- U.S. Locations
- UMGC Europe
- Learn Online
- Find Answers
- 855-655-8682
- Current Students

Online Guide to Writing and Research
The research process, explore more of umgc.
- Online Guide to Writing
Planning and Writing a Research Paper
Draw Conclusions
As a writer, you are presenting your viewpoint, opinions, evidence, etc. for others to review, so you must take on this task with maturity, courage and thoughtfulness. Remember, you are adding to the discourse community with every research paper that you write. This is a privilege and an opportunity to share your point of view with the world at large in an academic setting.
Because research generates further research, the conclusions you draw from your research are important. As a researcher, you depend on the integrity of the research that precedes your own efforts, and researchers depend on each other to draw valid conclusions.

To test the validity of your conclusions, you will have to review both the content of your paper and the way in which you arrived at the content. You may ask yourself questions, such as the ones presented below, to detect any weak areas in your paper, so you can then make those areas stronger. Notice that some of the questions relate to your process, others to your sources, and others to how you arrived at your conclusions.
Checklist for Evaluating Your Conclusions
Key takeaways.
- Because research generates further research, the conclusions you draw from your research are important.
- To test the validity of your conclusions, you will have to review both the content of your paper and the way in which you arrived at the content.
Mailing Address: 3501 University Blvd. East, Adelphi, MD 20783 This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License . © 2022 UMGC. All links to external sites were verified at the time of publication. UMGC is not responsible for the validity or integrity of information located at external sites.
Table of Contents: Online Guide to Writing
Chapter 1: College Writing
How Does College Writing Differ from Workplace Writing?
What Is College Writing?
Why So Much Emphasis on Writing?
Chapter 2: The Writing Process
Doing Exploratory Research
Getting from Notes to Your Draft
Introduction
Prewriting - Techniques to Get Started - Mining Your Intuition
Prewriting: Targeting Your Audience
Prewriting: Techniques to Get Started
Prewriting: Understanding Your Assignment
Rewriting: Being Your Own Critic
Rewriting: Creating a Revision Strategy
Rewriting: Getting Feedback
Rewriting: The Final Draft
Techniques to Get Started - Outlining
Techniques to Get Started - Using Systematic Techniques
Thesis Statement and Controlling Idea
Writing: Getting from Notes to Your Draft - Freewriting
Writing: Getting from Notes to Your Draft - Summarizing Your Ideas
Writing: Outlining What You Will Write
Chapter 3: Thinking Strategies
A Word About Style, Voice, and Tone
A Word About Style, Voice, and Tone: Style Through Vocabulary and Diction
Critical Strategies and Writing
Critical Strategies and Writing: Analysis
Critical Strategies and Writing: Evaluation
Critical Strategies and Writing: Persuasion
Critical Strategies and Writing: Synthesis
Developing a Paper Using Strategies
Kinds of Assignments You Will Write
Patterns for Presenting Information
Patterns for Presenting Information: Critiques
Patterns for Presenting Information: Discussing Raw Data
Patterns for Presenting Information: General-to-Specific Pattern
Patterns for Presenting Information: Problem-Cause-Solution Pattern
Patterns for Presenting Information: Specific-to-General Pattern
Patterns for Presenting Information: Summaries and Abstracts
Supporting with Research and Examples
Writing Essay Examinations
Writing Essay Examinations: Make Your Answer Relevant and Complete
Writing Essay Examinations: Organize Thinking Before Writing
Writing Essay Examinations: Read and Understand the Question
Chapter 4: The Research Process
Planning and Writing a Research Paper: Ask a Research Question
Planning and Writing a Research Paper: Cite Sources
Planning and Writing a Research Paper: Collect Evidence
Planning and Writing a Research Paper: Decide Your Point of View, or Role, for Your Research
Planning and Writing a Research Paper: Draw Conclusions
Planning and Writing a Research Paper: Find a Topic and Get an Overview
Planning and Writing a Research Paper: Manage Your Resources
Planning and Writing a Research Paper: Outline
Planning and Writing a Research Paper: Survey the Literature
Planning and Writing a Research Paper: Work Your Sources into Your Research Writing
Research Resources: Where Are Research Resources Found? - Human Resources
Research Resources: What Are Research Resources?
Research Resources: Where Are Research Resources Found?
Research Resources: Where Are Research Resources Found? - Electronic Resources
Research Resources: Where Are Research Resources Found? - Print Resources
Structuring the Research Paper: Formal Research Structure
Structuring the Research Paper: Informal Research Structure
The Nature of Research
The Research Assignment: How Should Research Sources Be Evaluated?
The Research Assignment: When Is Research Needed?
The Research Assignment: Why Perform Research?
Chapter 5: Academic Integrity
Academic Integrity
Giving Credit to Sources
Giving Credit to Sources: Copyright Laws
Giving Credit to Sources: Documentation
Giving Credit to Sources: Style Guides
Integrating Sources
Practicing Academic Integrity
Practicing Academic Integrity: Keeping Accurate Records
Practicing Academic Integrity: Managing Source Material
Practicing Academic Integrity: Managing Source Material - Paraphrasing Your Source
Practicing Academic Integrity: Managing Source Material - Quoting Your Source
Practicing Academic Integrity: Managing Source Material - Summarizing Your Sources
Types of Documentation
Types of Documentation: Bibliographies and Source Lists
Types of Documentation: Citing World Wide Web Sources
Types of Documentation: In-Text or Parenthetical Citations
Types of Documentation: In-Text or Parenthetical Citations - APA Style
Types of Documentation: In-Text or Parenthetical Citations - CSE/CBE Style
Types of Documentation: In-Text or Parenthetical Citations - Chicago Style
Types of Documentation: In-Text or Parenthetical Citations - MLA Style
Types of Documentation: Note Citations
Chapter 6: Using Library Resources
Finding Library Resources
Chapter 7: Assessing Your Writing
How Is Writing Graded?
How Is Writing Graded?: A General Assessment Tool
The Draft Stage
The Draft Stage: The First Draft
The Draft Stage: The Revision Process and the Final Draft
The Draft Stage: Using Feedback
The Research Stage
Using Assessment to Improve Your Writing
Chapter 8: Other Frequently Assigned Papers
Reviews and Reaction Papers: Article and Book Reviews
Reviews and Reaction Papers: Reaction Papers
Writing Arguments
Writing Arguments: Adapting the Argument Structure
Writing Arguments: Purposes of Argument
Writing Arguments: References to Consult for Writing Arguments
Writing Arguments: Steps to Writing an Argument - Anticipate Active Opposition
Writing Arguments: Steps to Writing an Argument - Determine Your Organization
Writing Arguments: Steps to Writing an Argument - Develop Your Argument
Writing Arguments: Steps to Writing an Argument - Introduce Your Argument
Writing Arguments: Steps to Writing an Argument - State Your Thesis or Proposition
Writing Arguments: Steps to Writing an Argument - Write Your Conclusion
Writing Arguments: Types of Argument
Appendix A: Books to Help Improve Your Writing
Dictionaries
General Style Manuals
Researching on the Internet
Special Style Manuals
Writing Handbooks
Appendix B: Collaborative Writing and Peer Reviewing
Collaborative Writing: Assignments to Accompany the Group Project
Collaborative Writing: Informal Progress Report
Collaborative Writing: Issues to Resolve
Collaborative Writing: Methodology
Collaborative Writing: Peer Evaluation
Collaborative Writing: Tasks of Collaborative Writing Group Members
Collaborative Writing: Writing Plan
General Introduction
Peer Reviewing
Appendix C: Developing an Improvement Plan
Working with Your Instructor’s Comments and Grades
Appendix D: Writing Plan and Project Schedule
Devising a Writing Project Plan and Schedule
Reviewing Your Plan with Others
By using our website you agree to our use of cookies. Learn more about how we use cookies by reading our Privacy Policy .
- USC Libraries
- Research Guides
Organizing Your Social Sciences Research Paper
- 9. The Conclusion
- Purpose of Guide
- Design Flaws to Avoid
- Independent and Dependent Variables
- Glossary of Research Terms
- Reading Research Effectively
- Narrowing a Topic Idea
- Broadening a Topic Idea
- Extending the Timeliness of a Topic Idea
- Academic Writing Style
- Applying Critical Thinking
- Choosing a Title
- Making an Outline
- Paragraph Development
- Research Process Video Series
- Executive Summary
- The C.A.R.S. Model
- Background Information
- The Research Problem/Question
- Theoretical Framework
- Citation Tracking
- Content Alert Services
- Evaluating Sources
- Primary Sources
- Secondary Sources
- Tiertiary Sources
- Scholarly vs. Popular Publications
- Qualitative Methods
- Quantitative Methods
- Insiderness
- Using Non-Textual Elements
- Limitations of the Study
- Common Grammar Mistakes
- Writing Concisely
- Avoiding Plagiarism
- Footnotes or Endnotes?
- Further Readings
- Generative AI and Writing
- USC Libraries Tutorials and Other Guides
- Bibliography
The conclusion is intended to help the reader understand why your research should matter to them after they have finished reading the paper. A conclusion is not merely a summary of the main topics covered or a re-statement of your research problem, but a synthesis of key points derived from the findings of your study and, if applicable, where you recommend new areas for future research. For most college-level research papers, two or three well-developed paragraphs is sufficient for a conclusion, although in some cases, more paragraphs may be required in describing the key findings and their significance.
Conclusions. The Writing Center. University of North Carolina; Conclusions. The Writing Lab and The OWL. Purdue University.
Importance of a Good Conclusion
A well-written conclusion provides you with important opportunities to demonstrate to the reader your understanding of the research problem. These include:
- Presenting the last word on the issues you raised in your paper . Just as the introduction gives a first impression to your reader, the conclusion offers a chance to leave a lasting impression. Do this, for example, by highlighting key findings in your analysis that advance new understanding about the research problem, that are unusual or unexpected, or that have important implications applied to practice.
- Summarizing your thoughts and conveying the larger significance of your study . The conclusion is an opportunity to succinctly re-emphasize your answer to the "So What?" question by placing the study within the context of how your research advances past research about the topic.
- Identifying how a gap in the literature has been addressed . The conclusion can be where you describe how a previously identified gap in the literature [first identified in your literature review section] has been addressed by your research and why this contribution is significant.
- Demonstrating the importance of your ideas . Don't be shy. The conclusion offers an opportunity to elaborate on the impact and significance of your findings. This is particularly important if your study approached examining the research problem from an unusual or innovative perspective.
- Introducing possible new or expanded ways of thinking about the research problem . This does not refer to introducing new information [which should be avoided], but to offer new insight and creative approaches for framing or contextualizing the research problem based on the results of your study.
Bunton, David. “The Structure of PhD Conclusion Chapters.” Journal of English for Academic Purposes 4 (July 2005): 207–224; Conclusions. The Writing Center. University of North Carolina; Kretchmer, Paul. Twelve Steps to Writing an Effective Conclusion. San Francisco Edit, 2003-2008; Conclusions. The Writing Lab and The OWL. Purdue University; Assan, Joseph. "Writing the Conclusion Chapter: The Good, the Bad and the Missing." Liverpool: Development Studies Association (2009): 1-8.
Structure and Writing Style
I. General Rules
The general function of your paper's conclusion is to restate the main argument . It reminds the reader of the strengths of your main argument(s) and reiterates the most important evidence supporting those argument(s). Do this by clearly summarizing the context, background, and necessity of pursuing the research problem you investigated in relation to an issue, controversy, or a gap found in the literature. However, make sure that your conclusion is not simply a repetitive summary of the findings. This reduces the impact of the argument(s) you have developed in your paper.
When writing the conclusion to your paper, follow these general rules:
- Present your conclusions in clear, concise language. Re-state the purpose of your study, then describe how your findings differ or support those of other studies and why [i.e., what were the unique, new, or crucial contributions your study made to the overall research about your topic?].
- Do not simply reiterate your findings or the discussion of your results. Provide a synthesis of arguments presented in the paper to show how these converge to address the research problem and the overall objectives of your study.
- Indicate opportunities for future research if you haven't already done so in the discussion section of your paper. Highlighting the need for further research provides the reader with evidence that you have an in-depth awareness of the research problem but that further investigations should take place beyond the scope of your investigation.
Consider the following points to help ensure your conclusion is presented well:
- If the argument or purpose of your paper is complex, you may need to summarize the argument for your reader.
- If, prior to your conclusion, you have not yet explained the significance of your findings or if you are proceeding inductively, use the end of your paper to describe your main points and explain their significance.
- Move from a detailed to a general level of consideration that returns the topic to the context provided by the introduction or within a new context that emerges from the data [this is opposite of the introduction, which begins with general discussion of the context and ends with a detailed description of the research problem].
The conclusion also provides a place for you to persuasively and succinctly restate the research problem, given that the reader has now been presented with all the information about the topic . Depending on the discipline you are writing in, the concluding paragraph may contain your reflections on the evidence presented. However, the nature of being introspective about the research you have conducted will depend on the topic and whether your professor wants you to express your observations in this way. If asked to think introspectively about the topics, do not delve into idle speculation. Being introspective means looking within yourself as an author to try and understand an issue more deeply, not to guess at possible outcomes or make up scenarios not supported by the evidence.
II. Developing a Compelling Conclusion
Although an effective conclusion needs to be clear and succinct, it does not need to be written passively or lack a compelling narrative. Strategies to help you move beyond merely summarizing the key points of your research paper may include any of the following:
- If your essay deals with a critical, contemporary problem, warn readers of the possible consequences of not attending to the problem proactively.
- Recommend a specific course or courses of action that, if adopted, could address a specific problem in practice or in the development of new knowledge leading to positive change.
- Cite a relevant quotation or expert opinion already noted in your paper in order to lend authority and support to the conclusion(s) you have reached [a good source would be from your literature review].
- Explain the consequences of your research in a way that elicits action or demonstrates urgency in seeking change.
- Restate a key statistic, fact, or visual image to emphasize the most important finding of your paper.
- If your discipline encourages personal reflection, illustrate your concluding point by drawing from your own life experiences.
- Return to an anecdote, an example, or a quotation that you presented in your introduction, but add further insight derived from the findings of your study; use your interpretation of results from your study to recast it in new or important ways.
- Provide a "take-home" message in the form of a succinct, declarative statement that you want the reader to remember about your study.
III. Problems to Avoid
Failure to be concise Your conclusion section should be concise and to the point. Conclusions that are too lengthy often have unnecessary information in them. The conclusion is not the place for details about your methodology or results. Although you should give a summary of what was learned from your research, this summary should be relatively brief, since the emphasis in the conclusion is on the implications, evaluations, insights, and other forms of analysis that you make. Strategies for writing concisely can be found here .
Failure to comment on larger, more significant issues In the introduction, your task was to move from the general [the field of study] to the specific [the research problem]. However, in the conclusion, your task is to move from a specific discussion [your research problem] back to a general discussion framed around the implications and significance of your findings [i.e., how your research contributes new understanding or fills an important gap in the literature]. In short, the conclusion is where you should place your research within a larger context [visualize your paper as an hourglass--start with a broad introduction and review of the literature, move to the specific analysis and discussion, conclude with a broad summary of the study's implications and significance].
Failure to reveal problems and negative results Negative aspects of the research process should never be ignored. These are problems, deficiencies, or challenges encountered during your study. They should be summarized as a way of qualifying your overall conclusions. If you encountered negative or unintended results [i.e., findings that are validated outside the research context in which they were generated], you must report them in the results section and discuss their implications in the discussion section of your paper. In the conclusion, use negative results as an opportunity to explain their possible significance and/or how they may form the basis for future research.
Failure to provide a clear summary of what was learned In order to be able to discuss how your research fits within your field of study [and possibly the world at large], you need to summarize briefly and succinctly how it contributes to new knowledge or a new understanding about the research problem. This element of your conclusion may be only a few sentences long.
Failure to match the objectives of your research Often research objectives in the social and behavioral sciences change while the research is being carried out. This is not a problem unless you forget to go back and refine the original objectives in your introduction. As these changes emerge they must be documented so that they accurately reflect what you were trying to accomplish in your research [not what you thought you might accomplish when you began].
Resist the urge to apologize If you've immersed yourself in studying the research problem, you presumably should know a good deal about it [perhaps even more than your professor!]. Nevertheless, by the time you have finished writing, you may be having some doubts about what you have produced. Repress those doubts! Don't undermine your authority as a researcher by saying something like, "This is just one approach to examining this problem; there may be other, much better approaches that...." The overall tone of your conclusion should convey confidence to the reader about the study's validity and realiability.
Assan, Joseph. "Writing the Conclusion Chapter: The Good, the Bad and the Missing." Liverpool: Development Studies Association (2009): 1-8; Concluding Paragraphs. College Writing Center at Meramec. St. Louis Community College; Conclusions. The Writing Center. University of North Carolina; Conclusions. The Writing Lab and The OWL. Purdue University; Freedman, Leora and Jerry Plotnick. Introductions and Conclusions. The Lab Report. University College Writing Centre. University of Toronto; Leibensperger, Summer. Draft Your Conclusion. Academic Center, the University of Houston-Victoria, 2003; Make Your Last Words Count. The Writer’s Handbook. Writing Center. University of Wisconsin Madison; Miquel, Fuster-Marquez and Carmen Gregori-Signes. “Chapter Six: ‘Last but Not Least:’ Writing the Conclusion of Your Paper.” In Writing an Applied Linguistics Thesis or Dissertation: A Guide to Presenting Empirical Research . John Bitchener, editor. (Basingstoke,UK: Palgrave Macmillan, 2010), pp. 93-105; Tips for Writing a Good Conclusion. Writing@CSU. Colorado State University; Kretchmer, Paul. Twelve Steps to Writing an Effective Conclusion. San Francisco Edit, 2003-2008; Writing Conclusions. Writing Tutorial Services, Center for Innovative Teaching and Learning. Indiana University; Writing: Considering Structure and Organization. Institute for Writing Rhetoric. Dartmouth College.
Writing Tip
Don't Belabor the Obvious!
Avoid phrases like "in conclusion...," "in summary...," or "in closing...." These phrases can be useful, even welcome, in oral presentations. But readers can see by the tell-tale section heading and number of pages remaining that they are reaching the end of your paper. You'll irritate your readers if you belabor the obvious.
Assan, Joseph. "Writing the Conclusion Chapter: The Good, the Bad and the Missing." Liverpool: Development Studies Association (2009): 1-8.
Another Writing Tip
New Insight, Not New Information!
Don't surprise the reader with new information in your conclusion that was never referenced anywhere else in the paper. This why the conclusion rarely has citations to sources. If you have new information to present, add it to the discussion or other appropriate section of the paper. Note that, although no new information is introduced, the conclusion, along with the discussion section, is where you offer your most "original" contributions in the paper; the conclusion is where you describe the value of your research, demonstrate that you understand the material that you’ve presented, and position your findings within the larger context of scholarship on the topic, including describing how your research contributes new insights to that scholarship.
Assan, Joseph. "Writing the Conclusion Chapter: The Good, the Bad and the Missing." Liverpool: Development Studies Association (2009): 1-8; Conclusions. The Writing Center. University of North Carolina.
- << Previous: Limitations of the Study
- Next: Appendices >>
- Last Updated: May 25, 2024 4:09 PM
- URL: https://libguides.usc.edu/writingguide
Get science-backed answers as you write with Paperpal's Research feature
How to Write a Conclusion for Research Papers (with Examples)

