Your browser is not supported
Sorry but it looks as if your browser is out of date. To get the best experience using our site we recommend that you upgrade or switch browsers.
Find a solution
- Skip to main content
- Skip to navigation
Education Prizes 2024: Give someone the recognition they deserve! Nominate before 19 June
- Back to parent navigation item
- Primary teacher
- Secondary/FE teacher
- Early career or student teacher
- Higher education
- Curriculum support
- Literacy in science teaching
- Periodic table
- Interactive periodic table
- Climate change and sustainability
- Resources shop
- Collections
- Post-lockdown teaching support
- Remote teaching support
- Starters for ten
- Screen experiments
- Assessment for learning
- Microscale chemistry
- Faces of chemistry
- Classic chemistry experiments
- Nuffield practical collection
- Anecdotes for chemistry teachers
- On this day in chemistry
- Global experiments
- PhET interactive simulations
- Chemistry vignettes
- Context and problem based learning
- Journal of the month
- Chemistry and art
- Art analysis
- Pigments and colours
- Ancient art: today's technology
- Psychology and art theory
- Art and archaeology
- Artists as chemists
- The physics of restoration and conservation
- Ancient Egyptian art
- Ancient Greek art
- Ancient Roman art
- Classic chemistry demonstrations
- In search of solutions
- In search of more solutions
- Creative problem-solving in chemistry
- Solar spark
- Chemistry for non-specialists
- Health and safety in higher education
- Analytical chemistry introductions
- Exhibition chemistry
- Introductory maths for higher education
- Commercial skills for chemists
- Kitchen chemistry
- Journals how to guides
- Chemistry in health
- Chemistry in sport
- Chemistry in your cupboard
- Chocolate chemistry
- Adnoddau addysgu cemeg Cymraeg
- The chemistry of fireworks
- Festive chemistry
- Education in Chemistry
- Teach Chemistry
- On-demand online
- Live online
- Selected PD articles
- PD for primary teachers
- PD for secondary teachers
- What we offer
- Chartered Science Teacher (CSciTeach)
- Teacher mentoring
- UK Chemistry Olympiad
- Who can enter?
- How does it work?
- Resources and past papers
- Top of the Bench
- Schools' Analyst
- Regional support
- Education coordinators
- RSC Yusuf Hamied Inspirational Science Programme
- RSC Education News
- Supporting teacher training
- Interest groups

- More from navigation items
Education Prizes 2024: Give someone the recognition they deserve! Nominate before 19 June

Starters for 10: Advanced level 2 (16–18)
- 1 Introduction
- 3 Equilibria
- 4 Acids and bases
- 5 Carbonyl chemistry
- 6 Aromatic chemistry
- 7 Compounds with amine groups
- 9 Structure determination
- 10 Organic synthesis
- 11 Thermodynamics
- 12 Periodicity
- 13 Redox equilibria
- 14 Transition metal chemistry
- 15 Inorganics in aqueous solution
Redox equilibria
- Four out of five
- No comments
A question and answer sheet that tests learner’s knowledge of redox equilibria
The topics covered in this Starter for ten activity are: redox reactions, standard electrode potentials, calculations involving electrochemical cells, using E Ɵ values to predict reactions, appplications of electrochemical cells.
Example questions
Faisal has written the following notes on redox reactions in preparation for his AS exams. However there are a few mistakes, many of which are commonly seen in exam answers. Help Faisal learn from his mistakes by correcting the errors so that he has an accurate set of notes to revise from.

We can measure how readily something gives away electrons by measuring its standard electrode potential, E ⦵ .
1. Standard electrode potentials are measured by connecting a half cell containing the equilibrium, the potential of which is to be measured to a standard hydrogen electrode at 298 K.
(a) Label the diagram below showing the standard hydrogen electrode.
(b) Complete the diagram to show the complete cell you would use if you wished to measure E ⦵ for a zinc electrode.

2. Cells can be represented in shorthand form using a series of standard conventions.
(a) Match up the symbol to its meaning when used to represent an electrochemical cell;
| Shows a salt bridge
|| Indicates a phase boundary
(b) For each half cell, the species in the highest oxidation state in the redox equilibrium is written next to the salt bridge.
Use this convention to complete the shorthand representation of the cells produced when half cells containing each of the equilibria below are connected to a standard hydrogen electrode.
(i) Fe 2+ (aq) + 2 e – ⇌ Fe(s); Pt | H 2 (g) | H + (aq) ||
(ii) MnO 4 - (aq) + 1 e – ⇌ MnO 4 2- (aq); Pt | H 2 (g) | H + (aq) ||
A full version of this question and answer sheet is available from the ‘downloads’ section below. An editable version is also available.
Redox equilibria - editable

Introduction

Acids and bases

Carbonyl chemistry

Aromatic chemistry

Compounds with amine groups

Structure determination

Organic synthesis

Thermodynamics

Periodicity

Transition metal chemistry

Inorganics in aqueous solution
- 16-18 years
- Redox chemistry
- Electrochemistry
- Equilibrium
Specification
- Write half-equations identifying the oxidation and reduction processes in redox reactions. Combine half-equations to give an overall redox equation.
- Electrochemical cells can be used as a commercial source of electrical energy.
- IUPAC convention for writing half-equations for electrode reactions.
- The conventional representation of cells.
- Cells are used to measure electrode potentials by reference to the standard hydrogen electrode.
- Students should be able to: use EƟ values to predict the direction of simple redox reactions.
- Calculate the EMF of a cell.
- Write and apply the conventional representation of a cell.
- 13. be able to write ionic half-equations and use them to construct full ionic equations
- 5. know the features of the standard hydrogen electrode and understand why a reference electrode is necessary
- 7. be able to calculate a standard emf, EƟcell, by combining two standard electrode potentials
- 8. be able to write cell diagrams using the conventional representation of half-cells
- 10. be able to predict the thermodynamic feasibility of a reaction using standard electrode potentials
- 12. understand the limitations of predictions made using standard electrode potentials, in terms of kinetic inhibition and departure from standard conditions
- 15. understand the application of electrode potentials to storage cells
- d) oxidation and reduction in terms of: electron transfer, changes in oxidation number
- a) explanation and use of the terms oxidising agent and reducing agent
- b) construction of redox equations using half-equations and oxidation numbers
- f) use of the term standard electrode (redox) potential, EƟ, including its measurement using a hydrogen electrode
- h) calculation of a standard cell potential by combining two standard electrode potentials
- i) prediction of the feasibility of a reaction using standard cell potentials and the limitations of such predictions in terms of kinetics and concentration
- j) application of principles of electrode potentials to modern storage cells
- (a) redox reactions in terms of electron transfer
- (b) how to represent redox systems in terms of ion/electron half-equations and as halfcells in cell diagrams
- (c) concept of standard electrode potential and role of the standard hydrogen electrode
- (d) how simple electrochemical cells are formed by combining electrodes (metal/metal ion electrodes and electrodes based on different oxidation states of the same element)
- 1.7.2 define the term redox and explain oxidation and reduction in terms of electron transfer and changes in oxidation state;
- 1.7.3 demonstrate understanding that oxidising agents gain electrons and are reduced and reducing agents lose electrons and are oxidised; and
- 1.7.5 write half-equations and combine half-equations to give a balanced redox equation;
- 5.5.14 deduce, given appropriate emf values, reagents for the interconversion of vanadium between its oxidation states and combine half-cells to give an overall equation for a reaction;
- 5.6.1 define standard electrode potential, EӨ, explain the construction and significance of the hydrogen electrode and demonstrate understanding of the importance of conditions when measuring electrode potentials; and
- 5.6.3 use conventional representations for cells;
- 5.6.8 recall the environmental issues associated with cells;
- Introduction to oxidation and reduction: simple examples only, e.g. Na with Cl₂, Mg with O₂, Zn with Cu²⁺.
- Oxidation and reduction in terms of loss and gain of electrons.
- Oxidising and reducing agents.
- Oxidation states and numbers. Rules for oxidation numbers (exclude peroxides, except for hydrogen peroxide).
- Oxidation and reduction in terms of oxidation numbers.
Related articles

Mastering titration apparatus
2024-05-07T08:38:00Z By Kristy Turner
Use this poster, fact sheet and classroom activity to show learners the names and uses of equipment they’ll encounter in this practical

How to teach extraction of metals at 14–16
2024-04-09T07:20:00Z By Niall Begley
Solidify learners’ understanding of extraction processes with these tips, misconception busters and teaching ideas

Crime-busting chemical analysis
2024-02-26T05:00:00Z By Kit Chapman
From dog detectives to AI, discover the cutting-edge advances in forensic science
No comments yet
Only registered users can comment on this article., more from resources.

Fractional distillation and hydrocarbons | Review my learning worksheets | 14–16 years
By Lyn Nicholls
Identify learning gaps and misconceptions with this set of worksheets offering three levels of support

Chromatography | Review my learning worksheets | 14–16 years
2024-05-10T13:33:00Z By Lyn Nicholls

Solubility | Review my learning worksheets | 14–16 years
- Contributors
- Email alerts
Site powered by Webvision Cloud
This website works best with JavaScript switched on. Please enable JavaScript
- Centre Services
- Associate Extranet
- All About Maths
AS and A-level Chemistry
- Specification
- Planning resources
- Teaching resources
- Assessment resources
- Introduction
- Specification at a glance
- 3.1 Physical chemistry
- 3.2 Inorganic chemistry
- 3.3 Organic chemistry
- Scheme of assessment
- General administration
- Mathematical requirements and exemplifications
- AS practical assessment
- A-level practical assessment

