
Statistics Made Easy

How to Write Hypothesis Test Conclusions (With Examples)
A hypothesis test is used to test whether or not some hypothesis about a population parameter is true.
To perform a hypothesis test in the real world, researchers obtain a random sample from the population and perform a hypothesis test on the sample data, using a null and alternative hypothesis:
- Null Hypothesis (H 0 ): The sample data occurs purely from chance.
- Alternative Hypothesis (H A ): The sample data is influenced by some non-random cause.
If the p-value of the hypothesis test is less than some significance level (e.g. α = .05), then we reject the null hypothesis .
Otherwise, if the p-value is not less than some significance level then we fail to reject the null hypothesis .
When writing the conclusion of a hypothesis test, we typically include:
- Whether we reject or fail to reject the null hypothesis.
- The significance level.
- A short explanation in the context of the hypothesis test.
For example, we would write:
We reject the null hypothesis at the 5% significance level. There is sufficient evidence to support the claim that…
Or, we would write:
We fail to reject the null hypothesis at the 5% significance level. There is not sufficient evidence to support the claim that…
The following examples show how to write a hypothesis test conclusion in both scenarios.
Example 1: Reject the Null Hypothesis Conclusion
Suppose a biologist believes that a certain fertilizer will cause plants to grow more during a one-month period than they normally do, which is currently 20 inches. To test this, she applies the fertilizer to each of the plants in her laboratory for one month.
She then performs a hypothesis test at a 5% significance level using the following hypotheses:
- H 0 : μ = 20 inches (the fertilizer will have no effect on the mean plant growth)
- H A : μ > 20 inches (the fertilizer will cause mean plant growth to increase)
Suppose the p-value of the test turns out to be 0.002.
Here is how she would report the results of the hypothesis test:
We reject the null hypothesis at the 5% significance level. There is sufficient evidence to support the claim that this particular fertilizer causes plants to grow more during a one-month period than they normally do.
Example 2: Fail to Reject the Null Hypothesis Conclusion
Suppose the manager of a manufacturing plant wants to test whether or not some new method changes the number of defective widgets produced per month, which is currently 250. To test this, he measures the mean number of defective widgets produced before and after using the new method for one month.
He performs a hypothesis test at a 10% significance level using the following hypotheses:
- H 0 : μ after = μ before (the mean number of defective widgets is the same before and after using the new method)
- H A : μ after ≠ μ before (the mean number of defective widgets produced is different before and after using the new method)
Suppose the p-value of the test turns out to be 0.27.
Here is how he would report the results of the hypothesis test:
We fail to reject the null hypothesis at the 10% significance level. There is not sufficient evidence to support the claim that the new method leads to a change in the number of defective widgets produced per month.
Additional Resources
The following tutorials provide additional information about hypothesis testing:
Introduction to Hypothesis Testing 4 Examples of Hypothesis Testing in Real Life How to Write a Null Hypothesis
Featured Posts
Hey there. My name is Zach Bobbitt. I have a Masters of Science degree in Applied Statistics and I’ve worked on machine learning algorithms for professional businesses in both healthcare and retail. I’m passionate about statistics, machine learning, and data visualization and I created Statology to be a resource for both students and teachers alike. My goal with this site is to help you learn statistics through using simple terms, plenty of real-world examples, and helpful illustrations.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Join the Statology Community
Sign up to receive Statology's exclusive study resource: 100 practice problems with step-by-step solutions. Plus, get our latest insights, tutorials, and data analysis tips straight to your inbox!
By subscribing you accept Statology's Privacy Policy.

Scientific Method: Step 6: CONCLUSION
- Step 1: QUESTION
- Step 2: RESEARCH
- Step 3: HYPOTHESIS
- Step 4: EXPERIMENT
- Step 5: DATA
- Step 6: CONCLUSION
Step 6: Conclusion
Finally, you've reached your conclusion. Now it is time to summarize and explain what happened in your experiment. Your conclusion should answer the question posed in step one. Your conclusion should be based solely on your results.
Think about the following questions:
- Was your hypothesis correct?
- If your hypothesis wasn't correct, what can you conclude from that?
- Do you need to run your experiment again changing a variable?
- Is your data clearly defined so everyone can understand the results and follow your reasoning?
Remember, even a failed experiment can yield a valuable lesson.
Draw your conclusion
- Conclusion Sections in Scientific Research Reports (The Writing Center at George Mason)
- Sample Conclusions (Science Buddies)
- << Previous: Step 5: DATA
- Next: Resources >>
- Last Updated: May 9, 2024 10:59 AM
- URL: https://harford.libguides.com/scientific_method
2.7 Drawing Conclusions and Reporting the Results
Learning objectives.
- Identify the conclusions researchers can make based on the outcome of their studies.
- Describe why scientists avoid the term “scientific proof.”
- Explain the different ways that scientists share their findings.
Drawing Conclusions
Since statistics are probabilistic in nature and findings can reflect type I or type II errors, we cannot use the results of a single study to conclude with certainty that a theory is true. Rather theories are supported, refuted, or modified based on the results of research.
If the results are statistically significant and consistent with the hypothesis and the theory that was used to generate the hypothesis, then researchers can conclude that the theory is supported. Not only did the theory make an accurate prediction, but there is now a new phenomenon that the theory accounts for. If a hypothesis is disconfirmed in a systematic empirical study, then the theory has been weakened. It made an inaccurate prediction, and there is now a new phenomenon that it does not account for.
Although this seems straightforward, there are some complications. First, confirming a hypothesis can strengthen a theory but it can never prove a theory. In fact, scientists tend to avoid the word “prove” when talking and writing about theories. One reason for this avoidance is that the result may reflect a type I error. Another reason for this avoidance is that there may be other plausible theories that imply the same hypothesis, which means that confirming the hypothesis strengthens all those theories equally. A third reason is that it is always possible that another test of the hypothesis or a test of a new hypothesis derived from the theory will be disconfirmed. This difficulty is a version of the famous philosophical “problem of induction.” One cannot definitively prove a general principle (e.g., “All swans are white.”) just by observing confirming cases (e.g., white swans)—no matter how many. It is always possible that a disconfirming case (e.g., a black swan) will eventually come along. For these reasons, scientists tend to think of theories—even highly successful ones—as subject to revision based on new and unexpected observations.
A second complication has to do with what it means when a hypothesis is disconfirmed. According to the strictest version of the hypothetico-deductive method, disconfirming a hypothesis disproves the theory it was derived from. In formal logic, the premises “if A then B ” and “not B ” necessarily lead to the conclusion “not A .” If A is the theory and B is the hypothesis (“if A then B ”), then disconfirming the hypothesis (“not B ”) must mean that the theory is incorrect (“not A ”). In practice, however, scientists do not give up on their theories so easily. One reason is that one disconfirmed hypothesis could be a missed opportunity (the result of a type II error) or it could be the result of a faulty research design. Perhaps the researcher did not successfully manipulate the independent variable or measure the dependent variable.
A disconfirmed hypothesis could also mean that some unstated but relatively minor assumption of the theory was not met. For example, if Zajonc had failed to find social facilitation in cockroaches, he could have concluded that drive theory is still correct but it applies only to animals with sufficiently complex nervous systems. That is, the evidence from a study can be used to modify a theory. This practice does not mean that researchers are free to ignore disconfirmations of their theories. If they cannot improve their research designs or modify their theories to account for repeated disconfirmations, then they eventually must abandon their theories and replace them with ones that are more successful.
The bottom line here is that because statistics are probabilistic in nature and because all research studies have flaws there is no such thing as scientific proof, there is only scientific evidence.
Reporting the Results
The final step in the research process involves reporting the results. As described in the section on Reviewing the Research Literature in this chapter, results are typically reported in peer-reviewed journal articles and at conferences.
The most prestigious way to report one’s findings is by writing a manuscript and having it published in a peer-reviewed scientific journal. Manuscripts published in psychology journals typically must adhere to the writing style of the American Psychological Association (APA style). You will likely be learning the major elements of this writing style in this course.
Another way to report findings is by writing a book chapter that is published in an edited book. Preferably the editor of the book puts the chapter through peer review but this is not always the case and some scientists are invited by editors to write book chapters.
A fun way to disseminate findings is to give a presentation at a conference. This can either be done as an oral presentation or a poster presentation. Oral presentations involve getting up in front of an audience of fellow scientists and giving a talk that might last anywhere from 10 minutes to 1 hour (depending on the conference) and then fielding questions from the audience. Alternatively, poster presentations involve summarizing the study on a large poster that provides a brief overview of the purpose, methods, results, and discussion. The presenter stands by his or her poster for an hour or two and discusses it with people who pass by. Presenting one’s work at a conference is a great way to get feedback from one’s peers before attempting to undergo the more rigorous peer-review process involved in publishing a journal article.

Share This Book
- Increase Font Size
When you choose to publish with PLOS, your research makes an impact. Make your work accessible to all, without restrictions, and accelerate scientific discovery with options like preprints and published peer review that make your work more Open.
- PLOS Biology
- PLOS Climate
- PLOS Complex Systems
- PLOS Computational Biology
- PLOS Digital Health
- PLOS Genetics
- PLOS Global Public Health
- PLOS Medicine
- PLOS Mental Health
- PLOS Neglected Tropical Diseases
- PLOS Pathogens
- PLOS Sustainability and Transformation
- PLOS Collections
- How to Write Discussions and Conclusions

The discussion section contains the results and outcomes of a study. An effective discussion informs readers what can be learned from your experiment and provides context for the results.
What makes an effective discussion?
When you’re ready to write your discussion, you’ve already introduced the purpose of your study and provided an in-depth description of the methodology. The discussion informs readers about the larger implications of your study based on the results. Highlighting these implications while not overstating the findings can be challenging, especially when you’re submitting to a journal that selects articles based on novelty or potential impact. Regardless of what journal you are submitting to, the discussion section always serves the same purpose: concluding what your study results actually mean.
A successful discussion section puts your findings in context. It should include:
- the results of your research,
- a discussion of related research, and
- a comparison between your results and initial hypothesis.
Tip: Not all journals share the same naming conventions.
You can apply the advice in this article to the conclusion, results or discussion sections of your manuscript.
Our Early Career Researcher community tells us that the conclusion is often considered the most difficult aspect of a manuscript to write. To help, this guide provides questions to ask yourself, a basic structure to model your discussion off of and examples from published manuscripts.
Questions to ask yourself:
- Was my hypothesis correct?
- If my hypothesis is partially correct or entirely different, what can be learned from the results?
- How do the conclusions reshape or add onto the existing knowledge in the field? What does previous research say about the topic?
- Why are the results important or relevant to your audience? Do they add further evidence to a scientific consensus or disprove prior studies?
- How can future research build on these observations? What are the key experiments that must be done?
- What is the “take-home” message you want your reader to leave with?
How to structure a discussion
Trying to fit a complete discussion into a single paragraph can add unnecessary stress to the writing process. If possible, you’ll want to give yourself two or three paragraphs to give the reader a comprehensive understanding of your study as a whole. Here’s one way to structure an effective discussion:
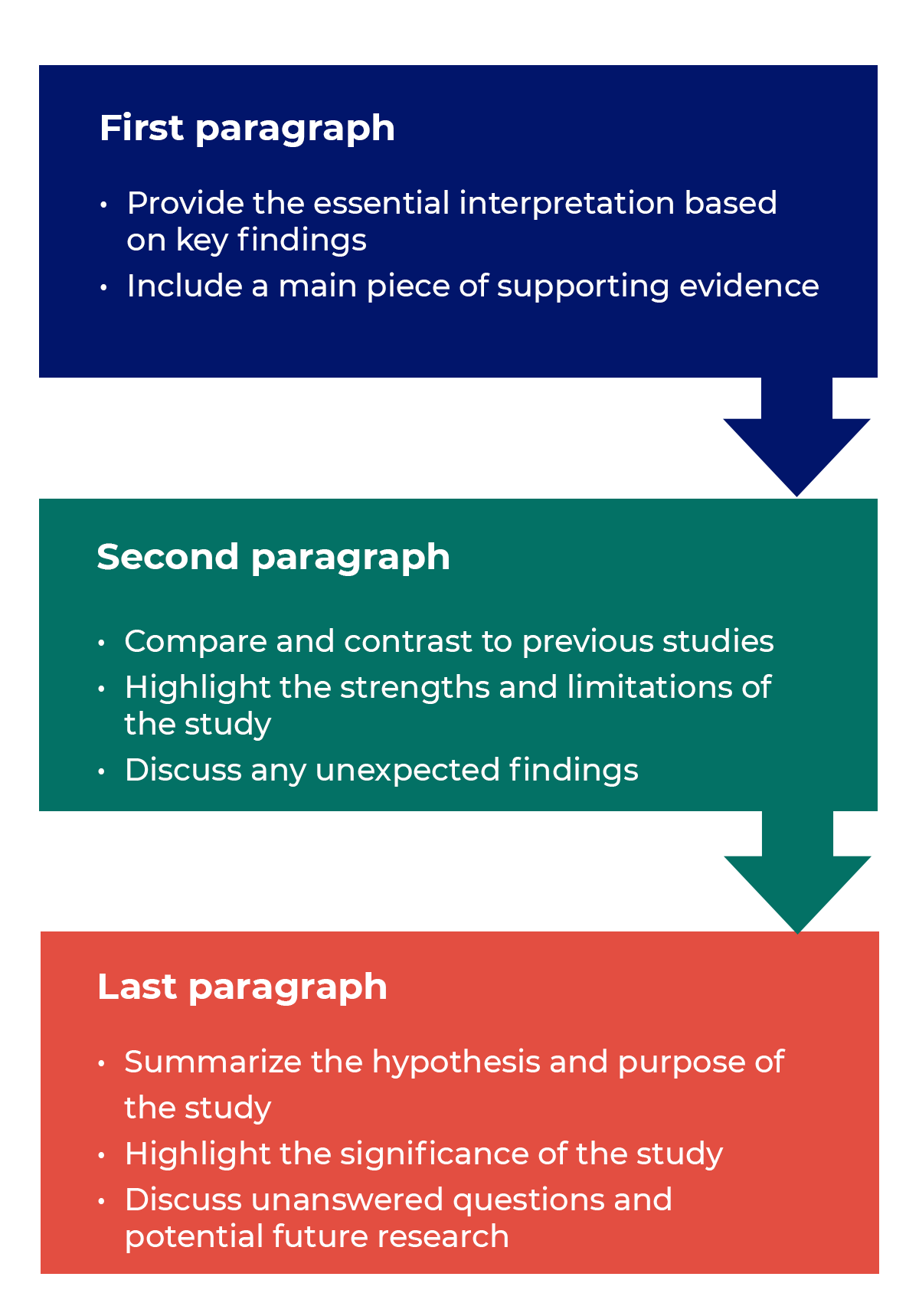
Writing Tips
While the above sections can help you brainstorm and structure your discussion, there are many common mistakes that writers revert to when having difficulties with their paper. Writing a discussion can be a delicate balance between summarizing your results, providing proper context for your research and avoiding introducing new information. Remember that your paper should be both confident and honest about the results!