The conclusion of a research paper is a crucial section that plays a significant role in the overall impact and effectiveness of your research paper. However, this is also the section that typically receives less attention compared to the introduction and the body of the paper. The conclusion serves to provide a concise summary of the key findings, their significance, their implications, and a sense of closure to the study. Discussing how can the findings be applied in real-world scenarios or inform policy, practice, or decision-making is especially valuable to practitioners and policymakers. The research paper conclusion also provides researchers with clear insights and valuable information for their own work, which they can then build on and contribute to the advancement of knowledge in the field.
The research paper conclusion should explain the significance of your findings within the broader context of your field. It restates how your results contribute to the existing body of knowledge and whether they confirm or challenge existing theories or hypotheses. Also, by identifying unanswered questions or areas requiring further investigation, your awareness of the broader research landscape can be demonstrated.
Remember to tailor the research paper conclusion to the specific needs and interests of your intended audience, which may include researchers, practitioners, policymakers, or a combination of these.
Table of Contents
What is a conclusion in a research paper, summarizing conclusion, editorial conclusion, externalizing conclusion, importance of a good research paper conclusion, how to write a conclusion for your research paper, research paper conclusion examples.
- How to write a research paper conclusion with Paperpal?
Frequently Asked Questions
A conclusion in a research paper is the final section where you summarize and wrap up your research, presenting the key findings and insights derived from your study. The research paper conclusion is not the place to introduce new information or data that was not discussed in the main body of the paper. When working on how to conclude a research paper, remember to stick to summarizing and interpreting existing content. The research paper conclusion serves the following purposes: 1
- Warn readers of the possible consequences of not attending to the problem.
- Recommend specific course(s) of action.
- Restate key ideas to drive home the ultimate point of your research paper.
- Provide a “take-home” message that you want the readers to remember about your study.

Types of conclusions for research papers
In research papers, the conclusion provides closure to the reader. The type of research paper conclusion you choose depends on the nature of your study, your goals, and your target audience. I provide you with three common types of conclusions:
A summarizing conclusion is the most common type of conclusion in research papers. It involves summarizing the main points, reiterating the research question, and restating the significance of the findings. This common type of research paper conclusion is used across different disciplines.
An editorial conclusion is less common but can be used in research papers that are focused on proposing or advocating for a particular viewpoint or policy. It involves presenting a strong editorial or opinion based on the research findings and offering recommendations or calls to action.
An externalizing conclusion is a type of conclusion that extends the research beyond the scope of the paper by suggesting potential future research directions or discussing the broader implications of the findings. This type of conclusion is often used in more theoretical or exploratory research papers.
Align your conclusion’s tone with the rest of your research paper. Start Writing with Paperpal Now!
The conclusion in a research paper serves several important purposes:
- Offers Implications and Recommendations : Your research paper conclusion is an excellent place to discuss the broader implications of your research and suggest potential areas for further study. It’s also an opportunity to offer practical recommendations based on your findings.
- Provides Closure : A good research paper conclusion provides a sense of closure to your paper. It should leave the reader with a feeling that they have reached the end of a well-structured and thought-provoking research project.
- Leaves a Lasting Impression : Writing a well-crafted research paper conclusion leaves a lasting impression on your readers. It’s your final opportunity to leave them with a new idea, a call to action, or a memorable quote.

Writing a strong conclusion for your research paper is essential to leave a lasting impression on your readers. Here’s a step-by-step process to help you create and know what to put in the conclusion of a research paper: 2
- Research Statement : Begin your research paper conclusion by restating your research statement. This reminds the reader of the main point you’ve been trying to prove throughout your paper. Keep it concise and clear.
- Key Points : Summarize the main arguments and key points you’ve made in your paper. Avoid introducing new information in the research paper conclusion. Instead, provide a concise overview of what you’ve discussed in the body of your paper.
- Address the Research Questions : If your research paper is based on specific research questions or hypotheses, briefly address whether you’ve answered them or achieved your research goals. Discuss the significance of your findings in this context.
- Significance : Highlight the importance of your research and its relevance in the broader context. Explain why your findings matter and how they contribute to the existing knowledge in your field.
- Implications : Explore the practical or theoretical implications of your research. How might your findings impact future research, policy, or real-world applications? Consider the “so what?” question.
- Future Research : Offer suggestions for future research in your area. What questions or aspects remain unanswered or warrant further investigation? This shows that your work opens the door for future exploration.
- Closing Thought : Conclude your research paper conclusion with a thought-provoking or memorable statement. This can leave a lasting impression on your readers and wrap up your paper effectively. Avoid introducing new information or arguments here.
- Proofread and Revise : Carefully proofread your conclusion for grammar, spelling, and clarity. Ensure that your ideas flow smoothly and that your conclusion is coherent and well-structured.
Write your research paper conclusion 2x faster with Paperpal. Try it now!
Remember that a well-crafted research paper conclusion is a reflection of the strength of your research and your ability to communicate its significance effectively. It should leave a lasting impression on your readers and tie together all the threads of your paper. Now you know how to start the conclusion of a research paper and what elements to include to make it impactful, let’s look at a research paper conclusion sample.