3.1.11 Electrode potentials and electrochemical cells (A-level only)
Redox reactions take place in electrochemical cells where electrons are transferred from the reducing agent to the oxidising agent indirectly via an external circuit. A potential difference is created that can drive an electric current to do work. Electrochemical cells have very important commercial applications as a portable supply of electricity to power electronic devices such as mobile phones, tablets and laptops. On a larger scale, they can provide energy to power a vehicle.
Electrode potentials and cells (A-level only)
Commercial applications of electrochemical cells (a-level only).
A-level Chemistry/AQA/Module 5/Redox equilibria
- 1 OXIDATION AND REDUCTION
- 2.1 Electrode potentials
- 2.2 Creating an emf
- 2.3 Designing electrochemical cells
- 2.4 Standard conditions
- 2.5 Reference electrodes
- 2.6 Conventional Representation of Cells
- 3 THE ELECTROCHEMICAL SERIES
- 4.1 Oxidising agents and reducing agents
- 4.2.1 Displacement reactions
- 4.2.2 Disproportionation
- 4.3 Non-standard conditions
- 4.4 Kinetic stability
OXIDATION AND REDUCTION [ edit | edit source ]
Redox reactions were studied extensively at AS-level. The key points are summarized here:
• The gain and loss of electrons can be shown by means of full equations;
• Oxidation is the loss of electrons. When a species loses electrons it is said to be oxidised. E.g. Fe 2+ à Fe 3+ + e -
• Reduction is the gain of electrons. When a species gains electrons it is said to be reduced. E.g. MnO 4 - + 8H + + 5e - à Mn 2+ + 4H 2 O
• Electrons can in fact never be created or destroyed; they can only be transferred from one species to another. Reactions which involve the transfer of electrons are known as redox reactions.
• Overall redox equations can be created by combining the half-equations for the oxidation process and reduction processes, after multiplying all the coefficients of the species in one of the half-equations by a factor which ensures that the number of electrons gained is equal to the number of electrons lost. E.g. Fe 2+ à Fe 3+ + e - oxidation MnO 4 - + 8H + + 5e - à Mn 2+ + 4H 2 O reduction Multiplying all coefficients in the oxidation reaction by 5: 5Fe 2+ à 5Fe 3+ + 5e - means that 5 electrons are gained and five are lost overall equation: MnO 4 - + 8H + + 5Fe 2+ à Mn 2+ + 4H 2 O + 5Fe 3+
• A species which can accept electrons from another species is an oxidising agent. Oxidising agents are reduced during redox reactions. E.g. MnO 4 - is the oxidizing agent in the above reaction.
• A species which can donate electrons to another species is a reducing agent. Reducing agents are oxidised during redox reactions. E.g. Fe 2+ is the reducing agent in the above reaction.
• The oxidation number of an atom is the charge that would exist on the atom if the bonding were completely ionic.
In simple ions, the oxidation number of the atom is the charge on the ion: Na + , K + , H + all have an oxidation number of +1. O 2- , S 2- all have an oxidation number of -2.
In molecules or compounds, the sum of the oxidation numbers on the atoms is zero: E.g. SO 3 ; oxidation number of S = +6, oxidation number of O = -2. +6 + 3(-2) = 0
In complex ions, the sum of the oxidation numbers on the atoms is equal to the overall charge on the ion. E.g. MnO 4 - ; oxidation number of Mn = +7, oxidation number of O = -2. +7 + 4(-2) = -1 E.g. Cr 2 O 7 2- ; oxidation number of Cr = +6, oxidation number of O = -2. 2(+6) + 7(-2) = -2 E.g. VO 2 + ; oxidation number of V = +5, oxidation number of O = -2. +5 + 2(-2) = +1
In elements in their standard states, the oxidation number of each atom is zero: In Cl 2 , S, Na and O 2 all atoms have an oxidation number of zero.
Many atoms, including most d-block atoms, exist in different oxidation numbers. In complex ions or molecules, the oxidation number of these atoms can be calculated by assuming that the oxidation number of the other atom in the species is fixed.
• Oxidation numbers are useful for writing half-equations:
The number of electrons gained or lost can be deduced from the formula: No of electrons gained/lost = change in oxidation number x number of atoms changing oxidation number
The oxygen atoms are balanced by placing an appropriate number of water molecules on one side.
The hydrogen atoms are balanced by placing an appropriate number of H + ions on one side.
• Disproportionation is the simultaneous oxidation and reduction of the same species. There are many d-block species which readily undergo both oxidation and reduction, and which can therefore behave as both oxidising agents and reducing agents. Cu + , Mn 3+ and MnO 4 2- are all examples:
E.g. Cu + à Cu 2+ + e - oxidation Cu+ + e à Cu reduction
E.g. Mn 3+ + 2H 2 O à MnO 2 + 4H + + e - oxidation Mn 3+ + e - à Mn 2+ reduction
E.g. MnO 4 2- à MnO 4 - + e - oxidation MnO 4 2- + 2H + + 2e - à MnO 2 + 2H 2 O reduction
Species such as these are capable of undergoing oxidation and reduction simultaneously. Disproportionation reactions are special examples of redox reactions.
ELECTROCHEMICAL CELLS [ edit | edit source ]
Electrode potentials [ edit | edit source ].
Consider a zinc rod immersed in a solution containing Zn²⁺ ions (e.g. ZnSO4):
The Zn atoms on the rod can deposit two electrons on the rod and move into solution as Zn²⁺ ions: Zn(s) == Zn²⁺(aq) + 2e This process would result in an accumulation of negative charge on the zinc rod. Alternatively, the Zn²⁺ ions in solution would accept two electrons from the rod and move onto the rod to become Zn atoms: Zn²⁺(aq) + 2e == Zn(s) This process would result in an accumulation of positive charge on the zinc rod.
In both cases, a potential difference is set up between the rod and the solution. This is known as an electrode potential.
A similar electrode potential is set up if a copper rod is immersed in a solution containing copper ions (e.g. CuSO4), due to the following processes: Cu²⁺(aq) + 2e == Cu(s) - reduction (rod becomes positive) Cu(s) == Cu²⁺(aq) + 2e - oxidation (rod becomes negative)
Note that a chemical reaction is not taking place - there is simply a potential difference between the rod and the solution. The potential difference will depend on the nature of the ions in solution, the concentration of the ions in solution, the type of electrode used the temperature.
Creating an emf [ edit | edit source ]
If two different electrodes are connected, the potential difference between the two electrodes will cause a current to flow between them. Thus an electromotive force (emf) is established and the system can generate electrical energy.
The circuit must be completed by allowing ions to flow from one solution to the other. This is achieved by means of a salt bridge - often a piece of filter paper saturated with a solution of an inert electrolyte such as KNO3(aq).
The e.m.f can be measured using a voltmeter. Voltmeters have a high resistance so that they do not divert much current from the main circuit.
The combination of two electrodes in this way is known as an electrochemical cell, and can be used to generate electricity. The two components which make up the cell are known as half-cells.
A typical electrochemical cell can be made by combining a zinc electrode in a solution of zinc sulphate with a copper electrode in a solution of copper sulphate.
The positive electrode is the one which most favours reduction. In this case it is the copper electrode which is positive.
The negative electrode is the one which most favours oxidation. In this case it is the zinc electrode which is negative.
Thus electrons flow from the zinc electrode to the copper electrode. Reduction thus takes place at the copper electrode: Cu²⁺(aq) + 2e à Cu(s) Oxidation thus takes place at the zinc electrode: Zn(s) à Zn²⁺(aq) + 2e
The overall cell reaction is as follows: Zn(s) + Cu²⁺(aq) à Zn²⁺(aq) + Cu(s)
The sulphate ions flow through the salt bridge from the Cu2+(aq) solution to the Zn²⁺(aq) solution, to complete the circuit and compensate for the reduced Cu2+ concentration and increased Zn2+ concentration. The cell reaction including spectator ions can thus be written as follows: CuSO4(aq) + Zn(s) à Cu(s) + ZnSO4(aq).
The external connection must be made of a metallic wire in order to allow electrons to flow. The salt bridge must be made of an aqueous electrolyte to allow ions to flow.
By allowing two chemical reagents to be connected electrically, but not chemically, a reaction can only take place if the electrons flow externally. The chemical energy is thus converted into electrical energy.
Designing electrochemical cells [ edit | edit source ]
Half-cells do not necessarily have to consist of a metal immersed in a solution of its ions. Any half-reaction can be used to create a half-cell.
If the half-reaction does not contain a metal in its elemental state, an inert electrode must be used. Platinum is generally used in this case, as it is an extremely inert metal. If a gas is involved, it must be bubbled through the solution in such a way that it is in contact with the electrode.
A few examples are shown below:
a) Fe3+(aq) + e == Fe2+(aq) A platinum electrode is used, immersed in a solution containing both Fe2+ and Fe3+ ions:
b) Cr2O72-(aq) + 14H+(aq) + 6e == 2Cr3+(aq) + 7H2O(l) A platinum electrode is used, immersed in a solution containing Cr2O72-, H+ and Cr3+ ions:
c) Cl2(g) + 2e == 2Cl-(aq) A platinum electrode is used, immersed in a solution containing Cl- ions. Chlorine gas is bubbled through the solution, in contact with the electrode:
d) 2H+(aq) + 2e == H2(g) A platinum electrode is used, immersed in a solution containing H+ ions. Hydrogen gas is bubbled through the solution, in contact with the electrode:
In addition to making electricity, half-cells provide important information on the relative ability of a half-reaction to undergo oxidation or reduction. The more positive the electrode, the greater the tendency to undergo reduction, and the more negative the electrode, the greater the tendency to undergo oxidation.
Standard conditions [ edit | edit source ]
The electrode potential depends on the conditions used, including temperature, pressure and concentration of reactants.
It is therefore necessary to specify the conditions used when measuring electrode potentials. These conditions are normally set at a temperature of 298 K, a pressure of 1 atm and with all species in solution having a concentration of 1.0 moldm-3. Electrode potentials measured under these conditions are known as standard electrode potentials. They are denoted by the symbol Eo.
It is possible to predict how the electrode potential will vary if non-standard conditions are used by using Le Chatelier’s Principle.
If the oxidizing agent has a concentration greater than 1.0 moldm-3, it is more likely to favour reduction and the electrode potential will be more positive than the standard electrode potential. If it has a concentration of less than 1.0 moldm-3, it is more likely to favour oxidation and the electrode potential will be more negative than the standard electrode potential. For reducing agents, the reverse is true.
E.g.: Fe2+(aq) + 2e == Fe(s) Standard electrode potential = -0.44 V If [Fe2+] = 0.1 moldm-3 the electrode potential = -0.50 V The concentration is lower than standard so reduction is less likely to take place, and hence the electrode potential is more negative than expected.
If the temperature is higher than 298 K, then the system will move in the endothermic direction and the electrode potential will change accordingly.
If the pressure is greater than 1 atm, then the system will move to decrease the pressure and the electrode potential will change accordingly.
In general, a change which favours the reduction direction will make the electrode potential more positive, and a change which favours the oxidation direction will make the electrode potential more negative.
Reference electrodes [ edit | edit source ]
The emf of electrochemical cells is easy to measure, but the individual electrode potentials themselves cannot actually be measured at all; it is only possible to measure the potential difference between two electrodes. Even if another electrode were inserted into the solution, it would set up its own electrode potential and it would only be possible to measure the difference between the two electrodes.
It is therefore only possible to assign a value to a half-cell if one half-cell is arbitrarily allocated a value and all other electrodes are measured relative to it. An electrode used for this purpose is known as a reference electrode. The electrode conventionally used for this purpose is the standard hydrogen electrode.
The gas pressure is fixed at 1 atm, the temperature is 25oC and the H+ ions have a concentration of 1.0 moldm-3.
This electrode is arbitrarily assigned a value of 0.00V.
Using this electrode, it is possible to assign an electrode potential to all other half-cells.
Voltmeters measure potential on the right-hand side of the cell and substract it from the potential on the left-hand side of the cell:
Emf = ERHS - ELHS
If the standard hydrogen electrode is placed on the left-hand side of the voltmeter, therefore, the ELHS will be zero and the emf of the cell will be the electrode potential on the right-hand electrode:
E.g. if the standard Zn2+(aq) + 2e == Zn(s) electrode is connected to the standard hydrogen electrode and the standard hydrogen electrode is placed on the left, the emf of the cell is
The Zn2+(aq) + 2e == Zn(s) half-cell thus has an electrode potential of -0.76V.
E.g. if the Cu2+(aq) + 2e == Cu(s) electrode is connected to the standard hydrogen electrode and the standard hydrogen electrode is placed on the left, the emf of the cell is +0.34V. The Cu2+(aq) + 2e == Cu(s) half-cell thus has an electrode potential of +0.34V.
The standard electrode potential of a half-reaction can be defined as follows:
"The standard electrode potential of a half-reaction is the emf of a cell where the left-hand electrode is the standard hydrogen electrode and the right-hand electrode is the standard electrode in question".
The equation emf = ERHS - ELHS can be applied to electrochemical cells in two ways:
a) If the RHS and LHS electrode are specified, and the emf of the cell measured accordingly, then if the Eo of one electrode is known then the other can be deduced.
E.g. If the standard copper electrode (+0.34V) is placed on the left, and the standard silver electrode is placed on the right, the emf of the cell is +0.46V. Calculate the standard electrode potential at the silver electrode.
Emf = ERHS - ELHS +0.46 = E - (+0.34V) E = 0.46 + 0.34 = +0.80V
b) If both SEP's are known, the emf of the cell formed can be calculated if the right-hand electrode and left-hand electrode are specified.
E.g. If RHS = silver electrode (+0.80V) and LHS is copper electrode (+0.34V), then emf = +0.80 - 0.34 = +0.46V
In fact, the hydrogen electrode is rarely used in practice for a number of reasons: - the electrode reaction is slow - the electrodes are not easily portable - it is difficult to maintain a constant pressure
Once one standard electrode potential has been measured relative to the standard hydrogen electrode, it is not necessary to use the standard hydrogen electrode again. Any electrode whose electrode potential is known could be used to measure standard electrode potentials. Such electrodes are known as secondary standard electrodes. A useful example is the calomel electrode.
Conventional Representation of Cells [ edit | edit source ]
As it is cumbersome and time-consuming to draw out every electrochemical cell in full, a system of notation is used which describes the cell in full, but does not require it to be drawn.
Half-cells are written as follows:
- the electrode is placed on one side of a vertical line. - the species in solution, whether solid, liquid, aqueous or gaseous, are placed together on the other side of the vertical line. - if there is more than one species in solution, and the species are on different sides of the half-equation, the different species are separated by a comma.
E.g. Zn²⁺(aq) + 2e == Zn(s)
E.g. Fe3+(aq) + e == Fe2+(aq)
E.g. Cl2(g) + 2e == 2Cl-(aq)
When two half-cells are connected to form a full electrochemical cell, the cell is written as follows:
- the more positive electrode is always placed on the right - the two half-cells are placed on either side of two vertical broken lines (which represent the salt bridge - the electrodes are placed on the far left and far right, and the other species are placed adjacent to the vertical broken lines in the centre - on the left (oxidation), the lower oxidation state species is written first, and the higher oxidation state species is written second. - on the right (reduction) the higher oxidation state species is written first, and the lower oxidation state species is written second.
E.g. Cell reaction = Zn(s) + 2H+(aq) à Zn2+(aq) + H2(g)
E.g. Cell Reaction = Cu2+(aq) + H2(g) à Cu(s) + 2H+(aq)
E.g. Cell reaction = Ag+(aq) + Fe2+(aq) à Ag(s) + Fe3+(aq)
This method of representing electrochemical cells is known as the conventional representation of a cell, and it is widely used.
One advantage of this notation is that it is easy to see the reduction and oxidation processes taking place.
On the LHS (oxidation): electrode à reduced species à oxidised species On the RHS (reduction): oxidised species à reduced species à electrode
THE ELECTROCHEMICAL SERIES [ edit | edit source ]
If all of the standard electrode potentials are arranged in order, usually starting with the most negative, a series is set up which clearly shows the relative tendency of all the half-reactions to undergo oxidation and reduction. This series is known as the electrochemical series, and a reduced form of this series is shown as follows:
HALF-EQUATION Eo/V
Li+(aq) + e == Li(s) -3.03
K+(aq) + e == K(s) -2.92
Ca2+(aq) + 2e == Ca(s) -2.87
Na+(aq) + e == Na(s) -2.71
Mg2+(aq) + 2e == Mg(s) -2.37
Be2+(aq) + 2e == Be(s) -1.85
Al3+(aq) + 3e == Al(s) -1.66
Mn2+(aq) + 2e == Mn(s) -1.19
V2+(aq) + 2e == V(s) -1.18
Zn2+(aq) + 2e == Zn(s) -0.76
Cr3+(aq) + 3e == Cr(s) -0.74
Fe2+(aq) + 2e == Fe(s) -0.44
2H2O(l) + 2e == H2(g) + 2OH-(aq) -0.42
PbSO4(s) + 2e == Pb(s) + SO42-(aq) -0.36
Co2+(aq) + 2e == Co(s) -0.28
V3+(aq) + e == V2+(aq) -0.26
Ni2+(aq) + 2e == Ni(s) -0.25
Sn2+(aq) + 2e == Sn(s) -0.14
CrO42-(aq) + 4H2O(l) + 3e == Cr(OH)3(s) + 5OH-(aq) -0.13
Pb2+(aq) + 2e == Pb(s) -0.13
CO2(g) + 2H+(aq) + 2e == CO(g) + H2O(l) -0.10
2H+(aq) + 2e == H2(g) 0.00
S4O62-(aq) + 2e == 2S2O32-(aq) +0.09
Cu2+(aq) + e == Cu+(aq) +0.15
4H+(aq) + SO42-(aq) + 2e == H2SO3(aq) + 2H2O(l) +0.17
Cu2+(aq) + 2e == Cu(s) +0.34
VO2+(aq) + 2H+(aq) + e == V3+(aq) + H2O(l) +0.34
Cu+(aq) + e == Cu(s) +0.52
I2(aq) + 2e == 2I-(aq) +0.54
2H+(aq) + O2(g) + 2e == H2O2(aq) +0.68
Fe3+(aq) + e == Fe2+(aq) +0.77
Ag+(aq) + e == Ag(s) +0.80
2H+(aq) + NO3-(aq) + e == NO2(g) + H2O(l) +0.81
VO2+(aq) + 2H+(aq) + e == VO2+(aq) + H2O(l) +1.02
Br2(aq) + 2e == 2Br-(aq) +1.09
2IO3-(aq) + 12H+(aq) + 10e == I2(aq) + 6H2O(l) +1.19
O2(g) + 4H+(aq) + 4e == 2H2O(l) +1.23
MnO2(s) + 4H+(aq) + 2e == Mn2+(aq) + 2H2O(l) +1.23
Cr2O72-(aq) + 14H+(aq) + 6e == 2Cr3+(aq) + 7H2O(l) +1.33
Cl2(g) + 2e == 2Cl-(aq) +1.36
PbO2(s) + 4H+(aq) + 2e == Pb2+(aq) + 2H2O(l) +1.46
MnO4-(aq) + 8H+(aq) + 5e == Mn2+(aq) + 4H2O(l) +1.51
PbO2(s) + 4H+(aq) + SO42-(aq) == PbSO4(s) + 2H2O(l) +1.69
MnO4-(aq) + 4H+(aq) + 3e == MnO2(s) + 2H2O(l) +1.70
H2O2(aq) + 2H+(aq) + 2e == 2H2O(l) +1.77
Ag2+(aq) + e == Ag+(aq) +1.98
F2(g) + 2e == 2F-(aq) +2.87
• Note that all half-equations are written as reduction processes. This is in accordance with the IUPAC convention for writing half-equations for electrode reactions.
The electrochemical series has a number of useful features:
• All the species on the left-hand side of the series are can accept electrons and be reduced to a lower oxidation state. They are therefore all oxidising agents. All the species on the right-hand side of the series can give up electrons and be oxidised to a higher oxidation state, and are thus reducing agents.
• The higher a half-equation is located in the electrochemical series, the more negative the standard electrode potential and the greater the tendency to undergo oxidation. The reducing agents at the top of the series are thus very strong, and the oxidising agents very weak. The lower down a half-equation is located in the electrochemical series, the more positive the standard electrode potential and the greater the tendency to undergo reduction. The oxidising agents at the bottom of the series are thus very strong, and the reducing agents very weak.
It can therefore be deduced that: i) oxidising agents increase in strength on descending the electrochemical series ii) reducing agents decrease in strength on descending the electrochemical series
• If two half-cells are connected, the half-cell higher up the electrochemical series (i.e. more negative) will undergo oxidation and the half-cell lower down the electrochemical series (i.e. more positive) will undergo reduction.
• Many of these electrode potentials cannot be measured experimentally, since one of the species involved reacts with water. In such cases the standard electrode potentials are calculated, often using a complex Born-Haber cycle.
SPONTANEOUS REACTIONS [ edit | edit source ]
If two half-cells are connected electrically and a current allowed to flow, the more positive electrode will undergo reduction and the more negative electrode will undergo oxidation. The oxidising agent at the more positive electrode is reduced, and thus oxidises the reducing agent at the more negative electrode.
E.g. If the zinc electrode and the copper electrode are connected, the following reaction takes place: Zn(s) + Cu2+(aq) à Zn2+(aq) + Cu(s)
It can be assumed that if a reaction occurs electrochemically, it will also occur chemically. Thus if zinc metal is added to a solution of copper (II) sulphate, the above reaction will occur. If copper metal is added to a solution of zinc (II) sulphate, however, no reaction will occur. If any reaction did occur, it would have to be Cu(s) + Zn2+(aq) à Cu2+(aq) + Zn(s)
This reaction is not the one which takes place if the two half-cells are connected, and therefore cannot be expected to take place in other circumstances.
Oxidising agents and reducing agents [ edit | edit source ]
Since the more positive electrodes are at the bottom of the electrochemical series, the oxidising agents in these systems will oxidise any reducing agent which lies above it in the electrochemical series.
E.g. H+(aq) will oxidise Pb(s) to Pb2+(aq), and any other metal above it, but will not oxidise Cu(s) to Cu2+(aq) or any metal below it. Pb(s) + 2H+(aq) à Pb2+(aq) + H2(g)
Acids such as nitric acid, however, which contains the more powerful oxidising agent NO3-(aq), will oxidise any reducing agent with a standard electrode potential more negative than +0.81V, e.g. Cu(s) Cu(s) + 4H+(aq) + 2NO3-(aq) à Cu2+(aq) + 2NO2(g) + 2H2O(l)
Reducing agents will reduce any oxidising agent which lies below it in the electrochemical series.
E.g. Fe2+(aq) will reduce VO2+(aq) to VO2+(aq), but not VO2+(aq) to V3+(aq) or V3+(aq) to V2+(aq) VO2+(aq) + 2H+(aq) + Fe2+(aq) à VO2+(aq) + H2O(l) + Fe3+(aq)
Cell potential [ edit | edit source ]
A more systematic method of predicting whether or not a reaction will occur is to construct two half-equations, one reduction and one oxidation, for the reaction trying to take place. Since reduction occurs at the more positive electrode, consider the reduction process to be the right-hand electrode and the oxidation process to be the left-hand electrode. The cell potential for the reaction is given by ERHS - ELHS, or EReduction - EOxidation. If the cell potential is positive, the reaction will occur. If the cell potential is negative, the reaction will not occur. This method can be used to predict whether or not any given redox reaction will take place.
Displacement reactions [ edit | edit source ]
E.g. Predict whether or not zinc metal will displace iron from a solution of FeSO4(aq). The reaction under consideration is Zn(s) + Fe2+(aq) == Zn2+(aq) + Fe(s) Reduction: Fe2+(aq) + 2e == Fe(s) (Eo = -0.44V) Oxidation: Zn(s) == Zn2+(aq) + 2e (Eo = -0.76V) ECELL = -0.44 -(-0.76) = +0.32V So the reaction will occur.
E.g. Predict whether or not zinc metal will desplace manganese from a solution of MnSO4(aq) The reaction under consideration is Zn(s) + Mn2+(aq) à Zn2+(aq) + Mn(s) Reduction: Mn2+(aq) + 2e == Mn(s) (Eo = -1.19V) Oxidation: Zn(s) == Zn2+(aq) + 2e (Eo = -0.76V) ECELL = -1.19 -(0.76) = -0.43V So the reaction will not occur.
E.g. Predict whether or not bromine will displace iodine from a solution of KI(aq) The reaction under consideration is Br2(aq) + 2I-(aq) == 2Br-(aq) + I2(aq) Reduction: Br2(aq) + 2e == 2Br-(aq) (Eo = +1.09V) Oxidation: 2I-(aq) == I2(aq) + 2e (Eo = +0.54V) ECELL = 1.09 - 0.54 = +0.55V So the reaction will occur.
E.g. Predict whether or not bromine will displace chlorine from a solution of NaCl(aq) The reaction under consideration is Br2(aq) + 2Cl-(aq) == 2Br-(aq) + Cl2(aq) Reduction: Br2(aq) + 2e == 2Br-(aq) (Eo = +1.09V) Oxidation: 2Cl-(aq) == Cl2(aq) + 2e (Eo = +1.36V) ECELL = 1.09 - 1.36 = -0.27V So the reaction will not occur.
Disproportionation [ edit | edit source ]
Standard electrode potentials can be used to predict whether or not a species will disproportionate.
E.g. Predict whether or not Ag+ ions will disproportionate in aqueous solution. Ag+ might be expected to disproportionate according to the following half-reactions: Ag+(aq) + e == Ag(s) reduction, Eo = + 0.80V Ag+(aq) == Ag2+(aq) + e oxidation, Eo = + 1.98V ECELL = 0.80 - 1.98 = -1.18V Therefore Ag+ will not disproportionate
E.g. Predict whether or not H2O2 will disproportionate in aqueous solution. H2O2 might be expected to disproportionate according to the following half-reactions: H2O2(aq) + 2H+(aq) + 2e == 2H2O(l) reduction, Eo = +1.77V H2O2(aq) == 2H+(aq) + O2(g) + 2e oxidation, Eo = +0.68V ECELL = 1.77 - 0.68 = +1.09V Therefore H2O2(aq) will disproportionate: 2H2O2(aq) + 2H+(aq) à 2H+(aq) + O2(g) + 2H2O(l) 2H2O2(aq) à 2H2O(l) + O2(g)
Non-standard conditions [ edit | edit source ]
Though cell potential is often a correct prediction of whether or not a given reaction will take place, it does strictly apply only to standard conditions. If the solutions used are either very concentrated or very dilute, then the electrode potentials will not be the standard electrode potentials and the sign of the cell potential may be different from that predicted under standard conditions. Thus many reactions which are not expected to occur do in fact take place if the solutions are hot or concentrated, and many reactions which are expected to occur do not take place if the solutions are too dilute.
E.g. The reaction between manganese dioxide and hydrochloric acid. MnO2(s) + 4H+(aq) + 2Cl-(aq) à Mn2+(aq) + Cl2(g) + 2H2O(l) Reduction: MnO2(s) + 4H2+(aq) + 2e == Mn2+(aq) + 2H2O(l) Eo = +1.23V Oxidation: 2Cl-(aq) àCl2(g) + 2e Eo = +1.36V ECELL = Er - Eo = -0.13V
This reaction does not occur under standard conditions. However if hot concentrated HCl is used, the high Cl- concentration favours oxidation, the electrode potential becomes less positive and ECELL thus becomes positive and the reaction occurs.
E.g. The reaction between potassium dichromate (VI) and hydrochloric acid. Cr2O72-(aq) + 14H+(aq) + 6Cl-(aq) à 2Cr3+(aq) + 3Cl2(g) + 7H2O(l) Reduction: Cr2O72-(aq) + 14H+(aq) + 6e == 2Cr3+(aq) + 7H2O(l) Eo = +1.33V Oxidation: 2Cl-(aq) == Cl2(g) + 2e Eo = +1.36V ECELL = Er - Eo = -0.03V This reaction does not occur under standard conditions. However if solid potassium dichromate is dissolved in hydrochloric acid, the high Cr2O72- concentration favours reduction and makes the electrode potential more positive. Thus ECELL becomes positive and the reaction occurs.
Kinetic stability [ edit | edit source ]
Cell potentials can be used effectively to predict whether or not a given reaction will take place, but they give no indication as to how fast a reaction will proceed. In many cases ECELL is positive but no apparent reaction occurs. This is because the reactants are kinetically stable; the reaction has a high activation energy so is very slow at room temperature. There are many examples of this in inorganic chemistry:
E.g. Mg(s) + 2H2O(l) à Mg2+(aq) + 2OH-(aq) + H2O(g) E = -0.42V, E = -2.38V so ECELL = Er - Eo = +1.96V So a reaction is expected but no reaction takes place. This is because the activation energy is too high (magnesium will react with steam and slowly with hot water).
Thus if a reaction is expected to take place but is found not to, there are two possible reasons: - the solutions are too dilute (i.e. conditions are non-standard) - the reaction is very slow (i.e. reactants are kinetically stable)
If a reaction is not expected to take place but does take place, then it is because the conditions are non-standard (i.e. the solutions are concentrated).
- Book:A-level Chemistry
Navigation menu

