As Europe's largest cancer centre, rated 'Outstanding' by the CQC, we have the expertise, technology and facilities to provide the highest standards of personalised care to our private patients.
Refer a patient
- About The Royal Marsden
- Why choose us?
- Meet our experts
- Find a consultant
- Cavendish Square
- Cancer types and treatments
- Useful information
- Freedom of information
- Equality and diversity
- Access policy
As a private patient at The Royal Marsden, you will have direct access to some of the most experienced cancer specialists in the world, leading‑edge diagnostic techniques and treatments, and individualised treatment plans based on the latest research.
Why choose us
- Payment information
- How to make an appointment
- Video consultations
- Cancer information videos
- Request a second opinion
- Information for patients
- Appointment reminders

As a patient at one of the world’s top three cancer centres, you will benefit from our state-of-the-art facilities, the most experienced and respected cancer consultants, and some of the world’s most innovative technology.
Patient Centre
- Make an enquiry in
Updates and referral information for GPs and other healthcare professionals.
Make a referral
- Information for GPs
- Education and events
- Resources and diagnostics
- News and Blogs
Make an appointment
UK: 020 7811 8111
Intl: +44 (0)20 7808 2063

Case Study: Breast cancer patient
‘Running a half marathon isn’t something you might expect of someone who’s just had breast cancer, but I was keen to get back to doing the things I love.’
Hepin* had been diagnosed with triple negative breast cancer late in 2014, before going on to have surgery. Her treatment was initially successful, and for a number of years she led an active lifestyle.
But in May 2018 she started to notice a change. ‘I was feeling more tired than usual – yawning and flagging easily,’ she explains.
After undergoing further tests, she received the news: the cancer had returned, this time spreading to lymph nodes in her armpit. She went through more treatment – this time having chemotherapy and radiotherapy.
‘A few months later, we went for a scan and it wasn’t good news,’ she says. Doctors told her that images showed possible disease in other parts of her body.
‘Obviously this was devastating to hear,’ she says. ‘But we were keen to get another opinion, to make sure this was the case, and to check what my treatment plan should be.’
Hepin and her husband looked to international centres for expert advice, before choosing The Royal Marsden. ‘I’d heard it was one of the world leading institutions treating breast cancer.’ she explains.
When she arrived at The Royal Marsden Hepin said she immediately noticed the calming atmosphere. ‘It was serene and quiet – it felt homely and not as busy as some of the hospitals we have at home.’ she explains.
After undergoing an MRI scan, her consultant Professor Stephen confirmed the good news; she wouldn’t need any further treatment for now, but should keep having regular checks to monitor her health.
‘Overall we were very pleased with our experience at The Royal Marsden,’ Hepin says. ‘They made us feel welcomed and comfortable and all the staff were so accommodating. The translation service provided was also of great help for us.’
*Not her real name
欲了解更多信息,请联系中国国际患者部邮箱: [email protected]
It was serene and quiet – it felt homely and not as busy as some of the hospitals we have at home. Hepin, breast cancer patient

Why choose The Royal Marsden?

Referrals to Private Care
CASE REPORT article
Case report: individualized treatment of advanced breast cancer with the use of the patient-derived tumor-like cell cluster model.

- 1 General Surgery, Cancer Center, Department of Breast Surgery, Zhejiang Provincial People’s Hospital, Affiliated People’s Hospital, Hangzhou Medical College, Hangzhou, China
- 2 Department of Breast Surgery (Surgical Oncology), Second Affiliated Hospital, Zhejiang University School of Medicine, Hangzhou, China
- 3 Rehabilitation Medicine Center, Rehabilitation and Sports Medicine Research Institute of Zhejiang Province, Department of Rehabilitation Medicine, Zhejiang Provincial People’s Hospital, Affiliated People’s Hospital, Hangzhou Medical College, Hangzhou, China
Breast cancer is one of the most common tumors in women. Despite various treatments, the survival of patients with advanced breast cancer is still disappointing. Furthermore, finding an effective individualized treatment for different kinds of patients is a thorny problem. Patient-derived tumor-like cell clusters were reported to be used for personalized drug testing in cancer therapy and had a prediction accuracy of 93%. However, there is still a lack of case reports about its application in the individualized treatment of breast cancer patients. Here, we described four cases of individualized treatment for advanced breast cancer using the patient-derived tumor-like cell cluster model (PTC model). In these four cases, the PTC model showed a good predictive effect. The tumor size was reduced significantly or even disappeared completely through clinical, radiological, or pathological evaluation with the help of the PTC model for selecting an individualized therapy regimen. Furthermore, the drug sensitivity test results of the PTC model were consistent with pathological molecular typing and the actual clinical drug resistance of the patients. In summary, our case report first evaluated the application value of the PTC model in advanced breast cancer, and the PTC model might be used as an efficient tool for drug resistance screening and for selecting a better personalized treatment, although further study is needed to prove the validity and stability of the PTC model in drug screening.
Introduction
Breast cancer is one of the most common tumors, and its incidence rate ranks first in female malignant tumors ( 1 ). Despite various treatments, the survival of patients with advanced breast cancer is still disappointing, and the overall survival (OS) is approximately 31% ( 2 ). Because of the rapid progression of the tumor, it is of great importance to find an effective treatment in time ( 3 ). However, finding an effective individualized treatment for different kinds of patients is a thorny problem ( 4 , 5 ). Some articles reported that patient-derived tumor-like cell clusters could be used for personalized drug testing in cancer therapy and had a prediction accuracy of 93% ( 6 ). However, there is still a lack of case reports about its application in the individualized treatment of breast cancer patients. Here, we described four cases of individualized treatment for advanced breast cancer with the use of the patient-derived tumor-like cell cluster model (PTC model).
To identify the optimum therapy for individualized treatment, a personalized PTC drug testing system was conducted as described in a previous study ( 6 ). Thousands of PTCs were divided into a multiwell chip and were evaluated with different drugs, and it was confirmed that the gene expressions within different wells were highly correlated and PTC gene expressions were consistent with that of the original tumor ( 6 ). In clinical practice, the Response Evaluation Criteria in Solid Tumors (RECIST) is usually used to assess the efficacy of individualized treatment. The PTC model defined a similar method to assess drug efficacy: it first fixed the cutoff value of cell viability and then determined the effective concentrations of different drugs.
First, drug efficacy was assessed by measuring the area of all PTCs in each well. PTCs were photographed and evaluated on days 0 and 7. Only cell clusters with diameters greater than 40 μm when measured at both time points were used to estimate the total area. Moreover, cell viability after the addition of drug A was estimated by the following method:
where S represents the sum of the cluster area in each well, n represents the number of repetitions, and q0, q1 represent the time points (days 0 and 7) when the area is measured. The cell viability of the negative control (pNC) was calculated in the same way and served as a quality control. If pNC was less than 0.9, the PTC test was discarded because PTCs were possibly in the decline phase.
Second, the cutoff value of the PTC model was determined based on the RECIST criteria as described in a previous study ( 6 ). According to the RECIST criteria, the tumor efficacy was divided into two subgroups with 0.7 as the cutoff value, and partial response (PR) or complete response (CR) was regarded as effective, while progressive disease (PD) or stable disease (SD) as otherwise. Accordingly, the drug was regarded as effective if pA<0.7, and the drug was not effective if pA ≥0.7.
Lastly, the effective drug concentration (Ec) of drug A in the PTC model was determined according to its clinical efficacy ( 6 ). The clinical efficacy was assessed in 272 breast cancer patients admitted to Zhejiang Provincial People’s Hospital from 1 January 2014 to 31 December 2020 with neoadjuvant chemotherapy or palliative chemotherapy (details are provided in Supplementary Material Table S1 ). For any precise tumor treatment method, including the PTC model, its predicted drug efficacy rate should be consistent with the patient’s clinical response rate of this drug among patients. In our PTC model, the predicted efficacy rate was determined by the cutoff value of the cell viability and the drug’s Ec. Therefore, after fixing the 0.7 cutoff value, we determined the Ec of a drug as the concentration such that the effective rate in the PTC assay was closest to the overall response rate of this drug in clinical practice which was assessed in 272 breast cancer patients with neoadjuvant chemotherapy or advanced treatment ( Table S2 ). We used the PTC samples of 12 patients as the training cohorts to determine the Ec values of nine drugs. The Ec of all drugs used in this study was determined. Three replications were performed for each drug sample pair ( Figure S1 ).
Because some drugs are dependent on exposure time while others are not, the drug exposure time is uniformly set to 24 h to ensure adequate and uniform exposure time.
Case description
A 37-year-old Chinese woman who was in lactation presented with a red and swollen left-side breast. Examination revealed 20 * 15 cm redness and swelling in the left breast and 4 * 3 cm mass in the upper quadrant of the right breast ( Figure 1A ). Core needle biopsies were performed on bilateral breast masses and revealed invasive ductal carcinoma [immunohistochemistry: left—estrogen receptor (ER) (−), progesterone receptor (PR) (−), human epidermal growth factor receptor 2 (HER2) (1+), Ki67 (+35%); right—ER (−), PR (−), HER2 (1+), Ki67 (+30%)]. Furthermore, positron emission tomography/computed tomography (PET/CT) showed multiple lymph node metastases in the bilateral axilla, left clavicular area, and left upper mediastinum, and her final TNM stage was T4N3M1 ( Figure 2A ). Individualized treatment was screened with the use of the PTC model, and the drug sensitivity results are included in Figure 3 and Figure S2 (details are available in Supplementary Material Table S3 ). Finally, compared with the other treatments, the albumin paclitaxel (125 mg/m 2 ) plus carboplatin (AUC = 2) d1, 8, 1/21d regimen showed a higher killing rate of the tumor cells (47%) and was selected. After six cycles of chemotherapy, the tumor size was reduced obviously ( Figure 1B ), but the drop in platelet count was also significant. Thus, the regimen was adjusted to albumin paclitaxel (260 mg/m 2 , d1, 1/21d) plus capecitabine (150 mg BID, d1–14, 1/21d) for maintenance therapy based on previous drug sensitivity results with the PTC model. After 10 cycles of chemotherapy in total, PET/CT was performed again and indicated a significant reduction of tumor and lymph nodes ( Figure 2B ). Finally, to improve her quality of life, bilateral mastectomy and local rotation skin flap grafting were performed ( Figures 1C, D ). The final pathological results indicated a pathologic complete response (pCR) of the right side, with Miller–Payne (MP) grade 5, and MP grade 3 of the left side, with a residual tumor size of 2.5 * 2 cm. By now, the progression-free survival (PFS) has reached 20 months.

Figure 1 Evaluation of the therapeutic effect after chemotherapy. (A) A frontal view of the patient first presenting with a red and swollen left-side breast; (B) a frontal view of the redness and swelling of the patient’s left breast decreasing obviously after six cycles of chemotherapy; (C) a frontal view of the patient completing 10 cycles of chemotherapy prior to a planned mastectomy; (D) a frontal view of the patient after bilateral mastectomy and local rotation skin flap grafting.

Figure 2 PET/CT images evaluating the changes in breast masses and metastatic lymph nodes during treatment in case 1. (A) PET/CT images showing intense FDG uptake in the bilateral breast, bilateral axilla, left clavicular area, and left upper mediastinum at the time of initial diagnosis; (B) PET/CT images showing that areas of high FDG uptake in the breast and lymph nodes were significantly reduced after 10 cycles of chemotherapy.

Figure 3 The drug sensitivity results of the PTC model for individualized treatment in case 1. (A) Comparison of trastuzumab before and after dosing; (B) comparison of epirubicin + cyclophosphamide before and after dosing; (C) comparison of vinorelbine + capecitabine before and after dosing; (D) comparison of albumin paclitaxel + capecitabine before and after dosing; (E) comparison of albumin paclitaxel + carboplatin before and after dosing; (F) negative control (NC) group.
A 50-year-old Chinese woman presented with a 3 * 2-cm right breast mass. Core needle biopsy indicated invasive ductal carcinoma [immunohistochemistry: ER (−), PR (−), HER2 (3+), Ki67 (+80%)]. In addition, PET/CT showed multiple bone metastases and right axillary lymph node metastasis, and the final stage was T2N1M1. The PTC model was used for drug sensitivity screening ( Figure 4 and Figure S3 ; details are available in Supplementary Material Table S4 ). The PTH (albumin paclitaxel 260 mg/m 2 d1, trastuzumab 8 mg/kg d1 followed by 6 mg/kg d1, and pertuzumab 840 mg d1 followed by 420 mg d1, 1/21d) regimen showed a better tumor cell killing rate of 70% and was finally selected. In addition, zoledronic acid was used to inhibit bone metastasis. After four cycles of chemotherapy, the tumor size was reduced obviously. Finally, right mastectomy and axillary lymph node dissection were performed, and the pathological results indicated a pCR of the tumor with MP grade 5. By now, the PFS has reached 18 months.