How to write a research paper conclusion with Paperpal?
A research paper conclusion is not just a summary of your study, but a synthesis of the key findings that ties the research together and places it in a broader context. A research paper conclusion should be concise, typically around one paragraph in length. However, some complex topics may require a longer conclusion to ensure the reader is left with a clear understanding of the study’s significance. Paperpal, an AI writing assistant trusted by over 800,000 academics globally, can help you write a well-structured conclusion for your research paper.
- Sign Up or Log In: Create a new Paperpal account or login with your details.
- Navigate to Features : Once logged in, head over to the features’ side navigation pane. Click on Templates and you’ll find a suite of generative AI features to help you write better, faster.
- Generate an outline: Under Templates, select ‘Outlines’. Choose ‘Research article’ as your document type.
- Select your section: Since you’re focusing on the conclusion, select this section when prompted.
- Choose your field of study: Identifying your field of study allows Paperpal to provide more targeted suggestions, ensuring the relevance of your conclusion to your specific area of research.
- Provide a brief description of your study: Enter details about your research topic and findings. This information helps Paperpal generate a tailored outline that aligns with your paper’s content.
- Generate the conclusion outline: After entering all necessary details, click on ‘generate’. Paperpal will then create a structured outline for your conclusion, to help you start writing and build upon the outline.
- Write your conclusion: Use the generated outline to build your conclusion. The outline serves as a guide, ensuring you cover all critical aspects of a strong conclusion, from summarizing key findings to highlighting the research’s implications.
- Refine and enhance: Paperpal’s ‘Make Academic’ feature can be particularly useful in the final stages. Select any paragraph of your conclusion and use this feature to elevate the academic tone, ensuring your writing is aligned to the academic journal standards.
By following these steps, Paperpal not only simplifies the process of writing a research paper conclusion but also ensures it is impactful, concise, and aligned with academic standards. Sign up with Paperpal today and write your research paper conclusion 2x faster .
The research paper conclusion is a crucial part of your paper as it provides the final opportunity to leave a strong impression on your readers. In the research paper conclusion, summarize the main points of your research paper by restating your research statement, highlighting the most important findings, addressing the research questions or objectives, explaining the broader context of the study, discussing the significance of your findings, providing recommendations if applicable, and emphasizing the takeaway message. The main purpose of the conclusion is to remind the reader of the main point or argument of your paper and to provide a clear and concise summary of the key findings and their implications. All these elements should feature on your list of what to put in the conclusion of a research paper to create a strong final statement for your work.
A strong conclusion is a critical component of a research paper, as it provides an opportunity to wrap up your arguments, reiterate your main points, and leave a lasting impression on your readers. Here are the key elements of a strong research paper conclusion: 1. Conciseness : A research paper conclusion should be concise and to the point. It should not introduce new information or ideas that were not discussed in the body of the paper. 2. Summarization : The research paper conclusion should be comprehensive enough to give the reader a clear understanding of the research’s main contributions. 3 . Relevance : Ensure that the information included in the research paper conclusion is directly relevant to the research paper’s main topic and objectives; avoid unnecessary details. 4 . Connection to the Introduction : A well-structured research paper conclusion often revisits the key points made in the introduction and shows how the research has addressed the initial questions or objectives. 5. Emphasis : Highlight the significance and implications of your research. Why is your study important? What are the broader implications or applications of your findings? 6 . Call to Action : Include a call to action or a recommendation for future research or action based on your findings.
The length of a research paper conclusion can vary depending on several factors, including the overall length of the paper, the complexity of the research, and the specific journal requirements. While there is no strict rule for the length of a conclusion, but it’s generally advisable to keep it relatively short. A typical research paper conclusion might be around 5-10% of the paper’s total length. For example, if your paper is 10 pages long, the conclusion might be roughly half a page to one page in length.
In general, you do not need to include citations in the research paper conclusion. Citations are typically reserved for the body of the paper to support your arguments and provide evidence for your claims. However, there may be some exceptions to this rule: 1. If you are drawing a direct quote or paraphrasing a specific source in your research paper conclusion, you should include a citation to give proper credit to the original author. 2. If your conclusion refers to or discusses specific research, data, or sources that are crucial to the overall argument, citations can be included to reinforce your conclusion’s validity.
The conclusion of a research paper serves several important purposes: 1. Summarize the Key Points 2. Reinforce the Main Argument 3. Provide Closure 4. Offer Insights or Implications 5. Engage the Reader. 6. Reflect on Limitations
Remember that the primary purpose of the research paper conclusion is to leave a lasting impression on the reader, reinforcing the key points and providing closure to your research. It’s often the last part of the paper that the reader will see, so it should be strong and well-crafted.
- Makar, G., Foltz, C., Lendner, M., & Vaccaro, A. R. (2018). How to write effective discussion and conclusion sections. Clinical spine surgery, 31(8), 345-346.
- Bunton, D. (2005). The structure of PhD conclusion chapters. Journal of English for academic purposes , 4 (3), 207-224.
Paperpal is a comprehensive AI writing toolkit that helps students and researchers achieve 2x the writing in half the time. It leverages 21+ years of STM experience and insights from millions of research articles to provide in-depth academic writing, language editing, and submission readiness support to help you write better, faster.
Get accurate academic translations, rewriting support, grammar checks, vocabulary suggestions, and generative AI assistance that delivers human precision at machine speed. Try for free or upgrade to Paperpal Prime starting at US$19 a month to access premium features, including consistency, plagiarism, and 30+ submission readiness checks to help you succeed.
Experience the future of academic writing – Sign up to Paperpal and start writing for free!
Related Reads:
- 5 Reasons for Rejection After Peer Review
- Ethical Research Practices For Research with Human Subjects
7 Ways to Improve Your Academic Writing Process
- Paraphrasing in Academic Writing: Answering Top Author Queries
Preflight For Editorial Desk: The Perfect Hybrid (AI + Human) Assistance Against Compromised Manuscripts
You may also like, mla works cited page: format, template & examples, how to write a high-quality conference paper, academic editing: how to self-edit academic text with..., measuring academic success: definition & strategies for excellence, phd qualifying exam: tips for success , ai in education: it’s time to change the..., is it ethical to use ai-generated abstracts without..., what are journal guidelines on using generative ai..., quillbot review: features, pricing, and free alternatives, what is an academic paper types and elements .
- Privacy Policy
Home » Research Paper Conclusion – Writing Guide and Examples
Research Paper Conclusion – Writing Guide and Examples
Table of Contents

Research Paper Conclusion
Definition:
A research paper conclusion is the final section of a research paper that summarizes the key findings, significance, and implications of the research. It is the writer’s opportunity to synthesize the information presented in the paper, draw conclusions, and make recommendations for future research or actions.
The conclusion should provide a clear and concise summary of the research paper, reiterating the research question or problem, the main results, and the significance of the findings. It should also discuss the limitations of the study and suggest areas for further research.
Parts of Research Paper Conclusion
The parts of a research paper conclusion typically include:
Restatement of the Thesis
The conclusion should begin by restating the thesis statement from the introduction in a different way. This helps to remind the reader of the main argument or purpose of the research.
Summary of Key Findings
The conclusion should summarize the main findings of the research, highlighting the most important results and conclusions. This section should be brief and to the point.
Implications and Significance
In this section, the researcher should explain the implications and significance of the research findings. This may include discussing the potential impact on the field or industry, highlighting new insights or knowledge gained, or pointing out areas for future research.
Limitations and Recommendations
It is important to acknowledge any limitations or weaknesses of the research and to make recommendations for how these could be addressed in future studies. This shows that the researcher is aware of the potential limitations of their work and is committed to improving the quality of research in their field.
Concluding Statement
The conclusion should end with a strong concluding statement that leaves a lasting impression on the reader. This could be a call to action, a recommendation for further research, or a final thought on the topic.
How to Write Research Paper Conclusion
Here are some steps you can follow to write an effective research paper conclusion:
- Restate the research problem or question: Begin by restating the research problem or question that you aimed to answer in your research. This will remind the reader of the purpose of your study.
- Summarize the main points: Summarize the key findings and results of your research. This can be done by highlighting the most important aspects of your research and the evidence that supports them.
- Discuss the implications: Discuss the implications of your findings for the research area and any potential applications of your research. You should also mention any limitations of your research that may affect the interpretation of your findings.
- Provide a conclusion : Provide a concise conclusion that summarizes the main points of your paper and emphasizes the significance of your research. This should be a strong and clear statement that leaves a lasting impression on the reader.
- Offer suggestions for future research: Lastly, offer suggestions for future research that could build on your findings and contribute to further advancements in the field.
Remember that the conclusion should be brief and to the point, while still effectively summarizing the key findings and implications of your research.
Example of Research Paper Conclusion
Here’s an example of a research paper conclusion:
Conclusion :
In conclusion, our study aimed to investigate the relationship between social media use and mental health among college students. Our findings suggest that there is a significant association between social media use and increased levels of anxiety and depression among college students. This highlights the need for increased awareness and education about the potential negative effects of social media use on mental health, particularly among college students.
Despite the limitations of our study, such as the small sample size and self-reported data, our findings have important implications for future research and practice. Future studies should aim to replicate our findings in larger, more diverse samples, and investigate the potential mechanisms underlying the association between social media use and mental health. In addition, interventions should be developed to promote healthy social media use among college students, such as mindfulness-based approaches and social media detox programs.
Overall, our study contributes to the growing body of research on the impact of social media on mental health, and highlights the importance of addressing this issue in the context of higher education. By raising awareness and promoting healthy social media use among college students, we can help to reduce the negative impact of social media on mental health and improve the well-being of young adults.
Purpose of Research Paper Conclusion
The purpose of a research paper conclusion is to provide a summary and synthesis of the key findings, significance, and implications of the research presented in the paper. The conclusion serves as the final opportunity for the writer to convey their message and leave a lasting impression on the reader.
The conclusion should restate the research problem or question, summarize the main results of the research, and explain their significance. It should also acknowledge the limitations of the study and suggest areas for future research or action.
Overall, the purpose of the conclusion is to provide a sense of closure to the research paper and to emphasize the importance of the research and its potential impact. It should leave the reader with a clear understanding of the main findings and why they matter. The conclusion serves as the writer’s opportunity to showcase their contribution to the field and to inspire further research and action.
When to Write Research Paper Conclusion
The conclusion of a research paper should be written after the body of the paper has been completed. It should not be written until the writer has thoroughly analyzed and interpreted their findings and has written a complete and cohesive discussion of the research.
Before writing the conclusion, the writer should review their research paper and consider the key points that they want to convey to the reader. They should also review the research question, hypotheses, and methodology to ensure that they have addressed all of the necessary components of the research.
Once the writer has a clear understanding of the main findings and their significance, they can begin writing the conclusion. The conclusion should be written in a clear and concise manner, and should reiterate the main points of the research while also providing insights and recommendations for future research or action.
Characteristics of Research Paper Conclusion
The characteristics of a research paper conclusion include:
- Clear and concise: The conclusion should be written in a clear and concise manner, summarizing the key findings and their significance.
- Comprehensive: The conclusion should address all of the main points of the research paper, including the research question or problem, the methodology, the main results, and their implications.
- Future-oriented : The conclusion should provide insights and recommendations for future research or action, based on the findings of the research.
- Impressive : The conclusion should leave a lasting impression on the reader, emphasizing the importance of the research and its potential impact.
- Objective : The conclusion should be based on the evidence presented in the research paper, and should avoid personal biases or opinions.
- Unique : The conclusion should be unique to the research paper and should not simply repeat information from the introduction or body of the paper.
Advantages of Research Paper Conclusion
The advantages of a research paper conclusion include:
- Summarizing the key findings : The conclusion provides a summary of the main findings of the research, making it easier for the reader to understand the key points of the study.
- Emphasizing the significance of the research: The conclusion emphasizes the importance of the research and its potential impact, making it more likely that readers will take the research seriously and consider its implications.
- Providing recommendations for future research or action : The conclusion suggests practical recommendations for future research or action, based on the findings of the study.
- Providing closure to the research paper : The conclusion provides a sense of closure to the research paper, tying together the different sections of the paper and leaving a lasting impression on the reader.
- Demonstrating the writer’s contribution to the field : The conclusion provides the writer with an opportunity to showcase their contribution to the field and to inspire further research and action.
Limitations of Research Paper Conclusion
While the conclusion of a research paper has many advantages, it also has some limitations that should be considered, including:
- I nability to address all aspects of the research: Due to the limited space available in the conclusion, it may not be possible to address all aspects of the research in detail.
- Subjectivity : While the conclusion should be objective, it may be influenced by the writer’s personal biases or opinions.
- Lack of new information: The conclusion should not introduce new information that has not been discussed in the body of the research paper.
- Lack of generalizability: The conclusions drawn from the research may not be applicable to other contexts or populations, limiting the generalizability of the study.
- Misinterpretation by the reader: The reader may misinterpret the conclusions drawn from the research, leading to a misunderstanding of the findings.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

How to Cite Research Paper – All Formats and...