- Read the journal’s guidelines on the discussion and conclusion sections. If possible, learn about the guidelines before writing the discussion to ensure you’re writing to meet their expectations.
- Begin with a clear statement of the principal findings. This will reinforce the main take-away for the reader and set up the rest of the discussion.
- Explain why the outcomes of your study are important to the reader. Discuss the implications of your findings realistically based on previous literature, highlighting both the strengths and limitations of the research.
- State whether the results prove or disprove your hypothesis. If your hypothesis was disproved, what might be the reasons?
- Introduce new or expanded ways to think about the research question. Indicate what next steps can be taken to further pursue any unresolved questions.
- If dealing with a contemporary or ongoing problem, such as climate change, discuss possible consequences if the problem is avoided.
- Be concise. Adding unnecessary detail can distract from the main findings.

Don’t
- Rewrite your abstract. Statements with “we investigated” or “we studied” generally do not belong in the discussion.
- Include new arguments or evidence not previously discussed. Necessary information and evidence should be introduced in the main body of the paper.
- Apologize. Even if your research contains significant limitations, don’t undermine your authority by including statements that doubt your methodology or execution.
- Shy away from speaking on limitations or negative results. Including limitations and negative results will give readers a complete understanding of the presented research. Potential limitations include sources of potential bias, threats to internal or external validity, barriers to implementing an intervention and other issues inherent to the study design.
- Overstate the importance of your findings. Making grand statements about how a study will fully resolve large questions can lead readers to doubt the success of the research.
Snippets of Effective Discussions:
Consumer-based actions to reduce plastic pollution in rivers: A multi-criteria decision analysis approach
Identifying reliable indicators of fitness in polar bears
- How to Write a Great Title
- How to Write an Abstract
- How to Write Your Methods
- How to Report Statistics
- How to Edit Your Work
The contents of the Peer Review Center are also available as a live, interactive training session, complete with slides, talking points, and activities. …
The contents of the Writing Center are also available as a live, interactive training session, complete with slides, talking points, and activities. …
There’s a lot to consider when deciding where to submit your work. Learn how to choose a journal that will help your study reach its audience, while reflecting your values as a researcher…
Scientific Conclusions | Definition, Steps & Examples
Additional info.
Alexandrea has taught secondary science for over six years. She has a bachelors degree in Teaching Secondary Science and a Masters of Education in Instructional Design. She's TESOL certified and a National Geographic Certified Educator. In addition, she was the spotlight educator for National Geographic in late 2019.
Amanda has taught high school science for over 10 years. She has a Master's Degree in Cellular and Molecular Physiology from Tufts Medical School and a Master's of Teaching from Simmons College. She is also certified in secondary special education, biology, and physics in Massachusetts.
What is an example of a conclusion in science?
Conclusions in science can be both simple and complex. Examples of scientific conclusions abound, including those written about the efficacy and implementation of vaccines like DTaP/TDaP.
How do you write a conclusion for science?
Scientific conclusions should be written after the first four steps of the scientific method are completed. They are Question, Hypothesize, Experiment, Analyze, and then finally Conclude. The conclusions should include contextual information, experimental results, analysis, and the conclusion drawn from that data.
Table of Contents
The scientific method & conclusion, how to write a scientific conclusion, scientific conclusion example, lesson summary.
The scientific method is an experimental process used in all branches of math, science, engineering, social sciences, and many other experimental pursuits. All experiments follow a version of the scientific method in order to be valid. The steps to the scientific method are:
- Determine the Question or Problem: What is the research attempting to explore?
- Hypothesize the Outcome: What is the outcome expected by the researcher? These are often written as if, then statements.
- Gather Data: Conduct the experiment and record results with fidelity.
- Analyze Data: Determine relationships between data points.
- Draw Conclusions: Using the analysis, conclude whether the hypothesis was correct or not, and why.
A classic example is the Penny Drop Experiment that many science teachers use as a demonstrative to teach their students about water tension. First, the student determines the question to be, how many drops of water can a penny hold? . The student will then write a hypothesis, usually guessing between five and eight drops of water will fit on a penny. Then, each student is given a penny and a pipette. Most pennies will hold 25 or more drops of water, and students count and record how many drops fit. The experiment is repeated three times. Next, the data is analyzed to find an average between the three experimental trials. Lastly, the student draws a scientific method conclusion as to how many drops of water fit on a penny and if their hypothesis was correct or not. This lesson will focus primarily on the intricacies of this last step, which is scientific conclusions.
What is a Conclusion in Science?
The definition of a scientific conclusion in science is the summary of the results of an experiment that is usually shared with peers or the general public. It is important to separate this from a scientific theory , which is a data-driven explanation, usually of the natural world. In order for a conclusion to become a theory, it must undergo numerous trials, often through several generations of scientists and critical thinkers. Examples of this include the theory of gravity.
To unlock this lesson you must be a Study.com Member. Create your account
For simple experiments, like the penny experiment discussed in the previous section, the scientific conclusion might be one sentence or two. Most academic research contains scientific conclusions that are pages in length, and some conclusions are as long as books. This depends entirely on the complexity of ideas and how much space it takes to effectively communicate those ideas and experimental results. Regardless of its length, the scientific conclusion requires the collection of data and data analysis to occur prior to a conclusion being made. It should include these results, explaining the context of results if required or helpful for overall understanding.
Collecting Data
Methods of data collection are as diverse as the ideas they are testing. Collecting data is the first step of developing a valid scientific conclusion once questioning and hypothesizing are complete. Regardless of the data collection method used, most experiments include writing a procedure . A procedure is a written document that details how an experiment was conducted, in the hopes that other peers in the field will be able to replicate the same results under different conditions. Repeating experiments several times ensures data is reliable and untainted by bias or extraneous variables. Extraneous variables change the results of an experiment without the knowledge or intent of the researcher.
An example of an extraneous variable impacting a study could be the time of day. A zoologist is researching the activity and breeding habits of a marsupial , noting that they seem to be a sleepy and uninterested species. He takes notes usually at three o'clock in the afternoon. If he were to take notes at all hours of the day, his report would reflect the truth that these marsupials are nocturnal and are most active between midnight and sunrise.
Analyzing Data & Results
Data shouldn't be analyzed by researchers during collection. This is because their preconceived notions might sway their data collection, either subconsciously or consciously. Proper analysis usually takes more time than data collection and can include tools like:
- Graphic organizers
- Line graphs
Any tool that helps the researcher look for patterns or trends in the data is helpful during data analysis. Outliers should also be noted during this period. In some cases, the outlier might require context from the researcher. For example, children receive test scores of 79, 81, 80, 78, 82, and 1,197. The last score, much higher than the others, should be identified by the researcher as a profoundly gifted child to provide context.
Drawing a Scientific Conclusion
Particularly with hot-button issues like reproduction, death, politics, war, medications, and access to medical treatment, poorly-conducted studies with ample bias are common. Bias is supporting something unfairly, or allowing personal feelings or opinions to influence things that should be kept separate. There are dozens of types of bias, including:
- Confirmation Bias: In which the scientist decides on the conclusion of the study before conducting it, either subconsciously or consciously.
- Sampling Bias: In which a representative population isn't included in the study. For example, surveying only white males under the age of 27 who identify as liberals, rather than everyone in a population including people of all ethnicities, ages, and belief systems.
- Publication Bias: In which certain types of studies are more likely to be published and read, usually leaning towards social science studies that are easier to understand and leaning away from mathematically dense publications.
- Funding Bias: The study is funded by an interested party, rather than a usually unbiased institution like a school or university.
Here is a hypothetical example of a biased study. BigFarma, a pharmaceutical company, is attempting to get its new medication approved. It is called FixItRol. During in-house clinical trials, heart problems were noted in younger adults for an unknown reason. To combat this, a subsidiary fund of BigFarma called "We Love Drugs From BigFarma" funds a study on FixItRol. This study shuts down the issues noted by previous researchers so it moves forward in the approval process. Where is the bias in this scenario? Looking at the funding source of many studies can elucidate what conclusions were drawn and why.
To avoid these pitfalls, scientific conclusions should be grounded in evidence, rather than bias. Ideally, the experiment has been repeated with the same results by other scientists in other environments. One of the ways that researchers can ensure their work has a limited amount of bias (as eliminating all bias is practically impossible) is by allowing peers to poke holes in it, challenging the conclusions or results by asking probing questions .
One of the most current scientific conclusion examples being put to the test today is that of vaccinations. This example will examine the DTaP/TDaP vaccine, which protects against Diphtheria , Pertussis, and Tetanus. These are three extremely serious diseases, all of which can cause serious harm or death. Diphtheria alone had over 150,000 yearly cases in the United States and was a common cause of death, particularly in children and young adolescents.
The modern vaccine was released, after gaining FDA approval, in 1991. However, Diphtheria vaccines have been available since the 1940s, and since their implementation, fewer than two cases per year have been recorded on average. The development of DTaP and its predecessors required the collection of data, analysis of results, and the drawing of conclusions many times before a vaccination that worked was discovered. A simple conclusion of this analyzed data could read, It appears as though the implementation of the Diphtheria vaccine in the 1940s resulted in a dramatic decrease in the incidence of disease .
The scientific method is an experimental process used in many experimental and academic branches to ensure valid results. The steps are Question, Hypothesize, Experiment, Analyze, and Conclude. The last step is a scientific conclusion , which is a summary of the results of an experiment that is usually shared with peers of the general public. Before a conclusion is written, the data collection and analysis must happen first. Patterns and trends should be assessed during the analysis process. The results should also be grounded in evidence, rather than bias. Bias is supporting something unfairly, or allowing personal feelings or opinions to influence things that should be kept separate.
Ideally, results are repeated several times by the main researcher along with researchers in different environments. This is achieved through the use of a procedure . A procedure is a written document that details how an experiment was conducted, in the hopes that other peers in the field will be able to replicate the same results to ensure the experiment is valid. Data collection is considered to be the first step of the conclusion process, once questioning and hypothesizing have been completed. Prior to publication, conclusions should be assessed for validity. One way to do this is to ask a peer to ask lots of questions in an attempt to poke holes in the conclusion.
Scientific Experiments and Conclusions
You're in biology class conducting an investigation on osmosis. You design an experiment to test which solutions cause water to go into a cell versus out of a cell. Your group tries the experiment three times and gets the same result.
Another group only does the experiment once, but gets a different result. To make matters more complicated, another group confirms your result, but gives a different explanation for the data. Who's data is more correct? How will you reconcile all these different results for your lab report?
The process of analyzing data and making meaning of it is called drawing conclusions in science. Evaluating scientific data is a key feature of being a scientist. Today, we're going to learn what methods are most reliable for gathering data, how to analyze results and finally draw conclusions, including comparing multiple explanations for the same data.
Gathering Data
The first step in any experiment is to gather data. Although this may seem simple, the process of gathering data can make or break a conclusion. Recall the beginning of this lesson where your group conducted the experiment three times and another group conducted an experiment only once. Which set of data is more reliable?
The more times an experiment is repeated and produces the same outcome, the more reliable the data is. A result that only occurs once is much more likely to be due to chance than any scientific principle. More trials equals more accurate data, and more accurate data will give you a more meaningful conclusion.
Analyzing Results
Now that you have your reliable data, it's time to analyze , or look for patterns in that data. At this point, it's helpful to make a chart or graph to organize your data. Ask yourself what you notice? Are there any differences between samples or trends?
Let's say you're studying photosynthesis. To do this you put spinach leaves in water, with or without carbon dioxide. You hypothesize that only the leaves with carbon dioxide will do photosynthesis.
When you preform your experiment, you see a trend that the more carbon dioxide the leaves were given, the more oxygen bubbles were produced. This is a trend and an important part of your analysis. During the analysis phase, you're looking for facts, trends, or patterns in your data, not necessarily making conclusions yet.
Drawing Conclusions
Now that you've noticed some patterns, it's time to make conclusions and figure out what that analysis means in context of science. In your photosynthesis experiment, you saw oxygen bubbles produced by the spinach in carbon dioxide rich water. What does that mean?
Using your background research, you know that photosynthesis makes oxygen. So, if the spinach makes oxygen bubbles, wouldn't that mean they are doing photosynthesis? And if the spinach with no carbon dioxide makes no bubbles, you can come to the conclusion that photosynthesis requires carbon dioxide.
How solid is this conclusion? Well, how can you be sure the bubbles are oxygen and not something else? Is that a reasonable assumption? Could you test that theory?
When coming to conclusions it's important to try to pick apart your own explanation. Think critically about other explanations for the same data, as if you are trying to prove yourself wrong. Science isn't about being wrong or right in your prediction, but rather coming to a solid conclusion based in evidence.
There is no bias in science, or having a preference for one answer. Scientists look strictly at the facts with no emotional attachment to their hypothesis.
Your job as a scientist is to defend your conclusion using only evidence from your experiment. If you don't have enough evidence to hold up your conclusion it's back to the drawing board. It doesn't make you a bad scientist. In fact, scientists learn just as much or more from incorrect hypotheses as they do from correct ones.
Comparing Alternate Explanations
Sometimes in science, there is conflicting data or people offer alternate conclusions for the same data. How are you supposed to know what's true? Well, we can go back to our steps.
Which experiment had the most statistically significant data, or data that was repeatable and reliable. If they both have solid methods and reliable results, it's time to look at the conclusions and compare.
Let's say scientists are trying to determine what causes cell growth. One experiment shows that a protein called TGF-beta causes cells to grow and might be too high in certain types of cancer. Yet another study finds the opposite data, that TGF-beta decreases cell growth. How can both be true?
It's time to find some differences in the two studies. Did the two groups use different types of cells? Were the cells grown under different conditions? Was one study more reliable than the other? When differences come about in scientific research, it's time to ask more questions. Both studies might be true, but the key is to ask questions and conduct more investigations.
Scientists gather data to analyze and make conclusions about a scientific phenomenon. Data should be repeatable and statistically significant to ground any conclusions. During the analysis phase, scientists look for patterns or trends without bias . Scientists can't be attached to their hypothesis and must only follow what the data explains.
Incorrect hypotheses provide just as much information as correct ones. Once there are patterns established, its time to assign meaning through making conclusions. Scientists apply known research to their data to draw conclusions about what it means. Sometimes, there may be conflicting information from similar studies. The job of the scientist is to notice what might be different and ask new questions to conduct more investigations.
Register to view this lesson
Unlock your education, see for yourself why 30 million people use study.com, become a study.com member and start learning now..
Already a member? Log In
Resources created by teachers for teachers
I would definitely recommend Study.com to my colleagues. It’s like a teacher waved a magic wand and did the work for me. I feel like it’s a lifeline.
Scientific Conclusions | Definition, Steps & Examples Related Study Materials
- Related Topics
Browse by Courses
- CSET Science Subtest II Chemistry (218): Practice & Study Guide
- Health 101: Principles of Health
- Weather and Climate
- CLEP Biology: Study Guide & Test Prep Course
- UExcel Anatomy & Physiology: Study Guide & Test Prep
- NY Regents Exam - Physics: Help and Review
- NY Regents Exam - Physics: Tutoring Solution
- Nutrition 101: Science of Nutrition
- Astronomy 101: Intro to Astronomy
- Supplemental Science: Study Aid
- AP Physics 2: Exam Prep
- DSST Foundations of Education Prep
- High School Physical Science: Help and Review
- NY Regents Exam - Earth Science: Tutoring Solution
- Middle School Life Science: Help and Review
Browse by Lessons
- Scientific Method | Definition, Steps & Examples
- Scientific Investigation | Overview, Steps & Examples
- Scientific Research Definition, Classifications & Purpose
- How to Improve Validity of a Scientific Investigation
- Nonscientific and Scientific Research: Definitions and Differences
- The Scientific Method Applied to Environmental Problems: Definition, Steps and Applications
- Scientific Method in Psychology | Definition, Steps & Examples
- Scientific Experiment | Types & Examples
- Scientific Thinking Definition, Method & Examples
- Scientific Method | Overview, Steps & Examples
- Scientific Method & Observation | Definition, Steps & Examples
- Scientific Method Lesson for Kids: Definition & Examples
- Scientific Method Lesson for Kids: Steps & Process
- Scientific Method Applications to Human Growth and Development Research
- Scientific Questions | Characteristics & Examples
Create an account to start this course today Used by over 30 million students worldwide Create an account
Explore our library of over 88,000 lessons
- Foreign Language
- Social Science
- See All College Courses
- Common Core
- High School
- See All High School Courses
- College & Career Guidance Courses
- College Placement Exams
- Entrance Exams
- General Test Prep
- K-8 Courses
- Skills Courses
- Teacher Certification Exams
- See All Other Courses
- Create a Goal
- Create custom courses
- Get your questions answered
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- How to Write a Strong Hypothesis | Steps & Examples
How to Write a Strong Hypothesis | Steps & Examples
Published on May 6, 2022 by Shona McCombes . Revised on November 20, 2023.
A hypothesis is a statement that can be tested by scientific research. If you want to test a relationship between two or more variables, you need to write hypotheses before you start your experiment or data collection .
Example: Hypothesis
Daily apple consumption leads to fewer doctor’s visits.
Table of contents
What is a hypothesis, developing a hypothesis (with example), hypothesis examples, other interesting articles, frequently asked questions about writing hypotheses.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess – it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Variables in hypotheses
Hypotheses propose a relationship between two or more types of variables .
- An independent variable is something the researcher changes or controls.
- A dependent variable is something the researcher observes and measures.
If there are any control variables , extraneous variables , or confounding variables , be sure to jot those down as you go to minimize the chances that research bias will affect your results.
In this example, the independent variable is exposure to the sun – the assumed cause . The dependent variable is the level of happiness – the assumed effect .
Prevent plagiarism. Run a free check.
Step 1. ask a question.
Writing a hypothesis begins with a research question that you want to answer. The question should be focused, specific, and researchable within the constraints of your project.
Step 2. Do some preliminary research
Your initial answer to the question should be based on what is already known about the topic. Look for theories and previous studies to help you form educated assumptions about what your research will find.
At this stage, you might construct a conceptual framework to ensure that you’re embarking on a relevant topic . This can also help you identify which variables you will study and what you think the relationships are between them. Sometimes, you’ll have to operationalize more complex constructs.
Step 3. Formulate your hypothesis
Now you should have some idea of what you expect to find. Write your initial answer to the question in a clear, concise sentence.
4. Refine your hypothesis
You need to make sure your hypothesis is specific and testable. There are various ways of phrasing a hypothesis, but all the terms you use should have clear definitions, and the hypothesis should contain:
- The relevant variables
- The specific group being studied
- The predicted outcome of the experiment or analysis
5. Phrase your hypothesis in three ways
To identify the variables, you can write a simple prediction in if…then form. The first part of the sentence states the independent variable and the second part states the dependent variable.
In academic research, hypotheses are more commonly phrased in terms of correlations or effects, where you directly state the predicted relationship between variables.
If you are comparing two groups, the hypothesis can state what difference you expect to find between them.
6. Write a null hypothesis
If your research involves statistical hypothesis testing , you will also have to write a null hypothesis . The null hypothesis is the default position that there is no association between the variables. The null hypothesis is written as H 0 , while the alternative hypothesis is H 1 or H a .
- H 0 : The number of lectures attended by first-year students has no effect on their final exam scores.
- H 1 : The number of lectures attended by first-year students has a positive effect on their final exam scores.
| Research question | Hypothesis | Null hypothesis |
|---|---|---|
| What are the health benefits of eating an apple a day? | Increasing apple consumption in over-60s will result in decreasing frequency of doctor’s visits. | Increasing apple consumption in over-60s will have no effect on frequency of doctor’s visits. |
| Which airlines have the most delays? | Low-cost airlines are more likely to have delays than premium airlines. | Low-cost and premium airlines are equally likely to have delays. |
| Can flexible work arrangements improve job satisfaction? | Employees who have flexible working hours will report greater job satisfaction than employees who work fixed hours. | There is no relationship between working hour flexibility and job satisfaction. |
| How effective is high school sex education at reducing teen pregnancies? | Teenagers who received sex education lessons throughout high school will have lower rates of unplanned pregnancy teenagers who did not receive any sex education. | High school sex education has no effect on teen pregnancy rates. |
| What effect does daily use of social media have on the attention span of under-16s? | There is a negative between time spent on social media and attention span in under-16s. | There is no relationship between social media use and attention span in under-16s. |
If you want to know more about the research process , methodology , research bias , or statistics , make sure to check out some of our other articles with explanations and examples.
- Sampling methods
- Simple random sampling
- Stratified sampling
- Cluster sampling
- Likert scales
- Reproducibility
Statistics
- Null hypothesis
- Statistical power
- Probability distribution
- Effect size
- Poisson distribution
Research bias
- Optimism bias
- Cognitive bias
- Implicit bias
- Hawthorne effect
- Anchoring bias
- Explicit bias
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Null and alternative hypotheses are used in statistical hypothesis testing . The null hypothesis of a test always predicts no effect or no relationship between variables, while the alternative hypothesis states your research prediction of an effect or relationship.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
McCombes, S. (2023, November 20). How to Write a Strong Hypothesis | Steps & Examples. Scribbr. Retrieved June 9, 2024, from https://www.scribbr.com/methodology/hypothesis/
Is this article helpful?