Figure 4 The drug sensitivity results of the PTC model for individualized treatment in case 2. (A) Comparison of albumin paclitaxel + capecitabine + trastuzumab before and after dosing; (B) comparison of albumin paclitaxel + carboplatin + trastuzumab before and after dosing; (C) comparison of albumin paclitaxel + carboplatin before and after dosing; (D) comparison of pyrotinib + capecitabine before and after dosing; (E) comparison of epirubicin before and after dosing; (F) comparison of albumin paclitaxel + trastuzumab + pertuzumab before and after dosing; (G) negative control (NC) group.
A 37-year-old Chinese woman presented with a 2.5 * 1.5-cm left breast mass. Core needle biopsy indicated invasive ductal carcinoma [immunohistochemistry: ER (−), PR (−), HER2 (2+), Ki67 (+30%)]. Fluorescence in-situ hybridization (FISH) was performed and the result was negative. Thus, the EC * 4 (pharmorubicin 90 mg/m 2 plus cyclophosphamide 600 mg/m 2 d1, 1/21d)–T * 4 (docetaxel 100 mg/m 2 d1, 1/21d) regimen was used for neoadjuvant chemotherapy. After eight cycles of neoadjuvant chemotherapy, modified radical mastectomy was performed, and the pathological results revealed invasive ductal carcinoma [MP grade 3, immunohistochemistry: ER (−), PR (−), HER2 (2+), Ki67 (+20%)]. Then, FISH was performed again andthe result was still negative. However, 2 months later, thepatient was confirmed with chest wall metastases [immunohistochemistry: ER (−), PR (−), HER2 (2+), Ki67 (+10%)]. The PTC model was used for drug sensitivity screening ( Figure S4 ), and the results indicated that anti-HER2 therapy was effective. Then, FISH was performed the third time, and the result turned out to be positive. Finally, the PTH (albumin paclitaxel 260 mg/m 2 d1, trastuzumab 8 mg/kg d1 followed by 6 mg/kg d1, and pertuzumab 840 mg d1 followed by 420 mg d1, 1/21d) regimen was selected, and the chest wall metastases disappeared completely. By now, the PFS has reached 12 months.
A 56-year-old woman presented with a 3 * 2-cm right breastmass. A preoperative puncture was performed and showed invasive ductal carcinoma of the right breast (immunohistochemistry: ER (−), PR (−), HER2 (3+), Ki67 (+35%)] and negative axillary lymph node. All organs (including the lungs) showed no signs of metastasis during preoperative evaluation. Therefore, modified radical mastectomy and sentinel lymph node biopsy were performed, and the postoperative pathological report revealed invasive ductal carcinoma of the right breast [2.5 * 2.0 cm, immunohistochemistry: ER (−), PR (−), HER2 (3+), Ki67 (+70%)] and negative sentinel lymph node (0/5). One month later, CT showed multiple pulmonary nodules that had not been detected on preoperative CT and were considered metastatic ( Figure S5A ). Her final TNM stage was T2N0M1. Thus, the PTH (docetaxel 100 mg/m 2 d1, trastuzumab 8 mg/kg d1 followed by 6 mg/kg d1, and pertuzumab 840 mg d1 followed by 420 mg d1, 1/21d) regimen was selected according to the guidelines. However, pulmonary nodules gradually increased and became larger after four cycles of treatment ( Figure S5B ). PET/CT suggested multiple metastatic nodules in both lungs, the largest of which was approximately 9 * 7 mm ( Figure S6A ). Thus, we implemented a PTC drug sensitivity test to screen effective drugs for individualized treatment. All drugs selected for the PTC sensitivity test were selected according to the guidelines and the clinical experience of experienced physicians. Interestingly, the PTC sensitivity test results suggested that compared with chemotherapy combined with targeted therapy, the corresponding chemotherapy regimen alone had similar tumor cell lethality ( Figures S7 , S8 ). This finding also demonstrated that the treatment regimen previously used (the PTH regimen) was ineffective. In addition, the pulmonary nodules were punctured, and the histopathological diagnosis was consistent with lung metastasis from breast cancer [immunohistochemistry: ER (−), PR (−), HER2 (1+), Ki67 (+30%)]. This result suggested that the patient’s HER2 status had changed, being positive in the primary tumor and negative in the metastatic lung nodule. This was consistent with our test results and might explain why targeted therapy based on the PTC sensitivity test was ineffective. Finally, the NCb (vinorelbine 25 mg/m 2 , d1, 8, carboplatin AUC = 2, d1, 8, 1/21d) plus targeted therapy (trastuzumab 6 mg/kg d1, pertuzumab 420 mg d1, 1/21d) regimen was selected based on the PTC drug sensitivity screening results. After four cycles of treatment, the pulmonary nodules almost completely disappeared ( Figures S5C , S6B ). At present, the patient has achieved a PFS time of 14 months.
The leading causes of death in patients with advanced breast cancer are tumor metastasis and drug resistance ( 3 , 7 ). Increasing evidence has indicated that patient-derived tumor models could present human tumor biology and evaluate the potential clinical responses ( 8 – 10 ). Although patient-derived tumor xenografts (PDXs) were reported to be a precise measurement of drug screening, it was difficult to generate sufficient organoids for drug screening within 2 to 3 weeks from small tissue samples ( 6 , 9 , 11 ). To address the defects of previous technologies, the PTC model was emphasized, which could be a method of long-term maintenance and expansion of primary tumor cells in a Matrigel-free condition ( 6 , 12 ), and it was reported as a structural and functional unit which could recapitulate the original tumors according to genotype, phenotype, and drug response within 2 weeks ( 6 ). Furthermore, a previous study has demonstrated that the PTC model in breast cancer can express ER, PR, and HER2 status similar to those of the original tumor ( 6 ). To ensure the accuracy and stability of drug sensitivity, specific culture conditions and an accurate cutoff value of the PTC model were established ( 6 , 13 ). The consistency of PTC cell viability in different wells as well as the consistency between the predicted results of the PTC model and the patient’s clinical response has been demonstrated ( 6 ). Furthermore, the PTC model was proved to be a tool for personalized treatment selection which had a prediction accuracy of 93% ( 6 , 14 ).
Our case report first evaluated the application value of the PTC model in advanced breast cancer and filled in its lack of clinical validation in the individualized treatment of breast cancer. In these four cases of individualized treatment for advanced breast cancer, the PTC model showed a good predictive effect. The tumor size was reduced significantly or even disappeared completely through clinical, radiological, or pathological evaluation with the help of the PTC model for selecting an individualized therapy regimen. Patients who responded to the treatments were reported to have a better OS; thus, the PTC model, which was reported to increase the pCR rate, might have a certain effect on improving the OS ( 15 , 16 ). Furthermore, the drug sensitivity test results of the PTC model were consistent with pathological molecular typing and the actual clinical drug resistance of the patients. For example, the drug sensitivity results of the PTC model showed that anti-HER2 therapy was insensitive to the tumor in case 1, which was pathologically confirmed as triple negative breast cancer, while in case 3, the drug sensitivity results of the PTC model indicated that anti-HER2 therapy was effective to the patient whose first two FISH tests were negative. Finally, it was confirmed that her HER2 status was positive. Moreover, in case 4, the primary tumor was HER2 positive, but the PTC drug sensitivity test results suggested that lung metastases were insensitive to anti-HER2 therapy. The histopathological findings from the biopsy of pulmonary nodules in case 4 finally confirmed that the patient’s HER2 status had changed from positive in the primary tumor to negative in the lung metastasis, which was consistent with the PTC drug sensitivity test results. In addition, the results of the PTC sensitivity test confirmed that the previously used therapeutic regimen was ineffective, suggesting that it had high value in predicting the drug resistance of tumors. Therefore, the PTC model might be used for evaluating the efficacy of chemotherapy and targeted therapy and for estimating pathological molecular typing, and it demonstrated good value in guiding individualized treatment.
In summary, our case report first evaluated the application value of the PTC model in advanced breast cancer, and the PTC model might be used as an efficient tool for drug resistance screening and for selecting a better personalized treatment, although further study is needed to prove the validity and stability of the PTC model in drug screening.
Data availability statement
The original contributions presented in the study are included in the article/ Supplementary Material . Further inquiries can be directed to the corresponding author.
Ethics statement
The studies involving human participants were reviewed and approved by Ethics Committee of Zhejiang Provincial People’s Hospital. The patients/participants provided their written informed consent to participate in this study. Written informed consent was obtained from the individual(s) for the publication of any potentially identifiable images or data included in this article.
Author contributions
WJ and WZ conceived the study, collected and analyzed the data, and co-wrote the first draft. HJ and SF evaluated the histopathological findings, and edited the manuscript. JX and JW were directly involved in the treatment of the patient. All authors contributed to the article and approved the submitted version.
This study was supported by the Public Welfare Technology Application Research Project of Zhejiang Province under Grant No. LGF21H160030, Zhejiang Provincial Natural Science Foundation of China together with Zhejiang Society for Mathematical Medicine (No. LSY19F020002), and Medical and Health Science and Technology Project of Zhejiang Province (2021KY061 and 2023KY046).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fonc.2022.897984/full#supplementary-material
Supplementary Figure 1 | Drug efficacy concentration (Ec). The determination of Ec was based upon the efficacy rate (ER) closest to the overall response rate (OR).
Supplementary Figure 2 | The summary of fold changes of tumor cells before and after drug dosing in case 1. It indicating albumin paclitaxel+carboplatin regimen showed the highest tumor cells killing rate of 47% in the PTCs model, and anti-HER2 therapy was insensitive to triple negative breast cancer.
Supplementary Figure 3 | The summary of fold changes of tumor cells before and after drug dosing in case 2. Albumin paclitaxel+ trastuzumab+ pertuzumab regimen showing the highest tumor cells killing rate of 70% in the PTCs model.
Supplementary Figure 4 | The summary of fold changes of tumor cells before and after drug dosing in case 3. It indicating anti-HER2 therapy was effective of PTCs model in case 3.
Supplementary Figure 5 | Axial CT lung window demonstrating changes in pulmonary nodules during treatment in Case 4. (A) Axial CT lung window demonstrating multiple pulmonary nodules, which was considered pulmonary metastasis. (B) Axial CT lung window demonstrating pulmonary nodules were markedly enlarged after four cycles of PTH (docetaxel+trastuzumab+pertuzumab) treatment. (C) Axial CT lung window demonstrating that pulmonary nodules almost disappeared after four cycles of NCbPH (vinorelbine+carboplatin+trastuzumab+pertuzumab) treatment, which was based on CTC drug sensitivity test results.
Supplementary Figure 6 | PET/CT images evaluating changes in pulmonary nodules during treatment in Case 4. (A) PET CT image showing intense FDG uptake in bilateral pulmonary nodules after four cycles of PTH treatment. (B) PET CT image showing that the area of high FDG uptake in the lung was almost completely eliminated after four cycles of NCbPH treatment, which was based on CTC drug sensitivity test results.
Supplementary Figure 7 | PTCs drug sensitivity test results for individualized treatment in Case 4. (A) Comparison of trastuzumab before and after dosing; (B) Comparison of PTH(docetaxel+trastuzumab+pertuzumab) before and after dosing; (C) Comparison of albumin paclitaxel+PH (albumin paclitaxel+trastuzumab+pertuzumab) before and after dosing; (D) Comparison of NCb(vinorelbine+carboplatin) before and after dosing; (E) Comparison of NCbPH (vinorelbine +carboplatin +trastuzumab +pertuzumab) before and after dosing; (F) negative control(NC) group. The results indicating that tumor cells were insensitive to anti-HER-2 therapy and PTH regimen, and this was consistent with pathological molecular typing and previous clinical practice in which PTH regimen showed poor efficacy. NCbPH and NCb regimen showing a higher killing rate of tumor cells(61.7% and 60.3%).
Supplementary Figure 8 | Summary of the fold changes in PTCs before and after drug dosing in Case 4.
Supplementary Table 1 | Detailed patient information for evaluating the clinical efficacy.
Supplementary Table 2 | Summary of efficacy and concentrations of drugs used in this study.
Supplementary Table 3 | The detailed data of changes in the number of tumor cells before and after drug dosing in case 1.
Supplementary Table 4 | The detailed data of changes in the number of tumor cells before and after drug dosing in case 2.
1. Siegel RL, Miller KD, Fuchs HE, Jemal A. Cancer statistics, 2021. CA Cancer J Clin (2021) 71(1):7–33. doi: 10.3322/caac.21654
PubMed Abstract | CrossRef Full Text | Google Scholar
2. Allemani C, Matsuda T, Di Carlo V, Harewood R, Matz M, Niksic M, et al. Global surveillance of trends in cancer survival 2000-14 (CONCORD-3): analysis of individual records for 37 513 025 patients diagnosed with one of 18 cancers from 322 population-based registries in 71 countries. Lancet. (2018) 391(10125):1023–75. doi: 10.1016/S0140-6736(17)33326-3
3. Zhang W, Xia W, Lv Z, Ni C, Xin Y, Yang L. Liquid biopsy for cancer: Circulating tumor cells, circulating free DNA or exosomes? Cell Physiol Biochem (2017) 41(2):755–68. doi: 10.1159/000458736
4. Pan B, Li X, Zhao D, Li N, Wang K, Li M, et al. Optimizing individualized treatment strategy based on breast cancer organoid model. Clin Transl Med (2021) 11(4):e380. doi: 10.1002/ctm2.380
5. Harris EER. Precision medicine for breast cancer: The paths to truly individualized diagnosis and treatment. Int J Breast Canc (2018) 2018:4809183. doi: 10.1155/2018/4809183
CrossRef Full Text | Google Scholar
6. Yin S, Xi R, Wu A, Wang S, Li Y, Wang C, et al. Patient-derived tumor-like cell clusters for drug testing in cancer therapy. Sci Transl Med (2020) 12(549):eaaz1723. doi: 10.1126/scitranslmed.aaz1723
7. Hoadley KA, Yau C, Hinoue T, Wolf DM, Lazar AJ, Drill E, et al. Cell-of-Origin patterns dominate the molecular classification of 10,000 tumors from 33 types of cancer. Cell. (2018) 173(2):291–304 e6. doi: 10.1016/j.cell.2018.03.022
8. Gao H, Korn JM, Ferretti S, Monahan JE, Wang Y, Singh M, et al. High-throughput screening using patient-derived tumor xenografts to predict clinical trial drug response. Nat Med (2015) 21(11):1318–25. doi: 10.1038/nm.3954
9. Stewart E, Federico SM, Chen X, Shelat AA, Bradley C, Gordon B, et al. Orthotopic patient-derived xenografts of paediatric solid tumours. Nature. (2017) 549(7670):96–100. doi: 10.1038/nature23647
10. Byrne AT, Alferez DG, Amant F, Annibali D, Arribas J, Biankin AV, et al. Interrogating open issues in cancer precision medicine with patient-derived xenografts. Nat Rev Canc (2017) 17(4):254–68. doi: 10.1038/nrc.2016.140
11. Rossi G, Manfrin A, Lutolf MP. Progress and potential in organoid research. Nat Rev Genet (2018) 19(11):671–87. doi: 10.1038/s41576-018-0051-9
12. Ding RB, Chen P, Rajendran BK, Lyu X, Wang H, Bao J, et al. Molecular landscape and subtype-specific therapeutic response of nasopharyngeal carcinoma revealed by integrative pharmacogenomics. Nat Commun (2021) 12(1):3046. doi: 10.1038/s41467-021-23379-3
13. Eisenhauer EA, Therasse P, Bogaerts J, Schwartz LH, Sargent D, Ford R, et al. New response evaluation criteria in solid tumours: revised RECIST guideline (version 1. 1). Eur J Cancer (2009) 45(2):228–47. doi: 10.1016/j.ejca.2008.10.026
14. Jiang S, Zhao H, Zhang W, Wang J, Liu Y, Cao Y, et al. An automated organoid platform with inter-organoid homogeneity and inter-patient heterogeneity. Cell Rep Med (2020) 1(9):100161. doi: 10.1016/j.xcrm.2020.100161
15. Cortazar P, Zhang L, Untch M, Mehta K, Costantino JP, Wolmark N, et al. Pathological complete response and long-term clinical benefit in breast cancer: the CTNeoBC pooled analysis. Lancet (2014) 384(9938):164–72. doi: 10.1016/S0140-6736(13)62422-8
16. Kuerer HM, Newman LA, Smith TL, Ames FC, Hunt KK, Dhingra K, et al. Clinical course of breast cancer patients with complete pathologic primary tumor and axillary lymph node response to doxorubicin-based neoadjuvant chemotherapy. J Clin Oncol (1999) 17(2):460–9. doi: 10.1200/JCO.1999.17.2.460
Keywords: breast cancer, individualized treatment, patient-derived tumor model, drug testing, case report
Citation: Xia W, Chen W, Fang S, Wu J, Zhang J and Yuan H (2022) Case report: Individualized treatment of advanced breast cancer with the use of the patient-derived tumor-like cell cluster model. Front. Oncol. 12:897984. doi: 10.3389/fonc.2022.897984
Received: 16 March 2022; Accepted: 11 October 2022; Published: 31 October 2022.
Reviewed by:
Copyright © 2022 Xia, Chen, Fang, Wu, Zhang and Yuan. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY) . The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Hongjun Yuan, [email protected]
Disclaimer: All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.
Ohio State nav bar
The Ohio State University
- BuckeyeLink
- Find People
- Search Ohio State
Pathophysiology
Normal physiology of the human breast.
Prior to sexual maturity, male and female breasts are structurally and functionally similar; they are both comprised of small immature nipples, fatty and fibrous tissue and several duct-like arrangements beneath the areola.
When puberty is underway in males and females, this is where the major structural development occurs. Male breasts remain unchanged due to the lack of high levels of estrogen and progesterone. Females, on the other hand, have significant changes occur due to an assortment of hormones (estrogen, growth hormone, insulin-like growth factor-1, progesterone, and prolactin) (p.739) that cause the female breast to develop into a lactating system.
The mature female breast’s foundational unit is the lobe (each breast contains 15-20) a system of ducts which is comprised of and supported by Cooper ligaments. Each lobe is made up of 20-40 lobules (glands that produce milk). The lobules contain alveolar cells, which are complicated spaces lined with epithelial cells that secrete milk and sub-epithelial cells that contract, passing milk into the arrangement of ducts that leads to the nipple (p. 739).
The lobes and lobules are enclosed and separated by muscle strands and adipose connective tissue which varies in amount depending on weight, genetics, endocrine factors and contributes to the diversity of breast size and shape.
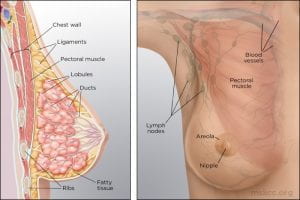
(Memorial Sloan Kettering Cancer Center)
During the reproductive years, breast tissue undergoes cyclic changes in response to hormonal changes of the menstrual cycle. After menopause, adipose deposits and connective tissue increases, glandular breast tissue becomes involuted, and breasts are reduced in size and form. Due to elevated aromatase (decreases circulating estrogen) there can be an increase in white adipose tissue inflammation (p.740).
The function of the female breast is primarily to provide a source of nourishment for the newborn; however, breasts are also a source of pleasurable sexual sensation and in Western cultures have become a sexual symbol (p.741).
(McCance, K. L., & Heuther, S. E. (2019). Pathophysiology: The biological basis for disease in adults and children (8th ed., pp.739-741). St. Louis, MO: Mosby.)
Pathophysiology of Breast Cancer
Except for skin cancer, breast cancer is the most common cancer in American women. Most breast cancer occurs in women older than 50 years. The major risk factors for breast cancer are classified as reproductive, such as nulliparity and pregnancy-associated breast cancer; familial, such as inherited gene syndromes; and environmental and lifestyle, such as hormonal factors and radiation exposure. Some examples of known carcinogenic agents with sufficient evidence in humans that contribute to the development of breast cancer are alcoholic beverages, diethylstilbestrol, estrogen-progestogen contraceptives, estrogen-progestogen menopausal therapy, X-radiation and γ-radiation (Rote, 2019). Other important factors are delayed involution of the mammary gland and increased breast density.
Overall, lifetime risk of breast cancer is reduced in parous women compared to nulliparous women, but pregnancy must occur at a young age. The influence of pregnancy on the risk of cancer also depends on family history, lactation postpartum, and overall parity. Breast gland involution after pregnancy and lactation uses some of the same tissue remodeling pathways activated during wound healing. The presence of macrophages in the involuting mammary gland contributes to carcinogenesis.
Most breast cancers are adenocarcinomas and first arise from the ductal/lobular epithelium as carcinoma in situ. Carcinoma in situ is an early-stage, noninvasive, proliferation of epithelial cells that is confined to the ducts and lobules, by the basement membrane. About 84% of all in situ disease is ductal carcinoma in situ (DCIS); the remainder is mostly lobular carcinoma in situ (LCIS) disease. Ductal carcinoma in situ (DCIS) refers to a heterogenous group of proliferative lesions limited to ducts and lobules without invasion to the basement membrane. DCIS occurs predominantly in women but can also occur in men. DCIS has a wide spectrum of risk for invasive cancers. Preinvasive lesions do not invariably progress to invasive malignancy. Lobular carcinoma in situ (LCIS) originates from the terminal duct-lobular unit. Unlike DCIS, LCIS has a uniform appearance; thus, the lobular structure is preserved. The cells grow in non-cohesive clusters, typically because of a loss of the tumor-suppressive adhesion protein E-cadherin . Also, unlike DCIS, LCIS is found as an incidental lesion from a biopsy and not mammography, is more likely to be present bilaterally.
(Winslow, 2012)
Breast cancer is a heterogeneous disease with diverse, molecular, genetic, phenotypic, and pathologic changes. Tumor heterogeneity results from the genetic, epigenetic, and microenvironmental influences (selective pressure) that tumor cells undergo during cancer progression. Cellular subpopulations from different sections of the same tumor vary in many ways including growth rate, immunogenicity, ability to metastasize, and drug response, demonstrating significant heterogeneity. The biological attributes of a tumor as a whole are strongly influenced by its subpopulation of cells with cellular populations communicating through paracrine or contact-dependent signaling (juxtacrine) from ligands and mediated from components of the microenvironment such as blood vessels, immune cells, and fibroblasts.
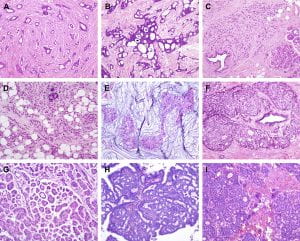
Figure 1. Histological special types of breast cancer preferentially oestrogen receptor positive. (A) Tubular carcinoma, (B) cribriform carcinoma, (C) classic invasive lobular carcinoma, (D) pleomorphic invasive lobular carcinoma, (E) mucinous carcinoma, (F) neuroendocrine carcinoma, (G) micropapillary carcinoma, (H) papillary carcinoma, (I) low grade invasive ductal carcinoma with osteoclast-like giant cells. (Weigelt, Geyer, & Reis-Filho, 2010)
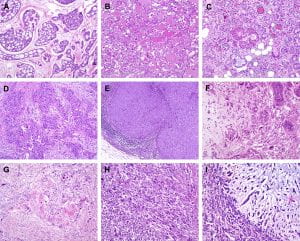
Figure 2. Histological special types of breast cancer preferentially oestrogen receptor negative. (A) Adenoid cystic carcinoma, (B) secretory carcinoma, (C) acinic-cell carcinoma, (D) apocrine carcinoma, (E) medullary carcinoma, (F) metaplastic carcinoma with heterologous elements, (G) metaplastic carcinoma with squamous metaplasia, (H) metaplastic spindle cell carcinoma, (I) metaplastic matrix-producing carcinoma. (Weigelt, Geyer, & Reis-Filho, 2010)
Gene expression profiling studies have identified major subtypes classified as luminal A, luminal B, HER2+, basal-like, Claudin-low, and normal breast. These subtypes have different prognoses and responses to therapy. Tumors can be stratified with gene expression profiles such as Oncotype Dx, Prosigna, and MammaPrint on the basis of genetic profiles. This information helps personalize breast cancer treatment and determine which women need aggressive systemic treatment for high-risk cancers versus close surveillance for indolent tumors.
Many models of breast carcinogenesis have been suggested and the expanding themes include (1) gene addiction, (2) phenotype plasticity, (3) cancer stem cells, (4) hormonal outcomes affecting cell turnover of mammary epithelium, stem cells, extracellular matrix, and immune function.
Cancer gene addiction includes oncogene addiction, whereby these driver genes play key roles in breast cancer development and progression. In non-oncogene addiction, these genes may not initiate cancer but play roles in cancer development and progression. Examples of key driver genes include HER2 and MYC, and examples of tumor-suppressor genes include TP53, BRCA1, and BRCA2. Once a founding tumor clone is established, genomic instability may assist through the establishment of other subclones and contribute to both tumor progression and therapy resistance.
Phenotypic plasticity is exemplified by a distinctive phenotype called epithelial-to-mesenchymal transition (EMT) . EMT is involved in the generation of tissues and organs during embryogenesis, is essential for driving tissue plasticity during development, and is hijacked during cancer progression. The EMT-associated programming is involved in many cancer cell characteristics, including suppression of cell death or apoptosis and senescence. It is reactivated during wound healing and is resistant to chemotherapy and radiation therapy. Remodeling or reprogramming of the breast during post-pregnancy involution is important because it involves inflammatory and “wound healing-like” tissue reactions known as reactive stroma or inflammatory stroma . The reactive stroma releases various signals and interleukins that affect nearby carcinoma cells, inducing these cells to activate their previously silent EMT programs. The activation is typically reversible (i.e., plasticity), and those EMT programs may revert through mesenchymal-epithelial (MET) to the previous phenotypic state before the induction of the EMT program. Reactive stroma increases the risk for tumor invasion and may facilitate the transition of carcinoma in situ to invasive carcinoma. Activation of an EMT program during cancer development often requires signaling between cancer cells and neighboring stromal cells. In advanced primary carcinomas, cancer cells recruit a variety of cell types into the surrounding stroma. Overall, increasing evidence suggests that interactions of cancer cells with adjacent tumor-associated stromal cells induce malignant phenotypes.
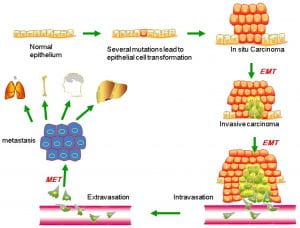
Figure 3. Putative EMT and MET in breast cancer progression. Normal epithelial cells undergo a series of transformational changes to become malignant tumor cells. Clonal proliferation of malignant cells gives rise to invasive carcinoma. Some of these cells undergo EMT and enter into the neighboring blood vessels or lymphatic vessels. These cells may remain in the circulation as circulating tumor cells or may extravasate at a distant site. The extravasated tumor cells form macrometastasis by a reverse mechanism known as MET. EMT, epithelial-mesenchymal transition; MET, mesenchymal-epithelial transition. (Liu, Gu, Shan, Geng, & Sang, 2016)
Using a mouse model of tumor heterogeneity, investigators demonstrated different clones within the heterogeneous population had distinct properties, such as the ability to dominate the primary tumor, or to contribute to metastatic populations, or to enter the lymphatic or vascular systems via vascular mimicry.
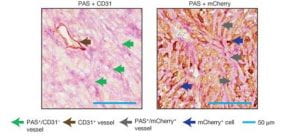
(Wagenblast et al., 2015)
Figure 4. Two adjacent sections of a mouse breast tumor. Tissue at left is stained so that normal blood vessels can be seen (brown arrow). Extending from these vessels are blood filled channels (green arrows). On the right, the tissue is stained for a fluorescent protein expressed by the tumor cells. Here it is seen that blood-filled channels are actually formed by tumor cells in a process known as vascular mimicry. The team demonstrate that the tumor cells lining these channels help drive metastasis, the process by which tumors spread. (Ravindran, 2019)
Invasion by primary tumor cells typically involves the collective migration of large cohesive groups into adjacent tissue rather than the scattering of individual carcinoma cells. However, still unknown are the precise events occurring at the invasive stage. Dormant carcinoma cells called minimal residual disease (MRD) appear to perpetuate carcinogenesis and form the precursors of eventual metastatic relapse and, sometimes, rapid cancer recurrence. Dormant cells have exited the cell cycle and are not proliferating. Thus current treatments that preferentially kill proliferating cells render dormant cells intrinsically more resistant and may remain after initial chemotherapy, radiotherapy, and surgery.
Emerging evidence supports three main prerequisites that must be met for metastatic colonization to succeed: the capacity to seed and maintain a population of tumor-initiating stem cells; the ability to create adaptive, organ-specific colonization programs; and the development of a supportive microenvironmental niche. Metastases may also occur early in the process of neoplastic transformation.
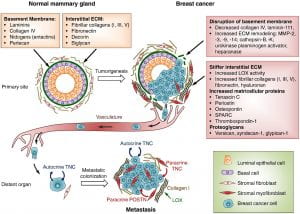
Figure 5 . Extracellular matrix (ECM) changes in breast cancer progression and metastasis. The primary components of the ECM in normal mammary gland are significantly changed in breast cancer. A desmoplastic reaction is associated with breast cancer development, due to the increased production of fibrous ECM by activated fibroblasts and cancer cells. The increased collagen deposition and crosslinking by lysyl oxidase (LOX) enzymes, together with the increased production of fibronectin and other ECM components, stiffens the ECM, which in turn promotes tumor aggressiveness. The basement membrane surrounding the mammary gland epithelium is broken down by ECM remodeling enzymes like MMPs, heparanase and others. Matricellular proteins that promote cancer cell fitness such as tenascin C, periostin, osteopontin, SPARC and thrombospondin-1 are also upregulated. Breast cancer cells from the primary tumor, that include cells with the ability to establish metastatic colonies, enter the blood circulation, disseminate and can reach distant sites. While the vast majority of disseminated cancer cells are eliminated or undergo dormancy due to the adverse environment, few cancer cells are able to resist the selective pressure and establish a metastatic colony. These cells may rely on signals from the ECM such as type I collagen (collagen I), crosslinked by LOX. Tenascin C (TNC) and periostin (POSTN), which are crucial ECM proteins of the metastatic niche, promote stem/progenitor pathways and metastatic fitness in disseminated breast cancer cells. (Insua-Rodríguez & Oskarsson, 2016)
The first clinical manifestation of breast cancer is usually a small, painless lump in the breast. Other manifestations include palpable lymph nodes in the axillae, dimpling of the skin, nipple and skin retraction, nipple discharge, ulcerations, reddened skin, and bone pain associated with bony metastases.
Treatment is based on the extent or stage of the cancer and includes surgery, radiation, chemotherapy, hormone therapy, and biologic therapy.
(Unless otherwise cited, all pathophysiology information was gathered from Danhausen, Phillippi, & McCance, 2019)
- Around the Practice
- Between the Lines
- Contemporary Concepts
- Readout 360
- Insights from Experts at Mayo Clinic on Translating Evidence to Clinical Practice
- Optimizing Outcomes in Patients with HER2+ Metastatic Breast Cancer