Data Collection – Methods Types and Examples

Delimitations in Research – Types, Examples and...

Research Paper Format – Types, Examples and...

Research Process – Steps, Examples and Tips

Research Design – Types, Methods and Examples
When you choose to publish with PLOS, your research makes an impact. Make your work accessible to all, without restrictions, and accelerate scientific discovery with options like preprints and published peer review that make your work more Open.
- PLOS Biology
- PLOS Climate
- PLOS Complex Systems
- PLOS Computational Biology
- PLOS Digital Health
- PLOS Genetics
- PLOS Global Public Health
- PLOS Medicine
- PLOS Mental Health
- PLOS Neglected Tropical Diseases
- PLOS Pathogens
- PLOS Sustainability and Transformation
- PLOS Collections
- How to Write Discussions and Conclusions

The discussion section contains the results and outcomes of a study. An effective discussion informs readers what can be learned from your experiment and provides context for the results.
What makes an effective discussion?
When you’re ready to write your discussion, you’ve already introduced the purpose of your study and provided an in-depth description of the methodology. The discussion informs readers about the larger implications of your study based on the results. Highlighting these implications while not overstating the findings can be challenging, especially when you’re submitting to a journal that selects articles based on novelty or potential impact. Regardless of what journal you are submitting to, the discussion section always serves the same purpose: concluding what your study results actually mean.
A successful discussion section puts your findings in context. It should include:
- the results of your research,
- a discussion of related research, and
- a comparison between your results and initial hypothesis.
Tip: Not all journals share the same naming conventions.
You can apply the advice in this article to the conclusion, results or discussion sections of your manuscript.
Our Early Career Researcher community tells us that the conclusion is often considered the most difficult aspect of a manuscript to write. To help, this guide provides questions to ask yourself, a basic structure to model your discussion off of and examples from published manuscripts.
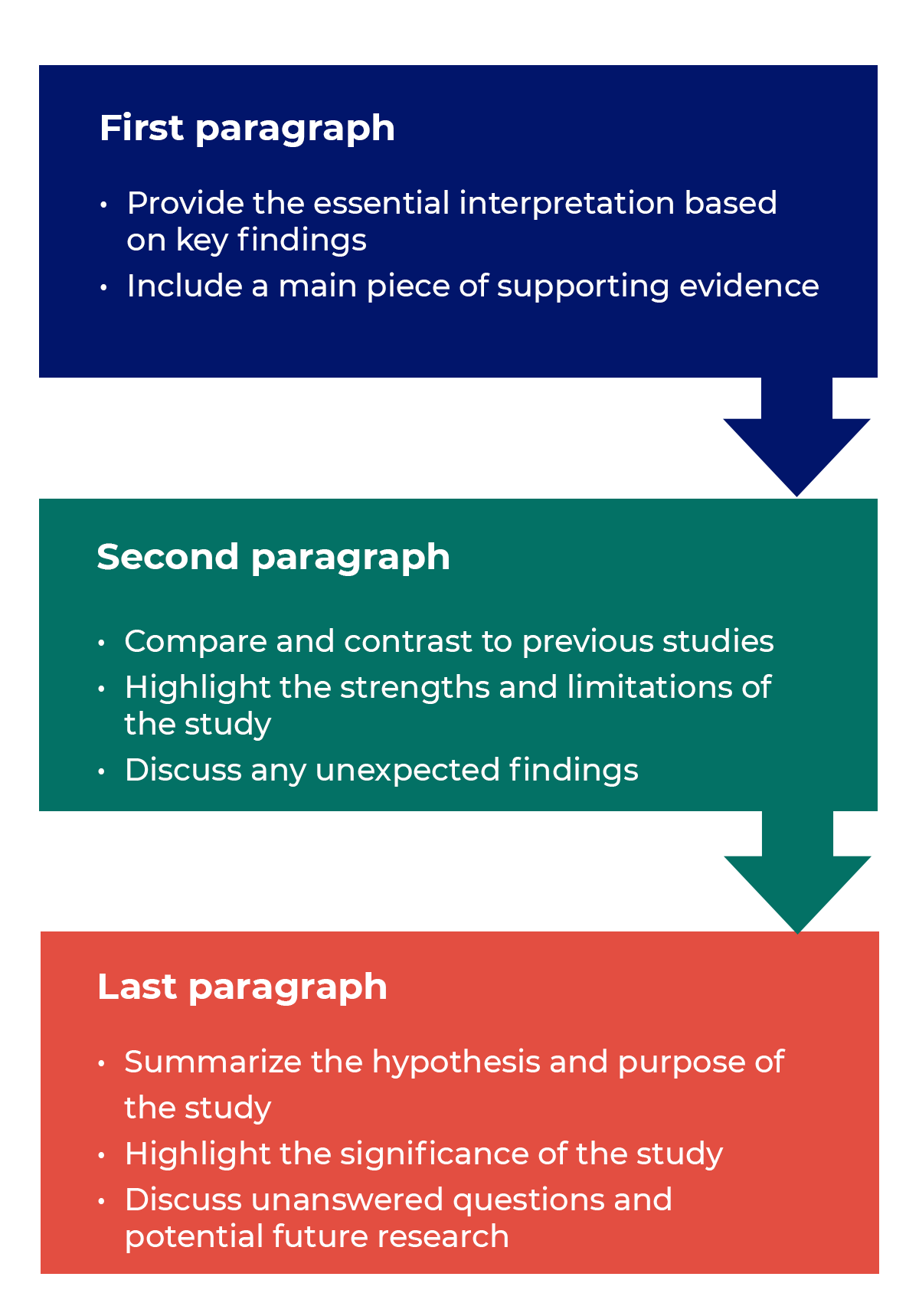
Questions to ask yourself:
- Was my hypothesis correct?
- If my hypothesis is partially correct or entirely different, what can be learned from the results?
- How do the conclusions reshape or add onto the existing knowledge in the field? What does previous research say about the topic?
- Why are the results important or relevant to your audience? Do they add further evidence to a scientific consensus or disprove prior studies?
- How can future research build on these observations? What are the key experiments that must be done?
- What is the “take-home” message you want your reader to leave with?
How to structure a discussion
Trying to fit a complete discussion into a single paragraph can add unnecessary stress to the writing process. If possible, you’ll want to give yourself two or three paragraphs to give the reader a comprehensive understanding of your study as a whole. Here’s one way to structure an effective discussion:
Writing Tips
While the above sections can help you brainstorm and structure your discussion, there are many common mistakes that writers revert to when having difficulties with their paper. Writing a discussion can be a delicate balance between summarizing your results, providing proper context for your research and avoiding introducing new information. Remember that your paper should be both confident and honest about the results!

- Read the journal’s guidelines on the discussion and conclusion sections. If possible, learn about the guidelines before writing the discussion to ensure you’re writing to meet their expectations.
- Begin with a clear statement of the principal findings. This will reinforce the main take-away for the reader and set up the rest of the discussion.
- Explain why the outcomes of your study are important to the reader. Discuss the implications of your findings realistically based on previous literature, highlighting both the strengths and limitations of the research.
- State whether the results prove or disprove your hypothesis. If your hypothesis was disproved, what might be the reasons?
- Introduce new or expanded ways to think about the research question. Indicate what next steps can be taken to further pursue any unresolved questions.
- If dealing with a contemporary or ongoing problem, such as climate change, discuss possible consequences if the problem is avoided.
- Be concise. Adding unnecessary detail can distract from the main findings.

Don’t
- Rewrite your abstract. Statements with “we investigated” or “we studied” generally do not belong in the discussion.
- Include new arguments or evidence not previously discussed. Necessary information and evidence should be introduced in the main body of the paper.
- Apologize. Even if your research contains significant limitations, don’t undermine your authority by including statements that doubt your methodology or execution.
- Shy away from speaking on limitations or negative results. Including limitations and negative results will give readers a complete understanding of the presented research. Potential limitations include sources of potential bias, threats to internal or external validity, barriers to implementing an intervention and other issues inherent to the study design.
- Overstate the importance of your findings. Making grand statements about how a study will fully resolve large questions can lead readers to doubt the success of the research.
Snippets of Effective Discussions:
Consumer-based actions to reduce plastic pollution in rivers: A multi-criteria decision analysis approach
Identifying reliable indicators of fitness in polar bears
- How to Write a Great Title
- How to Write an Abstract
- How to Write Your Methods
- How to Report Statistics
- How to Edit Your Work
The contents of the Peer Review Center are also available as a live, interactive training session, complete with slides, talking points, and activities. …
The contents of the Writing Center are also available as a live, interactive training session, complete with slides, talking points, and activities. …
There’s a lot to consider when deciding where to submit your work. Learn how to choose a journal that will help your study reach its audience, while reflecting your values as a researcher…

- Spencer Greenberg
- Nov 26, 2018
- 11 min read
12 Ways To Draw Conclusions From Information
Updated: Sep 25, 2023

There are a LOT of ways to make inferences – that is, for drawing conclusions based on information, evidence or data. In fact, there are many more than most people realize. All of them have strengths and weaknesses that render them more useful in some situations than in others.
Here's a brief key describing most popular methods of inference, to help you whenever you're trying to draw a conclusion for yourself. Do you rely more on some of these than you should, given their weaknesses? Are there others in this list that you could benefit from using more in your life, given their strengths? And what does drawing conclusions mean, really? As you'll learn in a moment, it encompasses a wide variety of techniques, so there isn't one single definition.
1. Deduction
Common in: philosophy, mathematics
If X, then Y, due to the definitions of X and Y.
X applies to this case.
Therefore Y applies to this case.
Example: “Plato is a mortal, and all mortals are, by definition, able to die; therefore Plato is able to die.”
Example: “For any number that is an integer, there exists another integer greater than that number. 1,000,000 is an integer. So there exists an integer greater than 1,000,000.”
Advantages: When you use deduction properly in an appropriate context, it is an airtight form of inference (e.g. in a mathematical proof with no mistakes).
Flaws: To apply deduction to the world, you need to rely on strong assumptions about how the world works, or else apply other methods of inference on top. So its range of applicability is limited.
2. Frequencies
Common in: applied statistics, data science
95% of the time that X occurred in the past, Y occurred also.
X occurred.
Therefore Y is likely to occur (with high probability).
Example: “95% of the time when we saw a bank transaction identical to this one, it was fraudulent. So this transaction is fraudulent.”
Advantages: This technique allows you to assign probabilities to events. When you have a lot of past data it can be easy to apply.
Flaws: You need to have a moderately large number of examples like the current one to perform calculations on. Also, the method assumes that those past examples were drawn from a process that is (statistically) just like the one that generated this latest example. Moreover, it is unclear sometimes what it means for “X”, the type of event you’re interested in, to have occurred. What if something that’s very similar to but not quite like X occurred? Should that be counted as X occurring? If we broaden our class of what counts as X or change to another class of event that still encompasses all of our prior examples, we’ll potentially get a different answer. Fortunately, there are plenty of opportunities to make inferences from frequencies where the correct class to use is fairly obvious.