Shona McCombes
Other students also liked, construct validity | definition, types, & examples, what is a conceptual framework | tips & examples, operationalization | a guide with examples, pros & cons, what is your plagiarism score.

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
1.2: The 7-Step Process of Statistical Hypothesis Testing
- Last updated
- Save as PDF
- Page ID 33320

- Penn State's Department of Statistics
- The Pennsylvania State University
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
We will cover the seven steps one by one.
Step 1: State the Null Hypothesis
The null hypothesis can be thought of as the opposite of the "guess" the researchers made: in this example, the biologist thinks the plant height will be different for the fertilizers. So the null would be that there will be no difference among the groups of plants. Specifically, in more statistical language the null for an ANOVA is that the means are the same. We state the null hypothesis as: \[H_{0}: \ \mu_{1} = \mu_{2} = \ldots = \mu_{T}\] for \(T\) levels of an experimental treatment.
Why do we do this? Why not simply test the working hypothesis directly? The answer lies in the Popperian Principle of Falsification. Karl Popper (a philosopher) discovered that we can't conclusively confirm a hypothesis, but we can conclusively negate one. So we set up a null hypothesis which is effectively the opposite of the working hypothesis. The hope is that based on the strength of the data, we will be able to negate or reject the null hypothesis and accept an alternative hypothesis. In other words, we usually see the working hypothesis in \(H_{A}\).
Step 2: State the Alternative Hypothesis
\[H_{A}: \ \text{treatment level means not all equal}\]
The reason we state the alternative hypothesis this way is that if the null is rejected, there are many possibilities.
For example, \(\mu_{1} \neq \mu_{2} = \ldots = \mu_{T}\) is one possibility, as is \(\mu_{1} = \mu_{2} \neq \mu_{3} = \ldots = \mu_{T}\). Many people make the mistake of stating the alternative hypothesis as \(mu_{1} \neq mu_{2} \neq \ldots \neq \mu_{T}\), which says that every mean differs from every other mean. This is a possibility, but only one of many possibilities. To cover all alternative outcomes, we resort to a verbal statement of "not all equal" and then follow up with mean comparisons to find out where differences among means exist. In our example, this means that fertilizer 1 may result in plants that are really tall, but fertilizers 2, 3, and the plants with no fertilizers don't differ from one another. A simpler way of thinking about this is that at least one mean is different from all others.
Step 3: Set \(\alpha\)
If we look at what can happen in a hypothesis test, we can construct the following contingency table:
| \(H_{0}\) is TRUE | \(H_{0}\) is FALSE | |
| Accept \(H_{0}\) | correct | Type II Error \(\beta\) = probability of Type II Error |
| Reject \(H_{0}\) | Type I Error | correct |
You should be familiar with type I and type II errors from your introductory course. It is important to note that we want to set \(\alpha\) before the experiment ( a priori ) because the Type I error is the more grievous error to make. The typical value of \(\alpha\) is 0.05, establishing a 95% confidence level. For this course, we will assume \(\alpha\) =0.05, unless stated otherwise.
Step 4: Collect Data
Remember the importance of recognizing whether data is collected through an experimental design or observational study.
Step 5: Calculate a test statistic
For categorical treatment level means, we use an \(F\) statistic, named after R.A. Fisher. We will explore the mechanics of computing the \(F\) statistic beginning in Chapter 2. The \(F\) value we get from the data is labeled \(F_{\text{calculated}}\).
Step 6: Construct Acceptance / Rejection regions
As with all other test statistics, a threshold (critical) value of \(F\) is established. This \(F\) value can be obtained from statistical tables or software and is referred to as \(F_{\text{critical}}\) or \(F_{\alpha}\). As a reminder, this critical value is the minimum value for the test statistic (in this case the F test) for us to be able to reject the null.
The \(F\) distribution, \(F_{\alpha}\), and the location of acceptance and rejection regions are shown in the graph below:
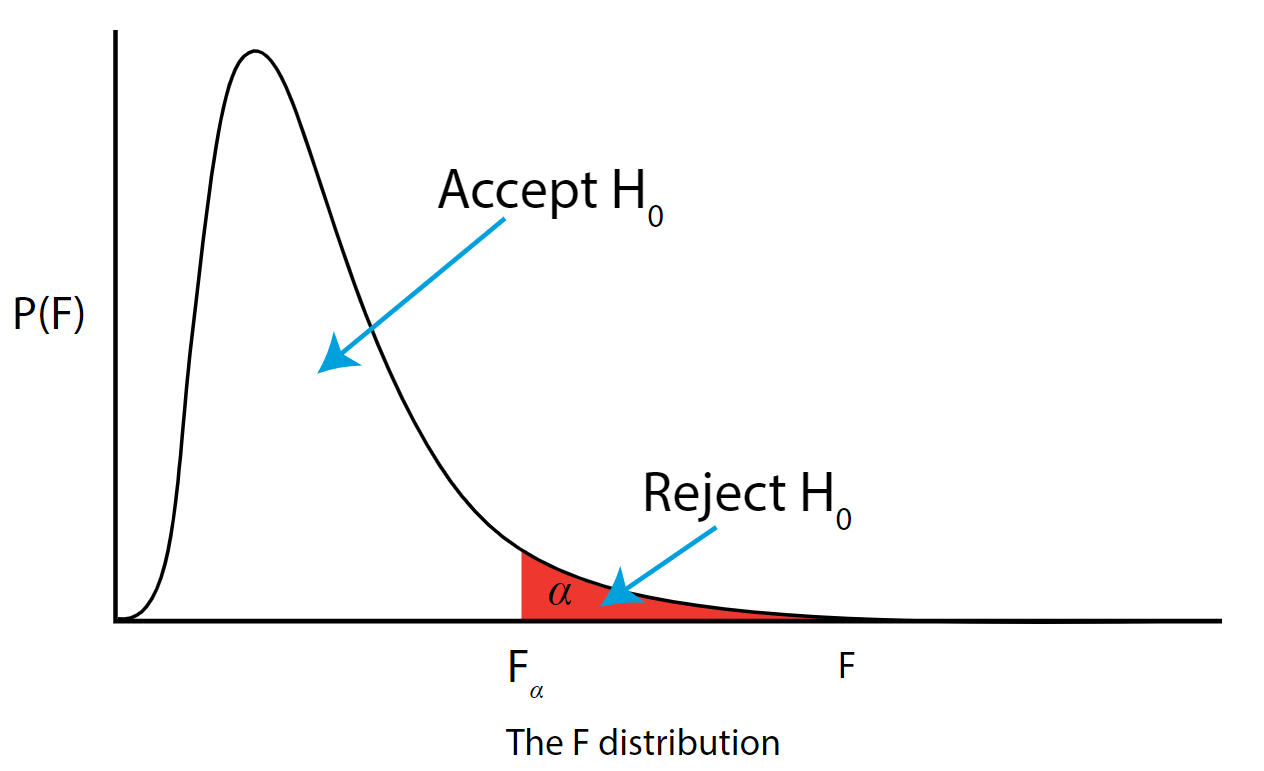.png?revision=1&size=bestfit&width=629&height=383 "what conclusions can be drawn from a hypothesis")
Step 7: Based on steps 5 and 6, draw a conclusion about H0
If the \(F_{\text{\calculated}}\) from the data is larger than the \(F_{\alpha}\), then you are in the rejection region and you can reject the null hypothesis with \((1 - \alpha)\) level of confidence.
Note that modern statistical software condenses steps 6 and 7 by providing a \(p\)-value. The \(p\)-value here is the probability of getting an \(F_{\text{calculated}}\) even greater than what you observe assuming the null hypothesis is true. If by chance, the \(F_{\text{calculated}} = F_{\alpha}\), then the \(p\)-value would exactly equal \(\alpha\). With larger \(F_{\text{calculated}}\) values, we move further into the rejection region and the \(p\) - value becomes less than \(\alpha\). So the decision rule is as follows:
If the \(p\) - value obtained from the ANOVA is less than \(\alpha\), then reject \(H_{0}\) and accept \(H_{A}\).
If you are not familiar with this material, we suggest that you review course materials from your basic statistics course.
Module 9: Hypothesis Testing With One Sample
Drawing conclusions, learning outcomes.
- State a conclusion to a hypothesis test in statistical terms and in context
Establishing the type of distribution, sample size, and known or unknown standard deviation can help you figure out how to go about a hypothesis test. However, there are several other factors you should consider when working out a hypothesis test.
Rare Events
Suppose you make an assumption about a property of the population (this assumption is the null hypothesis ). Then you gather sample data randomly. If the sample has properties that would be very unlikely to occur if the assumption is true, then you would conclude that your assumption about the population is probably incorrect. (Remember that your assumption is just an assumption —it is not a fact and it may or may not be true. But your sample data are real and the data are showing you a fact that seems to contradict your assumption.)
For example, Didi and Ali are at a birthday party of a very wealthy friend. They hurry to be first in line to grab a prize from a tall basket that they cannot see inside because they will be blindfolded. There are 200 plastic bubbles in the basket and Didi and Ali have been told that there is only one with a $100 bill. Didi is the first person to reach into the basket and pull out a bubble. Her bubble contains a $100 bill. The probability of this happening is [latex]\displaystyle\frac{{1}}{{200}}={0.005}[/latex]. Because this is so unlikely, Ali is hoping that what the two of them were told is wrong and there are more $100 bills in the basket. A “rare event” has occurred (Didi getting the $100 bill) so Ali doubts the assumption about only one $100 bill being in the basket.
Using the Sample to Test the Null Hypothesis
Use the sample data to calculate the actual probability of getting the test result, called the p -value . The p -value is the probability that, if the null hypothesis is true, the results from another randomly selected sample will be as extreme or more extreme as the results obtained from the given sample .
A large p -value calculated from the data indicates that we should not reject the null hypothesis . The smaller the p -value, the more unlikely the outcome, and the stronger the evidence is against the null hypothesis. We would reject the null hypothesis if the evidence is strongly against it.
Draw a graph that shows the p -value. The hypothesis test is easier to perform if you use a graph because you see the problem more clearly.
Recall: RECALL EVALUATING EXPRESSIONS
We use letters to represent unknown numerical values, these are called variables. Any variable in an algebraic expression may take on or be assigned different values. When that happens, the value of the algebraic expression changes. To evaluate an algebraic expression means to determine the value of the expression for a given value of each variable in the expression. Replace each variable in the expression with the given value then simplify the resulting expression using the order of operations.
Suppose a baker claims that his bread height is more than 15 cm, on average. Several of his customers do not believe him. To persuade his customers that he is right, the baker decides to do a hypothesis test. He bakes 10 loaves of bread. The mean height of the sample loaves is 17 cm. The baker knows from baking hundreds of loaves of bread that the standard deviation for the height is 0.5 cm and the distribution of heights is normal.
The null hypothesis could be H 0 : μ ≤ 15
The alternate hypothesis is H a : μ > 15
The words “is more than” translates as a “>” so “ μ > 15″ goes into the alternate hypothesis. The null hypothesis must contradict the alternate hypothesis.
Since σ is known ( σ = 0.5 cm.), the distribution for the population is known to be normal with mean μ = 15 and standard deviation [latex]\displaystyle\frac{\sigma}{\sqrt{n}}=\frac{0.5}{\sqrt{10}}=0.16[/latex]
Suppose the null hypothesis is true (the mean height of the loaves is no more than 15 cm). Then is the mean height (17 cm) calculated from the sample unexpectedly large? The hypothesis test works by asking the question how unlikely the sample mean would be if the null hypothesis were true. The graph shows how far out the sample mean is on the normal curve. The p -value is the probability that, if we were to take other samples, any other sample mean would fall at least as far out as 17 cm.
The p -value, then, is the probability that a sample mean is the same or greater than 17 cm when the population mean is, in fact, 15 cm. We can calculate this probability using the normal distribution for means.