- Conferences
- Publications
- Career Center
Clinical Case Presentation: A 36-Year-Old Woman with Breast Cancer and Brain Metastases
- Ruta Rao, MD
Ruta Rao, MD, presents the case of a 36-year-old woman with metastatic HER2+ breast cancer and brain metastases.

EP: 1 . Clinical Case Presentation: A 36-Year-Old Woman with Breast Cancer and Brain Metastases
EP: 2 . Treatment Options in the Frontline Setting for Metastatic HER2+ Breast Cancer
EP: 3 . Second-Line and Third-Line Treatment Options for Metastatic HER2+ Breast Cancer
Ep: 4 . tucatinib for metastatic her2+ breast cancer and brain metastases: patient selection, ep: 5 . treatment options for her2+ breast cancer after progression on tucatinib, ep: 6 . clinical case presentation: a 53-year-old woman with metastatic er/pr+ her2+ breast cancer and brain metastases, ep: 7 . neratinib for metastatic her2+ breast cancer and brain metastases, ep: 8 . leptomeningeal metastases in her2+ breast cancer, ep: 9 . novel agents under evaluation for her2+ breast cancer and brain metastases, ep: 10 . clinical case presentation: a 66-year-old woman with er+ her2+ invasive ductal carcinoma and brain metastases, ep: 11 . trastuzumab deruxtecan treatment for metastatic her2+ breast cancer with brain metastases, ep: 12 . role of neurooncologists in management of her2+ breast cancer and brain metastases.

EP: 13 . Recap: Updates in Treatment of HER2-Positive Breast Cancer and Brain Metastases

Applying Updated Breast Cancer Findings From ASCO to Clinical Practice
Neil M. Iyengar, MD, and Paolo Tarantino, MD, discuss updated data on agents such as T-DXd and abemaciclib in breast cancer presented at 2024 ASCO.

39 The Influence of Reconstruction Type on Outcomes in Women Undergoing Mastectomy With Immediate Reconstruction: A Nationwide Study

Finding a Place for Exercise Oncology in the Treatment of Breast Cancer
Neil M. Iyengar, MD, spoke about the potential impact of exercise on patient-reported outcomes in cancer and achieving work-life balance.

T-DXd Boosts PFS Vs Chemo in HR+, HER2-Low Metastatic Breast Cancer
Secondary end points such as overall survival also appear to favor T-DXd among this breast cancer population in the phase 3 DESTINY-Breast06 trial.

Inavolisib Combo Reduces Time to Subsequent Treatment in Breast Cancer
Data also show a longer median time to deterioration for patients in the inavolisib arm in phase 3 INAVO120 trial.
2 Commerce Drive Cranbury, NJ 08512
609-716-7777

- Member Benefits
- Communities
- Grants and Scholarships
- Student Nurse Resources
- Member Directory
- Course Login
- Professional Development
- Organizations Hub
- ONS Course Catalog
- ONS Book Catalog
- ONS Oncology Nurse Orientation Program™
- Account Settings
- Help Center
- Print Membership Card
- Print NCPD Certificate
- Verify Cardholder or Certificate Status
- Trouble finding what you need?
- Check our search tips.
- Clinical Journal of Oncology Nursing
- Number 6 / December 2021
- Supplement, December 2021, Survivorship Care
Breast Cancer: Survivorship Care Case Study, Care Plan, and Commentaries
Amber Whitton-Smith
Rachael Schmidt
Kristie Howlett
Rachée Hatfield
This case study highlights the patient’s status in care plan format and is followed by commentaries from expert nurse clinicians about their approach to manage the patient’s long-term or chronic cancer care symptoms. Finally, an additional expert nurse clinician summarizes the care plan and commentaries, emphasizing takeaways about the patient, the commentaries, and additional recommendations to manage the patient. As can happen in clinical practice, the patient’s care plan is intentionally incomplete and does not include all pertinent information. Responding to an incomplete care plan, the nurse clinicians offer comprehensive strategies to manage the patient’s status and symptoms. For all commentaries, each clinician reviewed the care plan and did not review each other’s commentary. The summary commentary speaks to the patient’s status, care plan, and nurse commentaries.
Become a Member
Purchase this article.
has been added to your cart
Related Articles
Dna methylation of bdnf and rasa2 genes is associated with cognitive function in postmenopausal women with breast cancer, distress, pain, and nausea on postoperative days 1 and 14 in women recovering from breast-conserving surgery: a repeated-measures study, gastrointestinal and neuropsychological symptoms are associated with distinct vomiting profiles in patients receiving chemotherapy.

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- HHS Author Manuscripts
A case-case analysis of women with breast cancer: predictors of interval vs screen-detected cancer
Nickolas dreher.
1 University of California San Francisco, San Francisco, CA, USA
2 The Icahn School of Medicine at Mount Sinai, New York, NY, USA
Madeline Matthys
Edward hadeler.
3 University of Miami Miller School of Medicine, Miami, FL, USA
Yiwey Shieh
Irene acerbi, fiona m. mcauley, michelle melisko, martin eklund.
4 Karolinska Institutet, Stockholm, Sweden
Jeffrey A. Tice
Laura j. esserman, laura j. van ‘t veer.
Authors’ contributions: All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by Nickolas Dreher, Madeline Matthys, and Edward Hadeler. The first draft of the manuscript was written by Nickolas Dreher and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript.
Associated Data
The Breast Cancer Surveillance Consortium (BCSC) model is a widely-used risk model that predicts five- and ten-year risk of developing invasive breast cancer for healthy women aged 35–74 years. Women with high BCSC risk may also be at elevated risk to develop interval cancers, which present symptomatically in the year following a normal screening mammogram. We examined the association between high BCSC risk (defined as the top 2.5% by age) and breast cancers presenting as interval cancers.
We compared the mode of detection and tumor characteristics of patients in the top 2.5% BCSC risk by age with age-matched (1:2) patients in the lower 97.5% risk. We constructed logistic regression models to estimate the odds ratio (OR) of presenting with interval cancers, and poor-prognosis tumor features, between women from the top 2.5% and bottom 97.5% of BCSC risk.
Our analysis included 113 breast cancer patients in the top 2.5% of risk for their age and 226 breast cancer patients in the lower 97.5% of risk. High-risk patients were more likely to have presented with an interval cancer within one year of a normal screening, OR 6.62 (95% CI 3.28–13.4, p<0.001). These interval cancers were also more likely to be larger, node positive, and higher stage.
Conclusion:
Breast cancer patients in the top 2.5% of BCSC risk for their age were more likely to present with interval cancers. The BCSC model could be used to identify healthy women who may benefit from intensified screening.
Introduction
Interval cancers are invasive breast cancers that present symptomatically within 12 months of a normal screening mammogram. These cancers include both those that develop after a mammogram and those that were not detected (but did exist) at the previous screening mammograms. Interval cancers tend to be more aggressive and faster-growing than screen-detected cancers.[ 1 – 4 ] Identifying women who are at increased risk for interval breast cancers could inform screening strategies, as these women may benefit from supplemental or more frequent screening and risk reduction. However, no consensus regarding how to risk-stratify women for interval breast cancer risk exists. The Breast Cancer Surveillance Consortium (BCSC) model is a validated and widely used risk prediction tool that predicts five- and ten-year risk of developing invasive breast cancer for women age 35–74.[ 5 ] It bases risk prediction on age, race/ethnicity, presence of first degree relative with breast cancer, prior biopsies/benign breast disease, and Breast Imaging-Reporting and Data System (BI-RADS) breast density.[ 5 , 6 ] Past work by Kerlikowske et al. has suggested that the combination of BCSC risk and BI-RADS breast density is one method upon which risk-stratification for interval cancer could be based.[ 7 ]
However, both the BCSC model and breast density itself are correlated with age: as age increases, BCSC score increases and breast density decreases. Providers may be wary of basing recommendations for screening frequency and modality on risk models (such as BCSC) that may enrich for increased screening as age increases. Further, tumor characteristics and morbidity vary by age, with younger women being at increased risk of developing poor prognosis tumors and interval cancers.[ 7 – 9 ] In contrast to using an absolute risk cutoff to identify high risk women, an alternative method is to use age-specific cutoffs. Age-specific BCSC risk distributions are generated directly by the BCSC, and aggregate 5-year age groups have been described in the literature.[ 5 ] The WISDOM study, run by the Athena Breast Health Network, uses these distributions to establish a threshold of the top 2.5% of risk for each age group to initiate counseling on prevention interventions and annual screening. Prior thresholds were not sufficiently high to motivate interest in embarking on risk reduction strategies.[ 10 ] The top 2.5% by age threshold consistently identifies women with lifetime risk of 23–28%, and 20% of these women elect to pursue prevention interventions. This is why it was chosen for the high risk threshold to trigger for annual screening and prevention counseling in WISDOM.[ 10 ]
This study’s primary aim is to validate this top 2.5% by age threshold by determining if these women are more likely to present with interval cancers rather than screen-detected cancers. We also evaluated whether these interval cancers have more aggressive features to confirm the clinical relevance of detecting interval cancers.
Patients and Methods
We conducted a case-case analysis of women treated for invasive breast cancer at the University of California San Francisco Breast Care Center (UCSF BCC). This study included only women with a confirmed diagnosis of invasive breast cancer previously undergoing standard mammography screening. Between 2013 and 2017, 896 patients completed the Athena intake questionnaire (described in Measures ) in the BCC and had available BI-RADS breast density and pathology data. We identified the 180 women in the top 2.5% of BCSC risk for their age. Women were excluded from the study if they deviated from standard screening intervals by having an increased screening frequency (more than 1 mammogram per year) or if they had an “interval” cancer detected more than one year after their prior clear mammogram. Ultimately, information on mode of detection (screen detected versus interval breast cancer) was available for 113 women in the top 2.5% of risk for their age. We then used a random number generator to select age-matched (±1 year) women from the lower 97.5% who also had method of detection available. ( Figure 1 ).