Electrochemical Cells
Electrode potentials & Cells
AQA Content
Use EƟ values to predict the direction of simple redox reactions
Calculate the emf of a cell, write and apply the conventional representation of a cell..
Specification Notes
IUPAC convention for writing half-equations for electrode reactions.
The conventional representation of cells., cells are used to measure electrode potentials by reference to the standard hydrogen electrode., the importance of the conditions when measuring the electrode potential, e (nernst equation not required)., standard electrode potential, eɵ, refers to conditions of 298 k, 100 kpa and 1.00 mol dm−3 solution of ions., standard electrode potentials can be listed as an electrochemical series..
Book a free consultation now
100+ Video Tutorials, Flashcards and Weekly Seminars
- Revision notes >
- A-level Chemistry Revision Notes >
- AQA A-Level Chemistry Revision Notes
Electrode Potentials and Electrochemical Cells - Representing Electrochemical Cells (A-Level Chemistry)
Representing electrochemical cells.
IUPAC (International Union of Pure and Applied Chemistry) came up with some conventions for representing electrochemical cells.
An electrochemical cell can be represented in a diagram, as shown above in figure 1:

In addition to diagrams, cells can also be represented written down in shorthand form :

The following conventions are used to represent the cell:
- Double vertical solid line = salt bridge
- Vertical solid line = phase boundary, e.g, between an aqueous solution (aq) and a solid (s).
- Species with the highest oxidation state = written closest to the salt bridge (the double vertical line).
- The half cell with the more negative potential = goes on the left
- Platinum electrode is used when there are no solid electrodes in the half cell.
Worked example:
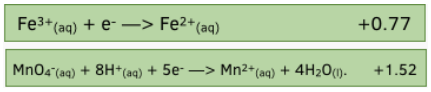
A half cell containing Fe³+ and Fe²+ ions is connected to a half cell containing acidified manganate (VII) ions.
Use the standard electrode potentials to write the correct cell notation.
The MnO4- half cell has a more positive electrode potential and therefore the reduction reaction will occur. This cell will be placed on the right.
Fe²+ ions will be oxidised to form Fe³+ ions. This half cell will be placed on the left hand side.
As there are no solids in either half cells, platinum electrodes are needed in each.
The cell can be represented by:-
Still got a question? Leave a comment
Leave a comment, cancel reply.
Save my name, email, and website in this browser for the next time I comment.
AQA 3.1.1 Atomic structure
Ionisation energies (a-level chemistry), atomic structure – electron arrangement (a-level chemistry), atomic structure – electrons in atoms (a-level chemistry), atomic structure – mass spectrometry (a-level chemistry), atomic structure – element isotopes (a-level chemistry), atomic structure – atomic and mass number (a-level chemistry), atomic structure – subatomic particles (a-level chemistry), aqa 3.1.10 equilibrium constant kp for homogeneous systems, equilibrium constant for homogenous systems – le chatelier’s principle in gas equilibria (a-level chemistry), equilibrium constant for homogenous systems – gas equilibria and kp (a-level chemistry), equilibrium constant for homogeneous system – changing kp (a-level chemistry), equilibrium constant for homogenous systems – gas partial pressures (a-level chemistry), aqa 3.1.11 electrode potentials and electrochemical cells, acids and bases – drawing ph curves (a-level chemistry), acids and bases – acid-base indicators (a-level chemistry), acids and bases – dilutions and ph (a-level chemistry), electrode potentials and electrochemical cells – commercial applications of fuel cells (a-level chemistry), electrode potentials and electrochemical cells – electrochemical cells reactions (a-level chemistry), electrode potentials and electrochemical cells – representing electrochemical cells (a-level chemistry), electrode potentials and electrochemical cells – electrode potentials (a-level chemistry), electrode potentials and electrochemical cells – half cells and full cells (a-level chemistry), aqa 3.1.12 acids and bases, acids and bases – titrations (a-level chemistry), acids and bases – buffer action (a-level chemistry), acids and bases – ph of strong bases (a-level chemistry), acids and bases – ionic product of water (a-level chemistry), acids and bases – more ka calculations (a-level chemistry), acids and bases – the acid dissociation constant, ka (a-level chemistry), acids and bases – the ph scale and strong acids (a-level chemistry), acids and bases – neutralisation reactions (a-level chemistry), acids and bases – acid and base strength (a-level chemistry), acids and bases – the brønsted-lowry acid-base theory (a-level chemistry), aqa 3.1.2 amount of substance, amount of substance – percentage atom economy (a-level chemistry), amount of substance – calculating percentage yields (a-level chemistry), amount of substance – stoichiometric calculations (a-level chemistry), amount of substance – balancing chemical equations (a-level chemistry), amount of substance – empirical and molecular formulae (a-level chemistry), amount of substance – further mole calculations (a-level chemistry), amount of substance- the mole and the avogadro constant (a-level chemistry), amount of substance – measuring relative masses (a-level chemistry), amount of substance – the ideal gas equation (a-level chemistry), aqa 3.1.3 bonding, periodicity – classification (a-level chemistry), bonding – hydrogen bonding in water (a-level chemistry), bonding – forces between molecules (a-level chemistry), bonding – bond polarity (a-level chemistry), bonding – molecular shapes (a-level chemistry), bonding – predicting structures (a-level chemistry), bonding – carbon allotropes (a-level chemistry), bonding – properties of metallic bonding (a-level chemistry), bonding – properties of covalent structures (a-level chemistry), bonding – covalent bonds (a-level chemistry), aqa 3.1.4 energetics, aqa 3.1.5 kinetics, kinetics – the maxwell–boltzmann distribution and catalysts (a-level chemistry), kinetics – the collision theory and reaction rates (a-level chemistry), aqa 3.1.6 chemical equilibria, calculations with equilibrium constants (a-level chemistry), chemical equilibria applied to industry (a-level chemistry), chemical equilibria and le chatelier’s principle (a-level chemistry), aqa 3.1.7 oxidation, reduction and redox, oxidation, reduction and redox equations – balancing redox equations (a-level chemistry), oxidation, reduction and redox equations – redox processes (a-level chemistry), oxidation, reduction and redox equations – oxidation states (a-level chemistry), aqa 3.1.8 thermodynamics, thermodynamic – calculations involving free energy (a-level chemistry), thermodynamic – gibbs free energy (a-level chemistry), thermodynamic – entropy change predictions (a-level chemistry), thermodynamic – total entropy changes (a-level chemistry), thermodynamic – introduction to entropy (a-level chemistry), thermodynamic – calculating enthalpy changes of solution (a-level chemistry), thermodynamic – enthalpy of solution (a-level chemistry), thermodynamic – enthalpy of hydration (a-level chemistry), thermodynamic – calculations involving born-haber cycles (a-level chemistry), thermodynamic – construction of born-haber cycles (a-level chemistry), aqa 3.1.9 rate equations, rate equations – reaction determining steps (a-level chemistry), rate equations – reaction half lives (a-level chemistry), rate equations – uses of clock reactions (a-level chemistry), rate equations – determining orders of reactions graphically (a-level chemistry), rate equations – determining order of reaction experimentally (a-level chemistry), rate equations – temperature changes and the rate constant (a-level chemistry), rate equations – the rate constant (a-level chemistry), rate equations – introduction to orders of reactions (a-level chemistry), rate equations – the rate equation (a-level chemistry), rate equations – measuring rate of reaction (a-level chemistry), aqa 3.2.1 periodicity, periodicity – trends along period 3 (a-level chemistry), aqa 3.2.2 group 2, the alkaline earth metals, uses of group 2 elements and their compounds (a-level chemistry), reactions of group 2 elements (a-level chemistry), group 2, the alkaline earth metals (a-level chemistry), aqa 3.2.3 group 7(17), the halogens, the halogens -halide ions and their reactions (a-level chemistry), the halogens – disproportionation reactions in halogens (a-level chemistry), the halogens – reactions with halogens (a-level chemistry), the halogens – group 7, the halogens (a-level chemistry), aqa 3.2.4 properties of period 3 elements, properties of period 3 elements – properties of period 3 compounds (a-level chemistry), properties of period 3 elements – reactivity of period 3 elements (a-level chemistry), aqa 3.2.5 transition metals, transition metals – autocatalysis of transition metals (a-level chemistry), transition metals – transition metals as homogeneous catalysts (a-level chemistry), transition metals – transition metals as heterogeneous catalysts (a-level chemistry), transition metals – examples of redox reactions in transition metals (a-level chemistry), transition metals – iodine-sodium thiosulfate titrations (a-level chemistry), transition metals – carrying titrations with potassium permanganate (a-level chemistry), transition metals – redox titrations (a-level chemistry), transition metals – redox potentials (a-level chemistry), transition metals – redox reactions revisited (a-level chemistry), transition metals – ligand substitution reactions (a-level chemistry), aqa 3.2.6 reactions of ions in aqueous solution, reactions of ions in aqueous solutions – metal ions in solution (a-level chemistry), aqa 3.3.1 introduction to organic chemistry, introduction to organic chemistry – structural isomers (a-level chemistry), introduction to organic chemistry – e/z isomerism (a-level chemistry), introduction to organic chemistry – reaction mechanisms in organic chemistry (a-level chemistry), introduction to organic chemistry – general formulae (a-level chemistry), introduction to organic chemistry – introduction to functional groups (a-level chemistry), introduction to organic chemistry – naming and representing organic compounds (a-level chemistry), aqa 3.3.10 aromatic chemistry, aromatic chemistry – friedel-crafts acylation and alkylation (a-level chemistry), aromatic chemistry – halogenation reactions in benzene (a-level chemistry), aromatic chemistry – electrophilic substitution reactions in benzene (a-level chemistry), aromatic chemistry – improved benzene model (a-level chemistry), aromatic chemistry – introduction to benzene (a-level chemistry), aqa 3.3.11 amines, amines – nitriles (a-level chemistry), amines – properties and reactivity of amines (a-level chemistry), amines – amine synthesis (a-level chemistry), amines – introduction to amines (a-level chemistry), aqa 3.3.12 polymers, polymer disposal (a-level chemistry), polymer biodegradability (a-level chemistry), condensation polymers (a-level chemistry), polyamide formation (a-level chemistry), aqa 3.3.13 amino acids, amino acids, proteins and dna – dna replication (a-level chemistry), amino acids, proteins and dna – dna (a-level chemistry), amino acids, proteins and dna – enzyme action (a-level chemistry), amino acids, proteins and dna – structure of proteins (a-level chemistry), amino acids, proteins and dna – structure of amino acids (a-level chemistry), aqa 3.3.14 organic synthesis, organic synthesis – considerations in organic synthesis (a-level chemistry), organic synthesis – organic synthesis: aromatic compounds (a-level chemistry), organic synthesis – organic synthesis: aliphatic compounds (a-level chemistry), aqa 3.3.15 nmr, analytical techniques – high resolution ¹h nmr (a-level chemistry), analytical techniques – types of nmr: hydrogen (a-level chemistry), analytical techniques – types of nmr: carbon 13 (a-level chemistry), analytical techniques – nmr samples and standards (a-level chemistry), analytical techniques – nuclear magnetic resonance spectroscopy (a-level chemistry), aqa 3.3.16 chromatography, analytical techniques – different types of chromatography (a-level chemistry), analytical techniques – chromatography (a-level chemistry), aqa 3.3.2 alkanes, alkanes – obtaining alkanes (a-level chemistry), alkanes – alkanes: properties and reactivity (a-level chemistry), aqa 3.3.3 halogenoalkanes, halogenoalkanes – environmental impact of halogenalkanes (a-level chemistry), halogenoalkanes – reactivity of halogenoalkanes (a-level chemistry), halogenoalkanes – introduction to halogenoalkanes (a-level chemistry), aqa 3.3.4 alkenes, alkenes – addition polymerisation in alkenes (a-level chemistry), alkenes – alkene structure and reactivity (a-level chemistry), aqa 3.3.5 alcohols, alcohols – industrial production of alcohols (a-level chemistry), alcohols – alcohol reactivity (a-level chemistry), alcohols – alcohol oxidation (a-level chemistry), alcohols – introduction to alcohols (a-level chemistry), aqa 3.3.6 organic analysis, organic analysis – infrared (ir) spectroscopy (a-level chemistry), organic analysis – identification of functional groups (a-level chemistry), aqa 3.3.7 optical isomerism, optical isomerism (a-level chemistry), aqa 3.3.8 aldehydes and ketones, aldehydes and ketones – reactions to increase carbon chain length (a-level chemistry), aldehydes and ketones – testing for carbonyl compounds (a-level chemistry), aldehydes and ketones – reactivity of carbonyl compunds (a-level chemistry), aldehydes and ketones – carbonyl compounds (a-level chemistry), aqa 3.3.9 carboxylic acids, carboxylic acids and derivatives – structure of amides (a-level chemistry), carboxylic acids and derivatives – acyl groups (a-level chemistry), carboxylic acids and derivatives – properties and reactivity of esters (a-level chemistry), carboxylic acids and derivatives – properties and reactivity of carboxylic acids (a-level chemistry), 21: organic synthesis, 29: intro to organic chemistry, aromatic chemistry – benzene nomenclature (a-level chemistry), cie 1: atomic structure, bonding – ion formation (a-level chemistry), cie 10: group 2, cie 11: group 17, cie 13: intro to as organic chemistry, cie 14: hydrocarbons, cie 15: halogen compounds, cie 16: hydroxy compounds, cie 17: carbonyl compounds, cie 18: carboxylic acids and derivatives, cie 19: nitrogen compounds, cie 2: atoms, molecules and stoichiometry, cie 20: polymerisation, cie 22: analytical techniques, cie 23: chemical energetics, cie 24: electrochemistry, cie 25: equilibria, cie 27: group 2 elements, cie 28: chemistry of transition elements, transition metals – colour in transition metal ions (a-level chemistry), transition metals – optical isomerism in complex ions (a-level chemistry), transition metals – cis-trans isomerism in complex ions (a-level chemistry), transition metals – complex ion shape (a-level chemistry), transition metals – ligands (a-level chemistry), transition metals – introduction to complex ions (a-level chemistry), cie 3: chemical bonding, bonding – properties of ionic bonding (a-level chemistry), cie 30: hydrocarbons, aromatic chemistry – reactivity of substituted benzene (a-level chemistry), cie 31: halogen compounds, cie 32: hydroxy compounds, cie 33: carboxylic acids and derivatives, cie 34: nitrogen compounds, cie 35: polymerisation, cie 36: organic synthesis, cie 37: analytic techniques, analytical techniques – deuterium use in ¹h nmr (a-level chemistry), cie 4: states of matter, cie 6: electrochemistry, cie 7: equilibria, cie 8: reaction kinetics, cie 9: the periodic table, cie: 26: reaction kinetics, catalysts, edexcel topic 1: atomic structure and the periodic table, edexcel topic 10: equlibrium 1, edexcel topic 11: equilibrium 2, edexcel topic 12: acid-base equilibria, edexcel topic 13: energetics 2, edexcel topic 14: redox 2, edexcel topic 15: transition metals, edexcel topic 16: kinetics 2, edexcel topic 17: organic chemistry 2, edexcel topic 18: organic chemistry 3, organic synthesis – practical purification techniques (a-level chemistry), organic synthesis – practical preparation techniques (a-level chemistry), edexcel topic 19: modern analytical techniques 2, edexcel topic 2a & b: bonding and structure, edexcel topic 3: redox 1, edexcel topic 4: inorganic chemistry & the periodic table, the halogens – testing for ions (a-level chemistry), edexcel topic 5: formulae, equations and amounts of substance, edexcel topic 6: organic chemistry 1, edexcel topic 7: modern analytical techniques 1, edexcel topic 8, edexcel topic 9: kinetics 1, related links.
- 1-1 Tutoring
- Online Course
Boost your A-Level Chemistry Performance
Get an A* in A-Level Chemistry with our Trusted 1-1 Tutors. Enquire now.
100+ Video Tutorials, Flashcards and Weekly Seminars. 100% Money Back Guarantee

Let's get acquainted ? What is your name?
Nice to meet you, {{name}} what is your preferred e-mail address, nice to meet you, {{name}} what is your preferred phone number, what is your preferred phone number, just to check, what are you interested in, when should we call you.
It would be great to have a 15m chat to discuss a personalised plan and answer any questions
What time works best for you? (UK Time)
Pick a time-slot that works best for you ?
How many hours of 1-1 tutoring are you looking for?
My whatsapp number is..., for our safeguarding policy, please confirm....
Please provide the mobile number of a guardian/parent
Which online course are you interested in?
What is your query, you can apply for a bursary by clicking this link, sure, what is your query, thank you for your response. we will aim to get back to you within 12-24 hours., lock in a 2 hour 1-1 tutoring lesson now.
If you're ready and keen to get started click the button below to book your first 2 hour 1-1 tutoring lesson with us. Connect with a tutor from a university of your choice in minutes. (Use FAST5 to get 5% Off!)