p -value = P ([latex]\overline{x}[/latex] > 17) which is approximately zero.
A p -value of approximately zero tells us that it is highly unlikely that a loaf of bread rises no more than 15 cm, on average. That is, almost 0% of all loaves of bread would be at least as high as 17 cm purely by CHANCE had the population mean height really been 15 cm. Because the outcome of 17 cm is so unlikely (meaning it is happening NOT by chance alone) , we conclude that the evidence is strongly against the null hypothesis (the mean height is at most 15 cm). There is sufficient evidence that the true mean height for the population of the baker’s loaves of bread is greater than 15 cm.
A normal distribution has a standard deviation of 1. We want to verify a claim that the mean is greater than 12. A sample of 36 is taken with a sample mean of 12.5.
H 0 : μ ≤ 12
H a : μ > 12
The p -value is 0.0013
Draw a graph that shows the p -value.
p- value = 0.0013
- Rare Events, the Sample, Decision and Conclusion. Provided by : OpenStax. Located at : https://openstax.org/books/statistics/pages/9-4-rare-events-the-sample-and-the-decision-and-conclusion . License : CC BY: Attribution . License Terms : Access for free at https://openstax.org/books/statistics/pages/1-introduction
- Introductory Statistics. Authored by : Barbara Illowsky, Susan Dean. Provided by : OpenStax. Located at : https://openstax.org/books/introductory-statistics/pages/1-introduction . License : CC BY: Attribution . License Terms : Access for free at https://openstax.org/books/introductory-statistics/pages/1-introduction
- Prealgebra. Provided by : OpenStax. Located at : https://openstax.org/books/prealgebra/pages/1-introduction . License : CC BY: Attribution . License Terms : Access for free at https://openstax.org/books/prealgebra/pages/1-introduction

Privacy Policy
If you're seeing this message, it means we're having trouble loading external resources on our website.
If you're behind a web filter, please make sure that the domains *.kastatic.org and *.kasandbox.org are unblocked.
To log in and use all the features of Khan Academy, please enable JavaScript in your browser.
AP®︎/College Statistics
Course: ap®︎/college statistics > unit 10.
- Idea behind hypothesis testing
- Examples of null and alternative hypotheses
- Writing null and alternative hypotheses
- P-values and significance tests
- Comparing P-values to different significance levels
- Estimating a P-value from a simulation
- Estimating P-values from simulations
Using P-values to make conclusions
- (Choice A) Fail to reject H 0 A Fail to reject H 0
- (Choice B) Reject H 0 and accept H a B Reject H 0 and accept H a
- (Choice C) Accept H 0 C Accept H 0
- (Choice A) The evidence suggests that these subjects can do better than guessing when identifying the bottled water. A The evidence suggests that these subjects can do better than guessing when identifying the bottled water.
- (Choice B) We don't have enough evidence to say that these subjects can do better than guessing when identifying the bottled water. B We don't have enough evidence to say that these subjects can do better than guessing when identifying the bottled water.
- (Choice C) The evidence suggests that these subjects were simply guessing when identifying the bottled water. C The evidence suggests that these subjects were simply guessing when identifying the bottled water.
- (Choice A) She would have rejected H a . A She would have rejected H a .
- (Choice B) She would have accepted H 0 . B She would have accepted H 0 .
- (Choice C) She would have rejected H 0 and accepted H a . C She would have rejected H 0 and accepted H a .
- (Choice D) She would have reached the same conclusion using either α = 0.05 or α = 0.10 . D She would have reached the same conclusion using either α = 0.05 or α = 0.10 .
- (Choice A) The evidence suggests that these bags are being filled with a mean amount that is different than 7.4 kg . A The evidence suggests that these bags are being filled with a mean amount that is different than 7.4 kg .
- (Choice B) We don't have enough evidence to say that these bags are being filled with a mean amount that is different than 7.4 kg . B We don't have enough evidence to say that these bags are being filled with a mean amount that is different than 7.4 kg .
- (Choice C) The evidence suggests that these bags are being filled with a mean amount of 7.4 kg . C The evidence suggests that these bags are being filled with a mean amount of 7.4 kg .
- (Choice A) They would have rejected H a . A They would have rejected H a .
- (Choice B) They would have accepted H 0 . B They would have accepted H 0 .
- (Choice C) They would have failed to reject H 0 . C They would have failed to reject H 0 .
- (Choice D) They would have reached the same conclusion using either α = 0.05 or α = 0.01 . D They would have reached the same conclusion using either α = 0.05 or α = 0.01 .
Ethics and the significance level α
Want to join the conversation.
- Upvote Button navigates to signup page
- Downvote Button navigates to signup page
- Flag Button navigates to signup page