Selection of the study group from women seen at the UCSF Breast Care Center from 2013–2017. Top 2.5% threshold determined from distributions of BCSC 5-year risk estimates.
The UCSF BCC is part of the Athena Breast Health Network, a breast cancer clinical care and research collaborative that includes breast care clinics from five University of California hospitals and Sanford Health in South Dakota.[ 11 ] Athena collects patient characteristics and outcome data across the entire care spectrum from screening and prevention to treatment and survivorship. At the UCSF BCC, questionnaires are distributed to all patients presenting with a new breast problem.
The Athena intake questionnaire at the BCC collects race/ethnicity, family history, personal cancer history, history of prior biopsies, presence of comorbidities, and psychosocial and physical quality of life metrics.[ 12 ] These questionnaires contain all the variables included in the BCSC model ( http://tools.bcsc-scc.org/BC5yearRisk/ ) except for BI-RADS density. Using the electronic medical record, we exported BI-RADS density based on the last negative screening mammogram prior to diagnosis and used it for the BCSC risk assessment. While the BCSC model is intended for women without a history of breast cancer, this allowed for a retrospective estimate of each patient’s 5-year risk of developing cancer at the approximate time of their diagnosis with the assumption that breast density stayed relatively stable between the last negative mammogram and density.[ 13 ] The 97.5 th BCSC risk percentile for each age ( Supplementary Table A ) was estimated by applying the BCSC risk calculator to data collected from more than six million mammograms from eight breast imaging registries across the country.[ 14 ]
The BCSC risk score was calculated for eligible women (those between the ages of 40–74 without a diagnosis of breast cancer prior to the current diagnosis) who completed the online intake questionnaire and whose BI-RADS density was available ( Figure 1 ). These BCSC scores were based on the patient’s age at time of intake. Medical records for all patients in the top 2.5% of risk for their age and two age-matched (±1 year) cases from the bottom 97.5% of risk were reviewed to determine method of cancer detection.
The UCSF Cancer Center registry contains pathology and outcome data linked to state and national registries, and has been described previously.[ 15 , 16 ] We collected information on each patient’s histology, grade, stage, nodal involvement, hormone receptor status, and tumor size from the Registry. If data were not available for a patient, we imported these fields from the UCSF surgical registry. The UCSF BCC maintains an internal surgical registry that is updated weekly with pathology reports from recent surgeries. This dataset, updated in near real-time, was included to capture data that were not yet reported in other registries.
Our primary outcome focused on interval cancers, defined as invasive breast cancers that presented within one year of a normal mammogram, BI-RADS score 1 or 2. Tumor characteristics including hormone receptor status, grade, size, nodal involvement and stage were imported from the registries based on patient medical record number and approximate diagnosis date.
Statistical Analysis
We compared the proportion of interval cancers between the two age-matched groups using conditional logistic regressions in R. We also used logistic regressions to compare tumor characteristics between interval cancers and screen-detected cancers. All tests were two-sided with alpha of 0.05.
In addition to comparing patients in the top 2.5% of risk for their age to patients from the lower 97.5%, we examined two additional risk stratification criteria from the literature: patients with extremely dense breasts (BI-RADS d) or a very high BCSC score irrespective of age (>4.00% 5-year risk of developing breast cancer).[ 7 ] This was an adjunct analysis included to address potential questions from the reader. However, it is important to note that the sample used in this study is not matched based on these two criteria.
Patient Characteristics
Of the 339 patients included in the final analysis, 113 fell in the top 2.5% of risk for their age, and they were compared to 226 from the lower 97.5% of risk ( Figure 1 ). Table 1 summarizes demographic information from the patients included in the analysis. Women in the top 2.5% of risk for their age tended to have higher breast density and more frequently reported a first degree relative with breast cancer and a personal history of breast biopsy (p<0.001 for all comparisons).
Baseline characteristics and demographic data for women in the top 2.5% of risk for their age (n=113) and age-matched women from the lower 97.5% (n=226).
| Characteristic | BCSC High Risk (Top 2.5% by Age) | BCSC Lower Risk (Lwr 97.5% by Age) | P-value |
|---|---|---|---|
| Mean age (range) | 57 (40–73) | 57 (40–73) | Matched |
| Mean BCSC score (SD) | 3.9 (1.3) | 2.0 (0.72) | <0.001 |
| BCSC score distribution | <0.001 | ||
| Low (0%–<1.00%) | 0 (0%) | 23 (10%) | |
| Average (1.00%–1.66%) | 0 (0%) | 65 (29%) | |
| Intermediate (1.67%–2.49%) | 13 (11%) | 92 (41%) | |
| High (2.50%–3.99%) | 54 (48%) | 46 (20%) | |
| Very high (≥4.00%) | 46 (41%) | 0 (0%) | |
| Breast density distribution | <0.001 | ||
| BI-RADS a (mostly fatty) | 1 (1%) | 20 (9%) | |
| BI-RADS b | 26 (23%) | 87 (39%) | |
| BI-RADS c | 62 (55%) | 98 (43%) | |
| BI-RADS d (extremely dense) | 24 (21%) | 21 (9%) | |
| First-degree relative with breast cancer | 59 (52%) | 36 (16%) | <0.001 |
| History of breast biopsy | 72 (64%) | 88 (39%) | <0.001 |
| Mean body mass index (SD) | 23.9 (5.2) | 25.9 (6.1) | 0.003 |
| Race: | 0.004 | ||
| White | 92 (81%) | 157 (70%) | |
| Asian | 8 (7%) | 41 (18%) | |
| Black or African American | 0 (0%) | 9 (4%) | |
| Mixed race or other | 13 (12%) | 19 (8%) | |
Interval cancer risk by BCSC risk group
Patients from the top 2.5% of risk for their age were more likely to present with an interval cancer within one year of a normal screening mammogram compared to patients in the lower 97.5% of risk, OR 6.62 (95% CI 3.28–13.4, p<0.001) ( Table 2 ). Similar results were seen when we expanded the analysis to include “late-interval” cancers, those discovered within two years of a normal screening mammogram.
Association between three risk stratification criteria and interval cancers. The three risk stratification criteria included the BCSC top 2.5%, BI-RADS d (extremely dense), or BCSC 5-year cancer risk >4.00% (very high).
| Primary Risk Stratification Criteria | Interval Cancers in High-risk Group | Interval Cancers in Low-risk Group | Odds Ratio | Confidence Interval | P-value |
|---|---|---|---|---|---|
| BCSC top 2.5% n=113/339 Avg age=57 Avg BCSC (SD)=3.9 (1.3) | 40 (35%) | 21 (9%) | 6.62 | 3.28 – 13.4 | <0.001 |
| BI-RADS d N=45/339 Avg age=51 Avg BCSC (SD)=2.6 (1.2) | 18 (40%) | 43 (15%) | 3.89 | 1.98 – 7.67 | <0.001 |
| BCSC very high, >4.00% n=46/339 Avg age=62 Avg BCSC (SD)=5.2 (1.1) | 15 (30%) | 46 (16%) | 2.60 | 1.30 – 5.19 | 0.007 |
We also compared the top 2.5% by age threshold to two other common risk stratification criteria: extremely dense breasts (BI-RADS d) or a very high BCSC score irrespective of age (>4.00% 5-year risk of developing breast cancer) ( Table 2 ). The BCSC top 2.5% by age threshold was most strongly associated with interval cancer risk. The mean age for the BCSC top 2.5% threshold was between that of extremely dense breasts and 4% 5-year BCSC risk. Furthermore, a substantial number of women in the top 2.5% of risk for their age would not have been identified by these other risk cutoffs. Specifically, 49 of 113 (43%) women would only be flagged for increased risk using the top 2.5% by age threshold – and these women show a similarly high percentage of interval cancers (32.7%).
Tumor characteristics of interval cancers
Interval cancers had more aggressive features than cancers detected via screening mammogram. Interval cancers were more likely to be lymph node positive (odds ratio, OR 3.24, 95% CI 1.76 – 5.96, p<0.001) and larger than two centimeters (OR 3.49, 95% CI 1.82 – 6.70, p<0.001). Thus, they were more likely to be stage II or higher (OR 4.88, 95% CI 2.34 – 10.2, p<0.001). Likewise, interval cancers tended to be grade 3 and hormone receptor negative, although these trends were not statistically significant ( Table 3 ).
Tumor characteristics of interval cancers compared to screen-detected cancers from 339 breast cancer patients seen at the UCSF Breast Care Center. Certain components of pathology were not available for all patients, most notably tumor size. The ratios represent number of patients with the characteristic per those with data available.
| Characteristic | Interval Cancers (n=61) | Screen-detected Cancers (n=278) | Odds Ratio | Confidence Interval | Difference |
|---|---|---|---|---|---|
| Size > 2 cm | 27/48 | 52/193 | 3.49 | 1.82 – 6.70 | <0.001 |
| Lymph node invasion present | 24/61 | 43/258 | 3.24 | 1.76 – 5.96 | <0.001 |
| Stage > 1 | 37/48 | 73/179 | 4.88 | 2.34 – 10.2 | <0.001 |
| Grade > 2 | 22/60 | 71/270 | 1.62 | 0.90 – 2.93 | 0.108 |
| Hormone receptor negative | 9/61 | 29/269 | 1.43 | 0.64 – 3.21 | 0.382 |
In this study, we compared breast cancer patients in the BCSC top 2.5% of risk for their age to patients from the remaining 97.5%. We found that women in the top 2.5% of risk for their age, who have double the risk of getting breast cancer relative to the average women, had more than six-fold higher odds of presenting with interval cancers. Furthermore, the interval cancers detected in this study were of clinical relevance as they followed trends outlined in the literature and tended to have more aggressive features.
Our study extends the literature by validating an alternative approach to risk stratification, which considers the distribution of risk among similarly aged women, as a predictor of interval cancer risk.[ 17 ] This allows providers to identify women at high risk without selecting certain age groups, as would BCSC score or density alone. A numeric threshold, identical for all ages, also fails to recognize the range of risk in each age group and does not account for lifetime risk. A 1.5% 5-year risk in a 40-year-old, for example, is associated with a much higher lifetime risk than a 1.5% 5-year risk in a 75-year-old. Many patients in the top 2.5% of risk for their age have extremely dense or heterogeneously dense breasts, which may mask tumors and contribute to interval cancer prevalence. However, if density alone drove this effect, we would expect to see the highest interval cancer prevalence in patients with BI-RADS d density. To the contrary, the data presented in this manuscript demonstrate that the top 2.5% by age threshold had the highest proportion of interval cancers when compared to other previously reported risk stratification criteria such as extremely dense breasts (BIRADS d) or a 4% absolute 5-year risk. However, it is important to recognize that this study was not designed to compare these criteria, and in creating the BIRADS d or 4% absolute risk groups age-matching was broken. Further research is necessary to effectively compare risk-stratification criteria; this analysis was included to address common questions from readers but is largely beyond the scope of this work.
We also replicated previous work showing interval cancers to be enriched for aggressive features and linked to poor prognosis.[ 7 , 18 ] In a large case-case study of 431,480 women, Kirsh et al. found interval cancers were more likely to be higher stage, higher grade, estrogen receptor negative, and progesterone receptor negative when compared to screen-detected tumors. We replicated these findings for stage, and while our study may not have been sufficiently powered to detect significant differences in grade and hormone receptor status, it should be noted that trends in our results were aligned with previous findings in the literature.[ 1 , 2 ]
Our work should be interpreted in light of several limitations. First, this was a case-case analysis and our sample size may have limited the precision of our estimates and ability to detect small differences between groups. Larger cohort studies in multiracial/multiethnic populations are needed to validate our main findings. Such studies would also make our work more generalizable, given our study predominately included white patients. Second, we did not review the most recent mammogram to confirm that the tumor represented a “true” interval cancer – rather than merely a missed tumor due to human error in the initial reading. However, missed interval cancers have also been shown to have more aggressive features compared to screen-detected cancers, although to a lesser extent.[ 1 ] Furthermore, these data reflect the limits of what is understood in clinical practice. Ultimately, if this sampling includes tumors that should have been screen-detected, it should only underestimate the unique characteristics of interval cancers. Third, women with higher risk are often offered more intensive screening due to the presence of risk factors such as dense breasts or positive family history. This may also bias these results, but we expect the bias to be toward the null, given that we expect increased screening to decrease interval cancer prevalence in high-risk groups.
Our results have several important clinical implications. Since interval cancers tend to present at later stages and lead to worse prognosis, it follows that a goal of breast cancer screening should be to detect interval cancers at an earlier, more treatable stage. However, increasing screening frequency for all women would likely lead to unsustainable resource usage and unintended effects such as false positives. As such, there is a clear need for risk stratification criteria that can identify women at elevated risk of interval cancers so that they can receive targeted screening and prevention. However, providers may be wary of using existing criteria that tend to select specific age groups for a variety of reasons – such as the prevalence of indolent tumors in older women.[ 19 , 20 ] Our results suggest that a simple top 2.5% by age threshold, based on a widely used risk-assessment tool, may effectively identify women with higher odds of developing interval cancers. This threshold is already being used to target preventative efforts (such as chemoprevention and lifestyle changes) by providers in the Athena Breast Health Network and in the WISDOM (Women Informed to Screen Depending on Measures of risk) Study, a randomized trial of personalized versus annual breast cancer screening that uses the BCSC model as well as genetic predisposition (mutations and polygenic risk).[ 21 , 22 ] Women in the personalized arm who are in the top 2.5% of risk for their age are assigned to annual screening and active outreach for risk reduction counseling; those whose 5-year risk is over 6% get screening every 6 months, alternating annual mammography with annual MRI.
Future work should aim to validate whether the top 2.5% by age threshold is associated with a similar increase in the likelihood of interval cancers in large cohort studies. These studies may also determine that a different sensitivity is optimal, such as top 1% or 5% by age. Cohort studies should ideally be powered to compare alternative risk-stratification criteria and examine the link between BCSC score and other features of aggressiveness, such as HER2 positivity, triple-negative/basal subtype, or high grade or proliferation.
Implications
Breast cancer patients whose BCSC risk, at the time they were diagnosed with breast cancer, was in the top 2.5% of predicted breast cancer risk for their age are significantly more likely to have their cancers detected in the interval between screening mammograms. These interval cancers were more likely to be higher grade and later stage, and thus may be linked to poor prognosis. Women in this elevated-risk category may benefit from tailored screening strategies or preventative interventions such as chemoprevention. A prospective validation is underway in the WISDOM study.
Supplementary Material
Acknowledgments.
We are extremely grateful to Karla Kerlikowske and her team at the San Francisco Mammography Registry (SFMR) for their guidance contextualizing this research and their willingness to collaborate. The SFMR provided access to data that was not ultimately used in this study. We would also like to thank Ann Griffin from the UCSF Cancer Registry and Patrick Wang from the UCSF Breast Care Center Internship Program. Data collection and sharing was supported by the National Cancer Institute-funded Breast Cancer Surveillance Consortium (HHSN261201100031C). You can learn more about the BCSC at: http://www.bcsc-research.org/ . Yiwey Shieh was supported by funding from the National Cancer Institute (1K08CA237829) and the MCL consortium. Dr. Esserman is supported by funding from the NCI MCL consortium (U01CA196406). We would also like to thank the dedicated Athena investigators and advocates for their continued work and support.
Yiwey Shieh was supported by funding from the National Cancer Institute (1K08CA237829) and the MCL consortium. Laura Esserman is supported by funding from the NCI MCL consortium (U01CA196406).
Conflicts of Interest: The authors declare no potential conflicts of interest.
Ethics approval: This work was approved by the UCSF Institutional Review Board and the study was performed in accordance with the ethical standards as laid down in the 1964 Declaration of Helsinki and its later amendments.
Consent to participate: All participants consented to have their data used for research that may result in publication.
Consent for publication: All participants consented to have their data used for research that may result in publication.
Availability of data and material: The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
Code availability: Code used in this analysis will be made available from the corresponding author on reasonable request.
We have a new app!
Take the Access library with you wherever you go—easy access to books, videos, images, podcasts, personalized features, and more.
Download the Access App here: iOS and Android . Learn more here!
- Remote Access
- Save figures into PowerPoint
- Download tables as PDFs

Chapter 16: Breast Pathology
Chad A. Livasy
- Download Chapter PDF
Disclaimer: These citations have been automatically generated based on the information we have and it may not be 100% accurate. Please consult the latest official manual style if you have any questions regarding the format accuracy.
Download citation file:
- Search Book
Jump to a Section
Introduction.
- BENIGN BREAST DISEASE
- CARCINOMA OF THE BREAST
- Full Chapter
- Supplementary Content
A 32-year-old G4P4 woman presents with complaints of a new lump in her left breast. Her past medical history is negative for a family history of breast carcinoma. Physical examination reveals a 3 cm firm, ill-defined mass that is tender to palpation. Ultrasound studies demonstrate a 4 cm solid-appearing mass with ill-defined borders. Due to the solid-appearing nature of the lesion and ill-defined borders, the lesion is categorized as suspicious and biopsy is recommended. Ultrasound-guided core biopsy is performed yielding the histology demonstrated in Figure 16-1 .
Pathologic diagnosis: Granulomatous mastitis.
FIGURE 16-1
Granulomatous mastitis. The breast stroma is involved by a dense inflammatory process consisting of dense aggregates of histiocytes (arrow) and a background of lymphocytes.

