publisher. Year.
Citation Help

- For example: "Kringle, K., & Frost, J."

- For example: "Kringle, K., & Frost, J. (2012)."
- If the date, or any other information, are not available, use the guide at https://blog.apastyle.org/apastyle/2012/05/missing-pieces.html .

- For example: "Kringle, K., & Frost, J. (2012). Red noses, warm hearts: The glowing phenomenon among North Pole reindeer."
- If you found the research paper in a database maintained by a university, corporation, or other organization, include any index number assigned to the paper in parentheses after the title. For example: "Kringle, K., & Frost, J. (2012). Red noses, warm hearts: The glowing phenomenon among North Pole reindeer. (Report No. 1234)."

- For example: "Kringle, K., & Frost, J. (2012). Red noses, warm hearts: The glowing phenomenon among North Pole reindeer. (Report No. 1234). Retrieved from Alaska University Library Archives, December 24, 2017."

- For example: "(Kringle & Frost, 2012)."
- If there was no date on the research paper, use the abbreviation n.d. : "(Kringle & Frost, n.d.)."

- For example: "Kringle, Kris, and Jack Frost."

- For example: "Kringle, Kris, and Jack Frost. "Red Noses, Warm Hearts: The Glowing Phenomenon among North Pole Reindeer." Master's thesis."

- For example: "Kringle, Kris, and Jack Frost. "Red Noses, Warm Hearts: The Glowing Phenomenon among North Pole Reindeer." Master's thesis, Alaska University, 2012."

- For example: "Kringle, Kris, and Jack Frost. "Red Noses, Warm Hearts: The Glowing Phenomenon among North Pole Reindeer." Master's thesis, Alaska University, 2012. Accessed at https://www.northpolemedical.com/raising_rudolf."

- Footnotes are essentially the same as the full citation, although the first and last names of the authors aren't inverted.
- For parenthetical citations, Chicago uses the Author-Date format. For example: "(Kringle and Frost 2012)."

- For example: "Kringle, Kris, and Frost, Jack."

- For example: "Kringle, Kris, and Frost, Jack. "Red Noses, Warm Hearts: The Glowing Phenomenon Among North Pole Reindeer.""

- For example, suppose you found the paper in a collection of paper housed in university archives. Your citation might be: "Kringle, Kris, and Frost, Jack. "Red Noses, Warm Hearts: The Glowing Phenomenon Among North Pole Reindeer." Master's Theses 2000-2010. University of Alaska Library Archives. Accessed December 24, 2017."

- For example: "(Kringle & Frost, p. 33)."

- For example: "Kringle K, Frost J."

- For example: "Kringle K, Frost J. Red noses, warm hearts: The glowing phenomenon among North Pole reindeer."

- For example: "Kringle K, Frost J. Red noses, warm hearts: The glowing phenomenon among North Pole reindeer. Nat Med. 2012; 18(9): 1429-1433."

- For example, if you're citing a paper presented at a conference, you'd write: "Kringle K, Frost J. Red noses, warm hearts: The glowing phenomenon among North Pole reindeer. Oral presentation at Arctic Health Association Annual Summit; December, 2017; Nome, Alaska."
- To cite a paper you read online, you'd write: "Kringle K, Frost J. Red noses, warm hearts: The glowing phenomenon among North Pole reindeer. https://www.northpolemedical.com/raising_rudolf"

- For example: "According to Kringle and Frost, these red noses indicate a subspecies of reindeer native to Alaska and Canada that have migrated to the North Pole and mingled with North Pole reindeer. 1 "
Community Q&A
- If you used a manual as a source in your research paper, you'll need to learn how to cite the manual also. Thanks Helpful 0 Not Helpful 0
- If you use any figures in your research paper, you'll also need to know the proper way to cite them in MLA, APA, AMA, or Chicago. Thanks Helpful 0 Not Helpful 0
You Might Also Like

- ↑ https://askus.library.wwu.edu/faq/116659
- ↑ https://guides.libraries.psu.edu/apaquickguide/intext
- ↑ https://owl.purdue.edu/owl/research_and_citation/chicago_manual_17th_edition/cmos_formatting_and_style_guide/general_format.html
- ↑ https://libanswers.snhu.edu/faq/48009
- ↑ https://www.chicagomanualofstyle.org/tools_citationguide/citation-guide-2.html
- ↑ https://owl.purdue.edu/owl/research_and_citation/mla_style/mla_formatting_and_style_guide/mla_in_text_citations_the_basics.html
- ↑ https://morningside.libguides.com/MLA8/location
- ↑ https://owl.purdue.edu/owl/research_and_citation/ama_style/index.html
About This Article

To cite a paper APA style, start with the author's last name and first initial, and the year of publication. Then, list the title of the paper, where you found it, and the date that you accessed it. In a paper, use a parenthetical reference with the last name of the author and the publication year. For an MLA citation, list the author's last name and then first name and the title of the paper in quotations. Include where you accessed the paper and the date you retrieved it. In your paper, use a parenthetical reference with the author's last name and the page number. Keep reading for tips on Chicago and AMA citations and exceptions to the citation rules! Did this summary help you? Yes No
- Send fan mail to authors
Did this article help you?

Featured Articles

Trending Articles

Watch Articles

- Terms of Use
- Privacy Policy
- Do Not Sell or Share My Info
- Not Selling Info
Don’t miss out! Sign up for
wikiHow’s newsletter
Educational resources and simple solutions for your research journey

A Beginner’s Guide to Citations, References and Bibliography in Research Papers

As an academician, terms such as citations, references and bibliography might be a part of almost every work-related conversation in your daily life. However, many researchers, especially during the early stages of their academic career, may find it hard to differentiate between citations, references and bibliography in research papers and often find it confusing to implement their usage. If you are amongst them, this article will provide you with some respite. Let us start by first understanding the individual terms better.
Citation in research papers: A citation appears in the main text of the paper. It is a way of giving credit to the information that you have specifically mentioned in your research paper by leading the reader to the original source of information. You will need to use citation in research papers whenever you are using information to elaborate a particular concept in the paper, either in the introduction or discussion sections or as a way to support your research findings in the results section.
Reference in research papers: A reference is a detailed description of the source of information that you want to give credit to via a citation. The references in research papers are usually in the form of a list at the end of the paper. The essential difference between citations and references is that citations lead a reader to the source of information, while references provide the reader with detailed information regarding that particular source.
Bibliography in research papers:
A bibliography in research paper is a list of sources that appears at the end of a research paper or an article, and contains information that may or may not be directly mentioned in the research paper. The difference between reference and bibliography in research is that an individual source in the list of references can be linked to an in-text citation, while an individual source in the bibliography may not necessarily be linked to an in-text citation.
It’s understandable how these terms may often be used interchangeably as they are serve the same purpose – namely to give intellectual and creative credit to an original idea that is elaborated in depth in a research paper. One of the easiest ways to understand when to use an in-text citation in research papers, is to check whether the information is an ongoing work of research or if it has been proven to be a ‘fact’ through reproducibility. If the information is a proven fact, you need not specifically add the original source to the list of references but can instead choose to mention it in your bibliography. For instance, if you use a statement such as “The effects of global warming and climate changes on the deterioration of environment have been described in depth”, you need not use an in-text citation, but can choose to mention key sources in the bibliography section. An example of a citation in a research paper would be if you intend to elaborate on the impact of climate change in a particular population and/or a specific geographical location. In this case, you will need to add an in-text citation and mention the correct source in the list of references.

| Citations | References | Bibliography | |
| Purpose | To lead a reader toward a source of information included in the text | To elaborate on of a particular source of information cited in the research paper | To provide a list of all relevant sources of information on the research topic
|
| Placement | In the main text | At the end of the text; necessarily linked to an in-text citation | At the end of the text; not necessarily linked to an in-text citation
|
| Information | Minimal; denoting only the essential components of the source, such as numbering, names of the first and last authors, etc.
| Descriptive; gives complete details about a particular source that can be used to find and read the original paper if needed | Descriptive; gives all the information regarding a particular source for those who want to refer to it |
Now that you have understood the basic similarities and differences in these terms, you should also know that every journal follows a particular style and format for these elements. So when working out how to write citations and add references in research papers, be mindful of using the preferred style of your target journal before you submit your research document.
R Discovery is a literature search and research reading platform that accelerates your research discovery journey by keeping you updated on the latest, most relevant scholarly content. With 250M+ research articles sourced from trusted aggregators like CrossRef, Unpaywall, PubMed, PubMed Central, Open Alex and top publishing houses like Springer Nature, JAMA, IOP, Taylor & Francis, NEJM, BMJ, Karger, SAGE, Emerald Publishing and more, R Discovery puts a world of research at your fingertips.
Try R Discovery Prime FREE for 1 week or upgrade at just US$72 a year to access premium features that let you listen to research on the go, read in your language, collaborate with peers, auto sync with reference managers, and much more. Choose a simpler, smarter way to find and read research – Download the app and start your free 7-day trial today !
Related Posts

Simple Random Sampling: Definition, Methods, and Examples

What is a Case Study in Research? Definition, Methods, and Examples
Learn HTML Code, Tags & CSS
The Student’s Guide To Citation Styles: Here’s When (And How) To Cite

Citing resources will also avoid plagiarism, by crediting to those who provided the research used to create a paper.
- 1.1 When Not to Cite a Source
- 2 The Main Types of Sources
- 3 How to Cite
- 4 Programs for Creating Citations
When to Cite a Source
Include a citation whenever you can. If you are not sure whether or not to cite a source, cite it. You should reference and cite whenever you:
- Quote directly from a source.
- Summarize or paraphrase another writer’s ideas, concepts or opinions.
- Anywhere you find data, facts and information used in your paper.
- Images, visuals, graphs and charts you use in your work.
When Not to Cite a Source
You do not have to cite your source if the information you use is common knowledge. For example, the first African American President of the U.S. is Barack Obama; however, if you aren’t sure if it is common knowledge or not, go ahead and cite it, just to be safe.
The Main Types of Sources
There are three main types of sources: primary, secondary and peer-reviewed.
Primary sources may be in their original form or digitized, or reprinted or reproduced in some form. They are first-hand accounts of an event or period in history, or original documents. Primary sources include:
- Texts – Novels, letters, diaries, government reports, newspaper articles and autobiographies. Images – Paintings, photographs and advertisements.
- Artifacts – Sculptures, buildings and clothing.
- Audio-Visual – Oral history like interviews, songs, films and photos.
Secondary sources are written about primary sources and are one or more steps away from the original source. They include discussions, comments and interpretations regarding the primary source or original material. Examples of secondary source materials are as follows:
- Articles from magazines, journals and newspapers.
- Textbooks, histories and encyclopedias.
- Book, play, concert and movie reviews, criticisms and commentaries.
- Articles from scholarly journals that assess or discuss the original research of others.
- Peer Reviewed
Usually published as an article in a medical or professional publication, such as a journal, a peer-reviewed source undergoes multiple critiques by top scholars in a particular field. Peer-reviewed articles offer authoritative information of the highest quality that scholarly disciplines can provide. Peer-reviewed and scholarly articles have these characteristics:
- List the journal of publication and author credentials.
- Are an abstract from a larger publication.
- Include a large amount of in-text citations, references, endnotes, footnotes and cited works, as well as a bibliography and appendix.
- Contain sections like methodology, conclusion and results.
- Have numerous in-text tables, charts and graphs.
- Use complex wording specific to the field.
How to Cite

When you cite data from another author’s work, explain all related aspects of the work clearly and concisely using your own words. Always provide a reference to the work directly following the information you have provided.
Most colleges and organizations use a variety of citation styles. The citation style often depends on the professor, so always check before beginning a paper. No matter what the style you use for citing your paper, the process is always the same:
- Consult the appropriate style guide for examples of how to produce in-text citations, reference lists and bibliographies.
- Some style guides are available via citation software that helps track sources for the use in creating bibliographies, in-text citations and reference lists.
- Use one standard style in a consistent manner throughout the entire paper.
Researchers and writers should understand some of the following styles:
The American Psychology Association – Use this style for education, psychology, sociology and other social sciences.
- Example of APA style for a book with one author:
Doe, J. (1999). Causes of the Civil War . Ohio: Smith Books.
Resources :
- Publication Manual of the American Psychological Association
- APA Formatting and Style Guide : Available online from The Owl at Purdue, this contains examples of reference list entries and in-text citations.
- Basics of APA Style Tutorial : Available online from the APA, this outlines citing and writing guidelines.
Modern Language Association – Use this style for arts, literature and the humanities.
- Example of MLA style for a book with one author:
Doe, John: “Causes of the Civil War.” Smith.
- MLA 2009 Formatting and Style Guide : Available online from The Owl at Purdue, with many examples for producing works cited entries and in-text footnotes.
- MLA Style Manual and Guide to Scholarly Publishing : Available online from The Owl at Purdue, contains examples.