User Preferences
Content preview.
Arcu felis bibendum ut tristique et egestas quis:
- Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris
- Duis aute irure dolor in reprehenderit in voluptate
- Excepteur sint occaecat cupidatat non proident
Keyboard Shortcuts
6.6 - confidence intervals & hypothesis testing.
Confidence intervals and hypothesis tests are similar in that they are both inferential methods that rely on an approximated sampling distribution. Confidence intervals use data from a sample to estimate a population parameter. Hypothesis tests use data from a sample to test a specified hypothesis. Hypothesis testing requires that we have a hypothesized parameter.
The simulation methods used to construct bootstrap distributions and randomization distributions are similar. One primary difference is a bootstrap distribution is centered on the observed sample statistic while a randomization distribution is centered on the value in the null hypothesis.
In Lesson 4, we learned confidence intervals contain a range of reasonable estimates of the population parameter. All of the confidence intervals we constructed in this course were two-tailed. These two-tailed confidence intervals go hand-in-hand with the two-tailed hypothesis tests we learned in Lesson 5. The conclusion drawn from a two-tailed confidence interval is usually the same as the conclusion drawn from a two-tailed hypothesis test. In other words, if the the 95% confidence interval contains the hypothesized parameter, then a hypothesis test at the 0.05 \(\alpha\) level will almost always fail to reject the null hypothesis. If the 95% confidence interval does not contain the hypothesize parameter, then a hypothesis test at the 0.05 \(\alpha\) level will almost always reject the null hypothesis.
Example: Mean Section
This example uses the Body Temperature dataset built in to StatKey for constructing a bootstrap confidence interval and conducting a randomization test .
Let's start by constructing a 95% confidence interval using the percentile method in StatKey:
The 95% confidence interval for the mean body temperature in the population is [98.044, 98.474].
Now, what if we want to know if there is enough evidence that the mean body temperature is different from 98.6 degrees? We can conduct a hypothesis test. Because 98.6 is not contained within the 95% confidence interval, it is not a reasonable estimate of the population mean. We should expect to have a p value less than 0.05 and to reject the null hypothesis.
\(H_0: \mu=98.6\)
\(H_a: \mu \ne 98.6\)
\(p = 2*0.00080=0.00160\)
\(p \leq 0.05\), reject the null hypothesis
There is evidence that the population mean is different from 98.6 degrees.
Selecting the Appropriate Procedure Section
The decision of whether to use a confidence interval or a hypothesis test depends on the research question. If we want to estimate a population parameter, we use a confidence interval. If we are given a specific population parameter (i.e., hypothesized value), and want to determine the likelihood that a population with that parameter would produce a sample as different as our sample, we use a hypothesis test. Below are a few examples of selecting the appropriate procedure.
Example: Cheese Consumption Section
Research question: How much cheese (in pounds) does an average American adult consume annually?
What is the appropriate inferential procedure?
Cheese consumption, in pounds, is a quantitative variable. We have one group: American adults. We are not given a specific value to test, so the appropriate procedure here is a confidence interval for a single mean .
Example: Age Section
Research question: Is the average age in the population of all STAT 200 students greater than 30 years?
There is one group: STAT 200 students. The variable of interest is age in years, which is quantitative. The research question includes a specific population parameter to test: 30 years. The appropriate procedure is a hypothesis test for a single mean .
Try it! Section
For each research question, identify the variables, the parameter of interest and decide on the the appropriate inferential procedure.
Research question: How strong is the correlation between height (in inches) and weight (in pounds) in American teenagers?
There are two variables of interest: (1) height in inches and (2) weight in pounds. Both are quantitative variables. The parameter of interest is the correlation between these two variables.
We are not given a specific correlation to test. We are being asked to estimate the strength of the correlation. The appropriate procedure here is a confidence interval for a correlation .
Research question: Are the majority of registered voters planning to vote in the next presidential election?
The parameter that is being tested here is a single proportion. We have one group: registered voters. "The majority" would be more than 50%, or p>0.50. This is a specific parameter that we are testing. The appropriate procedure here is a hypothesis test for a single proportion .
Research question: On average, are STAT 200 students younger than STAT 500 students?
We have two independent groups: STAT 200 students and STAT 500 students. We are comparing them in terms of average (i.e., mean) age.
If STAT 200 students are younger than STAT 500 students, that translates to \(\mu_{200}<\mu_{500}\) which is an alternative hypothesis. This could also be written as \(\mu_{200}-\mu_{500}<0\), where 0 is a specific population parameter that we are testing.
The appropriate procedure here is a hypothesis test for the difference in two means .
Research question: On average, how much taller are adult male giraffes compared to adult female giraffes?
There are two groups: males and females. The response variable is height, which is quantitative. We are not given a specific parameter to test, instead we are asked to estimate "how much" taller males are than females. The appropriate procedure is a confidence interval for the difference in two means .
Research question: Are STAT 500 students more likely than STAT 200 students to be employed full-time?
There are two independent groups: STAT 500 students and STAT 200 students. The response variable is full-time employment status which is categorical with two levels: yes/no.
If STAT 500 students are more likely than STAT 200 students to be employed full-time, that translates to \(p_{500}>p_{200}\) which is an alternative hypothesis. This could also be written as \(p_{500}-p_{200}>0\), where 0 is a specific parameter that we are testing. The appropriate procedure is a hypothesis test for the difference in two proportions.
Research question: Is there is a relationship between outdoor temperature (in Fahrenheit) and coffee sales (in cups per day)?
There are two variables here: (1) temperature in Fahrenheit and (2) cups of coffee sold in a day. Both variables are quantitative. The parameter of interest is the correlation between these two variables.
If there is a relationship between the variables, that means that the correlation is different from zero. This is a specific parameter that we are testing. The appropriate procedure is a hypothesis test for a correlation .
Statistical Thinking: A Simulation Approach to Modeling Uncertainty (UM STAT 216 edition)
2.14 drawing conclusions and “statistical significance”.
We have seen that statistical hypothesis testing is a process of comparing the real-world observed result to a null hypothesis where there is no effect . At the end of the process, we compare the observed result to the distribution of simulated results if the null hypothesis were true, and from this we determine whether the observed result is compatible with the null hypothesis.
The conclusions that we can draw form a hypothesis test are based on the comparison between the observed result and the null hypothesis. For example, in the Monday breakups study , we concluded:
The observed result is not compatible with the null hypothesis. This suggests that breakups may be more likely to be reported on Monday.
There are two important point to notice in how this conclusion is written:
- The conclusion is stated in terms of compatibility with the null hypothesis .
- The conclusion uses soft language like “suggests.” This is becuase we did not prove that breakups are more likely to be reported on Monday. Instead, we simply have strong evidence against the null hypothesis (that breakups are equally likely each day). This, in turn, suggests that breakups are more likely to be reported on Mondays.
Similarly, if the observed result had been within the range of likely results if the null hypothesis were true, we would still write the conclusion in terms of compatibility with the null hypothesis:
The observed result is compatible with the null hypothesis. We do not have sufficient evidence to suggest that breakups are more likely to be reported on Monday.
In both cases, notice that the conclusion is limited to whether there is an effect or not. There are many additional aspects that we might be interested in, but the hypothesis test does not tell us about. For example,
- We don’t know what caused the effect.
- We don’t know the size of the effect. Perhaps the true percentage of Monday breakups is 26%. Perhaps it is slightly more or slightly less. We only have evidence that the results are incompatible with the null hypothesis.
- We don’t know the scope of the effect. Perhaps the phenomenon is limited to this particular year, or to breakups that are reported on facebook, etc.
(We will learn about size, scope, and causation later in the course. The key point to understand now is that a hypothesis test, by itself, can not tell us about these things and so the conclusion should not address them.)
2.14.1 Statistical significance
In news reports and scientific literature, we often hear the term, “statistical significance.” What does it mean for a result to be “statistically significant?” In short, it means that the observed result is not compatible with the null hypothesis.
Different scientific communities have different standards for determining whether a result is statistically significant. In the social sciences, there are two common approaches for determining statistical significance.
- Use the range of likely results: The first approach is to determine whether the observed result is within the range of likely results if the null hypothesis were true. If the observed result is outside the range of likely values if the null hypothesis were true, then social scientists consider A second common practice is to use \(p\) -values. Commonly, social scientists consider that to be sufficient evidence that the observed result is not compatible with the null hypothesis, and thus that the observed result is statistically significant.
- Use p < 0.05: A second common approach is to use a \(p\) -value of 0.05 as a threshold. If \(p<0.05\) , social scientists consider that to be sufficient evidence that the observed result is not compatible with the null hypothesis, and thus that the observed result is statistically significant.
Other scientific communities may have different standards. Moreover, there is currently a lot of discussion about whether the current thresholds should be reconsidered, and even whether we should even have a threshold. Some scholars advocate that researchers should just report the \(p\) -value and make an argument as to whether it provides sufficient evidence against the null model.
For our class, you can use either the “range of likely values” approach, the “ \(p<0.05\) ” approach, or the “report the p-value and make an argument” approach to determining whether an observed result is statistically significant. As you become a member of a scientific community, you will learn which approaches that community uses.
2.14.2 Statistical significance vs. practical significance
Don’t confuse statistical significance with practical significance. Often, statistical significance is taken to be a indication of whether the result is meaningful in the real world (i.e., “practically significant”). But statistical significance has nothing to do with real-world importance. Remember, statistical significance just tells us whether the observed result is compatible with the null hypothesis. The question of whether the result is of real-world (or practical) significance cannot be determined statistically. Instead, this is something that people have to make an argument about.
2.14.3 Other things that statistical significance can’t tell us.
Again, statistical significance only tells us that an observed result is not compatible with the null hypothesis. It does not tell us about other important aspects, including:
- Statistical significance does not mean that we have proven something. It only tells us that the there is evidence against a null model, which in turn would suggest that the effect is real.
- Statistical significance says nothing about what caused the effect
- Statistical significance does not tell us the scope of the effect (that is, how broadly the result apply).
2.14.4 Examples
Here is how to write a conclusion to a hypothesis test.
If the result is statistically significant:
The observed result is not compatible with the null hypothesis. This suggests that there may be an effect.
If the result is not statistically significant:
The observed result is compatible with the null hypothesis. We do not have sufficient evidence to suggest that there is an effect.
2.14.5 Summary
The box below summarizes the key points about drawing conclusions and statistical significance. statistical hypothesis testing.
Key points about drawing conclusions and statistical significance
Conclusions from a hypothesis test are stated in terms of compatibility with the null hypothesis
We do not prove anything, so conclusions should use softer language like suggests
Statistical significance simply means that the observed result is not compatible with the null hypothesis
- Statistical significance does not tell us the size of the effect, or whether it is large enough to have real-world importance.
“Inductive” vs. “Deductive”: How To Reason Out Their Differences
- What Does Inductive Mean?
- What Does Deductive Mean?
- Inductive Reasoning Vs. Deductive Reasoning
Inductive and deductive are commonly used in the context of logic, reasoning, and science. Scientists use both inductive and deductive reasoning as part of the scientific method . Fictional detectives like Sherlock Holmes are famously associated with methods of deduction (though that’s often not what Holmes actually uses—more on that later). Some writing courses involve inductive and deductive essays.
But what’s the difference between inductive and deductive ? Broadly speaking, the difference involves whether the reasoning moves from the general to the specific or from the specific to the general. In this article, we’ll define each word in simple terms, provide several examples, and even quiz you on whether you can spot the difference.
⚡ Quick summary
Inductive reasoning (also called induction ) involves forming general theories from specific observations. Observing something happen repeatedly and concluding that it will happen again in the same way is an example of inductive reasoning. Deductive reasoning (also called deduction ) involves forming specific conclusions from general premises, as in: everyone in this class is an English major; Jesse is in this class; therefore, Jesse is an English major.
What does inductive mean?
Inductive is used to describe reasoning that involves using specific observations, such as observed patterns, to make a general conclusion. This method is sometimes called induction . Induction starts with a set of premises , based mainly on experience or experimental evidence. It uses those premises to generalize a conclusion .
For example, let’s say you go to a cafe every day for a month, and every day, the same person comes at exactly 11 am and orders a cappuccino. The specific observation is that this person has come to the cafe at the same time and ordered the same thing every day during the period observed. A general conclusion drawn from these premises could be that this person always comes to the cafe at the same time and orders the same thing.
While inductive reasoning can be useful, it’s prone to being flawed. That’s because conclusions drawn using induction go beyond the information contained in the premises. An inductive argument may be highly probable , but even if all the observations are accurate, it can lead to incorrect conclusions.
Follow up this discussion with a look at concurrent vs. consecutive .
In our basic example, there are a number of reasons why it may not be true that the person always comes at the same time and orders the same thing.
Additional observations of the same event happening in the same way increase the probability that the event will happen again in the same way, but you can never be completely certain that it will always continue to happen in the same way.
That’s why a theory reached via inductive reasoning should always be tested to see if it is correct or makes sense.
What else does inductive mean?
Inductive can also be used as a synonym for introductory . It’s also used in a more specific way to describe the scientific processes of electromagnetic and electrostatic induction —or things that function based on them.
What does deductive mean?
Deductive reasoning (also called deduction ) involves starting from a set of general premises and then drawing a specific conclusion that contains no more information than the premises themselves. Deductive reasoning is sometimes called deduction (note that deduction has other meanings in the contexts of mathematics and accounting).
Here’s an example of deductive reasoning: chickens are birds; all birds lay eggs; therefore, chickens lay eggs. Another way to think of it: if something is true of a general class (birds), then it is true of the members of the class (chickens).
Deductive reasoning can go wrong, of course, when you start with incorrect premises. For example, look where this first incorrect statement leads us: all animals that lay eggs are birds; snakes lay eggs; therefore, snakes are birds.
The scientific method can be described as deductive . You first formulate a hypothesis —an educated guess based on general premises (sometimes formed by inductive methods). Then you test the hypothesis with an experiment . Based on the results of the experiment, you can make a specific conclusion as to the accuracy of your hypothesis.
You may have deduced there are related terms to this topic. Start with a look at interpolation vs. extrapolation .
Deductive reasoning is popularly associated with detectives and solving mysteries. Most famously, Sherlock Holmes claimed to be among the world’s foremost practitioners of deduction , using it to solve how crimes had been committed (or impress people by guessing where they had been earlier in the day).
However, despite this association, reasoning that’s referred to as deduction in many stories is actually more like induction or a form of reasoning known as abduction , in which probable but uncertain conclusions are drawn based on known information.
Sherlock’s (and Arthur Conan Doyle ’s) use of the word deduction can instead be interpreted as a way (albeit imprecise) of referring to systematic reasoning in general.
What is the difference between inductive vs. deductive reasoning?
Inductive reasoning involves starting from specific premises and forming a general conclusion, while deductive reasoning involves using general premises to form a specific conclusion.
Conclusions reached via deductive reasoning cannot be incorrect if the premises are true. That’s because the conclusion doesn’t contain information that’s not in the premises. Unlike deductive reasoning, though, a conclusion reached via inductive reasoning goes beyond the information contained within the premises—it’s a generalization , and generalizations aren’t always accurate.
The best way to understand the difference between inductive and deductive reasoning is probably through examples.
Go Behind The Words!
- By clicking "Sign Up", you are accepting Dictionary.com Terms & Conditions and Privacy policies.
- Phone This field is for validation purposes and should be left unchanged.
Examples of inductive and deductive reasoning
Examples of inductive reasoning.
Premise: All known fish species in this genus have yellow fins. Conclusion: Any newly discovered species in the genus is likely to have yellow fins.
Premises: This volcano has erupted about every 500 years for the last 1 million years. It last erupted 499 years ago. Conclusion: It will erupt again soon.
Examples of deductive reasoning
Premises: All plants with rainbow berries are poisonous. This plant has rainbow berries. Conclusion: This plant is poisonous.
Premises: I am lactose intolerant. Lactose intolerant people get sick when they consume dairy. This milkshake contains dairy. Conclusion: I will get sick if I drink this milkshake.
Reason your way to the best score by taking our quiz on "inductive" vs. "deductive" reasoning!
Current Events
Science & Technology
Trending Words
[ ur -goh ]

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
5.15: Drawing Conclusions from Statistics
- Last updated
- Save as PDF
- Page ID 59855
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
Learning Objectives
- Describe the role of random sampling and random assignment in drawing cause-and-effect conclusions
Generalizability

One limitation to the study mentioned previously about the babies choosing the “helper” toy is that the conclusion only applies to the 16 infants in the study. We don’t know much about how those 16 infants were selected. Suppose we want to select a subset of individuals (a sample ) from a much larger group of individuals (the population ) in such a way that conclusions from the sample can be generalized to the larger population. This is the question faced by pollsters every day.
Example 1 : The General Social Survey (GSS) is a survey on societal trends conducted every other year in the United States. Based on a sample of about 2,000 adult Americans, researchers make claims about what percentage of the U.S. population consider themselves to be “liberal,” what percentage consider themselves “happy,” what percentage feel “rushed” in their daily lives, and many other issues. The key to making these claims about the larger population of all American adults lies in how the sample is selected. The goal is to select a sample that is representative of the population, and a common way to achieve this goal is to select a random sample that gives every member of the population an equal chance of being selected for the sample. In its simplest form, random sampling involves numbering every member of the population and then using a computer to randomly select the subset to be surveyed. Most polls don’t operate exactly like this, but they do use probability-based sampling methods to select individuals from nationally representative panels.
In 2004, the GSS reported that 817 of 977 respondents (or 83.6%) indicated that they always or sometimes feel rushed. This is a clear majority, but we again need to consider variation due to random sampling . Fortunately, we can use the same probability model we did in the previous example to investigate the probable size of this error. (Note, we can use the coin-tossing model when the actual population size is much, much larger than the sample size, as then we can still consider the probability to be the same for every individual in the sample.) This probability model predicts that the sample result will be within 3 percentage points of the population value (roughly 1 over the square root of the sample size, the margin of error ). A statistician would conclude, with 95% confidence, that between 80.6% and 86.6% of all adult Americans in 2004 would have responded that they sometimes or always feel rushed.
The key to the margin of error is that when we use a probability sampling method, we can make claims about how often (in the long run, with repeated random sampling) the sample result would fall within a certain distance from the unknown population value by chance (meaning by random sampling variation) alone. Conversely, non-random samples are often suspect to bias, meaning the sampling method systematically over-represents some segments of the population and under-represents others. We also still need to consider other sources of bias, such as individuals not responding honestly. These sources of error are not measured by the margin of error.
Query \(\PageIndex{1}\)
Query \(\PageIndex{2}\)
Cause and Effect
In many research studies, the primary question of interest concerns differences between groups. Then the question becomes how were the groups formed (e.g., selecting people who already drink coffee vs. those who don’t). In some studies, the researchers actively form the groups themselves. But then we have a similar question—could any differences we observe in the groups be an artifact of that group-formation process? Or maybe the difference we observe in the groups is so large that we can discount a “fluke” in the group-formation process as a reasonable explanation for what we find?
Example 2 : A psychology study investigated whether people tend to display more creativity when they are thinking about intrinsic (internal) or extrinsic (external) motivations (Ramsey & Schafer, 2002, based on a study by Amabile, 1985). The subjects were 47 people with extensive experience with creative writing. Subjects began by answering survey questions about either intrinsic motivations for writing (such as the pleasure of self-expression) or extrinsic motivations (such as public recognition). Then all subjects were instructed to write a haiku, and those poems were evaluated for creativity by a panel of judges. The researchers conjectured beforehand that subjects who were thinking about intrinsic motivations would display more creativity than subjects who were thinking about extrinsic motivations. The creativity scores from the 47 subjects in this study are displayed in Figure 2, where higher scores indicate more creativity.