Normal Anatomy and Histology
The breast lies anterior to the chest wall over the pectoralis major muscle and typically extends from the second to the sixth rib in the vertical axis and from the sternal edge to the midaxillary line in the horizontal axis. Bundles of dense fibrous connective tissue, the suspensory ligaments of Cooper, extend from the skin to the pectoral fascia and provide support for the breast. At puberty, estradiol and progesterone levels increase to initiate breast development. The adult female breast consists of a series of branching ducts that terminate in lobules. The arrangement of these structures resembles a branching tree with 5–10 primary milk ducts in the nipple, 20–40 segmental ducts, and 10–100 subsegmental ducts that end in glandular units called terminal-duct lobular units (TDLU) ( Figure 16-2 ). The TDLU represents the functional unit of the breast ( Figure 16-3 ). During lactation, there is a dramatic increase in the number of lobules, and the epithelial cells in the TDLU undergo secretory changes consisting of cytoplasmic vacuoles ( Figure 16-4 ). The accumulated secretions are then transported via the ductal system to the nipple. When lactation ceases, the lobules involute and return to their normal resting appearance. The mammary ducts and lobules are embedded within a stroma composed of varying amounts of fibrous and adipose tissue. The stromal component comprises the major portion of the nonlactating adult breast, consisting of lobular stroma and interlobular stroma. The proportions of fibrous and adipose tissue vary with age and among individuals and may affect the sensitivity and specificity of mammographic studies. During menopause, as a result of reduction in estrogen and progesterone, there is involution and atrophy of the TDLUs associated with loss of the specialized intralobular stroma. The postmenopausal breast is characterized by marked reduction in the glandular and fibrous stroma components, typically with concomitant increase in stromal adipose tissue.
FIGURE 16-2
Get free access through your institution, pop-up div successfully displayed.
This div only appears when the trigger link is hovered over. Otherwise it is hidden from view.
Please Wait
- Open access
- Published: 06 June 2024
Multi-stage optimization strategy based on contextual analysis to create M-health components for case management model in breast cancer transitional care: the CMBM study as an example
- Hong Chengang 1 ,
- Wang Liping 1 ,
- Wang Shujin 1 ,
- Chen Chen 1 ,
- Yang Jiayue 1 ,
- Lu Jingjing 1 ,
- Hua Shujie 1 ,
- Wu Jieming 1 ,
- Yao Liyan 1 ,
- Zeng Ni 1 ,
- Chu Jinhui 1 &
- Sun Jiaqi 1
BMC Nursing volume 23 , Article number: 385 ( 2024 ) Cite this article
173 Accesses
Metrics details
None of the early M-Health applications are designed for case management care services. This study aims to describe the process of developing a M-health component for the case management model in breast cancer transitional care and to highlight methods for solving the common obstacles faced during the application of M-health nursing service.
We followed a four-step process: (a) Forming a cross-functional interdisciplinary development team containing two sub-teams, one for content development and the other for software development. (b) Applying self-management theory as the theoretical framework to develop the M-health application, using contextual analysis to gain a comprehensive understanding of the case management needs of oncology nursing specialists and the supportive care needs of out-of-hospital breast cancer patients. We validated the preliminary concepts of the framework and functionality of the M-health application through multiple interdisciplinary team discussions. (c) Adopting a multi-stage optimization strategy consisting of three progressive stages: screening, refining, and confirmation to develop and continually improve the WeChat mini-programs. (d) Following the user-centered principle throughout the development process and involving oncology nursing specialists and breast cancer patients at every stage.
Through a continuous, iterative development process and rigorous testing, we have developed patient-end and nurse-end program for breast cancer case management. The patient-end program contains four functional modules: “Information”, “Interaction”, “Management”, and “My”, while the nurse-end program includes three functional modules: “Consultation”, “Management”, and “My”. The patient-end program scored 78.75 on the System Usability Scale and showed a 100% task passing rate, indicating that the programs were easy to use.
Conclusions
Based on the contextual analysis, multi-stage optimization strategy, and interdisciplinary team work, a WeChat mini-program has been developed tailored to the requirements of the nurses and patients. This approach leverages the expertise of professionals from multiple disciplines to create effective and evidence-based solutions that can improve patient outcomes and quality of care.
Peer Review reports
Female breast cancer is the second leading cause of global cancer incidence in 2022, with an estimated 2.3 million new cases, representing 11.6% of all cancer cases [ 1 ]. Due to surgical trauma, side effects of drugs, fear of the recurrence or metastasis of breast cancer, changes in female characteristics, and lack of knowledge, patients with breast cancer frequently experience a series of physical and psychological health problems [ 2 , 3 , 4 , 5 , 6 ]. These health problems seriously affected patients’ life and work [ 7 , 8 ]. At present, community nursing in China is still in the developing stage, and the oncology specialty nursing service capacity of community nurses is not enough to deal with the health problems of breast cancer patients. It made continuous care for out-of-hospital breast cancer patients a weak link in the Chinese oncology nursing service system.
Nowadays, case management is employed to manage health problems for out-of-hospital breast cancer patients worldwide [ 9 , 10 , 11 , 12 , 13 , 14 , 15 ]. Case management involves regular telephone follow-ups and home visits by case management nurses to provide educational support to patients, thereby ensuring uninterrupted continuity of care [ 16 , 17 ]. The home visits and organization of patient information required for case management tasks consume a significant amount of time, manpower, and material resources [ 17 ]. In China, case management services are primarily undertaken by oncology nursing specialists from tertiary hospitals in their spare time [ 18 ]. However, the shortage of nurses has consistently been one of the major challenges facing the nursing industry in China, especially in tertiary hospitals [ 19 ]. Consequently, the implementation and promotion of case management in China also face great difficulties in reality [ 20 ].
The Global Observatory for eHealth (GOe) of the World Health Organization (WHO) defines mobile health (M-Health) as “medical and public health practice supported by mobile devices, such as mobile phones, patient monitoring devices, personal digital assistants (PDAs), and other wireless devices” [ 21 , 22 ]. With the development of digital technology and the COVID-19 pandemic in 2019, M-Health applications were further integrated into healthcare services, which increased the demand for M-Health applications in turn [ 23 , 24 ]. Compared with the traditional health service model, M-Health service model has the advantages of high-level informatization, fast response speed, freedom from time and location constraints, and resource-saving, etc. In the context of limited nursing human resources, M-Health service provides a new solution for the case management of out-of-hospital breast cancer patients [ 23 , 25 , 26 ].
Researchers have developed a range of M-Health applications targeting breast cancer patients. To our knowledge, none of these developed M-Health applications are designed for case management nursing services.
Early M-Health applications were mostly designed for single interventional goals, such as health education, medication compliance, self-monitoring, etc. Larsen et al. applied a M-Health application to monitor and adjust the dosage of oral chemotherapy drugs in breast cancer patients, and the results suggested that the treatment adherence was effectively improved [ 27 ]. Heo and his team successfully promoted self-breast-examination behavior in women under 30 years old using a M-Health application [ 28 ]. Mccarrol carried out a M-Health diet and exercise intervention in overweight breast cancer patients and found that the weight, BMI, and waist circumference of the intervention group decreased after one month [ 29 ]. Smith’s team found that their application promoted the adoption of healthy diet and exercise behaviors among breast cancer patients [ 30 ]. The application designed by Eden et al. enhanced the ability of breast cancer patients receiving chemotherapy to recognize adverse drug reactions [ 31 ]. Keohane and colleagues designed a health educational application based on the best practices and it proved effective in improving breast cancer-related knowledge [ 32 ]. The guideline-based M-Health application developed by Eden et al. optimized breast cancer patients’ individualized health decision-making regarding mammography [ 33 ].
With the progress of computer technology and the emphasis on physical and mental rehabilitation of breast cancer patients, some universities [ 34 , 35 ] in China have separately developed M-Health applications for comprehensive health management, which provide access to online communication, health education, and expert consultation.
Analyzing these developed applications deeply, three factors could be found that hindered the promotion of applications in real life. Firstly, the developing procedure usually lacks contextual analysis based on the actual usage context during the design phase. Secondly, there is a lack of consistent and long-term monitoring and operation staff in the subsequent program implementation. These factors may be the main reasons why many M-Health applications face difficulties in promotion and continuous operation after the research phase. Furthermore, as applications need to be installed on patients’ smartphones, certain hardware requirements, such as memory, may also pose restrict the adoption of M-Health applications to some extent.
In order to meet the needs of supportive care for out-of-hospital breast cancer patients and the needs of case management for oncology nurse specialists, we formed a multidisciplinary research team and collaboratively developed a WeChat mini-program for breast cancer case management in the CMBM (M-health for case management model in breast cancer transitional care) project. WeChat is chosen as the program development platform based on the following considerations. Firstly, WeChat is the most popular and widely used social software in China. As of December 31, 2020, the monthly active users of WeChat have exceeded 1.2 billion, and the daily active users of WeChat mini-programs exceeded 450 million [ 36 ]. Secondly, users can access and use the services of the mini-program directly within the WeChat platform, without the need to download or install additional mobile applications. This reduces the hardware requirements for software applications. The above two factors allow for a positive user experience and a realistic foundation for software promotion.
The purpose of this study is to describe the process of developing a tailored M-health component for the case management model in breast cancer transitional care and to highlight methods for solving the common obstacles faced during the application of M-health nursing service.
Methods and results
The development process was conducted in four steps: (a) An interdisciplinary development team was formed, consisting of two sub-teams dedicated to content and software development. (b) Using the self-management theory as the theoretical framework, contextual analysis was used to understand the case management needs of oncology nursing specialists and the supportive care needs of out-of-hospital breast cancer patients. Through iterative discussion within the interdisciplinary team, the preliminary conception of the application framework and function was formed. (c) A multi-stage optimization strategy was adopted to develop and regularly update the WeChat mini-programs, including three stages (screening, refining, and confirming). (d) During the entire development process, a user-centered principle was followed with the involvement of oncology nursing specialists and breast cancer patients, including development, testing, and iterative development phases.
The interdisciplinary team
An important prerequisite for developing M-health applications is the formation of an interdisciplinary development team. We built a multidisciplinary team consisting of researchers, oncology nursing specialists, and software developers. Each team member brought their expertise from their respective fields, and all individuals were considered members of the same team rather than separate participants with a common goal.
Two sub-teams were established, one responsible for content development, and the other for software development. The content development team consisted of researchers and six senior breast oncology nursing specialists with bachelor’s degrees and over 10 years of clinical experience. Their work included contextual analysis, functional framework design, and content review of the “Information” module. The software development team included researchers and experienced software developers. Their tasks involved developing the mini-program based on the functional framework and requirements designed by the content development team.
The development team used contextual analysis to identify the actual usage needs of two target groups for the mini-program: oncologist nurse specialists and out-of-hospital breast cancer patients.
Involvement of oncology nursing specialists and breast cancer patients following user-centered design principle
Since the oncology nursing specialists and breast cancer patients are targeted users of the mini-program, the two groups fully participated in the development according to the user-centered principle. Nursing specialists who in charge of case management were interviewed about the preliminary functional framework of the mini-program. The interview results are presented in the section “Driving the Development Process via the Contextual Analysis Findings.” Semi-structured in-depth interviews were conducted in the testing and iteration stage to gain user feedback from nursing specialists to improve the applicability and usability of the mini-program. The interview guide can be found in the supplementary material.
Breast cancer patients fully engaged in the three developing phases (Screening, Refining, and Confirming). In the Screening Phase, since the self-management theory was selected as the theoretical framework, the supportive care needs of out-of-hospital breast cancer patients were explored, and the functional framework of the mini-program was constructed accordingly. In the Refining Phase, patients were invited to evaluate the usability and practicality of the mini-program through system tests and semi-structured in-depth interviews. The results of the system test are presented in the Results of System Test section. The feedback from interviews and corresponding iterative updates are listed in Table 1 . In the Confirming Phase, our research team is conducting clinical trials in out-of-hospital breast cancer patients to find out the actual effect of the mini-program on recovery.
The theory framework of the mini-program
This study applied the self-management theory [ 37 ] as the theoretical framework. The self-management theory explains how individual factors and environmental factors influence an individual’s self-efficacy, which ultimately affects the generation and development of individual behaviors. Self-efficacy is influenced by direct experience, indirect learning, verbal persuasion, and psychological arousal. By providing individuals with sufficient knowledge, healthy beliefs, skills, and support, their self-efficacy is increased, and they are likely to engage in beneficial health behaviors and self-management. Individuals who are confident in their abilities to apply self-management behaviors and overcome obstacles by improving their self-management skills and persevere in their efforts to manage their health [ 37 ]. Self-efficacy is directly and linearly positively related to the active adoption of health management behaviors [ 38 ]. The functions of the various parts of the mini-program designed using self-management theory can broaden the pathways and levels of efficacy information generation in four ways: direct experience, indirect learning, verbal persuasion, and mental arousal. Patients with high self-efficacy will take positive steps to achieve desired goals and possess disease-adapted behaviors. The form of the mini-application function block diagram is shown in Fig. 1 .

Driving the development process via the contextual analysis findings
Contextual analysis [ 39 ] is a method of discerning the profound significance and influence of language, behavior, events, and so forth, by examining them within a particular environment or background. Rather than being an afterthought, contextual analysis sheds light on the meaning and inner dynamics of our primary subject of interest. Through contextual analysis, we can gain a deeper understanding of the user’s usage scenarios, including their motivations, goals, environment, and behavior. This helps us better understand user needs, as well as the problems and challenges they may encounter when using the software.
In this paper, we adopted contextual analysis to gain a detailed understanding of the needs of oncology nurse specialists and out-of-hospital breast cancer patients. The research team adopted a mixed research strategy to achieve contextual analysis of the target users. A cross-sectional study was conducted among 286 patients and qualitative semi-structured in-depth interviews were applied in 12 patients to find out the supportive care needs of out-of-hospital breast cancer patients. According to the contextual analysis results from patients, the functional framework of the mini-program was constructed. See Fig. 2 for details.

Supportive care needs of out-of-hospital breast cancer patients
Contextual analysis of breast cancer case management nurses was conducted through focus group interview. The interview results were listed as three themes: health information, personal self-management, and case management needs. Health information included breast cancer-related knowledge, the side effects of chemotherapy drugs, and symptom management measures. The key task of personal self-management contained temperature monitoring, weight management, functional exercise, and symptom management. Case management needs involved storage and management of patients’ medical records and development of a nurse-end program.
Based on the contextual analysis results of out-of-hospital breast cancer patients and the oncology case management nurses, the framework and functional block of the mini-program were formed. An overview of the CMBM Software development process is listed in Fig. 3 .

Overview of the CMBM software development process
Patient-end program functional modules
Using the results of the contextual analysis, we design the functional modules of the patient-end program based on the patient’s supportive care needs. For example, the “Information” section is designed to meet the “Information need” of breast cancer patients; the “social needs” and “spiritual needs” of patients suggest that breast cancer patients lack peer support, and for this reason, the"Interaction” section for patients has been added to the app to provide a communication platform for patients.
The patient-end program include four functional modules: “Information”, “Interaction”, “Management” and “My”. In the “Information” module, information about breast cancer treatment and health management are compiled based on clinical guildlines. The “Interaction” module allows patients to interact with fellow patients and consult an case management nurse. In the “Management” module, patients can record and review their self-management-related health status, including three medical parameters (temperature, blood pressure, weight) and three behavioral parameters (daily steps, medication, mindfulness excersice). The “My” module enables patients to input and edit their basic personal information and medical history. The main structure and information support module contents are listed in Fig. 4 .

The main menu of patient-end program
Nurse-end program functional modules
The design of the functional modules of the nurse-end program was also derived from the results of contextual analyses. The nurse-end program includes three functional modules: “Consultation”, “Management”, and “My”. The “Consultation” module is mainly used for online communication between case management nurses and patients. Nurses can enter the patient’s name in the search box to open a dialog box, and communicate with each other by sending text, voice and pictures. In the “Management” module, nurses can effortlessly search for patients by entering their name, WeChat nickname, or mobile phone number in the search box. This initiates a seamless dialogue, and with a simple click of the “+” button, patients can be promptly added to the “My Concerns” list. They can view the medical record information on its homepage, and add the postoperative treatment plan for the patient. The “self-management report” feature empowers nurses to stay up-to-date with patients’ recent well-being. By monitoring vital indicators like temperature, weight, and incidents of nausea or vomiting following chemotherapy, nurses can proactively ensure patients’ safety. The “clock in record” feature meticulously logs various patient activities including weight variations, exercise regimens, and medication adherence, providing a holistic view of their health journey. “Treatment monitoring Schedule” enables nurses to create customized chemotherapy schedules. With the first postoperative chemotherapy session scheduled in the calendar, the system seamlessly computes subsequent chemotherapy sessions and associated assessments. This transition to an online system marks a significant advancement from the traditional paper-based chemotherapy planning. Its automated scheduling and data tracking functions serve to alleviate the clinical nursing workload, enhancing efficiency and freeing up valuable time for focused patient care. The “My” module offers nurses the convenience of adding patients of interest or relevant content to their “My Favorites” section, enabling streamlined one-click access for viewing and management. The core structure and informational components of this module are outlined in Fig. 5 .

The main menu of nurse-end program
Driving the development process via the multi-stage optimization strategy
We adopted a multi-phase optimization strategy to drive the software development process. This strategy was proposed by Collins in 2005 and has become an important guiding theory for the development and evaluation of M-health interventions in recent years [ 40 ]. The strategy consists of three phases: Screening Phase, Refining Phase, and Confirming Phase. The Screening Phase need theories to identify and incorporate intervention elements. In this study, the initial version (1.0) development was based on self-management theory. Focusing on self-management, the results of contextual analysis, literature review and expert consultation were combined to design the mini-program version (1.0). The Refining Phase involves iterative adjustments to the previously version. In this study, the development team iteratively adjusted the mini-program version (1.0) according to users’ suggestions and test results. The Confirming Phase includes planning for clinical trials to test effect of the mini-program version (2.0) on self-management and recovery outcomes in out-of-hospital breast cancer patients.
Results of system test
Eight out-of-hospital breast cancer patients were recruited for system tests. The patient’s general information is listed in Table 2 .
The 10-item System Availability Scale (SUS)developed by Brooke was used [ 41 ]. The scale is a widely used method for quantitatively assessing user satisfaction with software systems. SUS is a Likert-5 and 10-item questionnaire (4 = strongly agree, 0 = strongly disagree), with Cronbach Alpha of 0.91. Generally, a system score above 60 on the SUS scale could be considered to be easy and simple to use, and the average score of SUS in our research is 78.75. The SUS scores of the mini-program system are presented in Fig. 6 .