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
Conventional cell
- Last updated
- Save as PDF
- Page ID 17919
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
For each lattice, the conventional cell is the cell obeying the following conditions:
- its basis vectors define a right-handed axial setting;
- its edges are along symmetry directions of the lattice;
- it is the smallest cell compatible with the above condition.
Crystals having the same type of conventional cell belong to the same crystal family.
- International
- Schools directory
- Resources Jobs Schools directory News Search

Electrochemical Cells - Conventional Representation / Cell Notation Worksheet
Subject: Chemistry
Age range: 16+
Resource type: Worksheet/Activity
Last updated
2 November 2021
- Share through email
- Share through twitter
- Share through linkedin
- Share through facebook
- Share through pinterest

This set contains two worksheets aimed at A-level Chemistry students. The first worksheet asks students to write conventional representation for electrochemical cells and the second asks them to write half equations when given the conventional representation.
Tes paid licence How can I reuse this?
Your rating is required to reflect your happiness.
It's good to leave some feedback.
Something went wrong, please try again later.
This resource hasn't been reviewed yet
To ensure quality for our reviews, only customers who have purchased this resource can review it
Report this resource to let us know if it violates our terms and conditions. Our customer service team will review your report and will be in touch.
Not quite what you were looking for? Search by keyword to find the right resource:
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 10 May 2024
VOLTA: an enVironment-aware cOntrastive ceLl represenTation leArning for histopathology
- Ramin Nakhli ORCID: orcid.org/0000-0001-6463-4465 1 na1 ,
- Katherine Rich 2 na1 ,
- Allen Zhang 3 ,
- Amirali Darbandsari 4 ,
- Elahe Shenasa 3 ,
- Amir Hadjifaradji 1 ,
- Sidney Thiessen 5 ,
- Katy Milne ORCID: orcid.org/0000-0001-5616-1821 5 ,
- Steven J. M. Jones ORCID: orcid.org/0000-0003-3394-2208 6 , 7 ,
- Jessica N. McAlpine ORCID: orcid.org/0000-0001-6003-485X 8 ,
- Brad H. Nelson 5 ,
- C. Blake Gilks 3 ,
- Hossein Farahani ORCID: orcid.org/0000-0002-9503-1875 1 na2 &
- Ali Bashashati ORCID: orcid.org/0000-0002-4212-7224 1 , 3 , 6 na2
Nature Communications volume 15 , Article number: 3942 ( 2024 ) Cite this article
4 Altmetric
Metrics details
- Cancer imaging
- Gynaecological cancer
In clinical oncology, many diagnostic tasks rely on the identification of cells in histopathology images. While supervised machine learning techniques necessitate the need for labels, providing manual cell annotations is time-consuming. In this paper, we propose a self-supervised framework (enVironment-aware cOntrastive cell represenTation learning: VOLTA) for cell representation learning in histopathology images using a technique that accounts for the cell’s mutual relationship with its environment. We subject our model to extensive experiments on data collected from multiple institutions comprising over 800,000 cells and six cancer types. To showcase the potential of our proposed framework, we apply VOLTA to ovarian and endometrial cancers and demonstrate that our cell representations can be utilized to identify the known histotypes of ovarian cancer and provide insights that link histopathology and molecular subtypes of endometrial cancer. Unlike supervised models, we provide a framework that can empower discoveries without any annotation data, even in situations where sample sizes are limited.
Similar content being viewed by others

Cluster-based histopathology phenotype representation learning by self-supervised multi-class-token hierarchical ViT

Identification of cell types in multiplexed in situ images by combining protein expression and spatial information using CELESTA

Human-interpretable image features derived from densely mapped cancer pathology slides predict diverse molecular phenotypes
Introduction.
Cells located within the micro-environment of a tumor have a prominent impact on its developmental process 1 , 2 , 3 , 4 , 5 . Variations in the micro-environment have been associated with the epigenetic profiles within the tumor and the heterogeneity in the associated gene expression profiles 6 . Various cell types reside in the tumor micro-environment and growing evidence suggest that intratumoral heterogeneity is a large contributing factor to the therapeutic resistance of the tumor 6 , 7 . Several studies have shown that higher levels of intratumoral heterogeneity are strongly associated with poor outcomes in lung, ovarian, head and neck, and pancreatic cancers, with implications that the tumor is more likely to harbor a rare pre-existing resistant subclone 6 , 8 , 9 , 10 . Furthermore, spatial distribution of immune cells within the tumor microenvironment has a significant impact on the prognosis and therapeutic responses 4 , 11 , 12 , 13 , 14 . Therefore, the identification of individual cells within the tumor micro-environment is a vital step for tumor characterization in many complex tasks such as tissue classification, cancer diagnosis, subtyping and histological grading 15 , 16 , 17 , 18 .
The visual assessment of the Hematoxylin & Eosin (H&E)-stained tissue slides under the microscope is the conventional and widely utilized approach to tumor characterization and cell identification. However, manual cell identification can be cumbersome due to the time-consuming nature of the assessment of large numbers of cells (tens of thousands in a single slide) and suffers from pathologists’ intra- and inter-observer variability 19 . Machine learning and deep learning models coupled with the digitization of pathological material offer opportunities for computer-aided cell identification 20 , 21 , 22 . Despite the long history of machine learning research in cell classification using handcrafted features 23 , 24 , 25 , significant improvements have been reported by employing deep learning-based models 21 . For example, in a recent study 26 , authors developed a pipeline for segmentation and identification of several molecular features of cells from H&E images by employing supervised techniques while the ground truth data (i.e., labels) were generated through immunohistochemistry (IHC) staining and co-registration of IHC and H&E images.
Even though supervised models can potentially reduce the manual workload of cell identification, they require a large number of cell-level annotations for training. However, generating annotations requires labor-intensive manual examination of the tissue by pathologists. Furthermore, a model trained on a specific tissue type (e.g., ovarian cancer) cannot be directly applied to another tissue type (e.g., breast cancer); therefore, the data collection and labeling process has to be carried out again to retrained the model for a new tissue type. To address this issue, several studies have utilized unsupervised approaches for cell representation learning and clustering 27 . adopt InfoGAN 28 to train an implicit classifier, and in another attempt 29 , use a deep convolutional auto-encoder (DCAE) to learn the embeddings of cells. However, these studies focus on a single tissue type, which may not generalize to other tissues. Additionally, these techniques ignore the surrounding environment of a cell. Many recent studies have shown that cells are directly impacted by their environment 30 , 31 , 32 and as such, incorporation of the environment information may improve the performance of the models.
Recently, self-supervised learning (SSL) techniques have emerged as an important step towards generalizable representation learning. SSL is a technique developed for image representation learning, guided by using the augmentations of an image as its label. The utility of this technique has been investigated on different tasks in the natural image domain where 33 demonstrate the capability of this technique in object classification, and 34 show its efficacy in object detection. Despite the fact that a few studies 35 , 36 examine the utility of self-supervised methods in the patch-level classification of histopathology images, the potential of self-supervised techniques for labeling individual cells (rather than just classifying image patches) are largely ignored. More importantly, cell-based representation and classification techniques provide better linkages to biological mechanisms and tumor micro-environment assessment while patch-based techniques may fail to provide more explainable linkages to biology.
In this work, we propose a self-supervised framework for cell representation learning in histopathology images by introducing a technique to incorporate the mutual relationship between the cell and its environment for improved cell representation. We benchmark our model on data representing more than 800,000 cells in four cancer histotypes with three to six cell types in each dataset. Results confirm the superiority of our model in memory-efficient cell type representation compared to the state-of-the-art. We further utilize the proposed model in the context of ovarian and endometrial cancers and demonstrate that our cell representations, without any human annotations, can be utilized to identify the known histotypes of ovarian cancer, and gain novel insights that link histopathology and molecular subtypes of endometrial cancer.
Cell representation learning framework and benchmarking
Figure 1 depicts an overview of our proposed enVironment-aware cOntrastive cell represenTation leArning model (VOLTA). This framework consists of two major blocks, Cell Block and Environment Block . The Cell Block takes an image of a cell and applies two sets of augmentation operations to create visually distinct perspectives of the cell. This structure is inspired by the architectural design of self-supervised models 37 , 38 . The main purpose of doing so is to have two visually different-looking images of the exact same cell. These two augmented images are then transformed into their respective representation vectors using a stack of deep neural networks and, given that these representations correspond to the same cell, the models are trained to minimize the distance between the two representations. Even though it is possible to utilize more than two branches (i.e., more than two sets of augmentations), the two-branch design prevents complications in the pipeline and the loss function.

Overview of our proposed framework. The cell block trains the backbone model by applying two augmentations on the same cell image, encoding the images, and bringing their representations close to each other. While the backbone is trained through back-propagation, the momentum encoder averages the weights from the backbone. On the other hand, the Environment Block combines the cell representation created by the cell block with the surrounding environment (a larger region around the cell). We mask all of the cells in the environment patch to prevent the model from favoring the cell representation toward that of these cells (Source data are provided as a Source Data file).
The Environment Block of our proposed framework is utilized to increase the mutual information between the cell and a larger patch that captures the environment surrounding it. Specifically, we hypothesize that there is a mutual information between each cell and its environment; therefore, we aim to maximize this mutual information during training. By using the InfoNCE loss function 39 , VOLTA accomplishes this by performing a contrastive cross-modal learning between the cell representation and that of its environment. To prevent the model from biasing towards other cells appearing in the environment, we mask out these cells in the environment patch before feeding it to the model. Finally, the cell representations for downstream tasks such as cell clustering and classification can be obtained by using the backbone model trained in this setting.
We benchmarked these representations across multiple tasks and datasets. More specifically, nine public and private datasets (CoNSeP 21 , NuCLS 22 , Pannuke Breast 40 , Pannuke Colon 40 , Lizard 41 , SarcCell, Oracle, MastCell, and MiDOG 42 ) representing 800,000 cells and six cancer types (colon, breast, and ovarian, skin, neuroendocrine, and sarcoma) were utilized to evaluate the performance of the proposed cell representation model (Supplementary Note 1 and Supplementary Table 1) . Even though our model requires no labels for training, we split the data into train and test sets and use the former for the training of the model.
We also conducted ablation studies on the separate components of our model to measure their effects on the performance (see Supplementary Note 2) . Our experiments suggest that the cell masking operation (Supplementary Table 2) , whole- and local-view augmentations (Supplementary Tables 3 and 4) , memory storage (Supplementary Table 5) , environment patch size (Supplementary Table 6) , and momentum encoder (Supplementary Table 7) provide noticeable performance improvements to our model.
Identification of distinct cell clusters by self-supervised cell representation learning
VOLTA produces cell representations from histopathology images, and these representations should be capable of differentiating between biologically distinct cell types. To test this hypothesis, we used our method to identify cell clusters in each dataset. To be specific, after learning the cell representations in a self-supervised manner using VOLTA, we performed unsupervised clustering on the cell representations and examined the enrichment of the identified clusters with specific cell types. To show the utility of our approach, we compared the performance of VOLTA with the state-of-the-art morphology-based and deep learning-based models for cell representation. As shown in Table 1 , our model outperformed all counterparts by a large margin across multiple clustering metrics in all datasets (adjusted mutual index (AMI) 43 , adjusted rand index (ARI) 44 , Purity 45 , Dunn Index, and Silhouette Score - see Supplementary Note 3 , Supplementary Note 4 , and Supplementary Table 8) , reaching twice the performance of the best-performing baselines in some of the datasets (except for Oracle and SarcCell datasets where SimCLR and GAN perform better, respectively). More importantly, while the performance of the baseline models varies from one cancer to another, our model shows consistent results regardless of the cancer type. As an example, while the morphology-based representation method has the best performance compared to the other baselines over the NuCLS and PanNuke Breast cancer datasets, it has an inferior performance on PanNuke Colon and CoNSeP.
Figure 2 and Supplementary Fig. 1 (Supplementary Note 5) show the Uniform Manifold Approximation and Projection (UMAP) representations of various cell types that were derived by VOLTA using a contour-based and point-based visualization, respectively. The learned representations provide distinct and separable cell populations, thus confirming the comparison metrics that were presented in Table 1 . Additionally, one can observe that our model is able to differentiate between immune cells (T-cell and B-cell) and tumor cells in the Oracle dataset. While this behavior can be seen in the SimCLR baseline, it is not observed in the other baselines (Supplementary Figs. 2 – 4 and Supplementary Note 6) . Similarly, in the NuCLS dataset, our model is able to differentiate between stromal tumor-infiltrating lymphocytes (sTILs) and cancer cells. The same observations can be seen in the PanNuke Colon and CoNSeP datasets where various cell types such as epithelial and inflammatory cells are mapped to distinct locations in the embedding space.

Embedding space representation of each dataset using UMAP. Contours with the same color demonstrate the distribution of the learned representations by our model for that specific cell types. Despite not using labeled data in the training process, our model learns to map cells with the same type close to each other. The co-centered contours with the same color show the distribution of the representation for cells with a specific type (Source data are provided as a Source Data file).
Supervised cell classification accuracy and efficiency improvement
We then aimed to assess the effectiveness of the proposed model in few-shot cell classification in a supervised machine learning setting where labeled samples were available. Specifically, we trained the model using our self-supervised framework and utilized the learned cell representations as inputs for training a simple Multi-Layer Perceptron (MLP) for cell classification. The performance of the trained model on CoNSeP and NuCLS datasets across various settings is shown in Fig. 3 .