In this example, the key question is whether the type of motivation affects creativity scores. In particular, do subjects who were asked about intrinsic motivations tend to have higher creativity scores than subjects who were asked about extrinsic motivations?
Figure 2 reveals that both motivation groups saw considerable variability in creativity scores, and these scores have considerable overlap between the groups. In other words, it’s certainly not always the case that those with extrinsic motivations have higher creativity than those with intrinsic motivations, but there may still be a statistical tendency in this direction. (Psychologist Keith Stanovich (2013) refers to people’s difficulties with thinking about such probabilistic tendencies as “the Achilles heel of human cognition.”)
The mean creativity score is 19.88 for the intrinsic group, compared to 15.74 for the extrinsic group, which supports the researchers’ conjecture. Yet comparing only the means of the two groups fails to consider the variability of creativity scores in the groups. We can measure variability with statistics using, for instance, the standard deviation: 5.25 for the extrinsic group and 4.40 for the intrinsic group. The standard deviations tell us that most of the creativity scores are within about 5 points of the mean score in each group. We see that the mean score for the intrinsic group lies within one standard deviation of the mean score for extrinsic group. So, although there is a tendency for the creativity scores to be higher in the intrinsic group, on average, the difference is not extremely large.
We again want to consider possible explanations for this difference. The study only involved individuals with extensive creative writing experience. Although this limits the population to which we can generalize, it does not explain why the mean creativity score was a bit larger for the intrinsic group than for the extrinsic group. Maybe women tend to receive higher creativity scores? Here is where we need to focus on how the individuals were assigned to the motivation groups. If only women were in the intrinsic motivation group and only men in the extrinsic group, then this would present a problem because we wouldn’t know if the intrinsic group did better because of the different type of motivation or because they were women. However, the researchers guarded against such a problem by randomly assigning the individuals to the motivation groups. Like flipping a coin, each individual was just as likely to be assigned to either type of motivation. Why is this helpful? Because this random assignment tends to balance out all the variables related to creativity we can think of, and even those we don’t think of in advance, between the two groups. So we should have a similar male/female split between the two groups; we should have a similar age distribution between the two groups; we should have a similar distribution of educational background between the two groups; and so on. Random assignment should produce groups that are as similar as possible except for the type of motivation, which presumably eliminates all those other variables as possible explanations for the observed tendency for higher scores in the intrinsic group.
But does this always work? No, so by “luck of the draw” the groups may be a little different prior to answering the motivation survey. So then the question is, is it possible that an unlucky random assignment is responsible for the observed difference in creativity scores between the groups? In other words, suppose each individual’s poem was going to get the same creativity score no matter which group they were assigned to, that the type of motivation in no way impacted their score. Then how often would the random-assignment process alone lead to a difference in mean creativity scores as large (or larger) than 19.88 – 15.74 = 4.14 points?
We again want to apply to a probability model to approximate a p-value , but this time the model will be a bit different. Think of writing everyone’s creativity scores on an index card, shuffling up the index cards, and then dealing out 23 to the extrinsic motivation group and 24 to the intrinsic motivation group, and finding the difference in the group means. We (better yet, the computer) can repeat this process over and over to see how often, when the scores don’t change, random assignment leads to a difference in means at least as large as 4.41. Figure 3 shows the results from 1,000 such hypothetical random assignments for these scores.

Only 2 of the 1,000 simulated random assignments produced a difference in group means of 4.41 or larger. In other words, the approximate p-value is 2/1000 = 0.002. This small p-value indicates that it would be very surprising for the random assignment process alone to produce such a large difference in group means. Therefore, as with Example 2, we have strong evidence that focusing on intrinsic motivations tends to increase creativity scores, as compared to thinking about extrinsic motivations.
Notice that the previous statement implies a cause-and-effect relationship between motivation and creativity score; is such a strong conclusion justified? Yes, because of the random assignment used in the study. That should have balanced out any other variables between the two groups, so now that the small p-value convinces us that the higher mean in the intrinsic group wasn’t just a coincidence, the only reasonable explanation left is the difference in the type of motivation. Can we generalize this conclusion to everyone? Not necessarily—we could cautiously generalize this conclusion to individuals with extensive experience in creative writing similar the individuals in this study, but we would still want to know more about how these individuals were selected to participate.

Statistical thinking involves the careful design of a study to collect meaningful data to answer a focused research question, detailed analysis of patterns in the data, and drawing conclusions that go beyond the observed data. Random sampling is paramount to generalizing results from our sample to a larger population, and random assignment is key to drawing cause-and-effect conclusions. With both kinds of randomness, probability models help us assess how much random variation we can expect in our results, in order to determine whether our results could happen by chance alone and to estimate a margin of error.
So where does this leave us with regard to the coffee study mentioned previously (the Freedman, Park, Abnet, Hollenbeck, & Sinha, 2012 found that men who drank at least six cups of coffee a day had a 10% lower chance of dying (women 15% lower) than those who drank none)? We can answer many of the questions:
- This was a 14-year study conducted by researchers at the National Cancer Institute.
- The results were published in the June issue of the New England Journal of Medicine , a respected, peer-reviewed journal.
- The study reviewed coffee habits of more than 402,000 people ages 50 to 71 from six states and two metropolitan areas. Those with cancer, heart disease, and stroke were excluded at the start of the study. Coffee consumption was assessed once at the start of the study.
- About 52,000 people died during the course of the study.
- People who drank between two and five cups of coffee daily showed a lower risk as well, but the amount of reduction increased for those drinking six or more cups.
- The sample sizes were fairly large and so the p-values are quite small, even though percent reduction in risk was not extremely large (dropping from a 12% chance to about 10%–11%).
- Whether coffee was caffeinated or decaffeinated did not appear to affect the results.
- This was an observational study, so no cause-and-effect conclusions can be drawn between coffee drinking and increased longevity, contrary to the impression conveyed by many news headlines about this study. In particular, it’s possible that those with chronic diseases don’t tend to drink coffee.
This study needs to be reviewed in the larger context of similar studies and consistency of results across studies, with the constant caution that this was not a randomized experiment. Whereas a statistical analysis can still “adjust” for other potential confounding variables, we are not yet convinced that researchers have identified them all or completely isolated why this decrease in death risk is evident. Researchers can now take the findings of this study and develop more focused studies that address new questions.
Explore these outside resources to learn more about applied statistics:
- Video about p-values: P-Value Extravaganza
- Interactive web applets for teaching and learning statistics
- Inter-university Consortium for Political and Social Research where you can find and analyze data.
- The Consortium for the Advancement of Undergraduate Statistics
Think It Over
- Find a recent research article in your field and answer the following: What was the primary research question? How were individuals selected to participate in the study? Were summary results provided? How strong is the evidence presented in favor or against the research question? Was random assignment used? Summarize the main conclusions from the study, addressing the issues of statistical significance, statistical confidence, generalizability, and cause and effect. Do you agree with the conclusions drawn from this study, based on the study design and the results presented?
- Is it reasonable to use a random sample of 1,000 individuals to draw conclusions about all U.S. adults? Explain why or why not.
cause-and-effect: related to whether we say one variable is causing changes in the other variable, versus other variables that may be related to these two variables.
generalizability : related to whether the results from the sample can be generalized to a larger population.
margin of error : the expected amount of random variation in a statistic; often defined for 95% confidence level.
population : a larger collection of individuals that we would like to generalize our results to.
p-value : the probability of observing a particular outcome in a sample, or more extreme, under a conjecture about the larger population or process.
random assignment : using a probability-based method to divide a sample into treatment groups.
random sampling : using a probability-based method to select a subset of individuals for the sample from the population.
sample : the collection of individuals on which we collect data.
Licenses and Attributions
CC licensed content, Original
- Modification, adaptation, and original content. Authored by : Pat Carroll and Lumen Learning. Provided by : Lumen Learning. License : CC BY: Attribution
- Statistical Thinking. Authored by : Beth Chance and Allan Rossman, California Polytechnic State University, San Luis Obispo. Provided by : Noba. Located at : http://nobaproject.com/modules/statistical-thinking . License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
- The Replication Crisis. Authored by : Colin Thomas William. Provided by : Ivy Tech Community College. License : CC BY: Attribution

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Overview of the Scientific Method
13 Drawing Conclusions and Reporting the Results
Learning objectives.
- Identify the conclusions researchers can make based on the outcome of their studies.
- Describe why scientists avoid the term “scientific proof.”
- Explain the different ways that scientists share their findings.
Drawing Conclusions
Since statistics are probabilistic in nature and findings can reflect type I or type II errors, we cannot use the results of a single study to conclude with certainty that a theory is true. Rather theories are supported, refuted, or modified based on the results of research.
If the results are statistically significant and consistent with the hypothesis and the theory that was used to generate the hypothesis, then researchers can conclude that the theory is supported. Not only did the theory make an accurate prediction, but there is now a new phenomenon that the theory accounts for. If a hypothesis is disconfirmed in a systematic empirical study, then the theory has been weakened. It made an inaccurate prediction, and there is now a new phenomenon that it does not account for.
Although this seems straightforward, there are some complications. First, confirming a hypothesis can strengthen a theory but it can never prove a theory. In fact, scientists tend to avoid the word “prove” when talking and writing about theories. One reason for this avoidance is that the result may reflect a type I error. Another reason for this avoidance is that there may be other plausible theories that imply the same hypothesis, which means that confirming the hypothesis strengthens all those theories equally. A third reason is that it is always possible that another test of the hypothesis or a test of a new hypothesis derived from the theory will be disconfirmed. This difficulty is a version of the famous philosophical “problem of induction.” One cannot definitively prove a general principle (e.g., “All swans are white.”) just by observing confirming cases (e.g., white swans)—no matter how many. It is always possible that a disconfirming case (e.g., a black swan) will eventually come along. For these reasons, scientists tend to think of theories—even highly successful ones—as subject to revision based on new and unexpected observations.
A second complication has to do with what it means when a hypothesis is disconfirmed. According to the strictest version of the hypothetico-deductive method, disconfirming a hypothesis disproves the theory it was derived from. In formal logic, the premises “if A then B ” and “not B ” necessarily lead to the conclusion “not A .” If A is the theory and B is the hypothesis (“if A then B ”), then disconfirming the hypothesis (“not B ”) must mean that the theory is incorrect (“not A ”). In practice, however, scientists do not give up on their theories so easily. One reason is that one disconfirmed hypothesis could be a missed opportunity (the result of a type II error) or it could be the result of a faulty research design. Perhaps the researcher did not successfully manipulate the independent variable or measure the dependent variable.
A disconfirmed hypothesis could also mean that some unstated but relatively minor assumption of the theory was not met. For example, if Zajonc had failed to find social facilitation in cockroaches, he could have concluded that drive theory is still correct but it applies only to animals with sufficiently complex nervous systems. That is, the evidence from a study can be used to modify a theory. This practice does not mean that researchers are free to ignore disconfirmations of their theories. If they cannot improve their research designs or modify their theories to account for repeated disconfirmations, then they eventually must abandon their theories and replace them with ones that are more successful.
The bottom line here is that because statistics are probabilistic in nature and because all research studies have flaws there is no such thing as scientific proof, there is only scientific evidence.
Reporting the Results
The final step in the research process involves reporting the results. As described in the section on Reviewing the Research Literature in this chapter, results are typically reported in peer-reviewed journal articles and at conferences.
The most prestigious way to report one’s findings is by writing a manuscript and having it published in a peer-reviewed scientific journal. Manuscripts published in psychology journals typically must adhere to the writing style of the American Psychological Association (APA style). You will likely be learning the major elements of this writing style in this course.
Another way to report findings is by writing a book chapter that is published in an edited book. Preferably the editor of the book puts the chapter through peer review but this is not always the case and some scientists are invited by editors to write book chapters.
A fun way to disseminate findings is to give a presentation at a conference. This can either be done as an oral presentation or a poster presentation. Oral presentations involve getting up in front of an audience of fellow scientists and giving a talk that might last anywhere from 10 minutes to 1 hour (depending on the conference) and then fielding questions from the audience. Alternatively, poster presentations involve summarizing the study on a large poster that provides a brief overview of the purpose, methods, results, and discussion. The presenter stands by their poster for an hour or two and discusses it with people who pass by. Presenting one’s work at a conference is a great way to get feedback from one’s peers before attempting to undergo the more rigorous peer-review process involved in publishing a journal article.
Research Methods in Psychology Copyright © 2019 by Rajiv S. Jhangiani, I-Chant A. Chiang, Carrie Cuttler, & Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Online ordering is currently unavailable due to technical issues. We apologise for any delays responding to customers while we resolve this. For further updates please visit our website: https://www.cambridge.org/news-and-insights/technical-incident Due to planned maintenance there will be periods of time where the website may be unavailable. We apologise for any inconvenience.
We use cookies to distinguish you from other users and to provide you with a better experience on our websites. Close this message to accept cookies or find out how to manage your cookie settings .
Login Alert
- > How to Do Research
- > Draw conclusions and make recommendations

Book contents
- Frontmatter
- Acknowledgements
- Introduction: Types of research
- Part 1 The research process
- 1 Develop the research objectives
- 2 Design and plan the study
- 3 Write the proposal
- 4 Obtain financial support for the research
- 5 Manage the research
- 6 Draw conclusions and make recommendations
- 7 Write the report
- 8 Disseminate the results
- Part 2 Methods
- Appendix The market for information professionals: A proposal from the Policy Studies Institute
6 - Draw conclusions and make recommendations
from Part 1 - The research process
Published online by Cambridge University Press: 09 June 2018
This is the point everything has been leading up to. Having carried out the research and marshalled all the evidence, you are now faced with the problem of making sense of it all. Here you need to distinguish clearly between three different things: results, conclusions and recommendations.
Results are what you have found through the research. They are more than just the raw data that you have collected. They are the processed findings of the work – what you have been analysing and striving to understand. In total, the results form the picture that you have uncovered through your research. Results are neutral. They clearly depend on the nature of the questions asked but, given a particular set of questions, the results should not be contentious – there should be no debate about whether or not 63 per cent of respondents said ‘yes’ to question 16.
When you consider the results you can draw conclusions based on them. These are less neutral as you are putting your interpretation on the results and thus introducing a degree of subjectivity. Some research is simply descriptive – the final report merely presents the results. In most cases, though, you will want to interpret them, saying what they mean for you – drawing conclusions.
These conclusions might arise from a comparison between your results and the findings of other studies. They will, almost certainly, be developed with reference to the aim and objectives of the research. While there will be no debate over the results, the conclusions could well be contentious. Someone else might interpret the results differently, arriving at different conclusions. For this reason you need to support your conclusions with structured, logical reasoning.
Having drawn your conclusions you can then make recommendations. These should flow from your conclusions. They are suggestions about action that might be taken by people or organizations in the light of the conclusions that you have drawn from the results of the research. Like the conclusions, the recommendations may be open to debate. You may feel that, on the basis of your conclusions, the organization you have been studying should do this, that or the other.
Access options
Save book to kindle.
To save this book to your Kindle, first ensure [email protected] is added to your Approved Personal Document E-mail List under your Personal Document Settings on the Manage Your Content and Devices page of your Amazon account. Then enter the ‘name’ part of your Kindle email address below. Find out more about saving to your Kindle .
Note you can select to save to either the @free.kindle.com or @kindle.com variations. ‘@free.kindle.com’ emails are free but can only be saved to your device when it is connected to wi-fi. ‘@kindle.com’ emails can be delivered even when you are not connected to wi-fi, but note that service fees apply.
Find out more about the Kindle Personal Document Service .
- Draw conclusions and make recommendations
- Book: How to Do Research
- Online publication: 09 June 2018
- Chapter DOI: https://doi.org/10.29085/9781856049825.007
Save book to Dropbox
To save content items to your account, please confirm that you agree to abide by our usage policies. If this is the first time you use this feature, you will be asked to authorise Cambridge Core to connect with your account. Find out more about saving content to Dropbox .
Save book to Google Drive
To save content items to your account, please confirm that you agree to abide by our usage policies. If this is the first time you use this feature, you will be asked to authorise Cambridge Core to connect with your account. Find out more about saving content to Google Drive .
KPMG Personalization