American Medical Association or the National Library of Medicine for health, medicine and biological sciences.
- Example of AMA for a book with one author:
Doe JD. Causes of the Civil War . Columbus, OH: Smith Books; 1999.
- Example of NLM for a book with one author:
Doe, JD. Causes of the Civil War. Columbus (OH): Smith Books; 1999.
- AMA Manual of Style: A Guide for Authors and Editors
- Citing Medicine: The NLM Style Guide for authors, editors and publishers ; available online from the National Library of Medicine.
- A Comparison of AMA and NLM styles
Students and researchers commonly use the Chicago Manual of Style guide, or Turabian, for most real-world subjects in magazines, books, newspapers and many other non-scholarly publications.
- Example of Chicago style for a book with one author:
Doe, John. 1999. Causes of the Civil War . Columbus, Ohio:
Smith Books.
- CMS: Provide by the Perdue Owl Online Writing Laboratory.
There are a variety of scientific style guides depending on the particular field, whether it be biology, chemistry, engineering.
- Example of Scientific Style for a book with one author:
John D. Doe. Causes of the Civil War. Columbus (OH): Smith Press: 1999.
- ACS : American Chemical Society
- ACS Style Guidelines : Available online from UW-Madison Libraries, providing examples for citing references in the text and the bibliography of a research paper.
- IEEE : Institute of Electronics and Electrical Engineers
- IEEE Editorial Style Manual : An online PDF that provides editorial guidelines for IEEE letters, journals and transactions, with citation examples.
- The Writer’s Handbook – CSE Citation
More Citation Examples
The following resources provide more examples for formatting citations:
- Citing References Wiki – Maintained by LexisNexis, this guide includes examples from APA, MLA, Chicago and Turabian.
- Research and Documentation Online – Compiled by Diana Hacker, this guide includes APA, CMS, CSE and MLA styles
Programs for Creating Citations
The following resources provide programs to help researchers create citations:
- Landmark Citation Machine
- Citation Builder
When using a citation program, always check for errors before inserting them into your reference or works cited page.
The Annotated Bibliography or Reference Section
The reference page is also called the annotated bibliography , and it should go at the end of the research paper. The purpose of annotated bibliographies is to link each source to one another in an orderly fashion.
Here are six key factors for writing an annotation:
- Clearly state the qualifications and authority of the author early in the annotation. Example:
- Explain the main purpose and scope of the text in a few brief sentences.This is not like an abstract, which is a synopsis of the entire piece; rather, it is the main theme or concept. Example:
- Note the relation of the paper to other works in the field. Example:
- Clarify the author’s main opinion or conclusion in relation to the overall theme. Example:
- Indicate your target audience and the level of reading difficulty. Example:
- End with a summary comment. Example:
Completed example:
For more guidelines on creating an annotated bibliography, see the Purdue OWL: Annotated Bibliographies site, which includes additional sample annotations .
Adding citations may seem difficult at first; however, the more you practice, the easier it will become for you. By using a style guide and checking examples, citing all your sources is simple and complete.
Leave a Reply Cancel reply
You must be logged in to post a comment.

- Harvard Library
- Research Guides
- Harvard Graduate School of Design - Frances Loeb Library
Write and Cite
- Using Sources and AI
- Academic Integrity
Why acknowledge sources?
When is citing necessary, citing textual sources, citing images and non-textual sources, citing generative ai, links to style guides and citation resources.
- Academic Writing
- From Research to Writing
- GSD Writing Services
- Grants and Fellowships
- Reading, Notetaking, and Time Management
- Theses and Dissertations
Reasons for citing sources are based on academic, professional, and cultural values. At the GSD, we cite to promote
- Integrity and honesty by acknowledging the creative and intellectual work of others.
- The pursuit of knowledge by enabling others to locate the materials you used.
- The development of design excellence through research into scholarly conversations related to your subject.
Cite your source whenever you quote, summarize, paraphrase, or otherwise include someone else's
- Words
- Opinions, thoughts, interpretations, or arguments
- Original research, designs, images, video, etc.
- Chicago Style
Citations follow different rules for structure and content depending on which style you use. At the GSD, mostly you will use Chicago or APA style. Often you can choose the style you prefer, but it's good to ask your professor or TA/TF. Whichever style you use, be consistent. We recommend using Zotero , a citation-management tool, to structure your citations for you, but you should always check to make sure the tool captures the correct information in the correct place.
Chicago Style
Citing print sources.
Footnote - long (first time citing the source)
1. Joseph Rykwert, The Idea of a Town: The Anthropology of Urban Form in Rome, Italy and the Ancient World , (New Jersey: Princeton University Press, 1976), 35.
Footnote - short (citing the source again)
1. Rykwert, The Idea of a Town , 35.
In-text citation (alternative to footnotes)
(Rykwert 1976, 35)
Bibliography (alphabetical order and hanging indentation)
Rykwert, Joseph. The Idea of a Town: the Anthropology of Urban Form in Rome, Italy and the Ancient World . New Jersey: Princeton University Press, 1976.
Chapter
1. Diane Favro, “The Street Triumphant: The Urban Impact of Roman Triumphal Parades,” in Streets: Critical Perspectives on Public Space , ed. Zeynep Çelik , Diana Favro, and Richard Ingersoll (Berkeley: University of California Press,1994), 153.
1. Favro, “The Street Triumphant,” 156.
In-text citation (called "author-date," an alternative to footnotes)
(Favro 1994, 153)
Bibliography (alphabetical order and hanging indentation)
Favro, Diane. “The Street Triumphant: The Urban Impact of Roman Triumphal Parades.” In Streets: Critical Perspectives on Public Space, edited by Zeynep Çelik, Diane G. Favro, and Richard Ingersoll, 151-164. Berkeley: University of California Press, 1994.
Journal Article
1. Hendrik Dey, “From ‘Street’ to ‘Piazza’: Urban Politics, Public Ceremony, and the Redefinition of platea in Communal Italy and Beyond” Speculum 91, no.4 (October 2016): 919.
1. Dey, “From ‘Street’ to ‘Piazza,’” 932.
Dey, Hendrik. “From ‘Street’ to ‘Piazza’: Urban Politics, Public Ceremony, and the Redefinition of platea in Communal Italy and Beyond.” Speculum 91, no.4 (October 2016): 919-44.
APA Style
In-text citation
(Rykwert 1976 p. 35)
Footnote (for supplemental information)
1. From The idea of a town: The anthropology of urban form in Rome, Italy and the ancient world by Joseph Rykwert, 1976, New Jersey: Princeton University Press.
Bibliography/Reference (alphabetical order and hanging indentation)
Rykwert, J. (1976). The idea of a town: The anthropology of urban form in Rome, Italy and the ancient world . Princeton University Press.
In-Text Citation
(Favro 1994 p.153)
Footnote (for supplemental information)
1. From the chapter "The street triumphant: The urban impact of Roman triumphal parades" in Streets: Critical perspectives on public space, edited by Zeynep Çelik , Diana Favro, and Richard Ingersoll, 1994, Berkeley: University of California Press.
Favro, D. (1994) “The street triumphant: The Urban Impact of Roman Triumphal Parades.” In Zeynep Çelik, Diane G. Favro, and Richard Ingersoll (Eds.), Streets: Critical Perspectives on Public Space ( pp.151-164). University of California Press.
(Dey 2016 p.919)
Footnote (for supplemental material)
1. From the article “From ‘street’ to ‘Piazza’: Urban politics, public ceremony, and the Redefinition of platea in Communal Italy and Beyond” by Hendrik Dey in Speculum 91(4), 919. www.journals.uchicago.edu/toc/spc/2016/91/4
Dey, H. (2016). From "street" to "piazza": Urban politics, public ceremony, and the redefinition of platea in communal Italy and beyond. Speculum 91 (4), 919-44. www.journals.uchicago.edu/toc/spc/2016/91/4
Citing Visual Sources
Visual representations created by other people, including photographs, maps, drawings, models, graphs, tables, and blueprints, must be cited. Citations for visual material may be included at the end of a caption or in a list of figures, similar to but usually separate from the main bibliography.
When they are not merely background design, images are labeled as figures and numbered. In-text references to them refer to the figure number. Sometimes you will have a title after the figure number and a brief descriptive caption below it.
If you choose to include the citation under the caption, format it like a footnote entry. If you would prefer to have a list of figures for citation information, organize them by figure number and use the format of a bibliographic entry.

The construction of citations for artwork and illustrations is more flexible and variable than textual sources. Here we have provided an example with full bibliographic information. Use your best judgment and remember that the goals are to be consistent and to provide enough information to credit your source and for someone else to find your source.
Some borrowed material in collages may also need to be cited, but the rules are vague and hard to find. Check with your professor about course standards.
Visual representations created by other people, including photographs, maps, drawings, models, graphs, tables, and blueprints, must be cited. In APA style, tables are their own category, and all other visual representations are considered figures. Tables and figures both follow the same basic setup.
When they are not merely background design, images are labeled as figures and numbered and titled above the image. If needed to clarify the meaning or significance of the figure, a note may be placed below it. In-text references to visual sources refer to the figure number (ex. As shown in Figure 1...").
Citations for visual material created by other people may either be included under the figure or note or compiled in a list of figures, similar to but usually separate from the main bibliography.
Figures may take up a whole page or be placed at the top or bottom of the page with a blank double-space below or above it.
If you choose to include the citation under the figure, format it like a bibliographic entry. If you would prefer to have a list of figures for citation information, organize them by figure number and use the format of a bibliographic entry. Here is a detailed example. Some figures will require less bibliographic information, but it is a good practice to include as much as you can.

The construction of citations for artwork and illustrations is more flexible and variable than for textual sources. Here we have provided an example with full bibliographic information. Use your best judgment and remember that the goals are to be consistent and to provide enough information to credit your source and for someone else to find your source.
Citing Generative AI
The rules for citing the use of generative AI, both textual and visual, are still evolving. For guidelines on when to cite the use of AI, please refer to the section on Academic Integrity. Here, we will give you suggestions for how to cite based on what the style guides say and what Harvard University encourages. We again recommend that you to ask your instructors about their expectations for use and citation and to remain consistent in your formatting.
The Chicago Manual of Style currently states that "for most types of writing, you can simply acknowledge the AI tool in your text" with a parenthetical comment stating the use of a specific tool. For example: (Image generated by Midjourney).
For academic papers or research articles, you should have a numbered footnote or endnote
Footnote - prompt not included in the text of the paper
1. ChatGPT, response to "Suggest three possible responses from community stakeholders to the proposed multi-use development project," OpenAI, March 28, 2024, https://chat.openai.com/chat.
Footnote - prompt included in the text of the paper
1. Text generated by ChatGPT, OpenAI, March 28, 2024, https://chat.oenai.com/chat
Footnote - edited AI-generated text
1. Text generated by ChatGPT, OpenAI, March 28, 2024, edited for clarity, https://chat.oenai.com/chat
In-text citation (called "author-date," an alternative to footnotes)
(Text generated by ChatGPT, OpenAI) or (Text generated by ChatGPT, OpenAI, edited for clarity)
Chicago does not encourage including generative AI in a bibliography unless the tool also generates a direct link to the same generated content.
https://www-chicagomanualofstyle-org.ezp-prod1.hul.harvard.edu/qanda/data/faq/topics/Documentation/faq0422.html
The APA style team currently says to "describe how you used the tool in your Methods section or in a comparable section of your paper," perhaps the introduction for literature reviews and response papers. In your paper, state the prompt followed by the resulting generated text. Cite generative AI use according to the rules you would use for citing an algorithm. Include the URL if it leads directly to the same generated material; otherwise, the URL is optional.
(OpenAI, 2024)
Footnote (for supplemental material)
APA does not yet provide a structure or example for a footnote. If you need to mention generative AI in a footnote, stay as consistent with formatting as possible.
OpenAI. (2024). ChatGPT (Mar 14 version) [Large language model]. https://chat.openai.com/chat
These links take you to external resources for further research on citation styles.
- Chicago Manual of Style 17th Edition Online access to the full manual through Hollis with a quick guide, Q&A, video tutorials, and more.
- CMOS Shop Talk: How Do I Format a List of Figures? A brief description of how to format a list of figures with an attached sample document.
- Documenting and Citing Images in Chicago A Research guide from USC with nice examples of images with citations.
- Harvard Guide to Citing Sources A guide from Harvard Libraries on citing sources in Chicago style.
- A Manual for Writers of Research Papers, Theses, and Dissertations: Chicago Style for Students and Researchers A Chicago manual specifically for students with clear and detailed information about citing for papers rather than publications.
- Chicago Manual of Style Q&A Citing Generative Artificial Intelligence
- APA Style The main page of the official APA website that directs you to various topics on style and formatting
- APA Style Manual 7th Edition Online access to the full APA Style Manual (scanned) through Hollis.
- APA Style Common Reference Examples A list of sample references organized by type.
- APA Style Sample Papers Links to sample papers that model how to create citations in APA.
- Formatting Checklist This page is a quick guide to all kinds of formatting, from the title page to the bibliography, with links to more detailed instructions.
- Harvard Guide to Citing Sources A guide from Harvard Libraries on citing sources in APA style.
- Journal Article References This page contains reference examples for journal articles.
- In-Text Citations in APA Style A place to learn more about rules for citing sources in your text.
- Tables and Figures This page leads to explanations about how to format tables and figures as well as examples of both.
- How to Cite ChatGPT Here are the APA's current rules for citing generative AI and ChatGPT in particular.
- << Previous: Academic Integrity
- Next: Academic Writing >>
- Last Updated: Jun 24, 2024 11:19 AM
- URL: https://guides.library.harvard.edu/gsd/write
Harvard University Digital Accessibility Policy
Ask a question, get an answer backed by real research