If you've found this article valuable so far, you may also like our free tool
Common in : financial engineering, risk modeling, environmental science
Given our probabilistic model of this thing, when X occurs, the probability of Y occurring is 0.95.
Example: “Given our multivariate Gaussian model of loan prices, when this loan defaults there is a 0.95 probability of this other loan defaulting.”
Example: "When we run the weather simulation model many times with randomization of the initial conditions, rain occurs tomorrow in that region 95% of the time."
Advantages: This technique can be used to make predictions in very complex scenarios (e.g. involving more variables than a human mind can take into account at once) as long as the dynamics of the systems underlying those scenarios are sufficiently well understood.
Flaws: This method hinges on the appropriateness of the model chosen; it may require a large amount of past data to estimate free model parameters, and may go haywire if modeling assumptions are unrealistic or suddenly violated by changes in the world. You may have to already understand the system deeply to be able to build the model in the first place (e.g. with weather modeling).
4. Classification
Common in: machine learning, data science
In prior data, as X1 and X2 increased, the likelihood of Y increased.
X1 and X2 are at high levels.
Therefore Y is likely to occur.
Example: “Height for children can be approximately predicted as an (increasing) linear function of age (X1) and weight (X2). This child is older and heavier than the others, so we predict he is likely to be tall.”
Example: "We've trained a neural network to predict whether a particular batch of concrete will be strong based on its constituents, mixture proportion, compaction, etc."
Advantages: This method can often produce accurate predictions for systems that you don't have much understanding of, as long as enough data is available to train the regression algorithm and that data contains sufficiently relevant variables.
Flaws: This method is often applied with simple assumptions (e.g. linearity) that may not capture the complexity of the inference problem, but very large amounts of data may be needed to apply much more complex models (e.g to use neural networks, which are non-linear). Regression also may produce results that are hard to interpret – you may not really understand why it does a good job of making predictions.
5. Bayesianism
Common in: the rationality community
Given my prior odds that Y is true...
And given evidence X...
And given my Bayes factor, which is my estimate of how much more likely X is to occur if Y is true than if Y is not true...
I calculate that Y is far more likely to be true than to not be true (by multiplying the prior odds by the Bayes factor to get the posterior odds).
Therefore Y is likely to be true (with high probability).
Example: “My prior odds that my boss is angry at me were 1 to 4, because he’s angry at me about 20% of the time. But then he came into my office shouting and flipped over my desk, which I estimate is 200 times more likely to occur if he’s angry at me compared to if he’s not. So now the odds of him being angry at me are 200 * (1/4) = 50 to 1 in favor of him being angry.”
Example: "Historically, companies in this situation have 2 to 1 odds of defaulting on their loans. But then evidence came out about this specific company showing that it is 3 times more likely to end up defaulting on its loans than similar companies. Hence now the odds of it defaulting are 6 to 1 since: (2/1) * (3/1) = 6. That means there is an 85% chance that it defaults since 0.85 = 6/(6+1)."
Advantages: If you can do the calculations in a given instance, and have a sensible way to set your prior probabilities, this is probably the mathematically optimal framework to use for probabilistic prediction. For instance, if you have a belief about the probability of something, then you gain some new evidence, you can prove mathematically that Bayes's rule tells you how to calculate what your new probability should now be that incorporates that evidence. In that sense, we can think of many of the other approaches on this list as (hopefully pragmatic) approximations of Bayesianism (sometimes good approximations, sometimes bad ones).
Flaws: It's sometimes hard to know how to set your prior odds, and it can be very hard in some cases to perform the Bayesian calculation. In practice, carrying out the calculation might end up relying on subjective estimates of the odds, which can be especially tricky to guess when the evidence is not binary (i.e not of the form “happened” vs. “didn’t happen”), or if you have lots of different pieces of evidence that are partially correlated.
If you’d like to learn more about using Bayesian inference in everyday life, try our mini-course on The Question of Evidence . For a more math-oriented explanation, check out our course on Understanding Bayes’s Theorem .
6. Theories
Common in: psychology, economics
Given our theory, when X occurs, Y occurs.
Therefore Y will occur.
Example: “One theory is that depressed people are most at risk for suicide when they are beginning to come out of a really bad depression. So as depression is remitting, patients should be carefully screened for potentially increasing suicide risk factors.”
Example: “A common theory is that when inflation rises, unemployment falls. Inflation is rising, so we should predict that unemployment will fall.”
Advantages: Theories can make systems far more understandable to the human mind, and can be taught to others. Sometimes even very complex systems can be pretty well approximated with a simple theory. Theories allow us to make predictions about what will happen while only having to focus on a small amount of relevant information, without being bogged down by thousands of details.
Flaws: It can be very challenging to come up with reliable theories, and often you will not know how accurate such a theory is. Even if it has substantial truth to it and is right often, there may be cases where the opposite of what was predicted actually happens, and for reasons the theory can’t explain. Theories usually only capture part of what is going on in a particular situation, ignoring many variables so as to be more understandable. People often get too attached to particular theories, forgetting that theories are only approximations of reality, and so pretty much always have exceptions.
Common in: engineering, biology, physics
We know that X causes Y to occur.
Example: “Rusting of gears causes increased friction, leading to greater wear and tear. In this case, the gears were heavily rusted, so we expect to find a lot of wear.”
Example: “This gene produces this phenotype, and we see that this gene is present, so we expect to see the phenotype in the offspring.”
Advantages: If you understand the causal structure of a system, you may be able to make many powerful predictions about it, including predicting what would happen in many hypothetical situations that have never occurred before, and predicting what would happen if you were to intervene on the system in a particular way. This contrasts with (probabilistic) models that may be able to accurately predict what happens in common situations, but perform badly at predicting what will happen in novel situations and in situations where you intervene on the system (e.g. what would happen to the system if I purposely changed X).
Flaws: It’s often extremely hard to figure out causality in a highly complex system, especially in “softer” or "messier" subjects like nutrition and the social sciences. Purely statistical information (even an infinite amount of it) is not enough on its own to fully describe the causality of a system; additional assumptions need to be added. Often in practice we can only answer questions about causality by running randomized experiments (e.g. randomized controlled trials), which are typically expensive and sometimes infeasible, or by attempting to carefully control for all the potential confounding variables, a challenging and error-prone process.
Common in: politics, economics
This expert (or prediction market, or prediction algorithm) X is 90% accurate at predicting things in this general domain of prediction.
X predicts Y.
Example: “This prediction market has been right 90% of the time when predicting recent baseball outcomes, and in this case predicts the Yankees will win.”
Advantages: If you can find an expert or algorithm that has been proven to make reliable predictions in a particular domain, you can simply use these predictions yourself without even understanding how they are made.
Flaws: We often don’t have access to the predictions of experts (or of prediction markets, or prediction algorithms), and when we do, we usually don’t have reliable measures of their past accuracy. What's more, many experts whose predictions are publicly available have no clear track record of performance, or even purposely avoid accountability for poor performance (e.g. by hiding past prediction failures and touting past successes).
9. Metaphors
Common in: self-help, ancient philosophy, science education
X, which is what we are dealing with now, is metaphorically a Z.
For Z, when W is true, then obviously Y is true.
Now W (or its metaphorical equivalent) is true for X.
Therefore Y is true for X.
Example: “Your life is but a boat, and you are riding on the waves of your experiences. When a raging storm hits, a boat can’t be under full sail. It can’t continue at its maximum speed. You are experiencing a storm now, and so you too must learn to slow down.”
Example: "To better understand the nature of gasses, imagine tons of ping pong balls all shooting around in straight lines in random directions, and bouncing off of each other whenever they collide. These ping pong balls represent molecules of gas. Assuming the system is not inside a container, ping pong balls at the edges of the system have nothing to collide with, so they just fly outward, expanding the whole system. Similarly, the volume of a gas expands when it is placed in a vacuum."
Advantages: Our brains are good at understanding metaphors, so they can save us mental energy when we try to grasp difficult concepts. If the two items being compared in the metaphor are sufficiently alike in relevant ways, then the metaphor may accurately reveal elements of how its subject works.
Flaws: Z working as a metaphor for X doesn’t mean that all (or even most) predictions that are accurate for situations involving Z are appropriate (or even make any sense) for X. Metaphor-based reasoning can seem profound and persuasive even in cases when it makes little sense.
10. Similarities
Common in: the study of history, machine learning
X occurred, and X is very similar to Z in properties A, B and C.
When things similar to Z in properties A, B, and C occur, Y usually occurs.
Example: “This conflict is similar to the Gulf War in various ways, and from what we've learned about wars like the Gulf War, we can expect these sorts of outcomes.”
Example: “This data point (with unknown label) is closest in feature space to this other data point which is labeled ‘cat’, and all the other labeled points around that point are also labeled ‘cat’, so this unlabeled point should also likely get the label ‘cat’.”
Advantages: This approach can be applied at both small scale (with small numbers of examples) and at large scale (with millions of examples, as in machine learning algorithms), though of course large numbers of examples tend to produce more robust results. It can be viewed as a more powerful generalization of "frequencies"-based reasoning.
Flaws: In the history case, it is difficult to know which features are the appropriate ones to use to evaluate the similarity of two cases, and often the conclusions this approach produces are based on a relatively small number of examples. In the machine learning case, a very large amount of data may be needed to train the model (and it still may be unclear how to measure which examples are similar to which other cases, even with a lot of data). The properties you're using to compare cases must be sufficiently relevant to the prediction being made for it to work.
11. Anecdotes
Common in: daily life
In this handful of examples (or perhaps even just one example) where X occurred, Y occurred.
Example: “The last time we took that so-called 'shortcut' home, we got stuck in traffic for an extra 45 minutes. Let's not make that mistake again.”
Example: “My friend Bob tried that supplement and said it gave him more energy. So maybe it will give me more energy too."
Advantages: Anecdotes are simple to use, and a few of them are often all we have to work with for inference.
Flaws: Unless we are in a situation with very little noise/variability, a few examples likely will not be enough to accurately generalize. For instance, a few examples is not enough to make a reliable judgement about how often something occurs.
12. Intuition
My intuition (that I may have trouble explaining) predicts that when X occurs, Y is true.
Therefore Y is true.
Example: “The tone of voice he used when he talked about his family gave me a bad vibe. My feeling is that anyone who talks about their family with that tone of voice probably does not really love them.”
Example: "I can't explain why, but I'm pretty sure he's going to win this election."
Advantages: Our intuitions can be very well honed in situations we’ve encountered many times, and that we've received feedback on (i.e. where there was some sort of answer we got about how well our intuition performed). For instance, a surgeon who has conducted thousands of heart surgeries may have very good intuitions about what to do during surgery, or about how the patient will fare, even potentially very accurate intuitions that she can't easily articulate.
Flaws: In novel situations, or in situations where we receive no feedback on how well our instincts are performing, our intuitions may be highly inaccurate (even though we may not feel any less confident about our correctness).
Do you want to learn more about drawing conclusions from data?
If you'd like to know more about when intuition is reliable, try our 7-question guide to determining when you can trust your intuition.
We also have a full podcast episode about Mental models that apply across disciplines that you may like:
Click here to access other streaming options and show notes.
Recent Posts
We're launching a scientific test of astrology, and anyone can participate!
Problem-Solving Techniques That Work For All Types of Challenges
Remembering Daniel Kahneman: 7 theories that can help you understand how you think