- One year of the Supply Chain Act: interim results and practical tips
What conclusions can be drawn from the LkSG inspections in companies? We clarify.
- Share Share close
- 1000 Save this article to my library
- Go to bottom of page
- Home ›
- Insights ›
To what extent are companies complying with the requirements of the Supply Chain Due Diligence Act (LkSG) - and which aspects may need to be adjusted in particular? The Federal Office of Economics and Export Control (BAFA), which is responsible for monitoring and enforcing the LkSG, has taken stock one year after the new regulations came into force (1 January 2023). We analyse the results, provide recommendations for compliance and highlight the crucial role that third-party risk management can play.
LkSG inspections: Positive conclusion - but also room for improvement
The good news is that BAFA considers the implementation of measures required by the LkSG to be largely successful. Nevertheless, BAFA also identified room for improvement with regard to the fulfilment of some due diligence obligations.
Firstly, when implementing the requirements for the complaints procedure, the accessibility, comprehensibility, visibility and involvement of potentially affected parties in the design of the complaints procedure were criticised. Secondly, BAFA found that some companies transfer their due diligence obligations to suppliers through contractual obligations. In this context, BAFA emphasised that this is inadmissible.
Verena Hinze
Partnerin, Audit, Forensic
KPMG AG Wirtschaftsprüfungsgesellschaft
Violations of the LkSG are not only subject to high fines
As long as there is no standardised regulation at European level, many companies based in Germany associate the provisions of the LkSG with a disadvantage in terms of their own competitiveness in a European comparison. Critics also point out that the LkSG entails too much bureaucracy. Furthermore, the protection of human rights is already ensured by existing measures and it is impossible for individual companies to scrutinise the entire global supply chain.
All of these points are incentives to disregard or disregard the provisions of the LkSG in business practice. However, neglecting due diligence obligations under the LkSG harbours serious risks. Fines of up to 800,000 euros can be imposed for violations of due diligence obligations under the LkSG. For legal entities and associations of persons with an average annual turnover of 400 million euros, a fine of up to 2 per cent of the average annual turnover is also possible. In addition, the company may lose out on profits, as a breach of obligations can also result in the company being excluded from public contracts for several years. Potential reputational risks should also not be underestimated.
Comply with LkSG requirements: Five key aspects for practical implementation
The LkSG requires the establishment of an appropriate internal company complaints procedure. Companies should first take into account the BAFA's guidelines for support in implementing the complaints procedure. It is also advisable to examine the bundling of existing complaints channels (e.g. in accordance with the Whistleblower Protection Act).
When complying with the law, the principle of appropriateness must be taken into account, according to which a company does not have to implement all conceivable measures, but only those that can reasonably be expected of it. Appropriateness can be determined on the basis of various criteria, such as the nature and scope of the business activity, the company's ability to influence the risk, the severity of the breach and the contribution to causing the risk.
BAFA recommends using the definition in the UN Guiding Principles to implement measures relating to the accessibility of the complaints procedure.
The following questions should be used to overcome implementation weaknesses with regard to the accessibility, comprehensibility and visibility of the complaints procedure:
a. Have all target groups been considered and is there actual access for all target groups?
b. Is the procedure known?
c. Have possible language barriers been removed?
d. Are there any other barriers that could make access to the complaints procedure more difficult?
Consideration should be given to involving stakeholders from target groups in the design of the complaints procedure in order to recognise barriers to access at an early stage.
When transferring obligations, companies should also bear in mind that measures that obviously overburden a supplier are regularly not appropriate and may therefore be ineffective.
Blanket references to a contractual assurance of freedom from risk are not a suitable substitute for a risk analysis. Obligated companies must therefore continue to carry out an independent risk analysis and set up their own complaints procedure.
Further complex tasks
In addition to the weaknesses identified by the BAFA in the implementation of measures to fulfil the LkSG requirements, the time required for the reporting and documentation obligations of the LkSG represents a major challenge for many companies.
Monitoring third parties and responding appropriately can also be a major challenge for a company. In integrated business partner management, the risks under the LkSG are also taken into account. They are incorporated into general risk management and minimisation and must be assessed as part of the compliance and legal risks in the risk management system. The management of the various risk types is facilitated by a Third Party Risk Management (TPRM) system.
Other complex tasks
In addition to the weaknesses identified by BAFA in the implementation of measures to fulfil the LkSG requirements, the time required for the reporting and documentation obligations of the LkSG represents a major challenge for many companies.
TPRM support in the context of the LkSG
A TPRM makes it possible to identify, assess, monitor and manage risks within the supply chain. In doing so, the TPRM ensures compliance with various regulatory ESG provisions, such as those of the LkSG. Continuous monitoring, a structured assessment of third parties and the definition of reporting channels and escalation levels can ensure that the company fulfils the LkSG requirements.
The advantage of an integrated solution is that numerous modules are already available for new regulatory requirements, such as the Deforestation Ordinance or the extension of requirements to the downstream activity chain, and no new processes need to be set up.
In addition to fulfilling the LkSG requirements, the implementation of a TPRM also offers other advantages and added value for a company:
- Decision-making: A structured and continuous supplier assessment and the potential risks associated with this enables the company to make informed decisions about which suppliers are possible to work with without conflicting with applicable legal requirements.
- Transparency: Transparency in the supply chain can be increased through continuous monitoring and a structured assessment of third parties.
- Reputation: An effective and robust TPRM helps to enhance reputation.
- Early detection: By continuously monitoring third parties, potential risks within the supply chain can be recognised and mitigated at an early stage before they result in financial or reputational damage for the company.
- Effort: The time and financial effort required by companies to fulfil the LkSG reporting and documentation obligations can also be reduced by an efficient TPRM. Within the TPRM, it is possible to create automated standardised reports and display key findings via dashboards
A TPRM tailored to the company makes it possible to organise cooperation with business partners in such a way that the requirements of the LkSG are met. In this way, violations can be prevented, the company's reputation protected and legal consequences avoided.
On 15 March 2024, the member states of the European Union agreed on the Corporate Sustainability Due Diligence Directive (CSDDD) and thus on a European Supply Chain Directive.
Even though some of the original requirements of the CSDDD were watered down in the member states' compromise, the directive is stricter in some respects compared to the LkSG. With regard to the due diligence obligations, in contrast to the LkSG, the CSDD does not only apply to the upstream supply chain, but also to the chain of activities and therefore, in certain cases, to the downstream supply chain. In contrast to the LkSG, the sanctions are also more significant. Fines of up to 5 per cent of global net turnover will be possible in the event of violations. In this context, the CSDDD also introduces civil liability, which could pose a significant threat to companies. Those affected - including trade unions and NGOs - will then be able to assert their claims against the company within five years.

Die Lieferketten sollen nachhaltiger und transparenter werden. Was das bedeutet und wie Unternehmen die neuen Anforderungen umsetzen können.
Wie Unternehmen ihre Lieferketten transparent und nachhaltig gestalten können
More From Forbes
Rock art of 130-foot snake could be world’s biggest prehistoric drawing.
- Share to Facebook
- Share to Twitter
- Share to Linkedin
The tiny humans in this photo highlight the magnitude of the snake body in this Colombian rock art. ... [+]
At least 2,000 years ago, people living along South America’s Orinoco River carved symbols into rocks—human figures, geometric shapes, birds, centipedes. And snakes, lots of giant snakes. One such slithering subject measures more than 130 feet long, which likely makes it the largest rock art ever discovered.
But it’s not just the size of that and other serpents etched near the Orinoco that’s captivated scientists. It’s why they were drawn at such a scale in the first place. Their conclusion: The creatures, believed to be boa constrictors or anacondas, probably functioned as physical markers that could be seen from great distances.
“We believe the engravings could have been used by prehistoric groups as a way to mark territory, letting people know that this is where they live and that appropriate behavior is expected,” said Philip Riris, a lecturer in archaeology at Bouremouth University in the U.K. and lead author of the study according to researchers who analyzed the dominant snake motifs at a series of rock art sites, published Tuesday in the journal Antiquity . Riris and his fellow researchers want to better understand the connection between prehistoric art practices and indigenous world views.
Snakes, which feature prominently in indigenous creation myths and cosmologies across northern South America, are generally interpreted as threatening, Riris added in a statement. “So where the rock art is located could be a signal that these are places where you need to mind your manners,” he said.
An artistic impression of a mythical snake traversing the Orinoco River. Serpents figure heavily ... [+] into indigenous creations myths and cosmology.
Godzilla Minus One Dethroned In Netflix s Top 10 List By A New Movie
‘a very big opportunity’—crypto suddenly braced for a ‘tremendous’ china earthquake after bitcoin, ethereum and xrp price boom, still no one has beaten destiny 2 s final shape raid now its longest ever update someone did.
Prehistoric rock art, which has been discovered in Australia, Borneo, Brazil, India, South Africa, Amazonian rainforests, among other places, has much to reveal about our predecessors, including insights into their levels of sophistication , the objects of their fascination and astronomical phenomena they may have witnessed. One stone carving from thousands of years back appears to depict humans’ amazement at a supernova .
The large-scale rock art described in the Antiquity study appears in a region spanning the Colombian-Venzuelan border called the Atures Rapids. Other archaeological finds show the area would have been key to prehistoric trade and travel.
“This means it would have been a key point of contact, and so making your mark could have been all the more important because of that, marking out your local identity and letting visitors know that you are here,” study co-author José Oliver, a University College specialist in Latin American archaeology, said in a statement.
Adam Brumm, an archaeology professor at Australia’s Griffith University who was not involved with the Orinico research, agrees with the study’s hypothesis that the gigantic snakes shallowly etched into the riverside rocks likely reflect indigenous creation myths and cosmology. He says their location near the river could also reflect a belief in the “rainbow serpent,” an immortal ancestral being that appears around bodies of water in Aboriginal and other ancient mythology.
The association between snakes and water “is thought to come from humans observing rainbows appearing at waterfalls, rapids, deep pools and so on and interpreting these arching, snake-like forms as supernatural serpents of enormous size and power that dwelt in those water sources,” Brumm who has himself studied prehistoric rock art , said in an interview. “I would not be surprised to find that indigenous creation myths from the Orinoco River area contain references to this symbolic interconnection between rainbows and water and cultural images of huge snakes.”
An enhanced image of monumental rock art on Cerro Pintado in Venezuela shows a huge snake surrounded ... [+] by other symbols.
The study labels the rock art it describes as “monumental.” That means it’s really, really big, yes, but monumental is also archaelogical parlance for rock art more than 13 feet wide or high. Since 2015, Riris and fellow researchers have mapped 14 monumental rock art sites using DSLR cameras and drones. The Orinico engravings are “several times larger” than other massive rock art found in Arabia, Norway and Niger, Riris said in an email.
While it’s hard to date rock engravings , the motifs that appear in the Orinoco carvings show up in smaller rock art from around 2,000 years ago, indicating a shared symbolic vocabulary. One zigzagging snake with horns mimics a serpent seen on a ceramic vessel from around the same place and time.
The researchers say it’s crucial that these and other monumental rock art sites are preserved as visual records of the past. They’ve registered the sites with Colombian and Venezuelan national heritage bodies.
“Some of the communities around the sites feel a very strong connection to the rock art,” study co-author Natalia Lozada Mendieta of Universidad de los Andes, said in a statement. “Moving forward, we believe they are likely to be the best custodians.”
A north-facing view of the Orinoco River from the Colombian side, taken from the summit of a granite ... [+] inselberg.

- Editorial Standards
- Reprints & Permissions
Join The Conversation
One Community. Many Voices. Create a free account to share your thoughts.
Forbes Community Guidelines
Our community is about connecting people through open and thoughtful conversations. We want our readers to share their views and exchange ideas and facts in a safe space.
In order to do so, please follow the posting rules in our site's Terms of Service. We've summarized some of those key rules below. Simply put, keep it civil.
Your post will be rejected if we notice that it seems to contain:
- False or intentionally out-of-context or misleading information
- Insults, profanity, incoherent, obscene or inflammatory language or threats of any kind
- Attacks on the identity of other commenters or the article's author
- Content that otherwise violates our site's terms.
User accounts will be blocked if we notice or believe that users are engaged in:
- Continuous attempts to re-post comments that have been previously moderated/rejected
- Racist, sexist, homophobic or other discriminatory comments
- Attempts or tactics that put the site security at risk
- Actions that otherwise violate our site's terms.
So, how can you be a power user?
- Stay on topic and share your insights
- Feel free to be clear and thoughtful to get your point across
- ‘Like’ or ‘Dislike’ to show your point of view.
- Protect your community.
- Use the report tool to alert us when someone breaks the rules.
Thanks for reading our community guidelines. Please read the full list of posting rules found in our site's Terms of Service.
The U.S. announced it. Israel kind of rejected it. What is Biden's Gaza cease-fire plan?
Everything netanyahu has said about the plan has been a mixed signal, and agreeing to it risks a revolt by ultra-nationalists who could topple his government's ruling coalition..