After pre-training using our self-supervised framework, a fully-connected layer (single- or double-layer) was added to the end of the backbone (the model generating the cell representations), and they were fine-tuned using the labeled data. We compared fine-tuning with both frozen and unfrozen backbone ( a - CoNSeP and b - NuCLS). To account for the color differences in the train and test cohorts of the NuCLS dataset, we also performed the Vahedain color normalization before the fine-tuning process, which showed a significant boost compared to the unnormalized approach ( c ). The results demonstrate that our fine-tuned model can achieve the same performance as the supervised baselines (HoVer-Net and NuCLS) using only 20% of the labeled data while outperforming these baselines with the full set of the labeled data ( a and c ) (Source data are provided as a Source Data file).
We also demonstrated the effectiveness of our self-supervised cell representation learning framework by using a subset of the labeled cell identities to train an MLP-based cell classifier. Our results showed that the proposed model achieved a reasonable performance with a small subset of the labeled training data (Supplementary Table 9 and Supplementary Note 7) . For instance, with only 0.1% of the training labels, our models achieved 62.7% and 72.6% Top-1 accuracy on the CoNSeP and NuCLS datasets, respectively, while a model that utilized the entire labeled dataset achieved 80.2% and 76.3%. Furthermore, as the number of training labels increased, the classification accuracy consistently improved to an extent that our model outperformed the state-of-the-art Hover-Net model 21 results on the CoNSeP dataset, even with 70% of the training data. It is of note to mention that the number of the parameters of our proposed model is reduced by 60% compared to the HoVer-Net model (Supplementary Table 10 and Supplementary Note 8) . Our model reached an accuracy that was close to the Masked-RCNN model which led to state-of-the-art results in the NuCLS dataset 22 .
Self-supervised cell representation learning is robust to undesired color variations
Previous studies have shown that normalization and domain adaptation methods can enhance the performance of supervised models when the train and test datasets are collected from different sites 46 . Given that the training and validation sets of NuCLS dataset are collected from different sites, we hypothesize that variations in staining and color profiles could lead to over-fitting of the supervised models to the training data. Therefore, we studied the effect of such methods on our proposed model when it was utilized for cell representation learning and supervised cell classification settings. To serve this purpose, we used the Vahadane normalization method 47 within the context of the NuCLS dataset where the slides were stained and scanned in different institutions.
Supplementary Table 11 illustrates the effect of the normalization in the self-supervised setting on the NuCLS dataset. Although 46 showed that patch and slide classification tasks can benefit from cross-institution stain normalization, we noticed that our self-supervised cell representation approach does not benefit much from color normalization strategies. This finding can be attributed to the strong augmentations that were utilized in our self-supervised model training. Moreover, we investigated the effect of color normalization in the supervised fine-tuning setting. Interestingly, although self-supervised clustering results were robust to stain normalization, the supervised fine-tuned model benefited from it to an extent that it outperformed the MaskRCNN model 22 on this dataset (Supplementary Table 12 and Supplementary Note 9) . It is of note to mention that the normalization method was only applied to the test set while the self-supervised model was still trained on the original data (i.e., without any normalization).
VOLTA as a building block for unsupervised cancer subtype identification
We sought to investigate the utility of our proposed self-supervised cell representation model as a building block for annotation-free cancer subtyping. Therefore, we put together a TMA cohort of 12 ovarian cancer cases comprising of clear cell, endometrioid, high-grade serous, and low-grade serous ovarian carcinomas. Applying the same procedure as described in 2.1, we utilized the cells extracted from these images to train our self-supervised model. Subsequently, after applying VOLTA, we extracted cell cluster distributions for each of the TMA core images and used them to perform hierarchical clustering to group the patients (see Supplementary Fig. 5) . The results demonstrate that our model is capable of separating the epithelial ovarian cancer histotypes without a need for annotation or prior knowledge of the histotypes (Fig. 4 a). In particular, four major clusters enriched with each of the four specific histotypes were identified with only two cases that were grouped with other subtypes. These results suggest an 91% accuracy (11 out of 12 that were correctly grouped) in ovarian cancer subtyping; a finding that is in line with results reported in the literature 48 .