System availability scale (SUS) score of patients
The research team designed the core task tests based on the typical and necessary self-management tasks of out-of-hospital patients. The core task of the “Information” module was listed as an example (Table 3 ). Functional tests include the passing rate for each task, and performance tests include the completion time of each task. More details can be found in Table 4 .
In this article, we demonstrated how to create a customized software solution for breast cancer case management practices based on a multi-stage optimization strategy, applied the contextual analysis method, and followed the user-centered principle. Preliminary test results showed satisfaction and acceptance of the WeChat mini-program among both out-of-hospital breast cancer patients and oncology nursing specialists.
Team effort
There were two typical patterns for developing M-health applications in the past. One was led by software developers, while the other was led by medical professionals. Each of these patterns has its own advantages and disadvantages. To overcome these shortcomings, some projects [ 42 ] developing M-health applications are now utilizing interdisciplinary team collaborations. This approach not only ensures the quality of the software but also makes sure that applications meet the actual needs.
In order to develop a customized software solution, our research team consisted of researchers, oncology nursing specialists, and software developers. The interdisciplinary team work dedicated to customizing software solutions together. Our team members each played to their strengths and held regular meetings to discuss and enhance our understanding and resolution of issues encountered during the software development process. Our team also included informal members: breast cancer patients, whose suggestions contributed to the practicality of the program.
Contextual analysis and user-centered design
Contextual analysis is a valuable tool that enables developers to design systems that are more relevant and user-friendly. And it allows us to understand any context-specific characteristics, practice patterns, and the openness of the target setting’s nurses and patients towards technology [ 42 ]. User-centered design can significantly reduce the cost of program iteration. More importantly, it has a profound influence on various aspects of a program including its design, functionality, information architecture, and interactive elements [ 43 ]. By analyzing different contexts, not only did we design features that better meet user needs, but we also predicted and addressed potential issues that users may encounter when using the mini-program in advance, thereby enhancing the user experience. In the iterative development stage, we discovered and improved some deficiencies in the design through core task testing and usability testing. Notably, the completion rate of the core task test reached 100%, indicating that our application is user-friendly and easy to operate.
- Multi-stage optimization strategy
In several priority areas of public health, researchers have successfully applied multi-stage optimization strategies to enhance their work, including software development and intervention programs [ 44 , 45 , 46 ]. In this study, we also apply this strategy to software development. While the multi-stage optimization strategy provides an optimization framework, it is important to note that our optimization objectives (such as software functionality and content requirements) are determined by key users involved in the research (out-of-hospital breast cancer patients and oncology nurse spescialists). This project adopts a multi-stage optimization strategy, iteratively improving the development of the mini-program through screening, refinement, and confirmation stages. Each stage aims to optimize our program.
The research team plans to explore the feasibility of mini program development program through preliminary experiment, and verify the intervention effect of mini program on self-management behavior, self-efficacy and quality of life and other indicators through formal experiment. A randomized controlled trial (IRB-2020-408) was initiated in August 2022 at a Class III hospital in Zhejiang, China, and is currently in the data collection phase.
There is no doubt that M-health will play a core role in the future of health care. However, to successfully implement and promote M-health applications in clinical setting, it is essential to analyze the needs of the target population. Additionally, it is crucial to determine who will be the driving force behind the implementation of the entire M-health project. This study demonstrates how to integrate M-health components into existing breast cancer case management care practices. In addition to providing a reference for other teams interested in developing and integrating M-health components into case management care models, this study also provides a reference for building M-health-featured care work models in practices.
In this study, the collaborative work of an interdisciplinary team with backgrounds in nursing and computer science, along with the active involvement of patients, not only facilitated the planning, developing, updating, and testing of M-health components based on the actual needs of the target population, but also increased the chances of acceptance and long-term implementation of the M-health program in practice.
This study demonstrates how to integrate M-health components into existing breast cancer case management practices. It provides insights for other reserch teams interested in developing and integrating M-health components into daily nursingt practice.
In the context of the digital age, M-health applications are rapidly becoming information sources and decision support tools for healthcare professionals and patients. However, it is crucial not to overlook the issues of information security and digital barriers for older adults.
Through interviews with outpatients with breast cancer and oncology nurses, we have gained insights into their concerns regarding information security. Some interviewees expressed concerns about information security and were worried about the risk of their personal information being leaked during app usage. Such concerns, to some extent, hinder the widespread adoption of M-health applications. Additionally, some interviewees mentioned that older patients, in general, find it challenging to learn and use the various functions of WeChat mini-programs, making it difficult to promote and apply M-health applications among the elderly population.
Solving these issues effectively is not only vital for the patients’ rights and interests but also crucial for the comprehensive implementation of M-health in practice. It is a matter that requires careful consideration in future development of M-health applications.
Data availability
The datasets generated and/or analysed during the current study are not publicly available but are available from the corresponding author on reasonable request.
Bray F, Laversanne M, Sung H et al. Global cancer statistics 2022: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J Clin. 2024: 1–35.
Wu J, Zeng N, Wang L, Yao L. The stigma in patients with breast cancer: a concept analysis. Asia Pac J Oncol Nurs. 2023;10(10):100293.
Article PubMed PubMed Central Google Scholar
Heidkamp P, Hiltrop K, Breidenbach C, Kowalski C, Pfaff H, Geiser F, Ernstmann N. Coping with breast cancer during medical and occupational rehabilitation: a qualitative study of strategies and contextual factors. BMC Womens Health. 2024;24(1):183.
Zhao H, Li X, Zhou C, Wu Y, Li W, Chen L. Psychological distress among Chinese patients with breast cancer undergoing chemotherapy: concordance between patient and family caregiver reports. J Adv Nurs. 2022;78(3):750–64.
Article PubMed Google Scholar
Jang Y, Seong M, Sok S. Influence of body image on quality of life in breast cancer patients undergoing breast reconstruction: Mediating of self-esteem. J Clin Nurs. 2023;32(17–18):6366–73.
Oh PJ, Cho JR. Changes in fatigue, psychological distress, and Quality of Life after Chemotherapy in women with breast Cancer: a prospective study. Cancer Nurs. 2020 Jan/Feb;43(1):E54–60.
Maass SWMC, Boerman LM, Verhaak PFM, Du J, de Bock GH, Berendsen AJ. Long-term psychological distress in breast cancer survivors and their matched controls: a cross-sectional study. Maturitas. 2019;130:6–12.
Article CAS PubMed Google Scholar
De Vrieze T, Nevelsteen I, Thomis S, De Groef A, Tjalma WAA, Gebruers N, Devoogdt N. What are the economic burden and costs associated with the treatment of breast cancer-related lymphoedema? A systematic review. Support Care Cancer. 2020;28(2):439–49.
Liang Y, Gao Y, Yin G, Chen W, Gan X. Development of a breast cancer case management information platform (BC-CMIP) module based on patient-perceived value. Front Oncol. 2022;12:1034171.
Jin L, Zhao Y, Wang P, Zhu R, Bai J, Li J, Jia X, Wang Z. Efficacy of the whole-course case management model on compliance and satisfaction of breast Cancer patients with whole-course standardized treatment. J Oncol. 2022;2022:2003324.
Scherz N, Bachmann-Mettler I, Chmiel C, Senn O, Boss N, Bardheci K, Rosemann T. Case management to increase quality of life after cancer treatment: a randomized controlled trial. BMC Cancer. 2017;17(1):223.
Yamei Y, Yongfang Zh J, Sh, Xixi C, Dehong Z, Chuner J, Jianfen N. The influence of the whole course professional nursing case management model on the disease uncertainty for breast cancer patients with chemotherapy. J Nur Train. 2018;(02), 99–111.
Cuie P. The whole case management model for breast cancer patients to study the effect of quality of life and psychological society. Hunan Normal University; 2015.
Bleich C, Büscher C, Melchior H, Grochocka A, Thorenz A, Schulz H, Koch U, Watzke B. Effectiveness of case management as a cross-sectoral healthcare provision for women with breast cancer. Psycho Oncol. 2017;26(3):354–60.
Article Google Scholar
Huiting Zh J, Zh, Xiaodan W, Lijuan Zh, Wenhao H, Huiying Q. Exploration of case management model for breast cancer patients. J Nurs Sci. 2017;(14), 19–21.
Woodward J, Rice E. Case management. Nurs Clin North Am. 2015;50(1):109–21.
Luo X, Chen Y, Chen J, Zhang Y, Li M, Xiong C, Yan J. Effectiveness of mobile health-based self-management interventions in breast cancer patients: a meta-analysis. Support Care Cancer. 2022;30(3):2853–76.
Meiqin X, Lingjuan Z. The delivery and inspiration of case management model in China. Chin J Nurs. 2014;(03), 367–71.
Huanhuan L, Zhuangjie X, Yuan L, Ying L, ShouQi W, MeiLing Z, Jie Y, Pengcheng L, Huanhuan Zh, Jiao S. A review of the interventions of nurses’ intent to stay. Chin J Nurs. 2017;(08), 1007–9.
Dan W, Shanling L, Yulin X. Research status of continuous nursing at home and abroad. Nurs Res 2016;(20), 2436–8.
Mariani AW, Pêgo-Fernandes PM. Telemedicine: a technological revolution. Sao Paulo Med J. 2012;130(5):277–8.
Hamine S, Gerth-Guyette E, Faulx D, Green BB, Ginsburg AS. Impact of mHealth chronic disease management on treatment adherence and patient outcomes: a systematic review. J Med Internet Res. 2015;17(2):e52.
Mahmood S, Hasan K, Colder Carras M, Labrique A. Global preparedness against COVID-19: we must leverage the Power of Digital Health. JMIR Public Health Surveill. 2020;6(2):e18980.
Petracca F, Ciani O, Cucciniello M, Tarricone R. Harnessing Digital Health Technologies during and after the COVID-19 pandemic: context matters. J Med Internet Res. 2020;22(12):e21815.
Cong H, Yongyi C, Xiangyu C, Xuying L. Rehabilitation Effect of Chemotherapy-based adverse reactions to breast Cancer patients based on continuous care platform. Oncol Pharma. 2020;(02), 244–51.
Cong A, Liping W. Application progress of mobile health in transitional care of patients with hypertension. Chin J Mod Nurs. 2021;27(4):539–42.
Google Scholar
Larsen ME, Farmer A, Weaver A, Young A, Tarassenko L. Mobile health for drug dose optimisation. Annu Int Conf IEEE Eng Med Biol Soc. 2011;2011:1540–3.
PubMed Google Scholar
Heo J, Chun M, Lee KY, Oh YT, Noh OK, Park RW. Effects of a smartphone application on breast self-examination: a feasibility study. Healthc Inf Res. 2013;19(4):250–60.
McCarroll ML, Armbruster S, Pohle-Krauza RJ, Lyzen AM, Min S, Nash DW, Roulette GD, Andrews SJ, von Gruenigen VE. Feasibility of a lifestyle intervention for overweight/obese endometrial and breast cancer survivors using an interactive mobile application. Gynecol Oncol. 2015;137(3):508–15.
Smith SA, Whitehead MS, Sheats J, Mastromonico J, Yoo W, Coughlin SS. A Community-Engaged Approach to developing a Mobile Cancer Prevention App: the mCPA Study Protocol. JMIR Res Protoc. 2016;5(1):e34.
Eden KB, Ivlev I, Bensching KL, Franta G, Hersh AR, Case J, Fu R, Nelson HD. Use of an online breast Cancer Risk Assessment and patient decision aid in Primary Care practices. J Womens Health (Larchmt). 2020;29(6):763–9.
Keohane D, Lehane E, Rutherford E, Livingstone V, Kelly L, Kaimkhani S, O’Connell F, Redmond HP, Corrigan MA. Can an educational application increase risk perception accuracy amongst patients attending a high-risk breast cancer clinic? Breast. 2017;32:192–8.
Eden KB, Scariati P, Klein K, Watson L, Remiker M, Hribar M, Forro V, Michaels L, Nelson HD. Mammography decision aid reduces Decisional Conflict for women in their forties considering screening. J Womens Health (Larchmt). 2015;24(12):1013–20.
Zhu J, Ebert L, Liu X, Chan SW. A mobile application of breast cancer e-support program versus routine care in the treatment of Chinese women with breast cancer undergoing chemotherapy: study protocol for a randomized controlled trial. BMC Cancer. 2017;17(1):291.
Ying L. Construction of an M-Health based information support program for women with breast Cancer during diagnosis and treatment process. The Second Military Medical University; 2017.
Pengfei X, Bo Y, Yue H, Jingyun H. An empirical research on the interactive behavior of WeChat subscription number users from the perspective of the theory of interactive ritual chain. Chin J Inf Syst. 2023;(01), 69–83.
Bandura A. Self-efficacy: toward a unifying theory of behavioral change. Psychol Rev. 1977;84(2):191Y215.
Bandura A. Health promotion by social cognitive means. Health Educ Behav. 2004;31(2):143Y164.
George A, Scott K, Garimella S, Mondal S, Ved R, Sheikh K. Anchoring contextual analysis in health policy and systems research: a narrative review of contextual factors influencing health committees in low and middle income countries. Soc Sci Med. 2015;133:159–67.
Collins LM, Murphy SA, Strecher V. The multiphase optimization strategy (MOST) and the sequential multiple assignment randomized trial (SMART): new methods for more potent eHealth interventions. Am J Prev Med. 2007;32(5 Suppl):S112–8.
Brooke JB. SUS: a quick and dirty usability scale. Usability Evaluation Ind. 1996;189(194):4–7.
Leppla L, Hobelsberger S, Rockstein D, Werlitz V, Pschenitza S, Heidegger P, De Geest S, Valenta S, Teynor A. SMILe study team. Implementation Science meets Software Development to create eHealth Components for an Integrated Care Model for allogeneic stem cell transplantation facilitated by eHealth: the SMILe Study as an Example. J Nurs Scholarsh. 2021;53(1):35–45.
Luna D, Quispe M, Gonzalez Z, Alemrares A, Risk M, Garcia Aurelio M, Otero C. User-centered design to develop clinical applications. Literature review. Stud Health Technol Inf. 2015;216:967.
Piper ME, Fiore MC, Smith SS, Fraser D, Bolt DM, Collins LM, Mermelstein R, Schlam TR, Cook JW, Jorenby DE, Loh WY, Baker TB. Identifying effective intervention components for smoking cessation: a factorial screening experiment. Addiction. 2016;111(1):129–41.
Spring B, Pfammatter AF, Marchese SH, Stump T, Pellegrini C, McFadden HG, Hedeker D, Siddique J, Jordan N, Collins LM. A factorial experiment to optimize remotely delivered behavioral treatment for obesity: results of the Opt-IN Study. Obes (Silver Spring). 2020;28(9):1652–62.
O’Hara KL, Knowles LM, Guastaferro K, Lyon AR. Human-centered design methods to achieve preparation phase goals in the multiphase optimization strategy framework. Implement Res Pract. 2022;3:26334895221131052.
PubMed PubMed Central Google Scholar
Download references
Acknowledgements
The authors would like to express our sincere gratitude to all the breast cancer patients who participated in this research.
This study was supported by the Zhejiang Provincial Natural Science Foundation of China (LY18H160061) and Funding for innovation and entrepreneurship of high-level overseas students in Hangzhou.
Author information
Authors and affiliations.
School of Nursing, Hangzhou Normal University, Hangzhou City, Zhejiang Province, 311100, China
Hong Chengang, Wang Liping, Wang Shujin, Chen Chen, Yang Jiayue, Lu Jingjing, Hua Shujie, Wu Jieming, Yao Liyan, Zeng Ni, Chu Jinhui & Sun Jiaqi
You can also search for this author in PubMed Google Scholar
Contributions
HCG conceived the entire paper framework and was responsible for writing the paper. WSJ and CC conducted all interviews and managed the mini-programs. YJY, LJJ and HSJ were responsible for the collection of clinical nurse data. CJH and SJQ were responsible for patient data collection. Data analysis was conducted by WJM, YLY and ZN. WLP was responsible for the revision, editing and approval of manuscripts. All authors have rigorously revised and edited successive drafts of the manuscript. All authors read and approved the final version of the manuscript.
Corresponding author
Correspondence to Wang Liping .
Ethics declarations
Ethics approval and consent to participate.
The study was reviewed and approved by the Ethics Committee of ZheJiang Cancer Hospital (Ethic ID: ZJZLYY IRB-2020-408). All the participants signed written informed consent forms. This study was conducted in accordance with the 1964 Declaration of Helsinki guidelines.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Material 1
Rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Chengang, H., Liping, W., Shujin, W. et al. Multi-stage optimization strategy based on contextual analysis to create M-health components for case management model in breast cancer transitional care: the CMBM study as an example. BMC Nurs 23 , 385 (2024). https://doi.org/10.1186/s12912-024-02049-x
Download citation
Received : 22 November 2023
Accepted : 29 May 2024
Published : 06 June 2024
DOI : https://doi.org/10.1186/s12912-024-02049-x
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- User-centered design
- Contextual analysis
- Breast cancer patients
- Case management
- Transitional care
BMC Nursing
ISSN: 1472-6955
- General enquiries: [email protected]
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 06 June 2024
Performance evaluation of different regression models: application in a breast cancer patient data
- Mona Mahmoud Abo El Nasr 1 ,
- Alaa A. Abdelmegaly 2 na1 &
- Doaa A. Abdo 1 na1
Scientific Reports volume 14 , Article number: 12986 ( 2024 ) Cite this article
223 Accesses
Metrics details
- Breast cancer
This paper provides a comprehensive analysis of linear regression models, focusing on addressing multicollinearity challenges in breast cancer patient data. Linear regression methodologies, including GAM, Beta, GAM Beta, Ridge, and Beta Ridge, are compared using two statistical criteria. The study, conducted with R software, showcases the Beta regression model’s exceptional performance, achieving a BIC of − 5520.416. Furthermore, the Ridge regression model demonstrates remarkable results with the best AIC at − 8002.647. The findings underscore the practical application of these models in real-world scenarios and emphasize the Beta regression model’s superior ability to handle multicollinearity challenges. The preference for AIC over BIC in Generalized Additive Models (GAMs) is rooted in the AIC’s calculation framework, highlighting its effectiveness in capturing the complexity and flexibility inherent in GAMs.
Similar content being viewed by others