1.2b citation statements extracted and analyzed
187 m articles, book chapters, preprints, and datasets.
Trusted by leading Universities, Publishers, and Corporations across the world.
Read what research articles say about each other
scite is an award-winning platform for discovering and evaluating scientific articles via Smart Citations. Smart Citations allow users to see how a publication has been cited by providing the context of the citation and a classification describing whether it provides supporting or contrasting evidence for the cited claim.
Extracted citations in a report page
Never waste time looking for and evaluating research again.
Our innovative index of Smart Citations powers new features built to make research intuitive and trustworthy for anyone engaging with research.
Search Citation Statements
Find information by searching across a mix of metadata (like titles & abstracts) as well as Citation Statements we indexed from the full-text of research articles.
Create Custom Dashboards
Build and manage collections of articles of interest -- from a manual list, systematic review, or a search -- and get aggregate insights, notifications, and more.
Reference Check
Evaluate how references from your manuscript were used by you or your co-authors to ensure you properly cite high quality references.
Journal Metrics
Explore pre-built journal dashboards to find their publications, top authors, compare yearly scite Index rankings in subject areas, and more.
Large Language Model (LLM) Experience for Researchers
Assistant by scite gives you the power of large language models backed by our unique database of Smart Citations to minimize the risk of hallucinations and improve the quality of information and real references.
Use it to get ideas for search strategies, build reference lists for a new topic you're exploring, get help writing marketing and blog posts, and more.
Assistant is built with observability in mind to help you make more informed decisions about AI generated content.
Here are a few examples to try:
"How many rats live in NYC?"
"How does the structure of a protein affect its function?"
Awards & Press

Trusted by researchers and organizations around the world
Over 969,000 students, researchers, and industry experts use scite
See what they're saying

scite is an incredibly clever tool. The feature that classifies papers on whether they find supporting or contrasting evidence for a particular publication saves so much time. It has become indispensable to me when writing papers and finding related work to cite and read.
Emir Efendić, Ph.D
Maastricht University

As a PhD student, I'm so glad that this exists for my literature searches and papers. Being able to assess what is disputed or affirmed in the literature is how the scientific process is supposed to work, and scite helps me do this more efficiently.
Kathleen C McCormick, Ph.D Student

scite is such an awesome tool! It’s never been easier to place a scientific paper in the context of the wider literature.
Mark Mikkelsen, Ph.D
The Johns Hopkins University School of Medicine

This is a really cool tool. I just tried it out on a paper we wrote on flu/pneumococcal seasonality... really interesting to see the results were affirmed by other studies. I had no idea.
David N. Fisman, Ph.D
University of Toronto

Do better research
Join scite to be a part of a community dedicated to making science more reliable.
scite is a Brooklyn-based organization that helps researchers better discover and understand research articles through Smart Citations–citations that display the context of the citation and describe whether the article provides supporting or contrasting evidence. scite is used by students and researchers from around the world and is funded in part by the National Science Foundation and the National Institute on Drug Abuse of the National Institutes of Health.
Contact Info
10624 S. Eastern Ave., Ste. A-614
Henderson, NV 89052, USA
Blog Terms and Conditions API Terms Privacy Policy Contact Cookie Preferences Do Not Sell or Share My Personal Information
Copyright © 2024 scite LLC. All rights reserved.
Made with 💙 for researchers
Part of the Research Solutions Family.

Critically Thinking About “Citing Up”
Considering credibility, familiarity, and patience when citing research..
Posted June 12, 2024 | Reviewed by Davia Sills
- What Is a Career
- Find a career counselor near me
- Newer studies tend not to be referenced as frequently as more established scientific research.
- Credibility, familiarity, and implicit bias all play a role in which research gets cited more often.
- With patience and hard work, researchers can build their reputations as worthy of citation.
I came across an interesting social media post recently in preparation for a professional skills development workshop that I was presenting. The post discussed how academics tend to “cite up” in terms of referencing older, more famous scholars relative to more junior researchers. I thought about this proposition in light of my own citation strategies and knowledge of bibliometrics and concluded that this statement is likely true, but probably not for any explicit bias against junior researchers, as some might posit.
First and foremost, we must consider the purpose of citing research—to represent a source of evidence and indicate that someone didn’t just make up what they’re saying. It’s been established in previous work, and we pay that research kudos to further our argument in context. References are also useful for “ cutting a long story short”—one can cite another’s work that can more fully explain a concept without having to reiterate the whole thing. When I use a reference in my arguments, given that I’m trying to convince the reader of my point, I want to use the most credible source(s) that I can find.
Possible reasons for “citing up”
If Author A is at the apex of credible sources in the field, I’m going to cite them where appropriate. Indeed, if I was reviewing a relevant paper and didn’t see Author A cited, I might be concerned. Of course, one can include multiple citations, but perhaps the reason why more junior or early career researchers are not cited (relative to the Author As out there) is that other researchers may not be as familiar with the early career researchers”—Author Es’—research.
Maybe the citing researcher remembers the research but not the name of the author. Obviously, Author E’s work hasn’t seemed to “stick” yet, maybe because they’re yet to make a bigger impact in the field. Sure, that’s largely the citing researcher’s issue for not having better organized their reading and note-taking, but simply, it’s also an issue of accessibility. If a researcher can’t remember Author E’s name in this context, the credibility of Author A will more than suffice. “Citing up” is not a slight here; it’s just that Author E’s contribution might not be that impactful, accessible, or memorable to a more established researcher. Moreover, I must admit there might be a level of laziness here.
For example, the scenario above is context-dependent. If I can’t remember Author E, that’s fine; I have Author A to cite. However, if Author E is the only appropriate citation, the citing strategy will change. If I know a claim is fundamental to my rationale but I can’t remember where it came from, despite knowing I’ve seen solid evidence for it in the past, I will search for Author E’s paper until I find it (because I have to if there’s no Author A to rely on). This might take time and effort.
I can imagine that some researchers will be reading this and thinking, “Surely, others are reading the new literature and taking notes as they go along or maybe even writing the rationale as they engage the new literature.” Ideally, this should be the case; indeed, it’s a handy way of keeping up-to-date with the literature. However, this does not always happen.
I imagine more established researchers in a field are “familiar enough” with it to write a rationale without having to look up papers every few lines and, instead, are more likely to write what they know. Such is human nature. When they eventually get some free time, they might dedicate a few hours to reading recently published papers. I’m also aware that some researchers are better at this than others. Obviously, this is worrying in the realm of research—perhaps more worrying altogether than the issue of “citing-up.”
With that, what are the chances that a researcher has read every paper in their field? Slim-to-none. Given the exponential increase in the amount of information available to people in the past 25 years and, likewise, the increase in the amount of Ph.D. degrees awarded and research being conducted, being up-to-date with all work in a field just isn’t feasible.
So, maybe “lazy” is unfair in context. Maybe these researchers are indeed reading as much as they can, but because the amount that’s feasible is finite relative to the seemingly endless new research that’s coming out, they might be “pickier” in what they read; for example, prioritizing known and credible researchers in their field. So, there’s a good chance that when only Author A is cited regarding a particular finding, it’s quite possible that it’s because the citing researcher has never even heard of Author E’s paper, let alone read it.

Takeaways for early-career researchers
“New” papers—regardless of when and by whom they’re read, need “sticking power,” and by that, I mean that the research is well-conducted: It is well-written, and interesting food for thought is provided. I compile and read new papers every month—maybe one per session has any sticking power—and that’s not because I’m some kind of research snob; rather, it’s the case that much of it failed some of the criteria above. With that, if the paper had well-conducted research, was well-written, and provided either something novel or some food for thought, then regardless of familiarity, this paper (and its author) would be on my radar for the future. So, just as much as older researchers may be set in their bibliographies or “lazy” referencing, it is most definitely up to younger researchers to publish impactful work.
I completely understand how this is frustrating for early career researchers. I was there once, too. Even though it’s been well over 10 years since I received my Ph.D., I still find myself trying to make the aforementioned impact necessary to be considered one of those “A” researchers in the field. Of course, I get annoyed when I see missed opportunities for other researchers to cite my work. But I’m realistic enough to recognize that maybe they have not come across my work, I have not made a large enough impact for it to be noticed, or the research they did cite was sufficient to make their point. I don’t take it personally, and neither should young researchers. Their time will come, but they must be patient.
Consider the research by Morris, Wooding, and Grant (2011), where it was suggested that it takes approximately 17 years on average for health research implementation from “bench to bedside.” That’s a long time for “research to be realized.” I know citations are different and should be more visible quicker in the land of research, but the same logic applies. Patience—and continued hard work (i.e., to advance one’s research acumen)—are necessary for citation success.
Again, I don’t think that “citing up” is consciously done to slight early career academics; researchers are not conspiring against their junior colleagues—at least, not in my field. If anything, they want to see them and their field flourish. Instead, I think it’s more likely that this issue boils down to an implicit bias (which we all face on a day-to-day basis) toward what we know as familiar, accessible, and credible.
Morris, Z. S., Wooding, S., & Grant, J. (2011). The answer is 17 years, what is the question: understanding time lags in translational research. Journal of the royal society of medicine , 104 (12), 510-520.

Christopher Dwyer, Ph.D., is a lecturer at the Technological University of the Shannon in Athlone, Ireland.
- Find a Therapist
- Find a Treatment Center
- Find a Psychiatrist
- Find a Support Group
- Find Online Therapy
- United States
- Brooklyn, NY
- Chicago, IL
- Houston, TX
- Los Angeles, CA
- New York, NY
- Portland, OR
- San Diego, CA
- San Francisco, CA
- Seattle, WA
- Washington, DC
- Asperger's
- Bipolar Disorder
- Chronic Pain
- Eating Disorders
- Passive Aggression
- Personality
- Goal Setting
- Positive Psychology
- Stopping Smoking
- Low Sexual Desire
- Relationships
- Child Development
- Self Tests NEW
- Therapy Center
- Diagnosis Dictionary
- Types of Therapy

At any moment, someone’s aggravating behavior or our own bad luck can set us off on an emotional spiral that could derail our entire day. Here’s how we can face triggers with less reactivity and get on with our lives.
- Emotional Intelligence
- Gaslighting
- Affective Forecasting
- Neuroscience
Predicting citation impact of academic papers across research areas using multiple models and early citations
- Open access
- Published: 25 June 2024
Cite this article
You have full access to this open access article

- Fang Zhang 1 , 2 &
- Shengli Wu ORCID: orcid.org/0000-0003-2008-1736 1 , 3
178 Accesses
Explore all metrics
As the volume of scientific literature expands rapidly, accurately gauging and predicting the citation impact of academic papers has become increasingly imperative. Citation counts serve as a widely adopted metric for this purpose. While numerous researchers have explored techniques for projecting papers’ citation counts, a prevalent constraint lies in the utilization of a singular model across all papers within a dataset. This universal approach, suitable for small, homogeneous collections, proves less effective for large, heterogeneous collections spanning various research domains, thereby curtailing the practical utility of these methodologies. In this study, we propose a pioneering methodology that deploys multiple models tailored to distinct research domains and integrates early citation data. Our approach encompasses instance-based learning techniques to categorize papers into different research domains and distinct prediction models trained on early citation counts for papers within each domain. We assessed our methodology using two extensive datasets sourced from DBLP and arXiv. Our experimental findings affirm that the proposed classification methodology is both precise and efficient in classifying papers into research domains. Furthermore, the proposed prediction methodology, harnessing multiple domain-specific models and early citations, surpasses four state-of-the-art baseline methods in most instances, substantially enhancing the accuracy of citation impact predictions for diverse collections of academic papers.
Similar content being viewed by others

Features, techniques and evaluation in predicting articles’ citations: a review from years 2010–2023

Predicting High Impact Academic Papers Using Citation Network Features

Identification of important citations by exploiting research articles’ metadata and cue-terms from content
Avoid common mistakes on your manuscript.
Introduction
The rapid advancement of science and technology has led to a staggering increase in the number of academic publications produced globally each year (Zhu & Ban, 2018 ). In this ever-growing landscape, effectively evaluating the impact of research papers has become a critical issue (Castillo et al., 2007 ; Chakraborty et al., 2014 ; Li et al., 2019 ; Yan et al., 2011 ). Citation count, which measures the frequency with which a paper is referenced by other works, is widely recognized as the most prevalent metric for assessing the influence of academic papers, authors, and institutions (Bu et al., 2021 ; Cao et al., 2016 ; Lu et al., 2017 ; Redner, 1998 ; Stegehuis et al., 2015 ; Wang et al., 2021 ). Building upon the foundation of citation counts, numerous additional measures have been proposed to quantify research impact from various perspectives (Braun et al., 2006 ; Egghe, 2006 ; Garfield, 1972 , 2006 ; Hirsch, 2005 ; Persht, 2009 ; Yan & Ding, 2010 ).
Predicting the impact of scientific papers has garnered significant research attention due to its profound implications (Abramo et al., 2019 ; Abrishami & Aliakbary, 2019 ; Bai et al., 2019 ; Cao et al., 2016 ; Chen & Zhang, 2015 ; Li et al., 2019 ; Liu et al., 2020 ; Ma et al., 2021 ; Ruan et al., 2020 ; Su, 2020 ; Wang et al., 2013 , 2021 , 2023 ; Wen et al., 2020 ; Xu et al., 2019 ; Yan et al., 2011 ; Yu et al., 2014 ; Zhao & Feng, 2022 ; Zhu & Ban, 2018 ). See “ Citation count prediction ” section for more detailed discussion about them. Accurately forecasting the future citation impact of academic papers, particularly those recently published, offers invaluable benefits to various stakeholders within the research ecosystem. Precisely predicting the impact of papers, especially those published for a short time, would be helpful for researchers to find potentially high-impact papers and interesting research topics at an earlier stage. It is also helpful for institutions, government agencies, and funding bodies to evaluate published papers, researchers, and project proposals, among others.
For large and diverse collections encompassing papers from various research areas, a one-size-fits-all approach to citation impact prediction may be inadequate. Even within a broad field like Computing, sub-fields such as Theoretical Computing, Artificial Intelligence, Systems, and Applications can exhibit distinct citation patterns. Previous study has demonstrated that citation dynamics can vary significantly across research areas, journals, researchers in different age groups, among other factors (Kelly, 2015 ; Levitt & Thelwall, 2008 ; Mendoza, 2021 ; Milz & Seifert, 2018 ). To illustrate this point, let us consider an example from the DBLP dataset used in our study. Figure 1 a depicts the average citation distributions of papers in three research areas: Cryptography, Computer Networks, and Software Engineering. We can observe striking differences in their citation patterns:
Software Engineering papers consistently attract relatively few citations over time, without a pronounced peak in their citation curve.
Artificial Intelligence papers garner the highest citation counts among the three areas. Their citation curve rises rapidly, peaking around year 4, followed by a gradual decline until year 7, after which the decrease becomes more precipitous.
Cryptography papers exhibit a steadily increasing citation trend over the first 10 years, reaching a peak around year 11, followed by a slow decline in citations thereafter.