It was sold as an Israeli-endorsed deal. But it was President Joe Biden − whose support for Israel in the Gaza war has tarnished his reputation with Arab American voters − who announced it.
It was described as a cease-fire proposal supported by Israeli Prime Minister Benjamin Netanyahu. Yet everything Netanyahu subsequently said about it was a mixed signal, and agreeing to it risks a revolt by ultra-nationalists who could topple his government's ruling coalition, leaving him vulnerable to legal woes the war has obscured.
And it contained no clear identifiable solution to the one fundamental issue that both Israel and Hamas have appeared to be completely inflexible on after eight months of fighting: whether any cease-fire plan would be permanent and involve a complete withdrawal of Israel's military from Gaza.
The White House has said it has "every expectation" that Israel will, if Hamas does, accept the U.S.-backed cease-fire plan that Biden unveiled in a surprise speech last week. Hamas has yet to sign on to the deal. Here's what the plan involves and some of the calculations Netanyahu may have to make in deciding, or not, to back it.
What was in the Biden truce proposal?
Biden said the truce proposal was first outlined by Israel and then passed to mediators who brought it to Hamas. It contained three distinct phases. The first phase of the deal, characterized as a "full and complete cease-fire," would last six weeks. During this time, Israel's military would withdraw from Gaza's densely populated areas and release an unspecified number of hostages, including women, the elderly, the wounded, as well as the remains of killed hostages. In return, Israel would release hundreds of Palestinian prisoners. Humanitarian assistance to Gaza would surge during this first phase, with 600 trucks being allowed into the enclave each day.
The second phase of the deal, as described by Biden, would see all the remaining hostages , including male soldiers, held by Hamas released. At the same time, Israel would withdraw its forces from Gaza. The third phase of the agreement would involve the reconstruction of Gaza . The war has resulted in massive devastation to Gaza's infrastructure. The proposal did not specify who would run Gaza during the third phase, or afterward. A previous agreement reached by Israel and Hamas, in November, allowed for a pause in fighting in exchange for the release of Israeli hostages and Palestinian prisoners. The truce broke down after four days.
30,000-plus lives lost: Visualizing the death and destruction of Israel's war in Gaza
Was this Israel's idea? Or the United States'?
Ophir Falk, Netanyahu's chief foreign policy adviser, told the Sunday Times (of London) the deal as outlined by Biden was something Israel previously drafted and agreed to. But he also described Biden's announcement as a "political speech," an apparent reference to Biden's poor standing with Arab American and other voters from his political base who want to see the war in Gaza end as quickly as possible.
Falk said it was "not a good deal," as outlined.
He added that there were "a lot of details to be worked out."
For his part, Netanyahu, in two carefully worded statements released in the days after Biden's announcement, said "Israel's conditions for ending the war have not changed: the destruction of Hamas's military and governing capabilities, the freeing of all hostages and ensuring that Gaza no longer poses a threat to Israel."
A 'nonstarter'?
Netanyahu said Israel would not agree to any deal before those conditions were met. A "nonstarter," he called it.
So was this a case of Netanyahu floating a plan to Biden that Israel's leader was never actually willing to accept?
Ami Pedahzur, an expert on Israeli politics and security who teaches at the University of Haifa, said he had never before encountered a time in Israeli politics when there was "so much spin" going on in terms of teasing the government's thinking on the war and how to end it. However, he said he did not think Netanyahu was "playing games" by detailing a potential cease-fire plan to the U.S. that appears to cross some of his own red lines.
Pedahzur said one plausible explanation was that Netanyahu asked the U.S. to "put it forward to see what response" it would generate for his domestic audience, where polls show overwhelming support for any action that would lead to the freeing of hostages. Netanyahu faces growing pressure to secure the hostage's release from their families, and to end the war because of its impact on Palestinians. The International Court of Justice has ordered Israel to halt its assault on Rafah, Gaza's southernmost city. The International Criminal Court has applied for an arrest warrant for Netanyahu − as well as Hamas' leader − for alleged war crimes.
The White House has also dangled a threat to withdraw U.S. arms from Israel.
Putin, Joseph Kony, Gaddafi's son: Rogue's gallery of international court fugitives
Still, Nimrod Novik, a foreign policy fellow at Israel Policy Forum, a think tank, and a onetime adviser to Israel's late prime minister, Shimon Peres, had a different interpretation of Netanyahu's motivations. He said that "those of us who have been following Netanyahu for decades have seen this mode of operation before."
Novik said when faced with political obstacles and "narrowing" options Netanyahu almost always "trusts the second party will be obstructionist." In other words, Israel's leader is counting on Hamas rejecting the Biden-announced plan, Novik believes. He said in the event Hamas comes back with a positive reaction to the proposal "then we'll be at a fork in the road: either Netanyahu yields to the extremists in his government, in which case there will be a dramatic surge in public protests in Israel to the point where the country could be shut down."
Alternatively, should he go for the Biden initiative, triggering the fall of his government, it is possible that a coalition of centrist opposition parties could come to Netanyahu's aid to keep him in power "in the service of the national interest," Novik said. Though that would involve Netanyahu committing to "a sea change in our Palestinian policy, a permanent cease-fire, normalization of ties with Saudi Arabia, scrapping judicial reforms" and other measures that Israel's ultra-nationalists have opposed with his consent.
What happens to Netanyahu if he loses the right-wing?
The White House has denied that there are any "gaps" between what Biden outlined on Friday and what Netanyahu's government put forward. "We're confident that it accurately reflects that proposal − a proposal that we worked with the Israelis on," U.S. national security spokesman John Kirby said Monday.
However, Israel's National Security Minister Itamar Ben-Gvir and Finance Minister Bezalel Smotrich both described the plan unveiled by Biden as "reckless" and tantamount to surrendering to Hamas. They have threatened, if Netanyahu accepts it, to withdraw their parties' support for him in Israel's Knesset, or Parliament.
If that happens Netanyahu's government could collapse, potentially triggering an election and dislodging him from power and exposing Netanyahu to face a litany of bribery, fraud and breach of trust charges − all accusations he denies − that his time in office has provided a degree of shelter from.
It's also possible that a coalition of centrist opposition parties could come to Netanyahu's aid to keep him in power "in the service of the national interest," Novik said, though that would involve Netanyahu committing to "a sea change in our Palestinian policy, a permanent cease-fire, normalization of ties with Saudi Arabia, scrapping judicial reforms" and other measures that Israel's ultra-nationalists have opposed with his consent.
A threat by Benny Gantz, a retired army general and political centrist, to leave Netanyahu's wartime Cabinet by June 8 if no plan for a post-war Gaza materializes would mean Netanyahu is further reliant on his far-right allies.
Related: Exclusive: Concern over Biden's stance on Israel-Hamas war rattles high-profile campaign donors
An idea for a deal. Now what?
Still, Simcha Rothman, a lawyer and member of the Knesset from the far-right Religious Zionist Party, disputed the idea that Biden's announcement of the plan in any way applies pressure to Israel eight months into the war.
"If it's the Israeli offer he spoke about (on Friday), then why would he apply pressure to Israel to accept its own offer. That makes no sense," said Rothman. "I see this as simply a political act, and not as an act that will help bring back any hostage any sooner. It's a big mistake, to say the least," he said of Biden's intervention.
Rothman said he suspected Biden was "trying to interfere in Israel's politics, which is unacceptable."
He sidestepped a question on what would happen if Hamas were to accept the plan as revealed by Biden. Rothman's comments came as Biden said in an interview Tuesday that there is "every reason" to think Netanyahu is prolonging Israel's war against Hamas in Gaza for his own political gain and self-preservation.
"I'm not going to comment on that. There is every reason for people to draw that conclusion," Biden said.
Biden used the interview, with Time magazine, offer qualified support for Netanyahu. U.S. congressional leaders are working to finalize a date for Netanyahu to deliver a joint address to Congress, an event that could draw protests. Netanyahu addressed Congress in 2015, when he voiced concerns over a nuclear deal with Iran.
Yotam Eyal, an Israeli lawyer who lives on land in the West Bank claimed by Palestinians, nevertheless said he too was against any deal with Hamas for now. "It's not about the idea of a deal, it's more about the idea that we don't have a good deal that will stop Hamas. If we keep Hamas in power in Gaza we'll get Oct. 7. again and again and again," Eyal said of the day that saw Israelis attacked, murdered and kidnapped on Israel's southern border.
Sami Omar Zidan , a Gazan currently living in temporary housing in Cairo, Egypt, where he evacuated with his wife and daughter about a month ago, before Israel completely closed the border amid its assault on Rafah, said he also only sees endless cycles of violence. Deal or not, he said, he's not sure Israel's war will ever end.
"No matter what happens,'' he said, ''Israel never stops . ''
COMMENTS
When writing the conclusion of a hypothesis test, we typically include: Whether we reject or fail to reject the null hypothesis. The significance level. A short explanation in the context of the hypothesis test. For example, we would write: We reject the null hypothesis at the 5% significance level.
What conclusions can be drawn from a hypothesis? A. If evidence supports the hypothesis, the hypothesis is considered scientific theory. B. If evidence rejects the hypothesis, then it can be removed from the list of possible answers to the original question. C. If data support the hypothesis, then it is accepted and further testing is not ...
The scientific method. At the core of biology and other sciences lies a problem-solving approach called the scientific method. The scientific method has five basic steps, plus one feedback step: Make an observation. Ask a question. Form a hypothesis, or testable explanation. Make a prediction based on the hypothesis.
Finally, you've reached your conclusion. Now it is time to summarize and explain what happened in your experiment. Your conclusion should answer the question posed in step one. Your conclusion should be based solely on your results. Think about the following questions: Was your hypothesis correct?
A second complication has to do with what it means when a hypothesis is disconfirmed. According to the strictest version of the hypothetico-deductive method, disconfirming a hypothesis disproves the theory it was derived from. In formal logic, the premises "if A then B " and "not B " necessarily lead to the conclusion "not A."
Begin with a clear statement of the principal findings. This will reinforce the main take-away for the reader and set up the rest of the discussion. Explain why the outcomes of your study are important to the reader. Discuss the implications of your findings realistically based on previous literature, highlighting both the strengths and ...
Draw Conclusions: Using the analysis, conclude whether the hypothesis was correct or not, and why. ... Looking at the funding source of many studies can elucidate what conclusions were drawn and why.
Developing a hypothesis (with example) Step 1. Ask a question. Writing a hypothesis begins with a research question that you want to answer. The question should be focused, specific, and researchable within the constraints of your project. Example: Research question.
Step 7: Based on steps 5 and 6, draw a conclusion about H0. If the F\calculated F \calculated from the data is larger than the Fα F α, then you are in the rejection region and you can reject the null hypothesis with (1 − α) ( 1 − α) level of confidence. Note that modern statistical software condenses steps 6 and 7 by providing a p p -value.
The smaller the p-value, the more unlikely the outcome, and the stronger the evidence is against the null hypothesis. We would reject the null hypothesis if the evidence is strongly against it. Draw a graph that shows the p-value. The hypothesis test is easier to perform if you use a graph because you see the problem more clearly.
The Six Steps in Hypothesis Testing can be inserted into steps 5 and 6 of the Scienti c method. Let's number the six steps in hypothesis testing to emphasize this relationship: ... One collects data from a sample and uses the sample results to draw conclusions about the population. Inference is necessary whenever it is unrealistic to perform ...
Onward! We use p -values to make conclusions in significance testing. More specifically, we compare the p -value to a significance level α to make conclusions about our hypotheses. If the p -value is lower than the significance level we chose, then we reject the null hypothesis H 0 in favor of the alternative hypothesis H a .
The conclusion drawn from a two-tailed confidence interval is usually the same as the conclusion drawn from a two-tailed hypothesis test. In other words, if the the 95% confidence interval contains the hypothesized parameter, then a hypothesis test at the 0.05 \(\alpha\) level will almost always fail to reject the null hypothesis.
The conclusions that we can draw form a hypothesis test are based on the comparison between the observed result and the null hypothesis. For example, in the Monday breakups study, we concluded: The observed result is not compatible with the null hypothesis. This suggests that breakups may be more likely to be reported on Monday.
The scientific method can be described as deductive. You first formulate a hypothesis—an educated guess based on general premises (sometimes formed by inductive methods). Then you test the hypothesis with an experiment. Based on the results of the experiment, you can make a specific conclusion as to the accuracy of your hypothesis.
Researchers employ the scientific method that involves a great deal of statistical thinking: generate a hypothesis -> design a study to test that hypothesis -> conduct the study -> analyze the data -> report the results. [Image: widdowquinn] ... so no cause-and-effect conclusions can be drawn between coffee drinking and increased ...
In hypothesis testing if the null hypothesis is rejected, a. no conclusions can be drawn from the test b. the alternative hypothesis must also be rejected c. the data must have been accumulated incorrectly d. None of the other answers are correct.
The conclusion supports the hypothesis because it shows that particles close particle A particle is a single piece of matter from an element or a compound, which is too small to be seen. Particles ...
A second complication has to do with what it means when a hypothesis is disconfirmed. According to the strictest version of the hypothetico-deductive method, disconfirming a hypothesis disproves the theory it was derived from. In formal logic, the premises "if A then B " and "not B " necessarily lead to the conclusion "not A."
Experimental design is the process of carrying out research in an objective and controlled fashion. so that precision is maximized and specific conclusions can be drawn regarding a hypothesis ...
1. A decision, judgment, or opinion reached by reasoning 2. Facts from which conclusions can be drawn; information 3. A careful search; detailed or careful examination 4. An idea or theory which seems to be correct based on evidence or observation 5. Recorded information through reason and logic; provides support to validate or falsify a theory or hypothesis 6.
For this reason you need to support your conclusions with structured, logical reasoning. Having drawn your conclusions you can then make recommendations. These should flow from your conclusions. They are suggestions about action that might be taken by people or organizations in the light of the conclusions that you have drawn from the results ...
what conclusions can be drawn about a hypothesis following a single experiment. hypothesis can support or reject the findings of one experiment. T or F scientists alone should address ethical issues that arise. F. test group vs a control group.
The Federal Office of Economics and Export Control (BAFA), which is responsible for monitoring and enforcing the LkSG, has taken stock one year after the new regulations came into force (1 January 2023). We analyse the results, provide recommendations for compliance and highlight the crucial role that third-party risk management can play.
And snakes, lots of giant snakes. One such slithering subject measures more than 130 feet long, which likely makes it the largest rock art ever discovered. But it's not just the size of that and ...
Study with Quizlet and memorize flashcards containing terms like If the results of an experiment contradict the hypothesis, you have _____ the hypothesis. A) failed B) supported C) falsified D) verified E) proved, What conclusions can be drawn from a hypothesis? A) If data support the hypothesis then it is accepted and further testing is not warranted. B) If evidence rejects the hypothesis ...
There is every reason for people to draw that conclusion," Biden said. Biden used the interview, with Time magazine, offer qualified support for Netanyahu. U.S. congressional leaders are working ...