a , c Ovarian cancer and ( b , d ) endometrial cancer datasets are hierarchically clustered based on cell cluster proportions. To achieve this, we first train our model to deliver cell representations in a self-supervised manner. For the ovarian cases ( a , c ), our model will be applied to patches, a graph of cells will be built based on the cluster predictions, and the distribution of cell type clusters around each cell will be measured. Lastly, this distribution will be used to cluster the cases into distinct cohorts. In the case of endometrial cancer ( b , d ), we realize the cell count distribution across patches capture enough information for providing the separation. Therefore, after applying the model to each patch, we measure the distribution of cell type clusters across all the patches and use this distribution for a hierarchical clustering. In panel b , the supercluster on the right (yellow) demonstrates a cohort of patients that mostly have the POLE subtype (only one sample from p53abn is in this group), the supercluster in the middle (red) depicts mainly the MMRd patients (with only one POLE case misclassified), and the superclass on the left (purple) shows the p53abn cases with only one POLE case misplaced (Source data are provided as a Source Data file).
We next visualized the identified cell clusters on multiple patches and combined the clusters with similar cell types as assessed by a pathologist. We observed that each of the cell clusters is typically enriched with a specific type of cell, demonstrating the capability of the model in capturing morphological differences between cell types (Supplementary Figs. 6 – 10) . Supplementary Table 13 represents the cell distributions across the epithelial ovarian histotypes after combining the initial cell clusters, while Supplementary Fig. 11 depicts the boxplot of the cell distributions before combination. Notably, we observed that the five identified cell clusters represented variations in tumor cell morphology associated with ovarian cancer histotypes. High-grade serous and clear cell tumors were relatively enriched for tumor cell clusters containing larger cells (tumor clusters 2, 4, and 5) compared to low-grade serous and endometrioid tumors (see Supplementary Figs. 12 and 13) , consistent with the well-known high-grade nuclear histology of high-grade serous and clear cell carcinomas 49 .
Additionally, we utilized a larger cohort of ovarian cancers containing 186 TMA cores to confirm our results in a larger scale. This cohort included two histotypes of epithelial ovarian cancers: high-grade serous and clear cell carcinomas. Following the same approach for patient clustering (as outlined above), we identified two major clusters (Fig. 4 c) that were enriched with either the high-grade serous or clear cell carcinoma cases, suggesting a 92% accuracy in separating the two histotypes (14 of 186 that were mistakenly clustered in the wrong group).
To demonstrate the superiority of Volta for downstream analysis tasks compared to patch-based representation approaches, we employed a recent self-supervised model for patch representations 35 . Hierarchical clustering results assessed through the AMI, ARI, and Purity metrics (Supplementary Fig. 14 and Supplementary Table 14 , Supplementary Note 10) demonstrate the superiority of clustering results of Volta compared to patched-based representation in downstream clustering of ovarian cancer histotypes.
We next demonstrated a potential application of VOLTA for exploratory cancer subtype discovery. More specifically, we scanned 19 whole-section slide images (WSI) corresponding to three molecular subtypes of endometrial cancer (EC): (1) DNA polymerase epsilon (POLE)-mutant cases, (2) cases with mismatch repair deficiency (MMRd), and (3) cases with p53 abnormality (p53abn) as assessed by immunohistochemistry. We next asked whether our proposed model could identify features in the H&E slides that would aid us in identifying the molecular subtypes of EC. After applying Volta and summarizing the features (Supplementary Note 10) , we subjected EC WSI representations to clustering and identified three clusters of patients (Fig. 4 b).
Interestingly, each of the three clusters was enriched with a specific molecular subtype of endometrial carcinoma. Similar to the procedure taken for the ovarian cancer dataset, we also visualized the cell clusters within the representative patches for each of the EC molecular subtypes (Supplementary Figs. 15 – 17) along with the cell cluster distributions (Supplementary Table 15 and Fig. 18) . In line with recent findings, MMR-deficient tumors had the highest proportion of lymphocytes in the endometrial cancer dataset 50 , 51 , 52 .
To further showcase the capability of the model on a larger scale dataset, we collected a cohort of patients with 633 TMA cores corresponding to the p53abn and NSMP (no specific molecular subtype) molecular subtypes of endometrial cancers. By taking the same approach as discussed above, we obtained two main clusters in the data (Fig. 4 d) where each of the clusters was enriched with one of the two molecular subtypes. Furthermore, similar to the ovarian cancer dataset, we utilized the patch-based self-supervised learning baseline 35 to compare with Volta representations. Qualitative and quantitative results (Supplementary Fig. 14 and Supplementary Table 14) confirm the superiority of Volta compared to patch-based representation learning.
In this paper, we proposed a self-supervised framework (VOLTA) for learning cell representations from annotation-free H&E images. Our investigations confirm the superiority of VOLTA over the state-of-the-art models. Specifically, we demonstrated that VOLTA significantly outperformed the state-of-the-art unsupervised morphology- and deep-learning-based cell clustering methods on nine datasets, six cancer types, and datasets compromised of multiple cell types. Utilizing unsupervised learning to generate cell representations introduces unique opportunities for discovery, prediction, and development purposes. For instance, as part of our experiments, we illustrated that VOLTA can be successfully used as a building block for cancer histotype clustering by applying it to two cohorts of ovarian (including 12 and 186 cases) as well as two cohorts of endometrical cancer (including 19 and 633 cases). Our findings are interesting from two aspects: 1) even though our model does not receive any patient labels at training time, it is able to identify clusters of patients that are similar to pathologist diagnosis or molecular subtypes; 2) VOLTA is data efficient to an extent that it worked on two datasets with 10–20 patients samples. This is in contrast to the commonly held notion that having a large dataset is usually a prerequisite for deep learning models. We also demonstrated that these improvements are not exclusive to the unsupervised aspects of the model but can also extend to a supervised setting. By using our pre-trained VOLTA as an initialization weight for a classification model, we achieved a performance equal to that of the state-of-the-art supervised models with as low as 10% of the labeled data, surpassing the state-of-the-art models with the full data. Additionally, we demonstrated that our self-supervised model is robust to undesired staining biases, which facilitates the utilization of a pre-trained model on datasets collected across different centers.
Our investigation has demonstrated the efficiency of VOLTA as a tool for cell discovery within multiple pathology pipelines. Leveraging a self-supervised framework, the model can be seamlessly integrated with a wealth of histopathology archives accessible from various clinical centers to enable the generation of extensive cell-level representation databases. Furthermore, the model has the potential to alleviate the laborious cell type labeling process by annotating cell clusters instead of individual cells and be used in an interactive pathology pipeline. In addition to its utilization in cell type discovery, we have also demonstrated that the model can serve as a foundational element for both histotype and molecular subtype identification. This illustrates the wide-ranging potential of our model for discovery at multiple levels, from morphological features to molecular basis. These findings point to interesting directions for linking histopathology data to more advanced and in-depth areas such as genomic and molecular information.
The spatial distribution of cells within a tumor has been widely acknowledged to have a profound impact on the progression and prognosis of the disease. As demonstrated by 6 , the bivariate analysis of immune and tumor cells can yield a wealth of information about the underlying biology of the disease. By utilizing metrics such as the Morisita-Horn index 53 , Ripley’s K function 54 , and Intra-Tumor Lymphocyte Ratio (ITLR) 55 , researchers have gained meaningful insights into the relationship between the spatial distribution of cells and clinical outcomes, identify immune-cancer hotspots, and predict chemotherapy response 32 , 56 , 57 . Considering the crucial role of cell identification in these applications, our research has the potential to be instrumental in enabling the aforementioned studies to be conducted at more extensive scales. This, in turn, can lead to a more profound understanding of the intricate correlation between disease phenotype and the spatial arrangement of the tumor microenvironment.
The Declaration of Helsinki and the International Ethical Guidelines for Biomedical Research Involving Human Subjects were strictly adhered throughout the course of this study. All study protocols have been approved by the University of British Columbia/BC Cancer Research Ethics Board.
Methodology
Fig. 1 provides an overview of the proposed self-supervised method for cell classification. This framework consists of two main blocks: 1) Cell Block ; 2) Environment Block . The Cell Block learns the cell embeddings (i.e., representations) by contrasting individual cell-level images while the Environment Block incorporates environment-level information into the cell representations.
The architectural design of the Cell Block is similar to our previously proposed model 58 , which has shown promising performance in cell representation learning tasks. In this block, cell embeddings are learned by pulling the embeddings of two augmentations of the same image together, while the embeddings of other images are pushed away. Let X = { x i ∣ 1 ≤ i ≤ N } be the input batch of cell images and N to be the number of images in the batch. Each x i is a small crop of the H&E image around a cell in a way that it only includes that specific cell. Two different sets of augmentations are applied to X to generate Q = { q i ∣ 1 ≤ i ≤ N } and K = { k i ∣ 1 ≤ i ≤ N }. We call these sets query and key, respectively. q i and k j are the augmentations of the same image if and only if i = j . The query batch is encoded using a backbone model, a neural network of choice, while the keys are encoded using a momentum encoder, which has the same architecture as the backbone. This momentum encoder is updated using ( 1 ) in which \({{{{{{{{\boldsymbol{\theta }}}}}}}}}_{k}^{t}\) is the parameter of momentum encoder at time t , m is the momentum factor, and \({{{{{{{{\boldsymbol{\theta }}}}}}}}}_{q}^{t}\) is the parameter of the backbone at time t
Consequently, the obtained query and key representations are passed through separate Multi-Layer Perceptron (MLP) layers called projector heads. Although the query projector head is trainable, the key projector head is updated with momentum using the weight of the query projector head. We restrict these layers to be 2-layer MLPs with an input size of 512, a hidden size of 128, and an output size of 64. In addition to the projector head, we use an extra MLP on the query side of the framework, called the prediction head. This network is a 2-layer MLP with input, hidden, and output sizes of 64, 32, and 64, respectively. Similar to the last fully-connected layers of a conventional classification network, the projection and prediction heads provide more representation power to the model.
The networks of the Cell Block are trained using the InfoNCE 39 loss which is shown in ( 2 )
In this equation, τ is the temperature that controls the sharpness of the distribution, ∥ ∥ is the normalization operator, Q is the number of items stored in the queue from the key branch, f q is the equal function for the combination of the backbone, query projection head, and query prediction head, and f k shows the equal function for the momentum encoder and the key projection head.
The augmentation pipelines include cropping, color jitter (brightness of 0.4, contrast of 0.4, saturation of 0.4, and hue of 0.1), gray-scale conversion, Gaussian blur (with a random sigma between 0.1 and 2.0), horizontal and vertical flip, and rotation (randomly selected between 0 to 180 degrees). To ensure the model consistently observes the entire cell image on one side, we eliminate the cropping step from one of the processes. Consequently, the pipeline that includes cropping generates localized sections of the cell image, while the other augmentation pipeline produces global images encompassing the complete view of the entire cell. Due to the randomness of augmentations, either one can be passed through the backbone or momentum-encoder.
Cell embeddings are generated from the trained momentum encoder at the inference time and are clustered by applying the K-means algorithm. One can use either the encoder or momentum encoder for embedding generation; however, the momentum encoder provides more robust representations since it aggregates the learned weights of the encoder network from all of the training steps (an ensembling version of the encoder throughout training) 33 .
Environment block
Many studies have shown that the Tumor Micro Environment (TME) plays an important role in the tumor progression behavior 32 , 57 . Motivated by these findings, we ask: should the representation of a cell reflect its environment as well? Inspired by this question, we hypothesize that a deeper knowledge of the environment leads to a better general understanding of the cell. In a mathematical formulation, this hypothesis is equivalent to the assumption that there exists mutual information between cells and their environment. Therefore, to validate this hypothesis, we propose to increase the mutual information between the corresponding cell and environment representations during the training process. Previous studies 59 have shown that the InfoNCE loss maximizes the lower bound of mutual information between different views of the image. Thus, we will use this loss function to achieve the aforementioned target by performing cross-modal contrastive learning as an auxiliary task.
Let E = { e i ∣ 1 ≤ i ≤ N } be the corresponding environment patches of the cells represented by X . Here, we refer to the environment as a large region around a cell in a way that includes the surrounding tissue and cells. Therefore, for ∀ i ∈ 1, 2, . . . , N , x i and e i are centered on the same cell (however, for the cases where the cells are located on the edge of the patch, we limit the patch border to the border of the image). After applying an augmentation pipeline, the environment patches are passed through an encoder network, called an environment encoder. Simultaneously, we apply a new projection head, the environment projection head, to the cell representations obtained from the query backbone in the Cell Block . Finally, one can train the Environment Block using these two sets of representations (environment and cell) and ( 3 )
Therefore, the final loss of the whole framework can be written as ( 4 ), in which λ is a hyperparameter. Increasing the value of λ prioritizes the mutual information of the cell with its environment over the consistency of the representation for different augmentations of the same cell
The augmentation pipeline of the Environment Block uses the same operations as that of the Cell Block except for cropping.
To prevent the model from focusing on the overlapping regions between the corresponding cell and environment images (called shortcut 60 , meaning that the model uses undesired features to solve the problem), we mask the target cell in the environment patch. Furthermore, the rest of the cells in the environment patch are also masked to ensure that the model does not bias the representation of a cell towards the neighboring cell types. We will investigate the effectiveness of the masking operation in the ablation study.
Data preparation
The aforementioned datasets included patch-level images, while we required cell-level ones for the training of the model. To generate such data, we used the instance segmentation provided in each of the external datasets to find cells and crop a small box around them. However, for the Oracle and SarcCell datasets, the instance segmentation masks were generated by applying HoVer-Net 21 segmentation pre-trained on the PanNuke dataset.
An adaptive window size was used to extract cell images from the H&E slides. More specifically, this window is selected based on the size of the cell, and this strategy is utilized to prevent overlapping with other cells. The adaptive window size was set to twice the size of the cell for the CoNSeP dataset while it was equal to the size of the cell for the rest of the datasets. Finally, cell images were resized to 32 × 32 pixels (to enable batch-wise processing operations) and were normalized to zero mean and unit standard deviation before being fed into our proposed framework. The environment patch used in the Environment Block was set to 200 pixels for all datasets.
Ground-truth label generation of the Oracle and SarcCell dataset cells was performed by finding the most expressed biomarker (by intensity and quantity) in the same position of the corresponding IHC image. To accommodate for the potential noise associated with image registration, two post-processing steps were performed: 1) the size of the window in the IHC image was set to 5 times of the window size in the H&E core (however, this scale was set to 1 for the SarcCell dataset due to more accurate co-registration performance); 2) the most expressed biomarker was considered as the label only if it contained at least 70% of the biomarker distribution in the IHC window.
Implementation details
The code was implemented in Pytorch (v1.9.0), and the model was run on one and two V100 GPUs for the w/ and w/o environment settings, respectively. The batch size was set to 1024 (unless specified otherwise), the queue size to 65,536, and pre-activated ResNet18 61 was used for the backbone and momentum encoder in the Cell Block . The environment encoder architecture was set to LambdaNet model 62 as it extracts more informative patch representations using self-attention while keeping the computation and memory usage tractable. The stack was trained using the Adam optimizer for 500 epochs (unless specified otherwise) with a starting learning rate of 0.001, a cosine learning rate scheduler, and a weight decay of 0.0001. We also adopted a 10-epoch warm-up step. The momentum factor in the momentum encoders was 0.999, and the temperature was set to 0.07.