Citation patterns in different research areas or different classes of the same research area
These divergent citation patterns across research areas highlight the limitations of employing a single, universal model for citation impact prediction. In light of these observations, a more effective strategy would be to segment papers into distinct groups based on their research areas and develop tailored prediction models for each group. By accounting for the unique citation characteristics of different domains, such a group-specific modelling approach has the potential to significantly enhance the accuracy and reliability of citation impact predictions, particularly for large and heterogeneous collections of academic papers.
Citation patterns are not solely determined by research areas but also influenced by the quality and intrinsic characteristics of individual papers. Even within the same research area, the citation dynamics of papers can vary considerably (Garfield, 2006 ; Wang et al., 2021 ; Yan & Ding, 2010 ). High-impact papers may exhibit significantly different citation trajectories compared to average or low-impact works. Accounting for these differences by employing multiple models tailored to papers with varying citation potential could further improve prediction performance. Figure 1 b illustrates this phenomenon using an example from the Embedded & Real-Time Systems research area. All papers in this domain can be categorized into four classes based on their cumulative citation counts ( cc ) over 15 years: cc < 10, 10 ≤ cc < 50, 50 ≤ cc < 100, and cc ≥ 100. The general pattern observed for all the curves is that they initially increase for a few years and then decrease afterwards. However, the peak point varies depending on the total number of citations. Papers with higher citation counts take more years to reach their peak point. This finding suggests that class-based prediction can be a viable approach for our prediction task, as it account for the varying peak times based on the citation count classes.
If all of the papers are not classified, then it is necessary to have a classification system that encompasses multiple categories and an automated method for allocating each paper into one or more suitable categories. For a large collection of papers to be classified, both the effectiveness and efficiency of the allocating method are crucial factors to consider.
Taking into account all the observations mentioned earlier, we propose MM, a prediction method based on Multiple Models tailored for different research areas and citation counts, to predict the future citation counts of a paper. This work makes the following contributions:
A new instance-based learning method is introduced to classify papers into a given number of research areas. Both paper contents (titles and abstracts) and citations are considered separately. An ensemble-based method is then employed to make the final decision. Experiments with the DBLP dataset demonstrate that the proposed method can achieve excellent classification performance.
A prediction method for paper citation counts is proposed. For any paper to be predicted, a suitable prediction model is chosen based on its research area and early citation history. This customized approach enables each document to use a fitting model.
Experiments with two datasets show that the proposed prediction method outperforms four baseline methods in this study, demonstrating its superiority.
The remainder of this article is structured as follows: “ Related work ” section reviews related work on citation count prediction and classification of academic papers. “ Methodology ” section describes the proposed method in detail. “ Experimental settings and results ” section presents the experimental settings, procedures, and results, along with an analysis of the findings. Finally, “ Conclusion ” section concludes the paper.
Related work
In this work, the primary task is citation count prediction of papers, while classification of scientific papers serves as an additional task that may be required for the prediction task. Accordingly, we review some related work on citation count prediction and classification of academic papers separately in the following sections.
- Citation count prediction
In the literature, there are numerous papers on predicting the citation counts of scientific papers. These methods can be categorized into three groups based on the information used for prediction.
The first group relies solely on the paper’s citation history as input. Wang et al. ( 2013 ) developed a model called WSB to predict the total number of citations a paper will receive, assuming its earlier citation data is known. Cao et al. ( 2016 ) proposed a data analytic approach to predict the long-term citation count of a paper using its short-term (three years after publication) citation data. Given a large collection of papers C with long citation histories, for a paper p with a short citation history, they matched it with a group of papers in C with similar early citation data and then used those papers in C to predict p’s later citation counts. Abrishami and Aliakbary ( 2019 ) proposed a long-term citation prediction method called NNCP based on Recurrent Neural Network (RNN) and the sequence-to-sequence model. Their dataset comprised papers published in five authoritative journals: Nature, Science, NEJM (The New England Journal of Medicine), Cell, and PNAS (Proceedings of the National Academy of Sciences). Wang et al. ( 2021 ) introduced a nonlinear predictive combination model, NCFCM, that utilized multilayer perceptron (MLP) to combine WSB and an improved version of AVR for predicting citation counts.
The second group uses not only the citation data but also some other extracted features from the paper or the wider academic network for the prediction task. Yu et al. ( 2014 ) adopted a stepwise multiple regression model using four groups of 24 features, including paper, author, publication, and citation-related features. Bornmann et al. ( 2014 ) took the percentile approach of Hazen ( 1914 ), considering the journal’s impact and other variables such as the number of authors, cited references, and pages. Castillo et al. ( 2007 ) used information about past papers written by the same author(s). Chen and Zhang ( 2015 ) applied Gradient Boosting Regression Trees (GBRT) with six paper content features and 10 author features. Bai et al. ( 2019 ) made long-term predictions using the Gradient Boosting Decision Tree (GBDT) model with five features, including the citation count within 5 years after publication, authors’ impact factor, h-index, Q value, and the journal's impact factor. Akella et al. ( 2021 ) exploited 21 features derived from social media shares, mentions, and reads of scientific papers to predict future citations with various machine learning models, such as Random Forest, Decision Tree, Gradient Boosting, and others. Xu et al. ( 2019 ) extracted 22 features from heterogeneous academic networks and employed a Convolutional Neural Network (CNN) to capture the complex nonlinear relationship between early network features and the final cumulative citation count. Ruan et al. ( 2020 ) employed a four-layer BP neural network to predict the 5th year citation counts of papers, using a total of 30 features, including paper, author, publication, reference, and early citation-related features. By extracting high-level semantic features from metadata text, Ma et al. ( 2021 ) adopted a neural network to consider both semantic information and the early citation counts to predict long-term citation counts. Wang et al. ( 2023 ) applied neural network technology to a heterogeneous network including author and paper information. Huang et al. ( 2022 ) argued that citations should not be treated equally, as the citing text and the section in which the citation occurs significantly impact its importance. Thus, they applied deep learning models to perform fine-grained citation prediction—not just citation count for the whole paper but citation count occurring in each section.
The third group uses other types of information beyond those mentioned above. To investigate the impact of peer-reviewing data on prediction performance, Li et al. ( 2019 ) adopted a neural network prediction model, incorporating an abstract-review match method and a cross-review match mechanism to learn deep features from peer-reviewing texts. Combining these learned features with breadth features (topic distribution, topic diversity, publication year, number of authors, and average author h-index), they employed a multilayer perceptron (MLP) to predict citation counts. Li et al. ( 2022 ) also utilized peer-reviewing text for prediction, using an aspect-aware capsule network. Zhao and Feng ( 2022 ) proposed an end-to-end deep learning framework called DeepCCP, which takes an early citation network as input and predicts the citation count using both GRU and CNN, instead of extracting features.
Citation counts of a paper can be affected by many factors such as research areas, paper types, age, sex, and other aspects of the authors (Andersen & Nielsen, 2018 ; Mendoza, 2021 ; Thelwall, 2020 ). Levitt and Thelwall ( 2008 ) compared patterns of annual citations of highly cited papers across six research areas. To our knowledge, Abramo et al. ( 2019 ) is the only work that uses multiple regression models for prediction, with one model for each subject category. Abramo et al. ( 2019 ) is the most relevant to our work in this article. However, there are two major differences. First, we propose a paper classification method in this paper, while no paper classification is required in Abramo et al. ( 2019 ). Second, we apply multiple models for papers in each category, whereas only one model is used for each category in Abramo et al. ( 2019 ).
Classification of scientific papers
Classification of scientific papers becomes a critical issue when organizing and managing an increasing number of publications through computerized solutions. In previous research, typically, meta-data such as title, abstract, keywords, and citations of papers were used for this task, while full text was not considered due to its unavailability in most situations.
Various machine learning methods, such as K-Nearest Neighbors (Lukasik et al., 2013 ; Waltman & Van Eck, 2012 ), K-means (Kim & Gil, 2019 ), and Naïve Bayes (Eykens et al., 2021 ), have been applied. Recently, deep neural network models, such as Convolutional Neural Networks (Daradkeh et al., 2022 ; Rivest et al., 2021 ), Recurrent Neural Networks (Hoppe et al., 2021 ; Semberecki & Maciejewski, 2017 ), and pre-trained language models (Hande et al., 2021 ; Kandimalla et al., 2020 ), have also been utilized.
One key issue is the classification system to be used. There are many different classification systems. Both Thomson Reuters’ Web of Science database (WoS) and Elsevier’s Scopus database have their own general classification systems, covering many subjects/research areas. Some systems focus on one particular subject, such as the medical subject headings (MeSH), the physics and astronomy classification scheme (PACS), the Chemical Abstracts Sections, the journal of economic literature (JEL), and the ACM Computing Classification System.
Based on the WoS classification system, Kandimalla et al. ( 2020 ) applied a deep attentive neural network (DANN) to a collection of papers from the WoS database for the classification task. It was assumed that each paper belonged to only one category, and only abstracts were used.
Zhang et al. ( 2022 ) compared three classification systems: Thomson Reuters’ Web of Science, Fields of Research provided by Dimensions, and the Subjects Classification provided by Springer Nature. Among these, the second one was generated by machine learning methods automatically, while the other two were generated manually by human experts. It is found there are significant inconsistency between machine and human-generated systems.
Rather than using an existing classification system, some researchers build their own classification system using the collection to be classified or other resources such as Wikipedia.
Shen et al. ( 2018 ) organized scientific publications into a hierarchical concept structure of up to six levels. The first two levels (similar to areas and sub-areas) were manually selected, while the others were automatically generated. Wikipedia pages were used to represent the concepts. Each publication or concept was represented as an embedding vector, thus the similarity between a publication and a concept could be calculated by the cosine similarity of their vector representations. It is a core component for the construction of the Microsoft Academic Graph.
In the same vein as Shen et al. ( 2018 ), Toney-Wails and Dunham ( 2022 ) also used Wikipedia pages to represent concepts and build the classification system. Both publications and concepts were represented as embedding vectors. Their database contains more than 184 million documents in English and more than 44 million documents in Chinese.
Mendoza et al. ( 2022 ) presented a benchmark corpus and a classification system as well, which could be used for the academic paper classification task. The classification system used is the 36 subjects defined in the UK Research Excellent Framework. Footnote 1 According to Cressey and Gibney ( 2014 ), this practice is the largest overall assessment of university research outputs ever undertaken globally. The 191,000 submissions to REF 2014 comprise a very good data set because every paper was manually categorized by experts when submitted.
Liu et al. ( 2022 ) described the NLPCC 2022 Task 5 Track 1, a multi-label classification task for scientific literature, where one paper may belong to multiple categories simultaneously. The data set, crawled from the American Chemistry Society’s publication website, comprises 95,000 papers’ meta-data including titles and abstracts. A hierarchical classification system, with a maximum of three levels, was also defined.
As we can see, the classification problem of academic papers is quite complicated. Many classification systems and classification methods are available. However, classification systems and classification methods are related to each other. The major goal of this work is to perform citation count prediction of published papers, in which classification of papers is a basic requirement. For example, considering the DBLP dataset which includes over four million papers, special consideration is required to perform the classification task effectively and efficiently. We used the classification system from CSRankings, Footnote 2 which included a set of four categories (research areas) and 26 sub-categories in total. A group of top venues were identified for each sub-category. However, many more venues in DBLP are not assigned to any category. We used all those recommended venue papers in the CSRankings system as representative papers of a given research area. An instance-based learning approach was used to measure the semantic similarity of the target paper and all the papers in a particular area. A decision could be made based on the similarity scores that the target paper obtained for all research areas. Besides, citation data between the target paper and all the papers in those recommended venues is also considered. Quite different from those proposed classification methods before, this instance-based learning approach suits our purpose well. See “ Methodology ” section for more details.
Methodology
This research aims to predict the number of citations of academic papers in the next couple of years based on their metadata including title, abstract and citation data since publication. The main idea of our approach is: for a paper, depends on its research area and early citation count, we use a specific model to make the prediction. There are two key issues. Academic paper classification and citation count prediction methods. Let us detail them one by one in the following subsections.
Computing classification system
To carry out the classification task of academic papers, a suitable classification system is required. There are many classification systems available for natural science, social science, humanities, or specific branches of science or technology. Since one of the datasets used in this study is DBLP, which includes over four million papers on computer science so far, we will focus our discussion on classification systems and methods for computer science.
In computer science, there are quite a few classification systems available. For example, both the Association for Computing Machinery (ACM) and the China Computer Federation (CCF) define their own classification systems. However, both are not very suitable for our purpose. The ACM’s classification system is quite complicated, but it does not provide any representative venues for any of the research areas. The CCF defines 10 categories and recommends dozens of venues in each category. However, some journals and conferences publish papers in more than one category, but they are only recommended in one category. For instance, both the journals IEEE Transactions on Knowledge and Data Engineering and Data and Knowledge Engineering publish papers on Information Systems and Artificial Intelligence, but they are only recommended in the Database/Data Mining/Content Retrieval category.
In this research, we used the classification system from CSRankings. This system divides computer science into four areas: AI, System, Theory, and Interdisciplinary Areas. Then, each area is further divided into several sub-areas, totalling 26 sub-areas. We flatten these 26 sub-areas for classification, while ignoring the four general areas at level one. One benefit of using this system is that it lists several key venues for every sub-area. For example, three venues are identified for Computer Vision: CVPR (IEEE Conference on Computer Vision and Pattern Recognition), ECCV (European Conference on Computer Vision), and ICCV (IEEE International Conference on Computer Vision). This is very useful for the paper classification task, as we will discuss now.
Paper classification
For this research, we need a classification algorithm that can perform the classification task for all the papers in the DBLP dataset effectively and efficiently.
Although many classification methods have been proposed, we could not find a method that suits our case well. Therefore, we developed our own approach. Using the classification system of CSRankings, we assume that all the papers published in those identified venues belong to that given research area, referred to as seed papers. For all the non-seed papers, we need to decide the areas to which they belong. This is done by considering three aspects together: content, references, and citations. Let us look at the first aspect first.
The collection of all the seed papers, denoted as C , was indexed using the Search engine Lucene Footnote 3 with the BM25 model. Both titles and abstracts were used in the indexing process. Each research area \({a}_{k}\) is presented by all its seed papers C ( \({a}_{k}\) ). For a given non-seed paper p , we use its title and abstract as a query to search for similar papers in C . Then each seed paper s will obtain a score (similarity between p and s )
in which b 1 and b 2 are two parameters (set to 0.75 and 1.2, respectively, as default setting values of Lucene in the experiments), T s is the set of all the terms in s , \(AL(C)\) is the average length of all the documents in C , \(f\left({t}_{j},s\right)\) is the term frequency of \({t}_{j}\) in s , \(idf\left({t}_{j}\right)\) is the inverse document frequency of \({t}_{j}\) in collection C with all the seed papers. \(idf\left({t}_{j}\right)\) is defined as
in which \(\left|C\right|\) is the number of papers in \(C\) , and \(\left|C({t}_{j})\right|\) is the number of papers in C satisfying the condition that \({t}_{j}\) appears in them. For a paper p and a research area \({a}_{k}\) , we can calculate the average similarity score between p and all the seed papers in C ( \({a}_{k}\) ) as
where C ( \({a}_{k}\) ) is the collection of seed papers in area \({a}_{k}\) .
We also consider citations between \(p\) and any of the papers in C . Citations in two different directions are considered separately: \(citingNum\left( p,{a}_{k}\right)\) denotes the number of papers in C ( \({a}_{k}\) ) that p cites, and \(citedNum\left(p,{a}_{k}\right)\) denotes the number of papers in C ( \({a}_{k}\) ) that cites p . Now we want to combine the three features. Normalization is required. For example, \(sim\left({p,a}_{k}\right)\) can be normalized by
in which \(RA\) is the set of 26 research areas. \(citingNum\left(p,{a}_{k}\right)\) and \(citedNum\left(p,{a}_{k}\right)\) can be normalized similarly. Then we let
for any \({a}_{k}\in RArea\) , in which \({\beta }_{1}\) , \({\beta }_{2}\) , and \({\beta }_{3}\) are three parameters. When applying Eq. 5 to \(p\) and all 26 research areas, we may obtain corresponding scores for each area. p can be put to research area \({a}_{k}\) if \(score\left(p,{a}_{k}\right)\) is the biggest among all 26 scores for all research areas. The values of \({\beta }_{1}\) , \({\beta }_{2}\) , and \({\beta }_{3}\) are decided by Euclidean Distance with multiple linear regression with a training data set (Wu et al., 2023 ). Compared with other similar methods such as Stacking with MLS and StackingC, this method can achieve comparable performance but much more efficient than the others. It should be very suitable for large-scale datasets.
In this study, we assume that each paper just belongs to one of the research areas. If required, this method can be modified to support multi-label classification, then a paper may belong to more than one research area at the same time. We may set a reasonable threshold \(\tau\) , and for any testing paper \(p\) and research area \({a}_{k}\) , if \(score\left(p,{a}_{k}\right)>\tau\) , then paper \(p\) belongs to research area \({a}_{k}\) . However, this is beyond the scope of this research, and we leave it for further study.
In summary, the proposed classification algorithm instance-based learning (IBL) is sketched as follows:

As we observed that papers in the same research area may have different citation patterns, it is better to treat them using multiple prediction models rather than one unified model. Therefore, for all the papers in a research area, we divide them into up to 10 groups according to the number of citations already obtained in the first m years. In a specific research area, for a group of papers considered, we count the number of citations they obtained during a certain period. We use cc ( i ) to represent the number of papers cited i times, where i ranges from 0 to n .
A threshold of 100 is set. We consider the values of cc (0), cc (1),…, cc ( n ) in order. If cc (0) is greater than or equal to the threshold, we create a group with those papers that received zero citations. Otherwise, we combine cc (0) with cc (1), and if the sum is still less than the threshold, we continue adding the next value cc (2), and so on, until the cumulative sum reaches or exceeds the threshold. At this point, we create a group with all the papers contributing to that cumulative sum. We then move on to the next unassigned value of cc ( i ) and repeat the process, creating new groups until all papers are assigned to a group. The last group may contain fewer than 100 papers, but it is still considered a valid group.
A regression model is set for each of these groups for prediction. For the training data set, all the papers are classified by research area with known citation history of up to t years. For all the papers belonging to a group \({g}_{i}\) inside a research area \({a}_{k}\) , we put their information together. Consider
\({c}_{0}\) , \({c}_{1}\) , …, \({c}_{m}\) , and \({\text{c}}_{t}\) are citation counts of all the papers involved up to year 0, 1,…, m , and in year t ( t ≥ m ). We can train the weights \({\text{w}}_{0}\) , \({\text{w}}_{1}\) ,…, \({\text{w}}_{m}\) , and b for this group by multiple linear regression using \({c}_{0}\) , \({c}_{1}\) , …, \({c}_{m}\) as independent variables and \(c^{\prime}_{t}\) as the target variable. The same applies to all other groups and research areas.
To predict the future citation counts of a paper, we need to decide which research area and group that paper should be in. Then the corresponding model can be chosen for the prediction. Algorithm MM is sketched as follows:

Note that classification and citation count prediction are two separate tasks. When performing the citation count prediction task, it is required that all the papers involved should have a research area label. Such a requirement can be satisfied in different ways. For example, in the WoS system, it has a list of journals, and each journal is assigned to one or two research areas. All the papers published in those journals are classified by the journals publishing them. In arXiv, an open-access repository of scientific papers, all the papers are assigned a research area label by the authors when uploading them. When performing the citation count prediction task on such datasets, we do not need to do anything else. However, for papers in DBLP, all the papers are not classified. It is necessary to classify them in some way before we can perform citation count prediction for all the papers involved. In this study, we proposed an instance-based learning approach, which provides an efficient and effective solution to this problem.
Experimental settings and results
Two datasets were used for this study. One is a DBLP dataset, and other is an arXiv dataset.
We downloaded a DBLP dataset (Tang et al., 2008 ). Footnote 4 It contains 4,107,340 papers in computer science and 36,624,464 citations from 1961 to 2019. For every paper, the dataset provides its metadata, such as title, abstract, references, authors and their affiliations, publication year, the venue in which the paper was published, and citations since publication. Some subsets of it were used in this study.
For the classification part, we used two subsets of the dataset. The first one ( C 1 ) is all the papers published in those 72 recommended venues in CSRankings between 1965 and 2019. There are 191,727 papers. C 1 is used as seed papers for all 26 research areas. The second subset ( C 2 ) includes 1300 papers, 50 for each research area. Those papers were randomly selected from a group of 54 conferences and journals and judged manually. C 2 is used for the testing of the proposed classification method.
For the prediction part, we also used two subsets. One subset for training and the other for testing. The training dataset ( C 3 ) includes selected papers published between 1990 and 1994, and the testing dataset ( C 4 ) includes selected papers published in 1995. For all those papers between 1990 and 1994 or in 1995, we removed those that did not get any citation and those with incomplete information. After such processing, we obtain 38,247 papers for dataset C 3 , and 9967 papers for dataset C 4 .
We also downloaded an arXiv dataset (Saier and Farber, 2020 ). Footnote 5 It contains 1,043,126 papers in many research areas including Physics, Mathematics, Computer Science, and others, with 15,954,664 citations from 1991 to 2022. For every paper, its metadata such as title, abstract, references, authors and affiliations, publication year, and citations since publication was provided. Importantly, each paper is given a research area label by the authors. Therefore, it is no need to classify papers when we use this dataset for citation count prediction. Two subsets were generated in this study. One subset for training and the other for testing. The training dataset ( C 5 ) includes all the papers published between 2008 and 2013, and the testing dataset ( C 6 ) includes all the papers published in 2014. There are 5876 papers in dataset C 5 and 1471papers in dataset C 6 .
Classification results
In the CSRankings classification system, there are a total of 26 special research areas. A few top venues are recommended for each of them. We assume that all the papers published in those recommended conferences belong to the corresponding research area solely. For example, three conferences CVPR, ECCV, and ICCV are recommended for Computer Vision. We assume that all the papers published in these three conferences belong to the Computer Vision research area but no others.
To evaluate the proposed method, we used a set of 1300 non-seed papers ( C 2 ). It included 50 papers for each research area. All of them were labelled manually. In Eq. 5 , three parameters need to be trained. Therefore, we divided those 1300 papers into two equal partitions of 650, and each included the same number of papers in every research area. Then the two-fold cross-validation was performed. Table 1 shows the average performance.
We can see that the proposed method with all three features, content similarity (Sim), citation to other papers (To evaluate the proposed method, we used a set of 1300 non-seed papers ( C 2 ). It included 50 papers for each research area. All of them were labelled manually. In Eq. 5 , three parameters need to be trained. Therefore, we divided those 1300 papers into two equal partitions of 650, and each included the same number of papers in every research area. Then the two-fold cross-validation was performed. Table 1 shows the average performance.
We can see that the proposed method with all three features, content similarity ( \(sim\) ), citation to other papers ( \(citingNum\) ), and citation by others ( \(citedNum\) ), are useful for the classification task. Roughly citation in both directions ( \(citingNum+citedNum\) ) and content similarity ( \(sim\) ) have the same ability. Considering three features together, we can obtain an accuracy, or an F-measure, of approaching 0.8. We are satisfied with this solution. On the one hand, its classification performance is good compared with other methods in the same category, e.g., (Ambalavanan & Devarakonda, 2020 ; Kandimalla et al., 2020 ). In Kandimalla et al. ( 2020 ), F-scores across 81 subject categories are between 0.5 and 0.8 (See Fig. 1 in that paper). In Ambalavanan and Devarakonda ( 2020 ), the four models ITL, Cascade Learner, Ensemble-Boolean, and Ensemble-FFN obtain an F-score of 0.553, 0.753, 0.628, and 0.477, respectively, on the Marshall dataset they experimented with (see Table 4 in their paper). Although those results may not be comparable since the datasets used are different, it is an indicator that our method is very good. Besides, our method can be implemented very efficiently. When the seed papers are indexed, we can deal with a large collection of papers very quickly with very little resource. The method is very scalable.
Setting for the prediction task
For the proposed method MM, we set 10 as the number of groups in each research area for the DBLP dataset, and 5 for the arXiv dataset. This is mainly because the arXiv dataset is smaller and has fewer papers in each research area.
Apart from MM, five baseline prediction methods were used for comparison:
Mean of early years (MEY). It is a simple prediction function which returns the average of early citations of the paper as its predicted citations in the future (Abrishami & Aliakbary, 2019 ).
AVR. Assume that there is a collection of papers with known citation history as the training data set. For a given paper for prediction, this method finds a group of most similar papers in the training set relating to their early citations (with the minimal sum of the squared citation count difference over the years), and then utilizes the average citations of those similar papers in the subsequent years as the predicted citation counts of the paper (Cao et al., 2016 ).
RNN adopts a Recurrent Neural Network to predict papers’ future citation counts based on their early citation data (Abrishami & Aliakbary, 2019 ).
OLS. Linear regression is used for the prediction model (Abramo et al., 2019 ). There are four variants. Both OLS_res and OLS_log only use early citations as independent variables in their prediction models, while OLS2_res and OLS2_log use early citations and impact factors of journals in their prediction models. OLS_res and OLS2_res apply a linear regularization to their early citations, while OLS_log and OLS2_log apply a logarithmic regularization to their early citations.
NCFCM adopts a neural network to predict papers’ future citation counts based on early citation data and two simple prediction model data (Wang et al., 2021 ).
Evaluation metrics
Two popular metrics are used to evaluate the proposed method and compare it with the baselines: mean square error (MSE) and the coefficient of determination (R 2 ). For a given set of actual values Y \(=\{{y}_{1},{y}_{2},\dots ,{y}_{n}\}\) and set of predicted values \(\widehat{Y\boldsymbol{ }}=\{{\widehat{y}}_{1},{\widehat{y}}_{2},\dots ,{\widehat{y}}_{n}\}\) , MSE and R 2 are defined as follows:
where \({\overline{y} }_{i}\) is the average of all n values in y . MSE measures the variation of the predicted values from the actual values, thus smaller values of MSE are desirable. R 2 measures the corelation between the predicted values and actual values, and its value is between 0 and 1, where R 2 = 0 means no correlation, R 2 = 1 means a perfect positive correlation between the predicted values and the actual values, thus larger values of R 2 are desirable.
Evaluation results
Evaluation has been carried out on two different aspects: overall performance for all the papers and for 100 highly citated papers.
Overall prediction performance
For papers with 0–5 years of citation history, we predict their citation counts in three continuous years in the future. The results are shown in Tables 2 , 3 , 4 , 5 , 6 , 7 . “Zero years of early citation data” means that the prediction was made in the same year as the paper was published. “One year of early citation data” means that the prediction was made in the next year as the paper was published. The number in bold indicates the best performance.
One can see that MM performs the best in most cases. In a few cases, OLS2_res performs the best. This is because OLS2_res considers both the paper’s early citation history and the journal’s impact factor, and the latter is not considered in any other method. In this way, it gives OLS2_res some advantages, especially when the citation history is very short. In a few cases, RNN performs the best on the arXiv dataset. In one case, AVE and NCFCM tied for first place in R 2 . Because linear regression is used in both OLS_res and MM, a comparison between them is able to show that dividing papers into multiple research areas is a very useful strategy for us to obtain better prediction performance. See “ Ablation Study of MM ” section for further experiments and analysis.
Prediction performance of highly cited papers
An important application of citation prediction is the early detection of highly cited papers (Abrishami & Aliakbary, 2019 ). Therefore, we evaluate the performance of the proposed method and its competitors in predicting highly cited papers. Based on the total citation counts in 2000 (DBLP) and in 2019 (arXiv), 100 most cited papers were selected for prediction. For all the papers involved, we compute the MSE values between the predicted citation counts and the actual citation counts of them. The results are shown in Table 8 .
From Table 8 , one can see that MM performs better than all the others, except when k = 0 (which means zero years of early citation data) OLS2_res performs slightly better than MM in the DBLP dataset. In all other cases, MM outperforms the competing methods.
Ablation study of MM
MM mainly incorporates two factors including research area and early citation counts into consideration. It is desirable to find how these two factors impact prediction performance. Another angle is the number of groups divided in each research area. To find out the impact of these features on prediction performance, we define some variants that implement none or one of the features of MM.
MM-RA (RA). A variant of the MM algorithm that only considers research area but not early citation counts.
MM-CC (CC). A variant of the MM algorithm that only considers early citation counts.
MM-5. A variant of the MM algorithm that divides all the papers in the area into 5 instead of 10 groups.
MEY. It is a simplest variant of MM. It considers neither research area nor early citation counts.
Now let us have a look at how these variants perform compared with the original algorithm. See Tables 9 , 10 , 11 , 12 , 13 , 14 , 15 for the results. It is not surprising that MM performs better than three variants of MM including RA, CC and MEY, while MEY, the variant with none of the two components, performs the worst in predicting the citation counts of papers. Such a phenomenon demonstrates that both components including research area and early citation counts are useful for prediction performance, either used separately or in combination. However, the usefulness of these two components is not the same. The performance of CC is not as good as RA when k = 0 and k = 1, but better than RA when k > 1. Understandably, this indicates that RA is a more useful resource than citation history when the citation history is short, but the latter becomes more and more useful when the citation history becomes longer.
When applying the standard MM algorithm, we divide all the papers in one research area into 10 groups based on the number of citations they obtain in the early years. MM-5 reduces the number of groups from 10 to 5 simply by combining two neighbouring groups to one. MM is better than MM-5 in most cases and on average. The difference between them is small in most cases. However, it is noticeable that MM-5 performs better than MM in two cases, mainly because the size of some of the groups is very small, and the prediction based on such small groups is not very accurate.
Impact of classification on MM
For the DBLP dataset, some papers were classified automatically through the venues in which they were published, while many others were classified through the classification method IBL. It would be interesting to make a comparison of these two groups when performing the prediction task. The results are shown in Table 16 We can see that the group of non-seed papers gets better perdition results than the group of seed papers by a clear margin in all the cases. This demonstrates that the two methods IBL and MM can work together well for achieving good prediction results. On the other hand, such a result is a little surprising. Why can the non-seed group perform better than the seed group? One major reason is for the citation count prediction task, MSE values and citation counts have a strong positive correlation. In this case, there are 2346 seed papers ( C 7 ), whose average citation count is 6.339, while there are 7621 non-seed papers ( C 8 ), whose average citation count is 3.085. These two groups are not directly comparable because of the difference in average citation counts. Note that C 4 = C 7 + C 8 (see “ Datasets ” section for C 4 ’s definition).
To make the comparison fair to both parties, we select a subgroup from each of them by adding a restriction: those papers obtain a citation count in the range of [10,20] by the year 2000. We obtain 318 papers ( C 9 ) from the seed paper group and 418 papers ( C 10 ) from the non-seed paper group. Coincidentally, the average citation counts for both sub-groups are the same: 13.443. This time, the two groups are in a perfect condition for a comparison. Table 17 shows the results. Not surprisingly, those MSE value pairs are very close. It demonstrates that for papers either classified by our classification algorithm IBL, or categorized by recommended top venues, the prediction is equally good. It also implies that IBL can perform the classification work properly.