Large-scale foundation model on single-cell transcriptomics

A guide to artificial intelligence for cancer researchers

Genome-wide association studies
Introduction.
Regression analysis is one of the most important tools which has several applications in many fields. There are various types of regression models available in the literature, linear model (LRM), non-linear model, generalized linear model (GLM), and generalized additive models (GAM) 1 . GLM Introduced by Nelder & Wedderburn in 1972. GLM surpasses LRM assumptions, accommodating non-normally distributed responses, addressing heteroscedasticity, and allowing non-linear associations with predictors 2 , 3 . GLM takes many forms, one of these is the beta regression model (BRM), which models the continuous random variable dependency and suggests that the standard unit values are intervals based on the independent variables in different fields 4 . proposed BRM to explain variations in the dependent variable by rates and proportion behavior which supposes interval values (0, 1). This model assumes that the response variable follows the beta distribution. Further, the model can also accommodate asymmetries and heteroscedasticity 1 . Generally, the maximum likelihood estimator (MLE) is used to estimate the unknown regression coefficients of the BRM 5 , 6 . GAM offers the analyst an outstanding regression tool for understanding the quantitative structure of language data. An early monograph on generalized additive models is Hastie and Tibshirani in 1990 7 . GLM and GAM have become one of the standard tools for analyzing the impact of covariates on possibly non-Gaussian response variables. The only difference between GAM and GLM is that GAM permits the including nonlinear smooth functions in the model 8 . The selection of the smoothing parameter can be obtained, among many other proposals, by minimizing the conditional Akaike’s information criterion (AIC) 9 . This version of AIC for GAMs uses the log-likelihood evaluated at the penalized MLE and with the effective degrees of freedom computed as discussed in 10 .
Multicollinearity problem is a popular issue in regression modeling. It indicates that there is a strong association between the explanatory variables. However, many biased estimators have been introduced to combat multicollinearity in linear regression, such as the Stein estimator 11 , principal component estimator 12 , ridge regression estimator 13 , improved ridge estimators 14 , contraction estimator 15 , modified ridge regression estimator 16 , Liu estimator 17 , Liu-type estimator 18 , restricted and unrestricted two-parameter estimator 19 , (k-d) class estimator 20 , mixed ridge estimator 21 and modified Liu-type estimator 22 . There are several methods to estimate the shrinkage parameter such as ridge, Liu, and Liu-type estimations, which have become a generally accepted and more effective methodology to solve the multicollinearity problem in several regression models 13 proposed the ridge estimator (RE), the concept behind the ridge estimator is to apply a small definite amount (k) to the diagonal entries of the covariance matrix to increase the conditioning of this matrix, reduce the MSE, and achieve consistent coefficients. Several attempts have been made to choose the best ridge parameter k: Based on the work of 23 and 24 . The impact of multicollinearity on GLM is significant and enduring. Among the various GLMs, the BRM is notably affected by multicollinearity 5 , 25 and 26 proposed the ridge estimators for the BRM to remedy the problem of instability of the traditional ML method and increase the efficiency of estimation 1 proposed a new modified ridge-type estimator for the BRM. This paper aims to present a comparative analysis of various statistical models, incorporating both real data and simulation studies, with a specific focus on evaluating these models using the Akaike Information Criterion (AIC) and the Bayesian Information Criterion (BIC). Although there are a lot of high-dimension regression studies 27 , 28 , this paper specifically focuses on the evaluation of low-dimensional regression models. This paper is organized as follows; the differences in regression models the beta regression model, GAM regression model, GAM beta regression model, ridge model, and the beta ridge regression are presented. A numerical evaluation is offered using both Monte-Carlo simulation and empirical data application, respectively. Finally, conclusions are presented.
Methodology
Beta regression model.
The most used model in many branches like economic and medical research is beta regression, which is used to consider the influence of specific independent variables on a non-normal dependent variable. However, in the state of beta regression, the response variable is constrained to intervals (0, 1), such as fractions and percentages. These models are used to examine the relationship and effect of some chosen independent and normal dependent variables. However, this is not appropriate for conditions where the response variable does not follow the normal distribution because it may give an overestimated estimator 4 developed the beta regression model by using the link function to connect the mean function of its dependent variable and linear predictors. The inverse of a precision parameter of this model is called a dispersion scale, this parameter contains stability through observations. Despite the precision parameter might not be constant with the results of 29 , 30 .
Let y be a continuous random variable that has a beta distribution with a probability density function as follows:
where \(\Gamma\) is the gamma function and \(\emptyset\) is the precision parameter.
The mean and variance of the beta probability distribution are:
By using the logit link function, the model allows \(\mu _{i}\) , depending on covariates as follows:
The linear predictor is constrained within the beta distribution, which inherently models data with in the open set (0, 1). In scenarios where extreme values at 0 and 1 are observable, one can consider employing the inflated zero and or one beta distribution proposed by 31 .
Generalized Additive Model (GAM)
32 introduced generalized additive models that allow be modelling of the dependence of the response variable in a flexible way using smooth functions of the predictors by defining the linear predictors:
where, \(f_{j}(x_{ij})=\sum _{k=1}^{kj}\beta _{jk}(x_{ij})\) is the smoothing term from the \(j^{\text {th}}\) predictor with \(\{ \beta _{jk}( )\}_{k=1}^{kj}\) , the asset of known basis functions associated with unknown parameter \(\beta _{jk}\) .
We can define different smoothers by adopting different basis functions.
As penalized regression splines, cubic regression splines bases 33 .
We can estimate the GAM model using restricted maximum likelihood (REML), which amounts to maximizing the penalized log likelihood:
where \(L(\beta )=\sum _{t=1}^{n}L(y_{i}/\beta )\) is the log-likelihood for the observed values \(y_{i}\) of the response variable. \(\lambda\) : is a smoothing parameter. S : is a known penalty matrix. \(\lambda \beta ^{T} S\beta\) : the smoothing penalty.
Presented REML as a convenient estimation method for marginal likelihood estimation of \(\beta\) when the model contains Gaussian random effects, and it also leads to more stable estimates of \(\lambda\) with a much-reduced risk of under-smoothing 10 , 34 .
GAM beta regression model
Let \(y_i\) represent the test positive rate (TPR), which is determined by dividing the number of new positive cases \(P_i\) by the total number of tests \(T_i\) at time i. Time i is determined to have integer values between 1 and n for the first and last times of the period studied. TPR should have a built-in limit as a proportion between 0 and 1. Several methods and models may be used to analyze variables that are represented as proportions, but the beta regression model is perhaps the most well-known among them 5 , 35 .
The five-step GAM beta regression is as follows:
Suppose that the predictor variable \(Y_i\) follows a beta distribution with a mean of \(\mu _i\) 14 , 16 .
For the beta distribution’s mean and variance
In the second stage, we define the model’s systematic component. We determine the linear predictive functional \(\eta _i\) as:
where \(\beta\) is a vector with a \((p+1)\) dimensional regression model parameters that are yet to be defined, and \(x_i\) is the intercept plus the vector of measured values on p forecasters. The predictor function \(\eta _i\) provides the systematic component 9 and 36 . This equation represents how the systematic component is formulated in the model
In the third stage, we need to establish the relationship between the predictor function \(\eta _i\) and the expected value of \(Y_i\) denoted as \(\mu _i\) .. This relationship is achieved using the Link function, resulting in the following outcomes 9 , 36 .
The Link function in Generalized Linear Models (GLM) is specified in the references 9 , 36 .
Generalized additive models provide flexibility in modeling the dependence of the response variable by defining the linear predictor as a smooth function of the predictors, as described in 9 .
The term \(f_i(x_{ij})=\sum _{k=1}^{kj}\beta _{jk}\beta _{jk}(x_{ij})\) represents the smoothing function for the \(j^{\text {th}}\) predictor. It involves a sum of terms, each represented by \(\beta _{jk}\beta _{jk}(x_{ij})\) .
In estimating the Generalized Additive Model (GAM), Restricted Maximum Likelihood (REML) is utilized to maximize the penalized log-likelihood 9 The penalized Log-Likelihood \(L_p(\beta )\) is defined as
where \(L(\beta )=\sum _{t=1}^{n}L(Y_i/\beta )\) is the likelihood function for the observed values \(y_i\) of the response variable. \(\lambda\) represents the smoothing parameter, and S is the known penalty matrix. The use of REML helps in maximizing this penalized log-likelihood for GAM estimation.
predictions can be calculated as 9 .
Ridge regression model
One of the most widely used techniques for solving multicollinearity in multiple linear regression is ridge analysis. This method has found applications in various fields, including engineering, chemistry, and econometrics. Ridge regression (RR) modifies the Ordinary Least Squares (OLS) method to produce biased estimators of regression coefficients, thereby addressing issues related to multicollinearity. This approach is particularly valuable when OLS estimators exhibit significant variability. So, ridge analysis can improve the predictability and accuracy of a model 13 . Here, we describe the linear regression model 37 :
where Y represents the dependent variable, it is an \(n\times 1\) , X is the matrix of predictor variables, \(\beta\) is the vector of regression coefficients, it is \(p\times 1\) , and \(\epsilon\) represents an \(n\times 1\) vector of the error term.
In the context of ridge regression:
The ordinary least squares (OLS) estimator \({\hat{\beta }}\) Eq. ( 6 ) is calculated as follows
where \(S=X'X\) is the design matrix. represents the design matrix, and \({\hat{\beta }}\) is the vector of regression coefficients estimated using the ordinary least squares method.
The ridge regression estimator, introduced by Hoerl and Kennard, is derived by minimizing the given objective function 37
where \((Y-X\beta )'(Y-X\beta )+\) is a part of the OLS objective that minimizes the sum of squared residuals, and \(k(\beta '\beta -c)\) is the penalty term, where k is a constant, \(\beta\) is the vector of regression coefficients, and c is a predefined constant.
We obtain the normal equations 37
where \(X'X\) is the sum of squares and cross-products matrix, \(kI_p\) introduces the penalty term into the normal equations, and k is a constant.
The ridge estimator is determined by solving the normal equations, resulting in \(({\hat{\beta }} (k))\) as shown in Eq. ( 10 ):
where \(S=X'X\) , and \(W(k)=(I_{P}+kS^{-1}) ^{-1}\) is a matrix derived to simplify the computation.
The parameter k is the Biasing Parameter in ridge regression, Eq. ( 11 ) provides a method for selecting it 13 .
where p is the overall output variable, \(\sigma ^2\) is an estimate of the variance, and \(\beta '\beta\) is the sum of squared estimated coefficients.
The estimate of the ridge parameter, denoted as \({\hat{\beta }}_{k}\) is given by 38 :
where \(\Lambda\) represents a diagonal \(P\times P\) matrix. Efficiency of \({\hat{\beta }}_k\) is influenced by the selection of the ridge parameter k to get the smallest Mean Squared Error (MSE) estimate, a certain k value is determined. This assessment is performed at a chosen value of k , as expressed in Eq. ( 13 ) 38 :
Here, unbiased OLS estimated values for \({\hat{\sigma }}^2\) and \({\hat{\beta }}\) are used in place of \({\sigma ^2}\) and \({\beta }\)
Beta ridge regression model
The beta ridge regression estimator is proposed as an alternative to the beta maximum. likelihood estimator to mitigate the impacts of multicollinearity in the Beta Regression model. This estimator is denoted as follows 5 and 13 .
Assuming that \({\hat{\beta }}\) is an estimator of the vector \(\beta\) , the weighted sum of squared error is defined as 5 :
where \(\Theta\) represents the minimum value, and \({\hat{\beta }}>0\) is the constant increment that causes the WSSE to increase when \({\hat{\beta }}_{\text {ML}}\) substituted for \({\hat{\beta }}\) . The BRR estimator is obtained by minimizing the Length of \({\hat{\beta }}\) subject to a restriction:
\(({\hat{\beta }}-{\hat{\beta }}_{\text {ML}})^\prime X^\prime WX({\hat{\beta }}-{\hat{\beta }}_{\text {ML}})=\Theta _{0}\) , as Hoerl and Kennard’s restrictions 13 .
Minimized \(\varrho ={(y-{\hat{\beta }})\ }^\prime (y-{\hat{\beta }}) (\ y -{X{\hat{\beta }}}_{ML})\ ^\prime (y -{X{\hat{\beta }}}_{ML})+ (({\hat{\beta }}-{{\hat{\beta }}}_{ML})\ ^\prime X^\prime\) as Hoerl \({{\hat{\beta }}}_{ML}\)
where the Lagrangian multiplier is 1/ k . When Eq. ( 15 ) is differentiated from \({\hat{\beta }}\) , the outcome equals zero.
After simplification, we obtain the following BRR estimator:
Where, I is a matrix of identities with an order of \(p\times p\) , and k is the shrinkage parameter.
Numerical analysis
This study relies on data extracted from the Breast Cancer Wisconsin Diagnostic dataset, obtained from the University of Wisconsin Hospitals Madison Breast Cancer Database 39 , covering the period from January 1989 to November 1991. The dataset comprises records from 569 breast cancer patients and was accessed through an open online repository hosted at https://www.kaggle.com/code/gpreda/breast-cancer-prediction-from-cytopathology-data . Our research aims to explore the relationship between 10 predictor variables and tumor progression in breast cancer patients.
Data set description
Breast cancer represents a significant health burden globally, standing as the most prevalent cancer among women and ranking as the second leading cause of cancer-related mortality in women. Characterized by aberrant cell growth in breast tissue, this disease poses substantial health risks. In our study, we selected the radius mean as the dependent variable for several reasons. While previous research predominantly focused on diagnosis and disease classification, our approach provides a novel perspective. By utilizing the diagnosis state to assess the extent of disease spread, as indicated by the radius mean variable, we delve into the progression of breast cancer based on diagnostic information. This unique method yields valuable insights into tumor behavior and disease severity. Utilizing ‘radius mean’ as a continuous variable enriches the analysis of tumor data, enabling the use of diverse statistical methods to uncover intricate patterns. This approach not only enhances the understanding of tumor impact on patient outcomes but also facilitates the discovery of new correlations and insights in breast cancer research 40 . The radius mean serves as the primary outcome variable in our analysis, representing the average distance from the cell center to the perimeter. Its importance lies in its association with tumor spread; as the cell radius increases, so does the surface area, indicating a more extensive tumor spread. Our investigation encompasses 10 predictor variables, including diagnosis, texture, perimeter, area, smoothness, compactness, concavity, concave points, symmetry, and fractal dimension. These variables play crucial roles in elucidating various aspects of breast cancer progression. Detailed units of measurement for the features in the Breast Cancer Wisconsin (Diagnostic) Data Set are provided in Table 1 .
Table 2 provides comprehensive descriptive statistics for the variables in the breast cancer dataset, including the number of observations (N), as well as the minimum, maximum, mean, and standard deviation for each feature. Here’s a refined explanation of the analysis:
Texture, Perimeter, and Area: The mean texture value is 19.2896 (ranging from 9.71 to 39.28), the mean perimeter is 91.9690 pixels (ranging from 43.79 to 188.50), and the mean area is 654.8891 square pixels (ranging from 143.50 to 2501.00). Higher values for texture, perimeter, and area suggest greater variability, larger tumor sizes, and potentially more irregular tumor shapes, indicative of advanced breast cancer stages.
Smoothness and Compactness: The mean smoothness value is 0.0964 (ranging from 0.05 to 0.16), and the mean compactness is 0.1043 (ranging from 0.02 to 0.35). Lower smoothness values and higher compactness values suggest irregular and denser tumor structures, respectively, which may indicate more aggressive tumor growth patterns.
Concavity and concave points: The mean concavity value is 0.0888 (ranging from 0.00 to 0.43), and the mean number of concave points is 0.0489 (ranging from 0.00 to 0.20). Higher values for concavity and concave points indicate deeper and more pronounced concave regions in tumor contours, potentially reflecting aggressive tumor behavior.
Symmetry and fractal dimension: The mean symmetry value is 0.1812 (ranging from 0.11 to 0.30), and the mean fractal dimension is 0.0628 (ranging from 0.05 to 0.10). Deviations from symmetry in breast density and higher fractal dimension values suggest irregular and complex tumor shapes, respectively, which may be associated with aggressive tumor phenotypes and disease progression.
In Table 3 , the diagnosis frequencies indicate that 62.7% of cases are benign (B), while 37.3% are malignant (M). Understanding the distribution of malignant and benign cases is crucial for characterizing the dataset and identifying potential associations between diagnostic categories and clinical outcomes.
Table 4 shows the estimation of the linear regression coefficient The model performance indicators include \(R^{2}=0.9994\) , F statistic: \(9.184e^{4}\) and a p-value of less than 0.05. The information criteria values are AIC = − 6383.895 and BIC = − 6331.769. These results collectively provide insights into the effectiveness and significance of the linear regression model in capturing the relationship between the predictor variables and the response variable.
To check the existence of multicollinearity in the data, two methods are used. First, the correlation matrix of all explanatory variables 41 , Table 5 shows the correlation matrix. It is seen that there are correlations greater than 0.8 between Perimeter and Area, Texture and Concave Points, and Area and Compactness. Second, Variance Inflation Factors (VIF) values for all variables greater than 5 42 , high VIF values are indicative of a strong correlation between the predictor variables. Variables with high VIF: Perimeter, Area, Compactness, Concave Points. The determined condition number \(CN=\sqrt{\lambda _{max}/\lambda _{min}}\) of the data is 166.861. The correlation matrix, VIF and CN indicate the existence of a multicollinearity problem.
Table 6 indicates that several variables (diagnosis, perimeter, area, smoothness, and compactness) have a significant impact on the response variable, while others (texture, concavity, symmetry, and fractal dimension) do not show statistical significance in this analysis. These results provide insights into the relationship between the predictor variables and the response variable in the context of breast cancer data.
Table 7 views the estimation of GAM parameters and the most influential variables on the response variable. The variables that increase breast cancer according to this data are perimeter, area, smoothness, compactness, and concave points.
Table 8 introduces the residual deviance for the beta and GAM regression model, the deviance residual for the beta regression model ranges from (− 6.4337 to 6.4568), whereas the deviance residuals for the GAM model takes values from (− 0.1704 to 0.243243) which means GAM model has residuals less than beta regression model, this emphasizes that the differences between observed value and estimated value in GAM model are less than these differences in beta model, So the GAM model fits data in a best way from beta regression.
Table 9 displays the results of GAM beta regression. It indicates the variables that significantly impact the response variable. Diagnosis, perimeter, area, smoothness, compactness, and concave points have a significant impact on the response variable. Specifically, diagnosis, perimeter, area, and smoothness have positively affected the response variable, implying that these variables increased the risk of breast cancer in the analyzed dataset the breast cancer for patients based on this data. In contrast, compactness and concave points have negatively affected the response variable. They have a decreased risk of breast cancer for patients based on this data. However, the variables texture, Concavity, Symmetry, and Fractal dimension do not show significance. They have small effects on the response variable and are not associated with a significant change in breast cancer risk in this dataset.
Table 10 shows the results of ridge regression, The parameter estimates for the Ridge Regression Model include the estimate of the standard deviation of the error term (SC). It indicates the variables of diagnosis, perimeter, area, smoothness, compactness, concavity, and fractal dimension have a significant impact on the response variable. on the other hand, perimeter has a relatively large impact with an estimate of 0.9021, whereas texture has a very small impact with an estimate of − 0.0009. The variables diagnosis, perimeter, smoothness, and fractal dimension have a positive impact on the response variable. This suggests that an increase in these variables is associated with an increased risk of breast cancer as indicated by the data. In contrast, area, compactness, and concavity have negatively affected the response variable, these variables decreased the breast cancer based on the dataset. However, the variables texture, concave points, and symmetry are not significant in breast cancer risk in this dataset.
Table 11 shows the results of beta ridge regression. It indicates the variables of diagnosis, perimeter, area, smoothness, compactness, and concave points have a significant impact on the response variable. on the other hand, perimeter has a relatively large impact with an estimate of 12.5396, whereas texture has a very small impact with an estimate of − 0.0132. The variables diagnosis, perimeter, and smoothness, have a positive impact on the response variable. This suggests that an increase in these variables is associated with an increased risk of breast cancer. In contrast, area, compactness, and concave point have negatively affected the response variable, these variables decreased the risk of breast cancer. However, the variables texture, concavity p, symmetry, and fractal dimension are not significant in breast cancer risk.
According to the model selection criterion, as seen in Table 12 , the best model fit is the model that has the lowest value of this criterion; hence the Ridge regression model fits data in the best way for AIC and the Beta regression is the best model for BIC.

The fitted values of estimated models.
Figure 1 , illustrate the estimations of the values for the GAM, Beta, GAM Beta, Ridge, and Beta Ridge models. These figures demonstrate that an increase in one variable’s size corresponds to an increase in another variable, providing evidence that these models effectively capture the relationships between the variables and the radius.
Monte Carlo simulation study
In this section, we conduct a Monte Carlo simulation experiment to evaluate the performance of our proposed regression models across various conditions. The models under examination include the beta regression model, GAM regression model, GAM Beta regression model, Ridge regression model, and Beta Ridge regression model.
To generate synthetic data for our simulation, we utilized multivariate normal (mvrnorm) and beta distributions using the mvrnorm and rbeta functions, respectively. Specifically, we generated four predictor variables following multivariate normal distribution with a mean vector of zeros and a covariance matrix constructed using a correlation matrix and a diagonal scaling matrix (D). To ensure the stability and reliability of our results, we repeated the simulation 1000 times. We set the true mean parameter for the beta distribution to \(\mu\) = 3, with a dispersion parameter of \(\phi\) = 15. Given our focus on examining the effect of multicollinearity under different conditions, we varied the degree of correlation (rho) across \(\rho = (0.70, 0.80, 0.90)\) , and the number of constants (k) across (0, 0.01, 0.10). These parameters allow us to assess the impact of multicollinearity on model performance across a range of scenarios, providing valuable insights into the robustness and applicability of our regression models.
The simulated Akaike information criterion (AIC) and Bayesian information criterion (BIC) introduced by 43 are criteria for judging the performance of models as follows:
where \(\ln (L_{fit})\) is the log-likelihood of whatever model was fitted, k is the number of parameters estimated, and n is the number of observations 44 . All the computations are performed using the R Programming Language.
Results and discussion
The results from the Monte Carlo simulations for different n are presented in Tables 13 , 14 , 15 , 16 , 17 , 18 , 19 , 20 and 21 respectively. From these tables, the factors affecting the performance of the estimators are the degree of correlation \(\rho\) , the number of sample sizes n and the constant of ridge values k . Generally, as the sample size increases, it is expected that both AIC and BIC values will decrease, reflecting the improved fit of the model due to the inclusion of more data points. This decrease is not indicative of a negative relationship between AIC and BIC but rather a reflection of their individual responses to increased sample size. AIC penalizes model complexity to a lesser extent than BIC, which is why they may decrease at different rates as sample size grows. This trend indicates an improvement in the efficiency of all models with larger sample sizes. For all sample sizes, the degrees of correlation, and the constant of ridge values, the Ridge model has the lowest AIC values, indicating a better fit compared to other models, following the Beta and GAM-Beta models have the lowest AIC values, suggesting better fit for larger datasets. Introducing a ridge constant (0.01, 0.10) marginally affects the AIC and BIC values for the Ridge and Beta Ridge models, indicating the sensitivity of these models to regularization strength. on the other hand, for all sample sizes, the Beta and GAM-Beta models have the lowest BIC values, suggesting they provide the best fit for larger sample sizes. The Beta Ridge model has the highest BIC, and AIC values across all sample sizes, indicating a relatively poor fit compared to other models.