In Table 1 experiments, the training epoch count and batch size of our models were set to 200 and 512 for the PanNuke Breast, Lizard, Oracle, and SarcCell datasets. Additionally, for the training of our model on the Oracle datasets, we used 15,000 randomly selected cells from the training set, to reduce the training time.
In the self-supervised to supervised transfer learning step (cell classification), we adopted SGD (Stochastic Gradient Descent) with a starting learning rate of 0.001 using a cosine learning rate scheduler for 300 epochs with a batch size of 1024. Also, the weight decay was set to 0.00001. In the case that we allowed the encoder to be fine-tuned, we set the encoder’s learning rate to 0.0001.
It is worth mentioning that for the cell classification of NuCLS, we followed the same super-class grouping of the original paper 22 . In this regard, we only used 3 super-classes out of 5 for cell type classification, including tumor, stromal, and sTILs.
The performance was also compared against five baselines. The pre-trained ImageNet model used weights that were pre-trained on the ImageNet dataset to generate the cell embeddings. The Morphological Features approach 63 adopted morphological features to produce a 30-dimensional feature vector, consisting of geometrical and shape attributes. Prior to clustering, the feature vectors were normalized to zero mean and unit standard deviation, and their size was reduced to 2 using t-SNE. The third baseline was Manual Feature 27 which used a combination of Scale-Invariant Feature Transform (SIFT) and Local Binary Patterns (LBP) features to provide representations for the cells. Similar to the previous baseline, we exercised standardization on the computed feature vectors. Additionally, our baseline set included two state-of-the-art unsupervised deep learning models. More specifically, the Auto-Encoder baseline adopted a deep convolution auto-encoder alongside a clustering layer to learn cell embeddings by performing an image reconstruction task 29 . And finally, the last baseline was GAN 27 which adopted the idea of InfoGAN 28 and developed a Generative Adversarial Network (GAN) for cell clustering by increasing the mutual information between the cell representation and a categorical noise vector.
Statistics & reproducibility
The data selection and stratification were performed completely blind without any previous exposure to the patient or cell data. For public datasets, we used the train and test sets provided by the original publication; however, for the rest of the process, we took a completely blind approach.
The sample sizes used in this study are based on the sample provided sets from the original publication for the public datasets and the most available data for the private datasets. In both cases, we believe these sample sizes are sufficient for the study as at least 17,000 samples are available for each dataset.
Due to the stochastic nature of deep learning models, the exact reproduction of an experiment is not possible. However, we conducted each experiment multiple times and used the average of the results as the output.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The publicly available data used in this study (CoNSeP, NuCLS, PanNuke, MiDOG, and Lizard datasets) are available in the original publications and their corresponding authors ( https://arxiv.org/pdf/2204.03742 , https://arxiv.org/pdf/1812.06499.pdf , https://arxiv.org/abs/2102.09099 , https://arxiv.org/abs/2003.10778 , https://arxiv.org/abs/2108.11195 ). The internal histopathology slides generated in this study (SarcCell, Oracle, and MastCell datasets) can be obtained by direct email to the corresponding author. All data accesses are subject to institutional permission and compliance with ethics from the corresponding institutions. Data can only be shared for non-commercial academic purposes and will require a data user agreement. The requested data will be provided as soon as all the corresponding institutions grant the required permissions. The rest of the data used for visualization purposes are included in the supplementary information. Source data are provided with this paper.
Code availability
The code for this manuscript will be publicly available in https://github.com/AIMLab-UBC/VOLTA .
Farc, O. & Cristea, V. An overview of the tumor microenvironment, from cells to complex networks. Exp. Therapeutic Med. 21 , 1–1 (2021).
Google Scholar
Yang, Y., Yang, Y., Yang, J., Zhao, X. & Wei, X. Tumor microenvironment in ovarian cancer: function and therapeutic strategy. Front. Cell Dev. Biol. 8 , 758 (2020).
Article ADS PubMed PubMed Central Google Scholar
Liu, W. et al. Transcriptome-derived stromal and immune scores infer clinical outcomes of patients with cancer. Oncol. Lett. 15 , 4351–4357 (2018).
PubMed PubMed Central Google Scholar
Bremnes, R. M. et al. The role of tumor-infiltrating lymphocytes in development, progression, and prognosis of non–small cell lung cancer. J. Thorac. Oncol. 11 , 789–800 (2016).
Article PubMed Google Scholar
Schalper, K. A. et al. Objective measurement and clinical significance of tils in non–small cell lung cancer. J. Natl Cancer Inst. 107 , dju435 (2015).
Article PubMed PubMed Central Google Scholar
Pogrebniak, K. L. & Curtis, C. Harnessing tumor evolution to circumvent resistance. Trends Genet. 34 , 639–651 (2018).
Article CAS PubMed PubMed Central Google Scholar
Zhang, A., Miao, K., Sun, H. & Deng, C.-X. Tumor heterogeneity reshapes the tumor microenvironment to influence drug resistance. Int. J. Biol. Sci. 18 , 3019 (2022).
Zhang, J. et al. Intratumor heterogeneity in localized lung adenocarcinomas delineated by multiregion sequencing. Science 346 , 256–259 (2014).
Article ADS CAS PubMed PubMed Central Google Scholar
Schwarz, R. F. et al. Spatial and temporal heterogeneity in high-grade serous ovarian cancer: a phylogenetic analysis. PLoS Med. 12 , e1001789 (2015).
Andor, N. et al. Pan-cancer analysis of the extent and consequences of intratumor heterogeneity. Nat. Med. 22 , 105–113 (2016).
Article CAS PubMed Google Scholar
Steinhart, B. et al. The spatial context of tumor-infiltrating immune cells associates with improved ovarian cancer survivalspatial interactions in the tumor immune microenvironment. Mol. Cancer Res. 19 , 1973–1979 (2021).
Fu, T. et al. Spatial architecture of the immune microenvironment orchestrates tumor immunity and therapeutic response. J. Hematol. Oncol. 14 , 98 (2021).
Brambilla, E. et al. Prognostic effect of tumor lymphocytic infiltration in resectable non–small-cell lung cancer. J. Clin. Oncol. 34 , 1223 (2016).
Corredor, G. et al. Spatial architecture and arrangement of tumor-infiltrating lymphocytes for predicting likelihood of recurrence in early-stage non–small cell lung cancer. Clin. Cancer Res. 25 , 1526–1534 (2019).
Javed, S. et al. Cellular community detection for tissue phenotyping in colorectal cancer histology images. Med. Image Anal. 63 , 101696 (2020).
Zhou, Y. et al. Cgc-net: Cell graph convolutional network for grading of colorectal cancer histology images. IEEE/CVF International Conference on Computer Vision workshop 0–0 (IEEE, 2019).
Martin-Gonzalez, P., Crispin-Ortuzar, M. & Markowetz, F. Predictive modelling of highly multiplexed tumour tissue images by graph neural networks. In: Interpretability of Machine Intelligence in Medical Image Computing, and Topological Data Analysis and Its Applications for Medical Data. (eds. Reyes, M. et al.) vol 12929, 98–107 (Springer, Cham, 2021). https://doi.org/10.1007/978-3-030-87444-5_10 .
Lu, W., Graham, S., Bilal, M., Rajpoot, N. & Minhas, F. Capturing cellular topology in multi-gigapixel pathology images. In IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops 260–261 (IEEE, 2020).
Elmore, J. G. et al. Diagnostic concordance among pathologists interpreting breast biopsy specimens. JAMA 313 , 1122–1132 (2015).
Sirinukunwattana, K. et al. Locality sensitive deep learning for detection and classification of nuclei in routine colon cancer histology images. IEEE Trans. Med. Imaging 35 , 1196–1206 (2016).
Graham, S. et al. Hover-net: Simultaneous segmentation and classification of nuclei in multi-tissue histology images. Med. Image Anal. 58 , 101563 (2019).
Amgad, M.et al. Nucls: A scalable crowdsourcing, deep learning approach and dataset for nucleus classification, localization and segmentation. Gigascience 11 , giac037 (2022).
Dalle, J.-R. et al. Nuclear pleomorphism scoring by selective cell nuclei detection. IEEE/CVF Winter Conference of Computer Vision (IEEE, 2009).
Nguyen, K., Jain, A. K. & Sabata, B. Prostate cancer detection: Fusion of cytological and textural features. J. Pathol. Informatics 2 , S3 (2011).
Cruz-Roa, A. A., Ovalle, J. E. A., Madabhushi, A. & Osorio, F. A. G. A deep learning architecture for image representation, visual interpretability and automated basal-cell carcinoma cancer detection. Med. Image Comput. Comput. Assist. Interv. 16 , 403–410 (2013).
Han, W. et al. Identification of molecular cell type of breast cancer on digital histopathology images using deep learning and multiplexed fluorescence imaging. Digital Comput. Pathol. 12471 , 26–31 (2023).
Hu, B. et al. Unsupervised learning for cell-level visual representation in histopathology images with generative adversarial networks. IEEE J. Biomed. Health Inform. 23 , 1316–1328 (2018).
Chen, X. et al. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the 30th International Conference on Neural Information Processing Systems 2180–2188 (NIPS, 2016).
Vununu, C., Lee, S.-H. & Kwon, K.-R. A strictly unsupervised deep learning method for hep-2 cell image classification. Sensors 20 , 2717 (2020).
Keren, L. et al. A structured tumor-immune microenvironment in triple negative breast cancer revealed by multiplexed ion beam imaging. Cell 174 , 1373–1387 (2018).
Schürch, C. M. et al. Coordinated cellular neighborhoods orchestrate antitumoral immunity at the colorectal cancer invasive front. Cell 182 , 1341–1359 (2020).
Yuan, Y. Spatial heterogeneity in the tumor microenvironment. Cold Spring Harb. Perspect. Med. 6 , a026583 (2016).
Caron, M. et al. Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. 9650–9660 (2021).
Sohn, K. et al. A simple semi-supervised learning framework for object detection. Preprint at https://arxiv.org/abs/2005.04757 (2020).
Ciga, O., Xu, T. & Martel, A. L. Self supervised contrastive learning for digital histopathology. Mach. Learn. Appl. 7 , 100198 (2022).
Zhang, L., Amgad, M. & Cooper, L. A. A histopathology study comparing contrastive semi-supervised and fully supervised learning. Preprint at https://arxiv.org/abs/2111.05882 (2021).
Chen, X., Fan, H., Girshick, R. & He, K. Improved baselines with momentum contrastive learning. Preprint at https://arxiv.org/abs/2003.04297 (2020).
LeCun, Y., Chopra, S., Hadsell, R., Ranzato, M. & Huang, F. A tutorial on energy-based learning. Predicting structured data 1 (2006).
Oord, A. v. d., Li, Y. & Vinyals, O. Representation learning with contrastive predictive coding. Preprint at https://arxiv.org/abs/1807.03748 (2018).
Gamper, J. et al. Pannuke dataset extension, insights and baselines. Preprint at https://arxiv.org/abs/2003.10778 (2020).
Graham, S. et al. Lizard: A large-scale dataset for colonic nuclear instance segmentation and classification. In Proceedings of the IEEE/CVF International Conference on Computer Vision 684–693 (IEEE, 2021).
Aubreville, M. et al. Mitosis domain generalization in histopathology images-the midog challenge. Med. Image Anal. 84 , 102699 (2023).
Vinh, N. X., Epps, J. & Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 11 , 2837–2854 (2010).
MathSciNet Google Scholar
Hubert, L. & Arabie, P. Comparing partitions. J. Classification 2 , 193–218 (1985).
Article Google Scholar
Rand, W. M. Objective criteria for the evaluation of clustering methods. J. Am. Stat. Assoc. 66 , 846–850 (1971).
Boschman, J. et al. The utility of color normalization for ai-based diagnosis of hematoxylin and eosin-stained pathology images. J. Pathol. 256 , 15–24 (2022).
Vahadane, A. et al. Structure-preserving color normalization and sparse stain separation for histological images. IEEE Trans. Med. imaging 35 , 1962–1971 (2016).
Farahani, H. et al. Deep learning-based histotype diagnosis of ovarian carcinoma whole-slide pathology images. Mod. Pathol. 35 , 1983–1990 (2022).
Moch, H. Female genital tumours: Who classification of tumours , vol. 4 (WHO, 2020).
Pasanen, A., Loukovaara, M. & Bützow, R. Clinicopathological significance of deficient dna mismatch repair and mlh1 promoter methylation in endometrioid endometrial carcinoma. Mod. Pathol. 33 , 1443–1452 (2020).
Ramchander, N. C. et al. Distinct immunological landscapes characterize inherited and sporadic mismatch repair deficient endometrial cancer. Front. Immunol. 10 , 3023 (2020).
Dong, D. et al. Pole and mismatch repair status, checkpoint proteins and tumor-infiltrating lymphocytes in combination, and tumor differentiation: identify endometrial cancers for immunotherapy. Front. Oncol. 11 , 640018 (2021).
Scalon, J. D., Avelar, M. B. L., Alves, Gd. F. & Zacarias, M. S. Spatial and temporal dynamics of coffee-leaf-miner and predatory wasps in organic coffee field in formation. Ciência Rural 41 , 646–652 (2011).
Ripley, B. D. The second-order analysis of stationary point processes. J. Appl. Probab. 13 , 255–266 (1976).
Article MathSciNet Google Scholar
Yuan, Y. Modelling the spatial heterogeneity and molecular correlates of lymphocytic infiltration in triple-negative breast cancer. J. R. Soc. Interface 12 , 20141153 (2015).
Denkert, C. et al. Tumor-associated lymphocytes as an independent predictor of response to neoadjuvant chemotherapy in breast cancer. J. Clin. Oncol. 28 , 105–113 (2010).
Blise, K. E., Sivagnanam, S., Banik, G. L., Coussens, L. M. & Goecks, J. Single-cell spatial architectures associated with clinical outcome in head and neck squamous cell carcinoma. NPJ Precis. Oncol. 6 , 1–14 (2022).
Nakhli, R., Darbandsari, A., Farahani, H. & Bashashati, A. Ccrl: Contrastive cell representation learning. European conference on computer vision. 397–407 (Springer, 2022).
Wu, M., Zhuang, C., Mosse, M., Yamins, D. & Goodman, N. On mutual information in contrastive learning for visual representations. Preprint at https://arxiv.org/abs/2005.13149 (2020).
Minderer, M., Bachem, O., Houlsby, N. & Tschannen, M. Automatic shortcut removal for self-supervised representation learning. In International Conference on Machine Learning 6927–6937 (ACM, 2020).
He, K., Zhang, X., Ren, S. & Sun, J. Identity mappings in deep residual networks. In Computer Vision–ECCV 2016: 14th European Conference. (eds. Leibe, B., Matas, J., Sebe, N. & Welling, M.) vol. 9908, 630–645 (Springer, Amsterdam, The Netherlands, 2016).
Bello, I. Lambdanetworks: Modeling long-range interactions without attention. Preprint at https://arxiv.org/abs/2102.08602 (2021).
Van der Maaten, L. & Hinton, G. Visualizing data using t-sne. J. Mach. Learn. Res. 9 , 2579−2605 (2008).
Download references
Acknowledgements
This work was supported by Terry Fox Research Institute (J.N.M., A.B., grant number: 1116), Canadian Institute of Health Research (A.B., grant number: 201903PJT-418734), Natural Sciences and Engineering Research Council of Canada (A.B., grant number: RGPIN-2019-04896), Michael Smith Foundation for Health Research (A.B., grant number: SCH-2021-1546), Canada Research Chair (J.N.M., S.J.M.J.), Canada Foundation for Innovation/BC Knowledge Development Funds (AB, grant number: 41144), OVCARE Carraresi, and VGH UBC Hospital Foundation (A.B.). The funders had no involvement in study conception, data collection, data analysis, data interpretation, writing of the report, or publication decision.
Author information
These authors contributed equally: Ramin Nakhli, Katherine Rich.
These authors jointly supervised this work: Hossein Farahani, Ali Bashashati.
Authors and Affiliations
School of Biomedical Engineering, University of British Columbia, Vancouver, BC, Canada
Ramin Nakhli, Amir Hadjifaradji, Hossein Farahani & Ali Bashashati
Bioinformatics Graduate Program, University of British Columbia, Vancouver, Canada
Katherine Rich
Department of Pathology and Laboratory Medicine, University of British Columbia, Vancouver, BC, Canada
Allen Zhang, Elahe Shenasa, C. Blake Gilks & Ali Bashashati
Department of Electrical and Computer Engineering, University of British Columbia, Vancouver, BC, Canada
Amirali Darbandsari
Deeley Research Centre, BC Cancer Agency, Victoria, BC, Canada
Sidney Thiessen, Katy Milne & Brad H. Nelson
Canada’s Michael Smith Genome Sciences Centre, BC Cancer Research Institute, Vancouver, Canada
Steven J. M. Jones & Ali Bashashati
Department of Medical Genetics, University of British Columbia, Vancouver, Canada
Steven J. M. Jones
Department of Obstetrics and Gynecology, University of British Columbia, Vancouver, BC, Canada
Jessica N. McAlpine
You can also search for this author in PubMed Google Scholar
Contributions
R.N. designed and benchmarked the models. A.D. initiated the study. R.N. and A.D. implemented the baseline models. R.N. and K.R. collected and pre-processed the data. R.N., A.B., and H.F. wrote the first draft of the manuscript. R.N., K.R., H.F., and A.B. revised the manuscript. A.Z. contributed to the pathology review of the model’s results in terms of biological relevance. A.H. contributed to data analysis. J.N.M., S.J.M.J., C.B.G., B.H.N., S.T., K.M., E.S. contributed to cohort construction, tumor banking, experiments, pathology review, and computational infrastructure. A.B. and H.F. designed the experiments and supervised the study. A.B. conceived and oversaw the project and is the senior corresponding author. All authors have reviewed and approved the manuscript content.
Corresponding author
Correspondence to Ali Bashashati .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Peer review
Peer review information.
Nature Communications thanks Hamid Tizhoosh, and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Supplementary information, peer review file, reporting summary, source data, source data, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Nakhli, R., Rich, K., Zhang, A. et al. VOLTA: an enVironment-aware cOntrastive ceLl represenTation leArning for histopathology. Nat Commun 15 , 3942 (2024). https://doi.org/10.1038/s41467-024-48062-1
Download citation
Received : 29 March 2023
Accepted : 19 April 2024
Published : 10 May 2024
DOI : https://doi.org/10.1038/s41467-024-48062-1
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: Cancer newsletter — what matters in cancer research, free to your inbox weekly.