Different from previous studies, this paper applies multiple models to predict the citation counts of papers in the next couple of years, and each model fits a special research area and early citation history of the paper in question. The rationale behind this is: in general, papers in different research areas and with different early citation counts have their own citation patterns. To verify the prediction performance of the proposed method, we have tested it with two datasets taken from DBLP and arXiv. The experimental results show that the proposed MM method outperforms all the baseline methods involved in most cases in two tasks: the overall prediction performance of a large collection of paper and prediction performance of a group of highly cited papers.
As an important component of prediction for research papers, we have also presented a novel instance-based learning model for classification of research papers. By predefining a small group of papers in each category, the proposed method can classify new papers very efficiently with good accuracy.
As our future work, we would incorporating other types of information such as publication venues and author information. Then, prediction performance can be further improved. Secondly, we plan to explore using some deep learning methods for research paper classification. For example, such methods can be used to compare the content similarity of two research papers.
https://ref.ac.uk/2014/
https://CSRankings.org
https://lucene.apache.org
https://www.aminer.cn/
http://doi.org/10.5281/zenodo.3385851
Abramo, G., D’Angelo, C., & Felici, G. (2019). Predicting publication long-term impact through a combination of early citations and journal impact factor. Journal of Informetrics, 13 (1), 32–49.
Article Google Scholar
Abrishami, A., & Aliakbary, S. (2019). Predicting citation counts based on deep neural network learning techniques. Journal of Informetrics, 13 (2), 485–499.
Akella, A., Alhoori, H., Kondamudi, P., et al. (2021). Early indicators of scientific impact: Predicting citations with altmetrics. Journal of Informetrics, 15 (2), 101128.
Ambalavanan, A. K., & Devarakonda, M. V. (2020). Using the contextual language model BERT for multi-criteria classification of scientific articles. Journal of Biomedical Informatics, 112 , 103578.
Andersen, J. P., & Nielsen, M. W. (2018). Google Scholar and Web of Science: Examining gender differences in citation coverage across five scientific disciplines. Journal of Informetrics, 12 (3), 950–959.
Bai, X., Zhang, F., & Lee, I. (2019). Predicting the citations of scholarly paper. Journal of Informetrics, 13 (1), 407–418.
Bornmann, L., Leydesdorff, L., & Wang, J. (2014). How to improve the prediction based on citation impact percentiles for years shortly after the publication data? Journal of Informetrics, 8 (1), 175–180.
Braun, T., Glänzel, W., & Schubeert, A. (2006). Hirsch-type index for journals. Scientometrics, 69 (1), 169–173.
Bu, Y., Lu, W., Wu, Y., Chen, H., & Huang, Y. (2021). How wide is the citation impact of scientific publications? A cross-discipline and large-scale analysis. Information Processing & Management, 58 (1), 102429.
Cao, X., Chen, Y., & Liu, K. (2016). A data analytic approach to quantifying scientific impact. Journal of Informetrics, 10 (2), 471–484.
Castillo, C., Donato, D., & Gionis, A. (2007). Estimating number of citations using author reputation. String processing and information retrieval (pp. 107–117). Berlin: Springer.
Chapter Google Scholar
Chakraborty, T., Kumar, S., Goyal, P., Ganguly, N., & Mukherjee, A. (2014). Towards a stratified learning approach to predict future citation counts. In IEEE/ACM joint conference on digital libraries (pp. 351–360). IEEE.
Chen, J., & Zhang, C. (2015). Predicting citation counts of papers. In 2015 IEEE 14th international conference on cognitive informatics & cognitive computing (ICCI* CC) (pp. 434–440). IEEE.
Cressey, D., & Gibney, E. (2014). UK releases world’s largest university assessment. Nature . https://doi.org/10.1038/nature.2014.16587
Daradkeh, M., Abualigah, L., Atalla, S., & Mansoor, W. (2022). Scientometric analysis and classification of research using convolutional neural networks: A case study in data science and analytics. Electronics, 11 (13), 2066.
Egghe, L. (2006). Theory and practice of the g-index. Scientometrics, 69 (1), 131–152.
Eykens, J., Guns, R., & Engels, T. (2021). Fine-grained classification of social science journal articles using textual data: A comparison of supervised machine learning approaches. Quantitative Science Studies, 2 (1), 89–110.
Garfield, E. (1972). Citation analysis as a tool in journal evaluation. Science, 178 (4060), 471–479.
Garfield, E. (2006). The history and meaning of the journal impact factor. JAMA, 295 (1), 90–93.
Hande, A., Puranik, K., Priyadharshini, R., & Chakravarthi, B. (2021). Domain identification of scientific articles using transfer learning and ensembles. PAKDD, 2021 , 88–97.
Google Scholar
Hazen, A. (1914). Storage to be provided in impounding reservoirs for municipal water supply. Transactions of American Society of Civil Engineers, 77 (1914), 1539–1640.
Hirsch, J. (2005). An index to quantify an individual’s scientific research output. Proceedings of the National Academy of Science of the United States of America, 102 (46), 16569–16572.
Hoppe, F., Dessì, D., & Sack, H. (2021). Deep learning meets knowledge graphs for scholarly data classification. WWW (companion Volume), 2021 , 417–421.
Huang, S., Huang, Y., Bu, Y., et al. (2022). Fine-gained citation count prediction via a transformer-based model with among-attention mechanism. Information Processing & Management, 59 (2), 102799.
Kandimalla, B., Rohatgi, S., Wu, J., & Lee Giles, C. (2020). Large scale subject category classification of scholarly papers with deep attentive neural networks. Frontiers in Research Metrics and Analytics, 5 , 600382.
Kelly, M. (2015). Citation patterns of engineering, statistics, and computer science researchers: An internal and external citation analysis across multiple engineering subfields. College and Research Libraries, 76 (7), 859–882.
Kim, S., & Gil, J. (2019). Research paper classification systems based on TF-IDF and LDA schemes. Human-Centric Computing and Information Sciences, 9 , 30.
Levitt, J. M., & Thelwall, M. (2008). Patterns of annual citation of highly cited articles and the prediction of their citation ranking: A comparison across subjects. Scientometrics, 77 (1), 41–60.
Li, S., Zhao, W. X., Yin, E. J., & Wen, J. R. (2019). A neural citation count prediction model based on peer review text. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) (pp. 4914–4924).
Li, S., Li, Y., Zhao, W., et al. (2022). Interpretable aspect-aware capsule network for peer review based citation count prediction. ACM Transaction on Information System, 40 (1), 1–29.
Article MathSciNet Google Scholar
Liu, L., Yu, D., Wang, D., et al. (2020). Citation count prediction based on neural Hawkes model. IEICE Transactions on Information and Systems, 103 (11), 2379–2388.
Liu, M., Zhang, H., Tian, Y., et al. (2022). Overview of NLPCC2022 shared task 5 track 1: Multi-label classification for scientific literature. NLPCC, 2 (2022), 320–327.
Lu, C., Ding, Y., & Zhang, C. (2017). Understanding the impact change of a highly cited article: A content-based citation analysis. Scientometrics, 112 (3), 927–945.
Lukasik, M., Kusmierczyk, T., Bolikowski, L., & Nguyen, H. (2013). Hierarchical, multi-label classification of scholarly publications: Modifications of ML-KNN algorithm. Intelligent Tools for Building a Scientific Information Platform, 2013 , 343–363.
Ma, A., Liu, Y., Xu, X., et al. (2021). A deep learning based citation count prediction model with paper metadata semantic features. Scientometrics, 126 (2), 6803–6823.
Mendoza, Ó. E., Kusa, W., El-Ebshihy, A., Wu, R., Pride, D., Knoth, P., Herrmannova, D., Piroi, F., Pasi, G. & Hanbury, A. (2022). Benchmark for research theme classification of scholarly documents. In Proceedings of the third workshop on scholarly document processing (pp. 253–262).
Mendoza, M. (2021). Differences in citation patterns across areas, article types and age groups of researchers. Publications, 9 (4), 47.
Milz, T., & Seifert, C. (2018). Who cites what in computer science? Analysing citation patterns across conference rank and gender. TPDL, 2018 , 321–325.
Persht, A. (2009). The most influential journals: Impact factor and Eigenfactor. Proceedings of the National Academy of Sciences, 106 (17), 6883–6884.
Redner, S. (1998). How popular is your paper? An empirical study of the citation distribution. European Physical Journal B, 4 (2), 131–134.
Rivest, M., Vignola-Gagné, E., & Archambault, É. (2021). Article-level classification of scientific publications: A comparison of deep learning, direct citation and bibliographic coupling. PLoS ONE, 16 (5), e0251493.
Ruan, X., Zhu, Y., Li, J., et al. (2020). Predicting the citation counts of individual papers via a BP neural network. Journal of Informetrics, 4 (3), 101039.
Saier, T., & Färber, M. (2020). UnarXive: A large scholarly data set with publications’ full-text, annotated in-text citations, and links to metadata. Scientometrics, 125 , 3085–3108.
Semberecki, P., & Maciejewski, H. (2017). Deep learning methods for subject text classification of articles. FedCSIS, 2017 , 357–360.
Shen, Z., Ma, H., & Wang, K. (2018). A web-scale system for scientific knowledge exploration. ACL, 4 , 87–92.
Stegehuis, C., Litvak, N., & Waltman, L. (2015). Predicting the long-term citation impact of recent publications. Journal of Informetrics, 9 (3), 642–657.
Su, Z. (2020). Prediction of future citation count with machine learning and neural network. In 2020 Asia-Pacific conference on image processing, electronics and computers (IPEC) (pp. 101–104). IEEE.
Tang, J., Zhang, J., Yao, L., Li, J., Zhang, L., & Su, Z. (2008). Arnetminer: Extraction and mining of academic social networks. In Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 990–998).
Thelwall, M. (2020). Gender differences in citation impact for 27 fields and six English-speaking countries 1996–2014. Quantitative Science Studies, 1 (2), 599–617.
Toney, A., & Dunham, J. (2022). Multi-label classification of scientific research documents across domains and languages. In Proceedings of the third workshop on scholarly document processing (pp. 105–114).
Waltman, L., & van Eck, N. (2012). A new methodology for constructing a publication-level classification system of science. Journal of the American Society for Information Science and Technology, 63 (12), 2378–2392.
Wang, B., Wu, F., & Shi, L. (2023). AGSTA-NET: Adaptive graph spatiotemporal attention network for citation count prediction. Scientometrics, 128 (1), 511–541.
Wang, D., Song, C., & Barabasi, A. (2013). Quantifying long-term scientific impact. Science, 342 (6154), 127–132.
Wang, K., Shi, W., Bai, J., et al. (2021). Prediction and application of article potential citations based on nonlinear citation-forecasting combined model. Scientometrics, 126 (8), 6533–6550.
Wen, J., Wu, L., & Chai, J. (2020). Paper citation count prediction based on recurrent neural network with gated recurrent unit. In 2020 IEEE 10th international conference on electronics information and emergency communication (ICEIEC) (pp. 303–306). IEEE.
Wu, S., Li, J., & Ding, W. (2023). A geometric framework for multiclass ensemble classifiers. Machine Learning, 112 (12), 4929–4958.
Xu, J., Li, M., Jiang, J., et al. (2019). Early prediction of scientific impact based on multi-bibliographic features and convolutional neural network. IEEE ACCESS, 7 , 92248–92258.
Yan, R., Tang, J., Liu, X., Shan, D., & Li, X. (2011). Citation count prediction: learning to estimate future citations for literature. In Proceedings of the 20th ACM international conference on Information and knowledge management (pp. 1247–1252).
Yan, E., & Ding, Y. (2010). Weighted citation: An indicator of an article’s prestige. Journal of the American Society for Information Science and Technology, 61 (8), 1635–1643.
Yu, T., Yu, G., Li, P. Y., & Wang, L. (2014). Citation impact prediction for scientific papers using stepwise regression analysis. Scientometrics, 101 , 1233–1252.
Zhang, L., Sun, B., Shu, F., & Huang, Y. (2022). Comparing paper level classifications across different methods and systems: an investigation of Nature publications. Scientometrics, 127 (12), 7633–7651.
Zhao, Q., & Feng, X. (2022). Utilizing citation network structure to predict paper citation counts: A deep learning approach. Journal of Informetrics, 16 (1), 101235.
Zhu, X. P., & Ban, Z. (2018). Citation count prediction based on academic network features. In 2018 IEEE 32nd international conference on advanced information networking and applications (AINA) (pp. 534-541). IEEE.
Download references
No funding was received for conducting this study.
Author information
Authors and affiliations.
School of Computing Science, Jiangsu University, Zhenjiang, China
Fang Zhang & Shengli Wu
School of Education, Hubei University of Arts and Science, Xiangyang, China
School of Computing, Ulster University, Belfast, UK
You can also search for this author in PubMed Google Scholar
Contributions
All authors contributed to the study conception and design. Data collection, programming and analysis were performed by Fang Zhang. The first draft of the manuscript was written by Shengli Wu, and all authors read and approved the final manuscript.
Corresponding author
Correspondence to Shengli Wu .
Ethics declarations
Competing interests.
The authors have no relevant financial and non-financial interests to disclose.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Zhang, F., Wu, S. Predicting citation impact of academic papers across research areas using multiple models and early citations. Scientometrics (2024). https://doi.org/10.1007/s11192-024-05086-0
Download citation
Received : 30 August 2023
Accepted : 13 June 2024
Published : 25 June 2024
DOI : https://doi.org/10.1007/s11192-024-05086-0
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Multiple models
- Classification of academic papers
- Find a journal
- Publish with us
- Track your research
Child and Youth Mental Health Nurse Practitioners In Australia
13 Pages Posted: 25 Jun 2024
Sarah Casey
affiliation not provided to SSRN
Nurse practitioners are clinical leaders in their specialty field contributing to the development and changes in policies and procedures, initiating research based on identified need, and providing clinical expertise in managing complex care, among other numerous skills and standards.1 Considering the significant increase in the need for Child and Youth Mental Health Services (CYMHS), particularly since the pandemic,2 it would be remiss not to utilise such a resource in ameliorating the current burden on the system. The nurse practitioner in CYMHS is an anomaly, necessitating further research and exploration to illustrate their value and scope to be harnessed and supported.3
Keywords: Child and Youth Mental Health, nurse practitioner, Mental Health, Australia
Suggested Citation: Suggested Citation
Sarah Casey (Contact Author)
Affiliation not provided to ssrn ( email ).
No Address Available
Do you have a job opening that you would like to promote on SSRN?
Paper statistics, related ejournals, child & adolescent health ejournal.
Subscribe to this fee journal for more curated articles on this topic
Nursing Care eJournal
Medical & mental health sociology ejournal, nursing management ejournal, health systems & hospital infrastructure ejournal, medical ethics ejournal.
Scribbr Citation Generator
Accurate APA, MLA, Chicago, and Harvard citations, verified by experts, trusted by millions
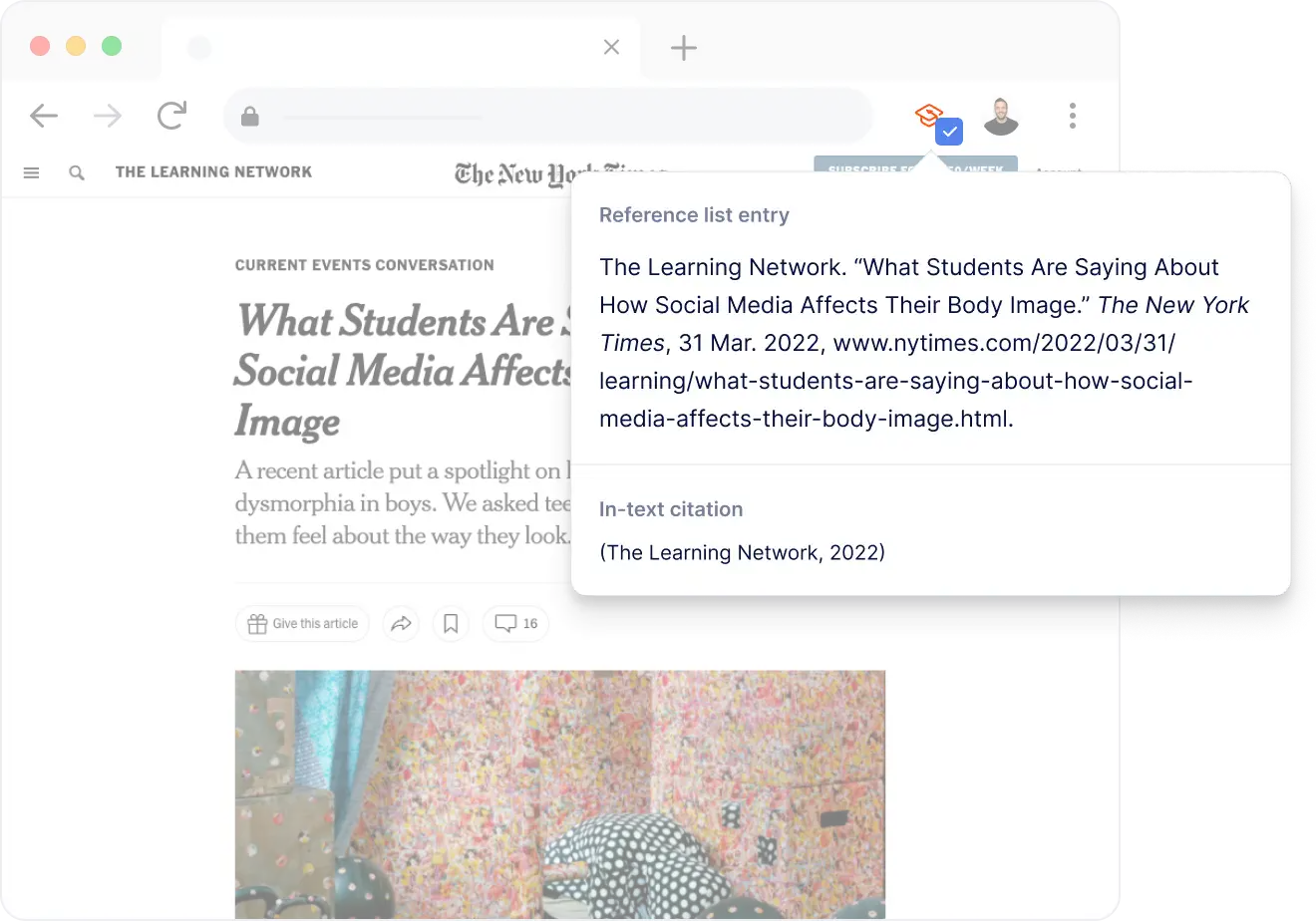
Scribbr for Chrome: Your shortcut to citations
Cite any page or article with a single click right from your browser. The extension does the hard work for you by automatically grabbing the title, author(s), publication date, and everything else needed to whip up the perfect citation.
| ⚙️ Styles | APA, MLA, Chicago, Harvard |
|---|---|
| 📚 Source types | Websites, books, articles |
| 🔎 Autocite | Search by title, URL, DOI, or ISBN |