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Overview of the Scientific Method
13 Drawing Conclusions and Reporting the Results
Learning objectives.
- Identify the conclusions researchers can make based on the outcome of their studies.
- Describe why scientists avoid the term “scientific proof.”
- Explain the different ways that scientists share their findings.
Drawing Conclusions
Since statistics are probabilistic in nature and findings can reflect type I or type II errors, we cannot use the results of a single study to conclude with certainty that a theory is true. Rather theories are supported, refuted, or modified based on the results of research.
If the results are statistically significant and consistent with the hypothesis and the theory that was used to generate the hypothesis, then researchers can conclude that the theory is supported. Not only did the theory make an accurate prediction, but there is now a new phenomenon that the theory accounts for. If a hypothesis is disconfirmed in a systematic empirical study, then the theory has been weakened. It made an inaccurate prediction, and there is now a new phenomenon that it does not account for.
Although this seems straightforward, there are some complications. First, confirming a hypothesis can strengthen a theory but it can never prove a theory. In fact, scientists tend to avoid the word “prove” when talking and writing about theories. One reason for this avoidance is that the result may reflect a type I error. Another reason for this avoidance is that there may be other plausible theories that imply the same hypothesis, which means that confirming the hypothesis strengthens all those theories equally. A third reason is that it is always possible that another test of the hypothesis or a test of a new hypothesis derived from the theory will be disconfirmed. This difficulty is a version of the famous philosophical “problem of induction.” One cannot definitively prove a general principle (e.g., “All swans are white.”) just by observing confirming cases (e.g., white swans)—no matter how many. It is always possible that a disconfirming case (e.g., a black swan) will eventually come along. For these reasons, scientists tend to think of theories—even highly successful ones—as subject to revision based on new and unexpected observations.
A second complication has to do with what it means when a hypothesis is disconfirmed. According to the strictest version of the hypothetico-deductive method, disconfirming a hypothesis disproves the theory it was derived from. In formal logic, the premises “if A then B ” and “not B ” necessarily lead to the conclusion “not A .” If A is the theory and B is the hypothesis (“if A then B ”), then disconfirming the hypothesis (“not B ”) must mean that the theory is incorrect (“not A ”). In practice, however, scientists do not give up on their theories so easily. One reason is that one disconfirmed hypothesis could be a missed opportunity (the result of a type II error) or it could be the result of a faulty research design. Perhaps the researcher did not successfully manipulate the independent variable or measure the dependent variable.
A disconfirmed hypothesis could also mean that some unstated but relatively minor assumption of the theory was not met. For example, if Zajonc had failed to find social facilitation in cockroaches, he could have concluded that drive theory is still correct but it applies only to animals with sufficiently complex nervous systems. That is, the evidence from a study can be used to modify a theory. This practice does not mean that researchers are free to ignore disconfirmations of their theories. If they cannot improve their research designs or modify their theories to account for repeated disconfirmations, then they eventually must abandon their theories and replace them with ones that are more successful.
The bottom line here is that because statistics are probabilistic in nature and because all research studies have flaws there is no such thing as scientific proof, there is only scientific evidence.
Reporting the Results
The final step in the research process involves reporting the results. As described in the section on Reviewing the Research Literature in this chapter, results are typically reported in peer-reviewed journal articles and at conferences.
The most prestigious way to report one’s findings is by writing a manuscript and having it published in a peer-reviewed scientific journal. Manuscripts published in psychology journals typically must adhere to the writing style of the American Psychological Association (APA style). You will likely be learning the major elements of this writing style in this course.
Another way to report findings is by writing a book chapter that is published in an edited book. Preferably the editor of the book puts the chapter through peer review but this is not always the case and some scientists are invited by editors to write book chapters.
A fun way to disseminate findings is to give a presentation at a conference. This can either be done as an oral presentation or a poster presentation. Oral presentations involve getting up in front of an audience of fellow scientists and giving a talk that might last anywhere from 10 minutes to 1 hour (depending on the conference) and then fielding questions from the audience. Alternatively, poster presentations involve summarizing the study on a large poster that provides a brief overview of the purpose, methods, results, and discussion. The presenter stands by their poster for an hour or two and discusses it with people who pass by. Presenting one’s work at a conference is a great way to get feedback from one’s peers before attempting to undergo the more rigorous peer-review process involved in publishing a journal article.
Research Methods in Psychology Copyright © 2019 by Rajiv S. Jhangiani, I-Chant A. Chiang, Carrie Cuttler, & Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Jump to navigation
Cochrane Training
Chapter 15: interpreting results and drawing conclusions.
Holger J Schünemann, Gunn E Vist, Julian PT Higgins, Nancy Santesso, Jonathan J Deeks, Paul Glasziou, Elie A Akl, Gordon H Guyatt; on behalf of the Cochrane GRADEing Methods Group
Key Points:
- This chapter provides guidance on interpreting the results of synthesis in order to communicate the conclusions of the review effectively.
- Methods are presented for computing, presenting and interpreting relative and absolute effects for dichotomous outcome data, including the number needed to treat (NNT).
- For continuous outcome measures, review authors can present summary results for studies using natural units of measurement or as minimal important differences when all studies use the same scale. When studies measure the same construct but with different scales, review authors will need to find a way to interpret the standardized mean difference, or to use an alternative effect measure for the meta-analysis such as the ratio of means.
- Review authors should not describe results as ‘statistically significant’, ‘not statistically significant’ or ‘non-significant’ or unduly rely on thresholds for P values, but report the confidence interval together with the exact P value.
- Review authors should not make recommendations about healthcare decisions, but they can – after describing the certainty of evidence and the balance of benefits and harms – highlight different actions that might be consistent with particular patterns of values and preferences and other factors that determine a decision such as cost.
Cite this chapter as: Schünemann HJ, Vist GE, Higgins JPT, Santesso N, Deeks JJ, Glasziou P, Akl EA, Guyatt GH. Chapter 15: Interpreting results and drawing conclusions. In: Higgins JPT, Thomas J, Chandler J, Cumpston M, Li T, Page MJ, Welch VA (editors). Cochrane Handbook for Systematic Reviews of Interventions version 6.4 (updated August 2023). Cochrane, 2023. Available from www.training.cochrane.org/handbook .
15.1 Introduction
The purpose of Cochrane Reviews is to facilitate healthcare decisions by patients and the general public, clinicians, guideline developers, administrators and policy makers. They also inform future research. A clear statement of findings, a considered discussion and a clear presentation of the authors’ conclusions are, therefore, important parts of the review. In particular, the following issues can help people make better informed decisions and increase the usability of Cochrane Reviews:
- information on all important outcomes, including adverse outcomes;
- the certainty of the evidence for each of these outcomes, as it applies to specific populations and specific interventions; and
- clarification of the manner in which particular values and preferences may bear on the desirable and undesirable consequences of the intervention.
A ‘Summary of findings’ table, described in Chapter 14 , Section 14.1 , provides key pieces of information about health benefits and harms in a quick and accessible format. It is highly desirable that review authors include a ‘Summary of findings’ table in Cochrane Reviews alongside a sufficient description of the studies and meta-analyses to support its contents. This description includes the rating of the certainty of evidence, also called the quality of the evidence or confidence in the estimates of the effects, which is expected in all Cochrane Reviews.
‘Summary of findings’ tables are usually supported by full evidence profiles which include the detailed ratings of the evidence (Guyatt et al 2011a, Guyatt et al 2013a, Guyatt et al 2013b, Santesso et al 2016). The Discussion section of the text of the review provides space to reflect and consider the implications of these aspects of the review’s findings. Cochrane Reviews include five standard subheadings to ensure the Discussion section places the review in an appropriate context: ‘Summary of main results (benefits and harms)’; ‘Potential biases in the review process’; ‘Overall completeness and applicability of evidence’; ‘Certainty of the evidence’; and ‘Agreements and disagreements with other studies or reviews’. Following the Discussion, the Authors’ conclusions section is divided into two standard subsections: ‘Implications for practice’ and ‘Implications for research’. The assessment of the certainty of evidence facilitates a structured description of the implications for practice and research.
Because Cochrane Reviews have an international audience, the Discussion and Authors’ conclusions should, so far as possible, assume a broad international perspective and provide guidance for how the results could be applied in different settings, rather than being restricted to specific national or local circumstances. Cultural differences and economic differences may both play an important role in determining the best course of action based on the results of a Cochrane Review. Furthermore, individuals within societies have widely varying values and preferences regarding health states, and use of societal resources to achieve particular health states. For all these reasons, and because information that goes beyond that included in a Cochrane Review is required to make fully informed decisions, different people will often make different decisions based on the same evidence presented in a review.
Thus, review authors should avoid specific recommendations that inevitably depend on assumptions about available resources, values and preferences, and other factors such as equity considerations, feasibility and acceptability of an intervention. The purpose of the review should be to present information and aid interpretation rather than to offer recommendations. The discussion and conclusions should help people understand the implications of the evidence in relation to practical decisions and apply the results to their specific situation. Review authors can aid this understanding of the implications by laying out different scenarios that describe certain value structures.
In this chapter, we address first one of the key aspects of interpreting findings that is also fundamental in completing a ‘Summary of findings’ table: the certainty of evidence related to each of the outcomes. We then provide a more detailed consideration of issues around applicability and around interpretation of numerical results, and provide suggestions for presenting authors’ conclusions.
15.2 Issues of indirectness and applicability
15.2.1 the role of the review author.
“A leap of faith is always required when applying any study findings to the population at large” or to a specific person. “In making that jump, one must always strike a balance between making justifiable broad generalizations and being too conservative in one’s conclusions” (Friedman et al 1985). In addition to issues about risk of bias and other domains determining the certainty of evidence, this leap of faith is related to how well the identified body of evidence matches the posed PICO ( Population, Intervention, Comparator(s) and Outcome ) question. As to the population, no individual can be entirely matched to the population included in research studies. At the time of decision, there will always be differences between the study population and the person or population to whom the evidence is applied; sometimes these differences are slight, sometimes large.
The terms applicability, generalizability, external validity and transferability are related, sometimes used interchangeably and have in common that they lack a clear and consistent definition in the classic epidemiological literature (Schünemann et al 2013). However, all of the terms describe one overarching theme: whether or not available research evidence can be directly used to answer the health and healthcare question at hand, ideally supported by a judgement about the degree of confidence in this use (Schünemann et al 2013). GRADE’s certainty domains include a judgement about ‘indirectness’ to describe all of these aspects including the concept of direct versus indirect comparisons of different interventions (Atkins et al 2004, Guyatt et al 2008, Guyatt et al 2011b).
To address adequately the extent to which a review is relevant for the purpose to which it is being put, there are certain things the review author must do, and certain things the user of the review must do to assess the degree of indirectness. Cochrane and the GRADE Working Group suggest using a very structured framework to address indirectness. We discuss here and in Chapter 14 what the review author can do to help the user. Cochrane Review authors must be extremely clear on the population, intervention and outcomes that they intend to address. Chapter 14, Section 14.1.2 , also emphasizes a crucial step: the specification of all patient-important outcomes relevant to the intervention strategies under comparison.
In considering whether the effect of an intervention applies equally to all participants, and whether different variations on the intervention have similar effects, review authors need to make a priori hypotheses about possible effect modifiers, and then examine those hypotheses (see Chapter 10, Section 10.10 and Section 10.11 ). If they find apparent subgroup effects, they must ultimately decide whether or not these effects are credible (Sun et al 2012). Differences between subgroups, particularly those that correspond to differences between studies, should be interpreted cautiously. Some chance variation between subgroups is inevitable so, unless there is good reason to believe that there is an interaction, review authors should not assume that the subgroup effect exists. If, despite due caution, review authors judge subgroup effects in terms of relative effect estimates as credible (i.e. the effects differ credibly), they should conduct separate meta-analyses for the relevant subgroups, and produce separate ‘Summary of findings’ tables for those subgroups.
The user of the review will be challenged with ‘individualization’ of the findings, whether they seek to apply the findings to an individual patient or a policy decision in a specific context. For example, even if relative effects are similar across subgroups, absolute effects will differ according to baseline risk. Review authors can help provide this information by identifying identifiable groups of people with varying baseline risks in the ‘Summary of findings’ tables, as discussed in Chapter 14, Section 14.1.3 . Users can then identify their specific case or population as belonging to a particular risk group, if relevant, and assess their likely magnitude of benefit or harm accordingly. A description of the identifying prognostic or baseline risk factors in a brief scenario (e.g. age or gender) will help users of a review further.
Another decision users must make is whether their individual case or population of interest is so different from those included in the studies that they cannot use the results of the systematic review and meta-analysis at all. Rather than rigidly applying the inclusion and exclusion criteria of studies, it is better to ask whether or not there are compelling reasons why the evidence should not be applied to a particular patient. Review authors can sometimes help decision makers by identifying important variation where divergence might limit the applicability of results (Rothwell 2005, Schünemann et al 2006, Guyatt et al 2011b, Schünemann et al 2013), including biologic and cultural variation, and variation in adherence to an intervention.
In addressing these issues, review authors cannot be aware of, or address, the myriad of differences in circumstances around the world. They can, however, address differences of known importance to many people and, importantly, they should avoid assuming that other people’s circumstances are the same as their own in discussing the results and drawing conclusions.
15.2.2 Biological variation
Issues of biological variation that may affect the applicability of a result to a reader or population include divergence in pathophysiology (e.g. biological differences between women and men that may affect responsiveness to an intervention) and divergence in a causative agent (e.g. for infectious diseases such as malaria, which may be caused by several different parasites). The discussion of the results in the review should make clear whether the included studies addressed all or only some of these groups, and whether any important subgroup effects were found.
15.2.3 Variation in context
Some interventions, particularly non-pharmacological interventions, may work in some contexts but not in others; the situation has been described as program by context interaction (Hawe et al 2004). Contextual factors might pertain to the host organization in which an intervention is offered, such as the expertise, experience and morale of the staff expected to carry out the intervention, the competing priorities for the clinician’s or staff’s attention, the local resources such as service and facilities made available to the program and the status or importance given to the program by the host organization. Broader context issues might include aspects of the system within which the host organization operates, such as the fee or payment structure for healthcare providers and the local insurance system. Some interventions, in particular complex interventions (see Chapter 17 ), can be only partially implemented in some contexts, and this requires judgements about indirectness of the intervention and its components for readers in that context (Schünemann 2013).
Contextual factors may also pertain to the characteristics of the target group or population, such as cultural and linguistic diversity, socio-economic position, rural/urban setting. These factors may mean that a particular style of care or relationship evolves between service providers and consumers that may or may not match the values and technology of the program.
For many years these aspects have been acknowledged when decision makers have argued that results of evidence reviews from other countries do not apply in their own country or setting. Whilst some programmes/interventions have been successfully transferred from one context to another, others have not (Resnicow et al 1993, Lumley et al 2004, Coleman et al 2015). Review authors should be cautious when making generalizations from one context to another. They should report on the presence (or otherwise) of context-related information in intervention studies, where this information is available.
15.2.4 Variation in adherence
Variation in the adherence of the recipients and providers of care can limit the certainty in the applicability of results. Predictable differences in adherence can be due to divergence in how recipients of care perceive the intervention (e.g. the importance of side effects), economic conditions or attitudes that make some forms of care inaccessible in some settings, such as in low-income countries (Dans et al 2007). It should not be assumed that high levels of adherence in closely monitored randomized trials will translate into similar levels of adherence in normal practice.
15.2.5 Variation in values and preferences
Decisions about healthcare management strategies and options involve trading off health benefits and harms. The right choice may differ for people with different values and preferences (i.e. the importance people place on the outcomes and interventions), and it is important that decision makers ensure that decisions are consistent with a patient or population’s values and preferences. The importance placed on outcomes, together with other factors, will influence whether the recipients of care will or will not accept an option that is offered (Alonso-Coello et al 2016) and, thus, can be one factor influencing adherence. In Section 15.6 , we describe how the review author can help this process and the limits of supporting decision making based on intervention reviews.
15.3 Interpreting results of statistical analyses
15.3.1 confidence intervals.
Results for both individual studies and meta-analyses are reported with a point estimate together with an associated confidence interval. For example, ‘The odds ratio was 0.75 with a 95% confidence interval of 0.70 to 0.80’. The point estimate (0.75) is the best estimate of the magnitude and direction of the experimental intervention’s effect compared with the comparator intervention. The confidence interval describes the uncertainty inherent in any estimate, and describes a range of values within which we can be reasonably sure that the true effect actually lies. If the confidence interval is relatively narrow (e.g. 0.70 to 0.80), the effect size is known precisely. If the interval is wider (e.g. 0.60 to 0.93) the uncertainty is greater, although there may still be enough precision to make decisions about the utility of the intervention. Intervals that are very wide (e.g. 0.50 to 1.10) indicate that we have little knowledge about the effect and this imprecision affects our certainty in the evidence, and that further information would be needed before we could draw a more certain conclusion.
A 95% confidence interval is often interpreted as indicating a range within which we can be 95% certain that the true effect lies. This statement is a loose interpretation, but is useful as a rough guide. The strictly correct interpretation of a confidence interval is based on the hypothetical notion of considering the results that would be obtained if the study were repeated many times. If a study were repeated infinitely often, and on each occasion a 95% confidence interval calculated, then 95% of these intervals would contain the true effect (see Section 15.3.3 for further explanation).
The width of the confidence interval for an individual study depends to a large extent on the sample size. Larger studies tend to give more precise estimates of effects (and hence have narrower confidence intervals) than smaller studies. For continuous outcomes, precision depends also on the variability in the outcome measurements (i.e. how widely individual results vary between people in the study, measured as the standard deviation); for dichotomous outcomes it depends on the risk of the event (more frequent events allow more precision, and narrower confidence intervals), and for time-to-event outcomes it also depends on the number of events observed. All these quantities are used in computation of the standard errors of effect estimates from which the confidence interval is derived.
The width of a confidence interval for a meta-analysis depends on the precision of the individual study estimates and on the number of studies combined. In addition, for random-effects models, precision will decrease with increasing heterogeneity and confidence intervals will widen correspondingly (see Chapter 10, Section 10.10.4 ). As more studies are added to a meta-analysis the width of the confidence interval usually decreases. However, if the additional studies increase the heterogeneity in the meta-analysis and a random-effects model is used, it is possible that the confidence interval width will increase.
Confidence intervals and point estimates have different interpretations in fixed-effect and random-effects models. While the fixed-effect estimate and its confidence interval address the question ‘what is the best (single) estimate of the effect?’, the random-effects estimate assumes there to be a distribution of effects, and the estimate and its confidence interval address the question ‘what is the best estimate of the average effect?’ A confidence interval may be reported for any level of confidence (although they are most commonly reported for 95%, and sometimes 90% or 99%). For example, the odds ratio of 0.80 could be reported with an 80% confidence interval of 0.73 to 0.88; a 90% interval of 0.72 to 0.89; and a 95% interval of 0.70 to 0.92. As the confidence level increases, the confidence interval widens.
There is logical correspondence between the confidence interval and the P value (see Section 15.3.3 ). The 95% confidence interval for an effect will exclude the null value (such as an odds ratio of 1.0 or a risk difference of 0) if and only if the test of significance yields a P value of less than 0.05. If the P value is exactly 0.05, then either the upper or lower limit of the 95% confidence interval will be at the null value. Similarly, the 99% confidence interval will exclude the null if and only if the test of significance yields a P value of less than 0.01.
Together, the point estimate and confidence interval provide information to assess the effects of the intervention on the outcome. For example, suppose that we are evaluating an intervention that reduces the risk of an event and we decide that it would be useful only if it reduced the risk of an event from 30% by at least 5 percentage points to 25% (these values will depend on the specific clinical scenario and outcomes, including the anticipated harms). If the meta-analysis yielded an effect estimate of a reduction of 10 percentage points with a tight 95% confidence interval, say, from 7% to 13%, we would be able to conclude that the intervention was useful since both the point estimate and the entire range of the interval exceed our criterion of a reduction of 5% for net health benefit. However, if the meta-analysis reported the same risk reduction of 10% but with a wider interval, say, from 2% to 18%, although we would still conclude that our best estimate of the intervention effect is that it provides net benefit, we could not be so confident as we still entertain the possibility that the effect could be between 2% and 5%. If the confidence interval was wider still, and included the null value of a difference of 0%, we would still consider the possibility that the intervention has no effect on the outcome whatsoever, and would need to be even more sceptical in our conclusions.
Review authors may use the same general approach to conclude that an intervention is not useful. Continuing with the above example where the criterion for an important difference that should be achieved to provide more benefit than harm is a 5% risk difference, an effect estimate of 2% with a 95% confidence interval of 1% to 4% suggests that the intervention does not provide net health benefit.
15.3.2 P values and statistical significance
A P value is the standard result of a statistical test, and is the probability of obtaining the observed effect (or larger) under a ‘null hypothesis’. In the context of Cochrane Reviews there are two commonly used statistical tests. The first is a test of overall effect (a Z-test), and its null hypothesis is that there is no overall effect of the experimental intervention compared with the comparator on the outcome of interest. The second is the (Chi 2 ) test for heterogeneity, and its null hypothesis is that there are no differences in the intervention effects across studies.
A P value that is very small indicates that the observed effect is very unlikely to have arisen purely by chance, and therefore provides evidence against the null hypothesis. It has been common practice to interpret a P value by examining whether it is smaller than particular threshold values. In particular, P values less than 0.05 are often reported as ‘statistically significant’, and interpreted as being small enough to justify rejection of the null hypothesis. However, the 0.05 threshold is an arbitrary one that became commonly used in medical and psychological research largely because P values were determined by comparing the test statistic against tabulations of specific percentage points of statistical distributions. If review authors decide to present a P value with the results of a meta-analysis, they should report a precise P value (as calculated by most statistical software), together with the 95% confidence interval. Review authors should not describe results as ‘statistically significant’, ‘not statistically significant’ or ‘non-significant’ or unduly rely on thresholds for P values , but report the confidence interval together with the exact P value (see MECIR Box 15.3.a ).
We discuss interpretation of the test for heterogeneity in Chapter 10, Section 10.10.2 ; the remainder of this section refers mainly to tests for an overall effect. For tests of an overall effect, the computation of P involves both the effect estimate and precision of the effect estimate (driven largely by sample size). As precision increases, the range of plausible effects that could occur by chance is reduced. Correspondingly, the statistical significance of an effect of a particular magnitude will usually be greater (the P value will be smaller) in a larger study than in a smaller study.
P values are commonly misinterpreted in two ways. First, a moderate or large P value (e.g. greater than 0.05) may be misinterpreted as evidence that the intervention has no effect on the outcome. There is an important difference between this statement and the correct interpretation that there is a high probability that the observed effect on the outcome is due to chance alone. To avoid such a misinterpretation, review authors should always examine the effect estimate and its 95% confidence interval.
The second misinterpretation is to assume that a result with a small P value for the summary effect estimate implies that an experimental intervention has an important benefit. Such a misinterpretation is more likely to occur in large studies and meta-analyses that accumulate data over dozens of studies and thousands of participants. The P value addresses the question of whether the experimental intervention effect is precisely nil; it does not examine whether the effect is of a magnitude of importance to potential recipients of the intervention. In a large study, a small P value may represent the detection of a trivial effect that may not lead to net health benefit when compared with the potential harms (i.e. harmful effects on other important outcomes). Again, inspection of the point estimate and confidence interval helps correct interpretations (see Section 15.3.1 ).
MECIR Box 15.3.a Relevant expectations for conduct of intervention reviews
15.3.3 Relation between confidence intervals, statistical significance and certainty of evidence
The confidence interval (and imprecision) is only one domain that influences overall uncertainty about effect estimates. Uncertainty resulting from imprecision (i.e. statistical uncertainty) may be no less important than uncertainty from indirectness, or any other GRADE domain, in the context of decision making (Schünemann 2016). Thus, the extent to which interpretations of the confidence interval described in Sections 15.3.1 and 15.3.2 correspond to conclusions about overall certainty of the evidence for the outcome of interest depends on these other domains. If there are no concerns about other domains that determine the certainty of the evidence (i.e. risk of bias, inconsistency, indirectness or publication bias), then the interpretation in Sections 15.3.1 and 15.3.2 . about the relation of the confidence interval to the true effect may be carried forward to the overall certainty. However, if there are concerns about the other domains that affect the certainty of the evidence, the interpretation about the true effect needs to be seen in the context of further uncertainty resulting from those concerns.
For example, nine randomized controlled trials in almost 6000 cancer patients indicated that the administration of heparin reduces the risk of venous thromboembolism (VTE), with a risk ratio of 43% (95% CI 19% to 60%) (Akl et al 2011a). For patients with a plausible baseline risk of approximately 4.6% per year, this relative effect suggests that heparin leads to an absolute risk reduction of 20 fewer VTEs (95% CI 9 fewer to 27 fewer) per 1000 people per year (Akl et al 2011a). Now consider that the review authors or those applying the evidence in a guideline have lowered the certainty in the evidence as a result of indirectness. While the confidence intervals would remain unchanged, the certainty in that confidence interval and in the point estimate as reflecting the truth for the question of interest will be lowered. In fact, the certainty range will have unknown width so there will be unknown likelihood of a result within that range because of this indirectness. The lower the certainty in the evidence, the less we know about the width of the certainty range, although methods for quantifying risk of bias and understanding potential direction of bias may offer insight when lowered certainty is due to risk of bias. Nevertheless, decision makers must consider this uncertainty, and must do so in relation to the effect measure that is being evaluated (e.g. a relative or absolute measure). We will describe the impact on interpretations for dichotomous outcomes in Section 15.4 .
15.4 Interpreting results from dichotomous outcomes (including numbers needed to treat)
15.4.1 relative and absolute risk reductions.
Clinicians may be more inclined to prescribe an intervention that reduces the relative risk of death by 25% than one that reduces the risk of death by 1 percentage point, although both presentations of the evidence may relate to the same benefit (i.e. a reduction in risk from 4% to 3%). The former refers to the relative reduction in risk and the latter to the absolute reduction in risk. As described in Chapter 6, Section 6.4.1 , there are several measures for comparing dichotomous outcomes in two groups. Meta-analyses are usually undertaken using risk ratios (RR), odds ratios (OR) or risk differences (RD), but there are several alternative ways of expressing results.
Relative risk reduction (RRR) is a convenient way of re-expressing a risk ratio as a percentage reduction:

For example, a risk ratio of 0.75 translates to a relative risk reduction of 25%, as in the example above.
The risk difference is often referred to as the absolute risk reduction (ARR) or absolute risk increase (ARI), and may be presented as a percentage (e.g. 1%), as a decimal (e.g. 0.01), or as account (e.g. 10 out of 1000). We consider different choices for presenting absolute effects in Section 15.4.3 . We then describe computations for obtaining these numbers from the results of individual studies and of meta-analyses in Section 15.4.4 .
15.4.2 Number needed to treat (NNT)
The number needed to treat (NNT) is a common alternative way of presenting information on the effect of an intervention. The NNT is defined as the expected number of people who need to receive the experimental rather than the comparator intervention for one additional person to either incur or avoid an event (depending on the direction of the result) in a given time frame. Thus, for example, an NNT of 10 can be interpreted as ‘it is expected that one additional (or less) person will incur an event for every 10 participants receiving the experimental intervention rather than comparator over a given time frame’. It is important to be clear that:
- since the NNT is derived from the risk difference, it is still a comparative measure of effect (experimental versus a specific comparator) and not a general property of a single intervention; and
- the NNT gives an ‘expected value’. For example, NNT = 10 does not imply that one additional event will occur in each and every group of 10 people.
NNTs can be computed for both beneficial and detrimental events, and for interventions that cause both improvements and deteriorations in outcomes. In all instances NNTs are expressed as positive whole numbers. Some authors use the term ‘number needed to harm’ (NNH) when an intervention leads to an adverse outcome, or a decrease in a positive outcome, rather than improvement. However, this phrase can be misleading (most notably, it can easily be read to imply the number of people who will experience a harmful outcome if given the intervention), and it is strongly recommended that ‘number needed to harm’ and ‘NNH’ are avoided. The preferred alternative is to use phrases such as ‘number needed to treat for an additional beneficial outcome’ (NNTB) and ‘number needed to treat for an additional harmful outcome’ (NNTH) to indicate direction of effect.
As NNTs refer to events, their interpretation needs to be worded carefully when the binary outcome is a dichotomization of a scale-based outcome. For example, if the outcome is pain measured on a ‘none, mild, moderate or severe’ scale it may have been dichotomized as ‘none or mild’ versus ‘moderate or severe’. It would be inappropriate for an NNT from these data to be referred to as an ‘NNT for pain’. It is an ‘NNT for moderate or severe pain’.
We consider different choices for presenting absolute effects in Section 15.4.3 . We then describe computations for obtaining these numbers from the results of individual studies and of meta-analyses in Section 15.4.4 .
15.4.3 Expressing risk differences
Users of reviews are liable to be influenced by the choice of statistical presentations of the evidence. Hoffrage and colleagues suggest that physicians’ inferences about statistical outcomes are more appropriate when they deal with ‘natural frequencies’ – whole numbers of people, both treated and untreated (e.g. treatment results in a drop from 20 out of 1000 to 10 out of 1000 women having breast cancer) – than when effects are presented as percentages (e.g. 1% absolute reduction in breast cancer risk) (Hoffrage et al 2000). Probabilities may be more difficult to understand than frequencies, particularly when events are rare. While standardization may be important in improving the presentation of research evidence (and participation in healthcare decisions), current evidence suggests that the presentation of natural frequencies for expressing differences in absolute risk is best understood by consumers of healthcare information (Akl et al 2011b). This evidence provides the rationale for presenting absolute risks in ‘Summary of findings’ tables as numbers of people with events per 1000 people receiving the intervention (see Chapter 14 ).
RRs and RRRs remain crucial because relative effects tend to be substantially more stable across risk groups than absolute effects (see Chapter 10, Section 10.4.3 ). Review authors can use their own data to study this consistency (Cates 1999, Smeeth et al 1999). Risk differences from studies are least likely to be consistent across baseline event rates; thus, they are rarely appropriate for computing numbers needed to treat in systematic reviews. If a relative effect measure (OR or RR) is chosen for meta-analysis, then a comparator group risk needs to be specified as part of the calculation of an RD or NNT. In addition, if there are several different groups of participants with different levels of risk, it is crucial to express absolute benefit for each clinically identifiable risk group, clarifying the time period to which this applies. Studies in patients with differing severity of disease, or studies with different lengths of follow-up will almost certainly have different comparator group risks. In these cases, different comparator group risks lead to different RDs and NNTs (except when the intervention has no effect). A recommended approach is to re-express an odds ratio or a risk ratio as a variety of RD or NNTs across a range of assumed comparator risks (ACRs) (McQuay and Moore 1997, Smeeth et al 1999). Review authors should bear these considerations in mind not only when constructing their ‘Summary of findings’ table, but also in the text of their review.
For example, a review of oral anticoagulants to prevent stroke presented information to users by describing absolute benefits for various baseline risks (Aguilar and Hart 2005, Aguilar et al 2007). They presented their principal findings as “The inherent risk of stroke should be considered in the decision to use oral anticoagulants in atrial fibrillation patients, selecting those who stand to benefit most for this therapy” (Aguilar and Hart 2005). Among high-risk atrial fibrillation patients with prior stroke or transient ischaemic attack who have stroke rates of about 12% (120 per 1000) per year, warfarin prevents about 70 strokes yearly per 1000 patients, whereas for low-risk atrial fibrillation patients (with a stroke rate of about 2% per year or 20 per 1000), warfarin prevents only 12 strokes. This presentation helps users to understand the important impact that typical baseline risks have on the absolute benefit that they can expect.
15.4.4 Computations
Direct computation of risk difference (RD) or a number needed to treat (NNT) depends on the summary statistic (odds ratio, risk ratio or risk differences) available from the study or meta-analysis. When expressing results of meta-analyses, review authors should use, in the computations, whatever statistic they determined to be the most appropriate summary for meta-analysis (see Chapter 10, Section 10.4.3 ). Here we present calculations to obtain RD as a reduction in the number of participants per 1000. For example, a risk difference of –0.133 corresponds to 133 fewer participants with the event per 1000.
RDs and NNTs should not be computed from the aggregated total numbers of participants and events across the trials. This approach ignores the randomization within studies, and may produce seriously misleading results if there is unbalanced randomization in any of the studies. Using the pooled result of a meta-analysis is more appropriate. When computing NNTs, the values obtained are by convention always rounded up to the next whole number.
15.4.4.1 Computing NNT from a risk difference (RD)
A NNT may be computed from a risk difference as