IMAGES
VIDEO
COMMENTS
An electrochemical cell can be represented in a shorthand way by a cell diagram (sometimes called cell representations or cell notations) The conventional representation of voltaic cells. By convention, the half cell with the greatest negative potential is written on the left of the salt bridge, so E θ cell = E θ right - E θ left. In this ...
Study with Quizlet and memorize flashcards containing terms like What does ROOR mean?, What do the 2 lines in the middle represent?, What do you use to separate ions with the same state symbol? and more.
This is shown for the Zn-Cu cell in Figure 1 from the Galvanic Cells section. You can readily confirm that the spontaneous cell reaction (Eq. (1) from Galvanic Cells) corresponds to the shorthand cell notation of Equation \(\ref{1}\). For the cell shown in Figure 1 in Galvanic Cells, the shorthand notation is
Conventional Representation of Cells. Chemists use a type of shorthand convention to represent electrochemical cells; In this convention: A solid vertical (or slanted) line shows a phase boundary, that is an interface between a solid and a solution; A double vertical line (sometimes shown as dashed vertical lines) represents a salt bridge. A salt bridge has mobile ions that complete the circuit
Study with Quizlet and memorize flashcards containing terms like rules for writing simple representation of a cell- where are the electrodes placed?, Simple cell representation lines, simple representation of a cell - where is platinum placed and more. ... Conventional cell representation (cell notation) Flashcards; Learn; Test; Match; Q-Chat ...
Two metal electrodes. 2. Salt bridge. 3. External wire connecting the two electrodes. 4. Two beakers containing aqueous solutions of the salts of the respective metal electrodes. What does the double line show in the conventional representation of a cell? Salt bridge.
An electrochemical cell can be represented in a shorthand way by a cell diagram (sometimes called cell representations or cell notations) The conventional representation of voltaic cells. By convention, the half cell with the greatest negative potential is written on the left of the salt bridge, so E ꝋ cell = E ꝋ right - E ꝋ left. In ...
3.1.11.1 - Electrode Potentials and Cells. Electrochemical cells use redox reactions as the electron transfer between products creates a flow of electrons. This flow of charged particles is an electrical current which flows between electrodes in the cell. A potential difference is produced between the two electrodes which can be measured.
IUPAC convention for writing half-equations for electrode reactions. The conventional representation of cells. ... write and apply the conventional representation of a cell. AT j and k. PS 1.1. Students could make simple cells and use them to measure unknown electrode potentials. AT a, b, j and k. PS 2.1 and 2.4 ...
The conventional representation of cells. Cells are used to measure electrode potentials by reference to the standard hydrogen electrode. Students should be able to: use EƟ values to predict the direction of simple redox reactions. Calculate the EMF of a cell. Write and apply the conventional representation of a cell. Edexcel Chemistry. Topic ...
IUPAC convention for writing half-equations for electrode reactions. The conventional representation of cells. ... write and apply the conventional representation of a cell. AT j and k. PS 1.1. Students could make simple cells and use them to measure unknown electrode potentials. AT a, b, j and k. PS 2.1 and 2.4 ...
This is shown for the Zn-Cu cell in Figure 1 from the Galvanic Cells section. You can readily confirm that the spontaneous cell reaction (Eq. (1) from Galvanic Cells) corresponds to the shorthand cell notation of Eq. 1.8.1. For the cell shown in Figure 1 in Galvanic Cells, the shorthand notation is. Pt, Cl 2(g) ∣ Cl- (1M) ∥ Fe2 + (1M ...
Conventional Cell Representation Cells are represented in a simplified way so that they don't have to be drawn out each time. This representation has specific rules to help show the reactions that occur: The half-cell with the most negative potential goes on the left . The most oxidised species from each half-cell goes next to the salt bridge
Conventional Representation of Cells [edit | edit source] As it is cumbersome and time-consuming to draw out every electrochemical cell in full, a system of notation is used which describes the cell in full, but does not require it to be drawn. ... This is in accordance with the IUPAC convention for writing half-equations for electrode reactions.
IUPAC convention for writing half-equations for electrode reactions. The conventional representation of cells. Cells are used to measure electrode potentials by reference to the standard hydrogen electrode. The importance of the conditions when measuring the electrode potential, E (Nernst equation not required).
The following conventions are used to represent the cell: Double vertical solid line = salt bridge; Vertical solid line = phase boundary, e.g, between an aqueous solution (aq) and a solid (s).; Species with the highest oxidation state = written closest to the salt bridge (the double vertical line).; The half cell with the more negative potential = goes on the left
An electrochemical cell can be represented in a shorthand way by a cell diagram (sometimes called cell representations or cell notations) The conventional representation of voltaic cells. By convention, the half cell with the greatest negative potential is written on the left of the salt bridge, so E θ cell = E θ right - E θ left. In this ...
Page ID. For each lattice, the conventional cell is the cell obeying the following conditions: its basis vectors define a right-handed axial setting; its edges are along symmetry directions of the lattice; it is the smallest cell compatible with the above condition. Crystals having the same type of conventional cell belong to the same crystal ...
Study with Quizlet and memorize flashcards containing terms like What 4 things do all electrochemical cells contain?, What does the double line show in the conventional representation of a cell?, What do the single lines show in the conventional representation of a cell? and more.
TASK 1 - Oxidation states 1) Calculate the oxidation state of the stated element in the following species: a) Fe in Fe 0 FeCl 3 +3 FeCl 2 +2 K 2FeO 4 +6 [Fe(H 2O) 6] 2+ +2 b) Cl in Cl 2 0 ClO 3-+5 ClO- +1 Cl 2O 7 +7 NaCl -1 2) Calculate the oxidation state of each element in the following: SO
Age range: 16+. Resource type: Worksheet/Activity. File previews. pdf, 69.91 KB. pdf, 75.07 KB. pdf, 111.48 KB. This set contains two worksheets aimed at A-level Chemistry students. The first worksheet asks students to write conventional representation for electrochemical cells and the second asks them to write half equations when given the ...
We continue to explore the learned embeddings on cell segmentations of Phalloidin-labelled cells 7 and discover that thin, F-actin-positive filopodia-like structures are reduced in lamin-A ...
In clinical oncology, many diagnostic tasks rely on the identification of cells in histopathology images. While supervised machine learning techniques necessitate the need for labels, providing ...