Perfectly formatted references every time
Inaccurate citations can cost you points on your assignments, so our seasoned citation experts have invested countless hours in perfecting Scribbr’s citation generator algorithms. We’re proud to be recommended by teachers and universities worldwide.
Enjoy a citation generator without flashy ads
Staying focused is already difficult enough, so unlike other citation generators, Scribbr won’t slow you down with flashing banner ads and video pop-ups. That’s a promise!
Citation Generator features you'll love
Look up your source by its title, URL, ISBN, or DOI, and let Scribbr find and fill in all the relevant information automatically.
APA, MLA, Chicago, and Harvard
Generate flawless citations according to the official APA, MLA, Chicago, Harvard style, or many other rules.
Export to Word
When your reference list is complete, export it to Word. We’ll apply the official formatting guidelines automatically.
Lists and folders
Create separate reference lists for each of your assignments to stay organized. You can also group related lists into folders.
Export to Bib(La)TeX
Are you using a LaTex editor like Overleaf? If so, you can easily export your references in Bib(La)TeX format with a single click.
Custom fonts
Change the typeface used for your reference list to match the rest of your document. Options include Times New Roman, Arial, and Calibri.
Industry-standard technology
Scribbr’s Citation Generator is built using the same citation software (CSL) as Mendeley and Zotero, but with an added layer for improved accuracy.
Annotations
Describe or evaluate your sources in annotations, and Scribbr will generate a perfectly formatted annotated bibliography .
Citation guides
Scribbr’s popular guides and videos will help you understand everything related to finding, evaluating, and citing sources.
Secure backup
Your work is saved automatically after every change and stored securely in your Scribbr account.
- Introduction
- Finding sources
Evaluating sources
- Integrating sources
Citing sources
Tools and resources, a quick guide to working with sources.
Working with sources is an important skill that you’ll need throughout your academic career.
It includes knowing how to find relevant sources, assessing their authority and credibility, and understanding how to integrate sources into your work with proper referencing.
This quick guide will help you get started!
Finding relevant sources
Sources commonly used in academic writing include academic journals, scholarly books, websites, newspapers, and encyclopedias. There are three main places to look for such sources:
- Research databases: Databases can be general or subject-specific. To get started, check out this list of databases by academic discipline . Another good starting point is Google Scholar .
- Your institution’s library: Use your library’s database to narrow down your search using keywords to find relevant articles, books, and newspapers matching your topic.
- Other online resources: Consult popular online sources like websites, blogs, or Wikipedia to find background information. Be sure to carefully evaluate the credibility of those online sources.
When using academic databases or search engines, you can use Boolean operators to refine your results.
Generate APA, MLA, Chicago, and Harvard citations in seconds
Get started
In academic writing, your sources should be credible, up to date, and relevant to your research topic. Useful approaches to evaluating sources include the CRAAP test and lateral reading.
CRAAP is an abbreviation that reminds you of a set of questions to ask yourself when evaluating information.
- Currency: Does the source reflect recent research?
- Relevance: Is the source related to your research topic?
- Authority: Is it a respected publication? Is the author an expert in their field?
- Accuracy: Does the source support its arguments and conclusions with evidence?
- Purpose: What is the author’s intention?
Lateral reading
Lateral reading means comparing your source to other sources. This allows you to:
- Verify evidence
- Contextualize information
- Find potential weaknesses
If a source is using methods or drawing conclusions that are incompatible with other research in its field, it may not be reliable.
Integrating sources into your work
Once you have found information that you want to include in your paper, signal phrases can help you to introduce it. Here are a few examples:
| Function | Example sentence | Signal words and phrases |
|---|---|---|
| You present the author’s position neutrally, without any special emphasis. | recent research, food services are responsible for one-third of anthropogenic greenhouse gas emissions. | According to, analyzes, asks, describes, discusses, explains, in the words of, notes, observes, points out, reports, writes |
| A position is taken in agreement with what came before. | Recent research Einstein’s theory of general relativity by observing light from behind a black hole. | Agrees, confirms, endorses, reinforces, promotes, supports |
| A position is taken for or against something, with the implication that the debate is ongoing. | Allen Ginsberg artistic revision … | Argues, contends, denies, insists, maintains |
Following the signal phrase, you can choose to quote, paraphrase or summarize the source.
- Quoting : This means including the exact words of another source in your paper. The quoted text must be enclosed in quotation marks or (for longer quotes) presented as a block quote . Quote a source when the meaning is difficult to convey in different words or when you want to analyze the language itself.
- Paraphrasing : This means putting another person’s ideas into your own words. It allows you to integrate sources more smoothly into your text, maintaining a consistent voice. It also shows that you have understood the meaning of the source.
- Summarizing : This means giving an overview of the essential points of a source. Summaries should be much shorter than the original text. You should describe the key points in your own words and not quote from the original text.
Whenever you quote, paraphrase, or summarize a source, you must include a citation crediting the original author.
Citing your sources is important because it:
- Allows you to avoid plagiarism
- Establishes the credentials of your sources
- Backs up your arguments with evidence
- Allows your reader to verify the legitimacy of your conclusions
The most common citation styles are APA, MLA, and Chicago style. Each citation style has specific rules for formatting citations.
Generate APA, MLA, Chicago, and Harvard citations in seconds
Scribbr offers tons of tools and resources to make working with sources easier and faster. Take a look at our top picks:
- Citation Generator: Automatically generate accurate references and in-text citations using Scribbr’s APA Citation Generator, MLA Citation Generator , Harvard Referencing Generator , and Chicago Citation Generator .
- Plagiarism Checker : Detect plagiarism in your paper using the most accurate Turnitin-powered plagiarism software available to students.
- AI Proofreader: Upload and improve unlimited documents and earn higher grades on your assignments. Try it for free!
- Paraphrasing tool: Avoid accidental plagiarism and make your text sound better.
- Grammar checker : Eliminate pesky spelling and grammar mistakes.
- Summarizer: Read more in less time. Distill lengthy and complex texts down to their key points.
- AI detector: Find out if your text was written with ChatGPT or any other AI writing tool. ChatGPT 2 & ChatGPT 3 supported.
- Proofreading services : Have a human editor improve your writing.
- Citation checker: Check your work for citation errors and missing citations.
- Knowledge Base : Explore hundreds of articles, bite-sized videos, time-saving templates, and handy checklists that guide you through the process of research, writing, and citation.
NTRS - NASA Technical Reports Server
Available downloads, related records.
IMAGES
VIDEO
COMMENTS
When using APA format, follow the author-date method of in-text citation. This means that the author's last name and the year of publication for the source should appear in the text, like, for example, (Jones, 1998). One complete reference for each source should appear in the reference list at the end of the paper.
At college level, you must properly cite your sources in all essays, research papers, and other academic texts (except exams and in-class exercises). Add a citation whenever you quote, paraphrase, or summarize information or ideas from a source. You should also give full source details in a bibliography or reference list at the end of your text.
The point of an in-text citation is to show your reader where your information comes from. Including citations: Avoids plagiarism by acknowledging the original author's contribution. Allows readers to verify your claims and do follow-up research. Shows you are engaging with the literature of your field.
Articles & Research Databases Literature on your research topic and direct access to articles online, when available at UW.; E-Journals Alphabetical list of electronic journal titles held at UW.; Encyclopedias & Dictionaries Resources for looking up quick facts and background information.; E-Newspapers, Media, Maps & More Recommendations for finding news, audio/video, images, government ...
Basic Principles of Citation. APA Style uses the author-date citation system, in which a brief in-text citation directs readers to a full reference list entry. The in-text citation appears within the body of the paper (or in a table, figure, footnote, or appendix) and briefly identifies the cited work by its author and date of publication.
Scholarship is a conversation and scholars use citations not only to give credit to original creators and thinkers, but also to add strength and authority to their own work.By citing their sources, scholars are placing their work in a specific context to show where they "fit" within the larger conversation.Citations are also a great way to leave a trail intended to help others who may want ...
Figure 8.1 in Chapter 8 of the Publication Manual provides an example of an appropriate level of citation. The number of sources you cite in your paper depends on the purpose of your work. For most papers, cite one or two of the most representative sources for each key point. Literature review papers typically include a more exhaustive list of ...
The Bluebook: A Uniform System of Citation is the main style guide for legal citations in the US. It's widely used in law, and also when legal materials need to be cited in other disciplines. Bluebook footnote citation. 1 David E. Pozen, Freedom of Information Beyond the Freedom of Information Act, 165, U. P🇦 .
Have fewer than 40 words, use quotation marks around the quote, are incorporated into the text of the paper. (Shayden, 2016, p. 202) Long quotes: Have 40 words or MORE, DO NOT use quotation marks, are in a block quote (by indenting 0.5" or 1 tab) beneath the text of the paragraph. (Miller et al., 2016, p. 136) Quotes for webpages:
Author-date citations are used in APA and Chicago styles and list the author's last name, publication date, and page number(s). Author-page citations are used in MLA and include the author's last name and page number(s). Each citation style has different formatting rules, so be sure to double-check the style guide for the style you are using.
A list of sources can be a useful record for further research; Different academic disciplines prefer different citation styles, most commonly APA and MLA styles. Besides these styles, there are Chicago, Turabian, AAA, AP, and more. Only use the most current edition of the citation style.
A citation identifies for the reader the original source for an idea, information, or image that is referred to in a work. In the body of a paper, the in-text citation acknowledges the source of information used.; At the end of a paper, the citations are compiled on a References or Works Cited list.A basic citation includes the author, title, and publication information of the source.
In this situation the original author and date should be stated first followed by 'as cited in' followed by the author and date of the secondary source. For example: Lorde (1980) as cited in Mitchell (2017) Or (Lorde, 1980, as cited in Mitchell, 2017) Back to top. 3. How to Cite Different Source Types.
The Chicago/Turabian style of citing sources is generally used when citing sources for humanities papers, and is best known for its requirement that writers place bibliographic citations at the bottom of a page (in Chicago-format footnotes) or at the end of a paper (endnotes). The Turabian and Chicago citation styles are almost identical, but ...
Articles & Research Databases Literature on your research topic and direct access to articles online, when available at UW.; E-Journals Alphabetical list of electronic journal titles held at UW.; Encyclopedias & Dictionaries Resources for looking up quick facts and background information.; E-Newspapers, Media, Maps & More Recommendations for finding news, audio/video, images, government ...
There are two main kinds of titles. Firstly, titles can be the name of the standalone work like books and research papers. In this case, the title of the work should appear in the title element of the reference. Secondly, they can be a part of a bigger work, such as edited chapters, podcast episodes, and even songs.
When you cite a source with up to three authors, cite all authors' names. For four or more authors, list only the first name, followed by ' et al. ': Number of authors. In-text citation example. 1 author. (Davis, 2019) 2 authors. (Davis and Barrett, 2019) 3 authors.
Research paper: In-text citation: Use superscript numbers to cite sources in the text, e.g., "Previous research has shown that^1,2,3…". Reference list citation: Format: Author (s). Title of paper. In: Editor (s). Title of the conference proceedings. Place of publication: Publisher; Year of publication. Page range.
3. List the title of the research paper. Use sentence capitalization to write out the full title of the research paper, capitalizing the first word and any proper names. If it has a subtitle, place a colon and capitalize the first word of the subtitle. [3] For example: "Kringle, K., & Frost, J. (2012).
Parenthetical citation: According to new research … (Smith, 2020). Narrative citation: Smith (2020) notes that … Multiple authors and corporate authors. The in-text citation changes slightly when a source has multiple authors or an organization as an author. Pay attention to punctuation and the use of the ampersand (&) symbol.
Citation in research papers: A citation appears in the main text of the paper. It is a way of giving credit to the information that you have specifically mentioned in your research paper by leading the reader to the original source of information. You will need to use citation in research papers whenever you are using information to elaborate a ...
Chicago or Turabian. Students and researchers commonly use the Chicago Manual of Style guide, or Turabian, for most real-world subjects in magazines, books, newspapers and many other non-scholarly publications. Example of Chicago style for a book with one author: Doe, John. 1999. Causes of the Civil War.
The rules for citing the use of generative AI, both textual and visual, are still evolving. For guidelines on when to cite the use of AI, please refer to the section on Academic Integrity. ... For academic papers or research articles, you should have a numbered footnote or endnote. Footnote - prompt not included in the text of the paper. 1 ...
scite is a Brooklyn-based organization that helps researchers better discover and understand research articles through Smart Citations-citations that display the context of the citation and describe whether the article provides supporting or contrasting evidence. scite is used by students and researchers from around the world and is funded in part by the National Science Foundation and the ...
I know citations are different and should be more visible quicker in the land of research, but the same logic applies. Patience—and continued hard work (i.e., to advance one's research acumen ...
As the volume of scientific literature expands rapidly, accurately gauging and predicting the citation impact of academic papers has become increasingly imperative. Citation counts serve as a widely adopted metric for this purpose. While numerous researchers have explored techniques for projecting papers' citation counts, a prevalent constraint lies in the utilization of a singular model ...
Abstract. Nurse practitioners are clinical leaders in their specialty field contributing to the development and changes in policies and procedures, initiating research based on identified need, and providing clinical expertise in managing complex care, among other numerous skills and standards.1 Considering the significant increase in the need for Child and Youth Mental Health Services (CYMHS ...
Citation Generator: Automatically generate accurate references and in-text citations using Scribbr's APA Citation Generator, MLA Citation Generator, Harvard Referencing Generator, and Chicago Citation Generator. Plagiarism Checker: Detect plagiarism in your paper using the most accurate Turnitin-powered plagiarism software available to ...
This paper focuses on the thermophysical property mixture model approach that makes use of NASA's polynomial fits of species and another cryogenic model chosen from NIST's Refprop program. Presented in this paper are results of a 1D denotation CFD simulation of stoichiometric Hydrogen and Oxygen mixture at a cryogenic upstream condition.
Recent research suggests that greater in-flight running intensity and volume attenuate decrements in aerobic capacity and strength; however, this has not been experimentally confirmed. The Exploration Exercise Treadmill Requirements study is currently underway, aiming to determine the effects of exercising without a treadmill on aerobic ...