Average Values of AIC and BIC the degree of correlation ( \(\rho\) ), the number of sample sizes ( n ) and , and the constant of ridge values ( k ) for all models.
From Fig. 2 , we found that as sample sizes increased the average values of AIC decreased, Moreover, the average values of both AIC and BIC demonstrate a decreasing pattern with the increase in sample sizes, specifically evident in the beta regression model, as illustrated in Figs. 1 and 2 . In Fig. 3 , as the degree of correlation \((\rho )\) increases from 0.70 to 0.90, and as the ridge constant ( k ) in all sample sizes, the performance of the Ridge and Beta Ridge models shows a significant fluctuation in both AIC and BIC values, underscoring the sensitivity of these models to changes in correlation and regularization strength.

Average Values of AIC and BIC the degree of correlation ( \(\rho\) ) and the constant of ridge values ( k ) for BRR, RR models.
In Fig. 3 , across all values of \((\rho )\) and ( k ), the optimal model fit was consistently observed at a sample size of 200. Specifically, for AIC, the Ridge model demonstrated the best fit, while according to BIC, the Beta model also emerged as the top-performing model.

Average Values of AIC and BIC the degree of correlation ( \(\rho\) ) and the constant of ridge values ( k ) for all models.
In Fig. 4 , as sample sizes increase, depicted in (h.1) for varying degrees of correlation ( \(\rho\) ) and in (h.2) for constant ridge values, there is a notable decrease in the average AIC values. Ridge regression consistently emerges as the best model in terms of AIC. Conversely, when assessing the average BIC values, the optimal model is identified as beta ridge regression.
Conclusions
In this paper, we meticulously tailored a suite of models, including Generalized Additive Models (GAM), Beta regression, GAM Beta regression, Ridge regression, and Beta Ridge regression, to the intricacies of breast cancer data. Our analysis underscored a preference for the Akaike Information Criterion (AIC) in GAMs, attributed to its accommodation of the models’ complexity and flexibility, essential for capturing the multifaceted nature of the data [10].
A thorough simulation study was conducted to empirically validate our models across varying sample sizes and correlation coefficients, enhancing the robustness of our findings. In analyzing data from 569 breast cancer patients, we discerned key independent variables that significantly influence breast cancer risk. The comparative analysis revealed that the Beta regression model outperformed others based on the Bayesian Information Criterion (BIC), while the Ridge regression model showed superiority according to the Akaike Information Criterion (AIC). These results mirror those obtained from our simulation study, indicating that the selection between Ridge and Beta regression models may depend on the preferred information criterion, especially in smaller sample sizes. However, as sample sizes increase, both models consistently demonstrate suitability across both AIC and BIC metrics. It is crucial to acknowledge that these conclusions are drawn within the confines of our study’s dataset and simulation parameters, necessitating caution when extrapolating to other contexts.
Our investigation rigorously assessed a suite of low-dimensional regression models, including Generalized Additive Models (GAM), Beta regression, GAM Beta regression, Ridge regression, and Beta Ridge regression. While acknowledging the extensive research on high-dimensional regression models 27 , 28 , our study is distinctively focused on low-dimensional contexts. Applied to authentic breast cancer data, the performance of these models was meticulously evaluated against a simulation study, ensuring a robust examination within the dataset’s dimensional constraints.
Data availability
The data in this study was obtained from an open online repository from https://www.kaggle.com/code/gpreda/breast-cancer-prediction-from-cytopathology-data .
Akram, M. N., Amin, M., Elhassanein, A. & Ullah, M. A. A new modified ridge-type estimator for the beta regression model: Simulation and application. AIMS Math. 7 , 10351057 (2022).
MathSciNet Google Scholar
Anderson, C. J., Verkuilen, J. & Johnson, T. Applied generalized linear mixed models: Continuous and discrete data. Soc. Behav. Sci. 63 , 89 (2010).
Google Scholar
Geissinger, E. A., Khoo, C. L., Richmond, I. C., Faulkner, S. J. & Schneider, D. C. A case for beta regression in the natural sciences. Ecosphere 13 , e3940 (2022).
Article Google Scholar
Ferrari, S. & Cribari-Neto, F. Beta regression for modelling rates and proportions. J. Appl. Stat. 31 , 799–815 (2004).
Article MathSciNet Google Scholar
Qasim, M., Maansson, K. & Golam Kibria, B. On some beta ridge regression estimators: Method, simulation and application. J. Stat. Comput. Simul. 91 , 1699–1712 (2021).
Espinheira, P. L., Ferrari, S. L. & Cribari-Neto, F. On beta regression residuals. J. Appl. Stat. 35 , 407–419 (2008).
Baayen, R. H. & Linke, M. An Introduction to the Generalized Additive Model. A Practical Handbook of Corpus Linguistics 563–591 (Springer, Uk, 2020).
Book Google Scholar
Zakariene, E. & Ducinskas, K. Implementation of generalized additive modelsfor spatial bets regression. In Computer Data Analysis and Modeling: Stochastics and Data Scince 341–343 (2019).
Scrucca, L. A covindex based on a gam beta regression model with an application to the covid-19 pandemic in italy. Stat. Methods Appl. 31 , 881–900 (2022).
Wood, S. N., Pya, N. & Saf ken, B. Smoothing parameter and model selection for general smooth models. J. Am. Stat. Assoc. 111 , 1548–1563 (2016).
Article MathSciNet CAS Google Scholar
Stein, C. Inadmissibility of the usual estimator for the mean of a multivariate normal distribution. In Proceedings of the Third Berkeley Symposium on Mathematical Statistics and Probability, Volume 1: Contributions to the Theory of Statistics, vol. 3 197–207 (University of California Press, 1956).
Massy, W. F. Principal components regression in exploratory statistical research. J. Am. Stat. Assoc. 60 , 234–256 (1965).
Hoerl, A. E. & Kennard, R. W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 12 , 55–67 (1970).
Singh, B. & Chaubey, Y. P. On some improved ridge estimators. Statist. Hefte 28 , 53–67 (1987).
Mayer, L. S. & Willke, T. A. On biased estimation in linear models. Technometrics 15 , 497–508 (1973).
Swindel, B. F. Good ridge estimators based on prior information. Commun. Stat. Theory Methods 5 , 1065–1075 (1976).
Kejian, L. A new class of blased estimate in linear regression. Commun. Stat. Theory Methods 22 , 393–402 (1993).
Liu, K. Using liu-type estimator to combat collinearity. Commun. Stat. Theory Methods 32 , 1009–1020 (2003).
Ozkale, M. R. & Kaciranlar, S. The restricted and unrestricted two-parameter estimators. Commun. Stat. Theory Methods 36 , 2707–2725 (2007).
Sakalliouglu, S. & Kacciranlar, S. A new biased estimator based on ridge estimation. Stat. Pap. 49 , 669–689 (2008).
Li, Y. & Yang, H. A new stochastic mixed ridge estimator in linear regression model. Stat. Pap. 51 , 315–323 (2010).
Alheety, M. I. & Golam Kibria, B. Modified liu-type estimator based on (r- k) class estimator. Commun. Stat. Theory Methods 42 , 304–319 (2013).
Alkhamisi, M., Khalaf, G. & Shukur, G. Some modifications for choosing ridge parameters. Commun. Stat. Theory Methods 35 , 2005–2020 (2006).
Kibria, B. G. Performance of some new ridge regression estimators. Commun. Stat.-Simul. Comput. 32 , 419–435 (2003).
Qasim, M., Kibria, B., Maansson, K. & Sjolander, P. A new poisson liu regression estimator: Method and application. J. Appl. Stat. 47 , 2258–2271 (2020).
Article MathSciNet PubMed Google Scholar
Abonazel, M. R. & Taha, I. M. Beta ridge regression estimators: Simulation and application. Commun. Stat.-Simul. Comput. 52 , 4280–4292 (2023).
Zhang, Z., Yue, M., Huang, L., Wang, Q. & Yang, B. Large portfolio allocation based on high-dimensional regression and kendall’s tau. Commun. Stat.-Simul. Comput. 2023 , 1–13 (2023).
CAS Google Scholar
Wu, Y., Huang, L. & Jiang, H. Optimization of large portfolio allocation for new-energy stocks: Evidence from china. Energy 285 , 129456 (2023).
Smithson, M. & Verkuilen, J. A better lemon squeezer maximum-likelihood regression with beta-distributed dependent variables. Psychol. Methods 11 , 54 (2006).
Article PubMed Google Scholar
Ospina-Neto Francisco, C. & Zeileis, A. Beta regression in r. J. Stat. Softw. 34 , 1–24 (2010).
Ospina, R. & Ferrari, S. L. A general class of zero-or-one inflated beta regression models. Comput. Stat. Data Anal. 56 , 1609–1623 (2012).
Hastie, T. J. & Tibshirani, R. J. Generalized additive models. In Statistical Models in S (CRC press, 1990).
Wood, S. N. Generalized Additive Models: An Introduction With R (CRC press, 2017).
Wood, S. N. Fast stable restricted maximum likelihood and marginal likelihood estimation of semiparametric generalized linear models. J. R. Stat. Soc. Ser. B Stat Methodol. 73 , 3–36 (2011).
Douma, J. C. & Weedon, J. T. Analysing continuous proportions in ecology and evolution: A practical introduction to beta and dirichlet regression. Methods Ecol. Evol. 10 , 1412–1430 (2019).
Zuur, A. F. et al. Mixed Effects Models and Extensions in Ecology with R, vol. 574 (Springer, 2009).
Kan, B., Alpu, O. & Yazici, B. Robust ridge and robust liu estimator for regression based on the its estimator. J. Appl. Stat. 40 , 644–655 (2013).
Kibria, B. et al. A new ridge-type estimator for the linear regression model: Simulations and applications. Scientifica 2020 , 895 (2020).
Naji, M. A. et al. Machine learning algorithms for breast cancer prediction and diagnosis. Procedia Comput. Sci. 191 , 487–492 (2021).
Jaiswal, V., Suman, P. & Bisen, D. An improved ensembling techniques for prediction of breast cancer tissues. Multimedia Tools Appl. 2023 , 1–26 (2023).
Algamal, Z. Y. & Abonazel, M. R. Developing a liutype estimator in beta regression model. Concurr. Comput.: Pract. Exp. 34 , 6685 (2022).
Daoud, J. I. Multicollinearity and regression analysis. In Journal of Physics: Conference Series, vol. 949 (IOP Publishing, 2017).
Dishon, M. & Weiss, G. H. Small sample comparison of estimation methods for the beta distribution. J. Stat. Comput. Simul. 11 , 1–11 (1980).
Abonazel, M. R., Said, H. A., Tag-Eldin, E., Abdel-Rahman, S. & Khattab, I. G. Using beta regression modeling in medical sciences: A comparative study. Commun. Math. Biol. Neurosci. 2023 , 896 (2023).
Download references
Open access funding provided by The Science, Technology & Innovation Funding Authority (STDF) in cooperation with The Egyptian Knowledge Bank (EKB).
Author information
These authors contributed equally: Alaa A. Abdelmegaly and Doaa A. Abdo.
Authors and Affiliations
Department of Applied Statistics and Insurance, Faculty of Commerce, Mansoura University, Mansoura, 33516, Egypt
Mona Mahmoud Abo El Nasr & Doaa A. Abdo
Higher Institute of Advanced Management Sciences and Computers, Al-Buhayrah, Egypt
Alaa A. Abdelmegaly
You can also search for this author in PubMed Google Scholar
Contributions
All author contributed to this manuscript equally.
Corresponding author
Correspondence to Mona Mahmoud Abo El Nasr .
Ethics declarations
Competing interest.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Abo El Nasr, M.M., Abdelmegaly, A.A. & Abdo, D.A. Performance evaluation of different regression models: application in a breast cancer patient data. Sci Rep 14 , 12986 (2024). https://doi.org/10.1038/s41598-024-62627-6
Download citation
Received : 26 December 2023
Accepted : 20 May 2024
Published : 06 June 2024
DOI : https://doi.org/10.1038/s41598-024-62627-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: Cancer newsletter — what matters in cancer research, free to your inbox weekly.

IMAGES
VIDEO
COMMENTS
For example, docetaxel and ... HER2-negative breast cancer: the TransNEOS study. ... Mehta V, Goel S, Kabarriti R, et al. Case fatality rate of cancer patients with COVID-19 in a New York hospital ...
example, in a series of 8422 patients enrolled on International Breast Cancer Study Group trials between 1978 and 1999, the rate of node-negativity for medial compared to lateral/central tumors was 44 versus 33 percent, respectively. The most likely explanation for this difference is preferential drainage of some medial tumors to the IM nodes ...
Adam M. Brufsky, MD, PhD: Let's talk about this case. This is a 48-year-old woman who presented to her primary care physician a number of years ago with a lump in her breast. She had a 4.4-cm left breast mass and 3 palpable axillary lymph nodes. Her ultrasound and mammogram confirmed these physical findings.
Patient Case Presentation. Patient Mrs. B.C. is a 56 year old female who is presenting to her WHNP for her annual exam. She had to cancel her appointment two months ago and didn't reschedule until now. Her last pap smear and mammogram were normal. Today, while performing her breast exam, her nurse practitioner notices dimpling in the left ...
This patient's breast cancer is negative for ER and PR. Immunohistochemistry staining results for HER-2 are shown in Figure 3. HER-2 IHC is scored as 2+ (equivocal) for HER-2, demonstrating weak to moderate complete membrane staining in >10% of tumor cells. Due to this result, the sample is tested reflexively by FISH.
Background. Worldwide, male breast cancer is extremely rare, accounting for <1% of all breast tumors and <1% of all malignancies in men [1-3].Recently, the incidence of male breast cancer has increased from 1.0 per 100,000 men in the late 1970s to 1.2 per 100,000 men from 2000 to 2004 [4-7].The American Cancer Society reported a similar trend in the incidence of breast cancer in men from ...
Initial experience of dedicated breast PET imaging of ER+ breast cancers using [F-18]fluoroestradiol. Ella F. Jones. Kimberly M. Ray. Nola M. Hylton. Case Report Open Access 16 Apr 2019. Browse ...
The incidence of breast cancer is growing rapidly worldwide (1.7 million new cases and 600,000 deaths per year). Moreover, about 10% of breast cancer cases occur in young women under the age of 45. The aim of the study was to report a rare case of BRCA 1-mutated breast cancer in a young patient with multiple affected relatives.
Hepin* had been diagnosed with triple negative breast cancer late in 2014, before going on to have surgery. Her treatment was initially successful, and for a number of years she led an active lifestyle. But in May 2018 she started to notice a change. 'I was feeling more tired than usual - yawning and flagging easily,' she explains.
Sample size calculations for the pilot study showed that, assuming an OR for breast cancer mortality of 0.7 and a number of discordant pairs of 33%, two controls per case with 800 breast cancer ...
Introduction. Breast cancer is one of the most common tumors, and its incidence rate ranks first in female malignant tumors ().Despite various treatments, the survival of patients with advanced breast cancer is still disappointing, and the overall survival (OS) is approximately 31% ().Because of the rapid progression of the tumor, it is of great importance to find an effective treatment in ...
A healthy female breast is made up of adipose tissue (fat cells) and lobes. The lobes contain many lobules. Lobules are responsible for milk production in lactating women. The lobes and lobules are connected via milk ducts (National Breast Cancer Foundation INC, 2019). All together, this system is responsible for transporting milk to the nipple.
Pathophysiology of Breast Cancer. Except for skin cancer, breast cancer is the most common cancer in American women. Most breast cancer occurs in women older than 50 years. The major risk factors for breast cancer are classified as reproductive, such as nulliparity and pregnancy-associated breast cancer; familial, such as inherited gene ...
The Playback API request failed for an unknown reason. EP: 1. Clinical Case Presentation: A 36-Year-Old Woman with Breast Cancer and Brain Metastases. EP: 2. Treatment Options in the Frontline Setting for Metastatic HER2+ Breast Cancer. EP: 3. Second-Line and Third-Line Treatment Options for Metastatic HER2+ Breast Cancer.
Breast Cancer: Survivorship Care Case Study, Care Plan, and Commentaries. CJON 2021, 25 (6), 34-42. DOI: 10.1188/21.CJON.S2.34-42. This case study highlights the patient's status in care plan format and is followed by commentaries from expert nurse clinicians about their approach to manage the patient's long-term or chronic cancer care ...
In this study, we compared breast cancer patients in the BCSC top 2.5% of risk for their age to patients from the remaining 97.5%. We found that women in the top 2.5% of risk for their age, who have double the risk of getting breast cancer relative to the average women, had more than six-fold higher odds of presenting with interval cancers.
CASE 16-1. A 32-year-old G4P4 woman presents with complaints of a new lump in her left breast. Her past medical history is negative for a family history of breast carcinoma. Physical examination reveals a 3 cm firm, ill-defined mass that is tender to palpation. Ultrasound studies demonstrate a 4 cm solid-appearing mass with ill-defined borders.
Breast Cancer Case Study Group one. Patient Profile R M. is a 68-year-old white female who went to her healthcare provider with a complaint of "feeling tightness" around a lump in her right breast. She has a history of hypertension and smoking (25 pack- year history). Subjective Data Has a family history of breast cancer-one sister recently had lumpectomy and radiation therapy.
Abstract and Figures. In this case study, a women aged 40 was diagnosed with Metastatic breast cancer. Metastatic breast cancer is a complex multi-stage disease involving the expansion of ...
isolated to the breast and axilla. An MRI confi rmed the presence of the malignancy in the left breast and the enlarged lymph node in the axilla; it also showed no satellite lesions and a normal right breast (Figs. 3-5). Based on Ms. Connolly's aggressive and advanced breast cancer, the surgeon felt she should be considered for
Example Case Study 1a: BRAJFEC . Patient D.N. (BC Cancer ID #20-45678) is a 48-year-old female in good health, recently diagnosed with breast cancer. The pathology report indicates: invasive lobular carcinoma, high risk, Grade 3, tumor size 2.5 cm, no lymphovascular invasion (0/11 lymph nodes involved), estrogen and progesterone receptor ...
None of the early M-Health applications are designed for case management care services. This study aims to describe the process of developing a M-health component for the case management model in breast cancer transitional care and to highlight methods for solving the common obstacles faced during the application of M-health nursing service. We followed a four-step process: (a) Forming a cross ...
This study relies on data extracted from the Breast Cancer Wisconsin Diagnostic dataset, obtained from the University of Wisconsin Hospitals Madison Breast Cancer Database 39, covering the period ...
MAPK on resistance to anti-HER2 therapy for breast cancer (MSK, Nat Commun. 2022) 145 samples. Metastatic Breast Cancer (INSERM, PLoS Med 2016) ... Myoepithelial Carcinomas of Soft Tissue (WCM, CSH Molecular Case Studies 2022) 12 samples. Testis Select All; Germ Cell Tumors (MSK, J Clin Oncol 2016) 180 samples ... Example Queries. Primary vs ...