where the vertical bars (‘absolute value of’) in the denominator indicate that any minus sign should be ignored. It is convention to round the NNT up to the nearest whole number. For example, if the risk difference is –0.12 the NNT is 9; if the risk difference is –0.22 the NNT is 5. Cochrane Review authors should qualify the NNT as referring to benefit (improvement) or harm by denoting the NNT as NNTB or NNTH. Note that this approach, although feasible, should be used only for the results of a meta-analysis of risk differences. In most cases meta-analyses will be undertaken using a relative measure of effect (RR or OR), and those statistics should be used to calculate the NNT (see Section 15.4.4.2 and 15.4.4.3 ).
15.4.4.2 Computing risk differences or NNT from a risk ratio
To aid interpretation of the results of a meta-analysis of risk ratios, review authors may compute an absolute risk reduction or NNT. In order to do this, an assumed comparator risk (ACR) (otherwise known as a baseline risk, or risk that the outcome of interest would occur with the comparator intervention) is required. It will usually be appropriate to do this for a range of different ACRs. The computation proceeds as follows:

As an example, suppose the risk ratio is RR = 0.92, and an ACR = 0.3 (300 per 1000) is assumed. Then the effect on risk is 24 fewer per 1000:

The NNT is 42:

15.4.4.3 Computing risk differences or NNT from an odds ratio
Review authors may wish to compute a risk difference or NNT from the results of a meta-analysis of odds ratios. In order to do this, an ACR is required. It will usually be appropriate to do this for a range of different ACRs. The computation proceeds as follows:

As an example, suppose the odds ratio is OR = 0.73, and a comparator risk of ACR = 0.3 is assumed. Then the effect on risk is 62 fewer per 1000:

The NNT is 17:

15.4.4.4 Computing risk ratio from an odds ratio
Because risk ratios are easier to interpret than odds ratios, but odds ratios have favourable mathematical properties, a review author may decide to undertake a meta-analysis based on odds ratios, but to express the result as a summary risk ratio (or relative risk reduction). This requires an ACR. Then

It will often be reasonable to perform this transformation using the median comparator group risk from the studies in the meta-analysis.
15.4.4.5 Computing confidence limits
Confidence limits for RDs and NNTs may be calculated by applying the above formulae to the upper and lower confidence limits for the summary statistic (RD, RR or OR) (Altman 1998). Note that this confidence interval does not incorporate uncertainty around the ACR.
If the 95% confidence interval of OR or RR includes the value 1, one of the confidence limits will indicate benefit and the other harm. Thus, appropriate use of the words ‘fewer’ and ‘more’ is required for each limit when presenting results in terms of events. For NNTs, the two confidence limits should be labelled as NNTB and NNTH to indicate the direction of effect in each case. The confidence interval for the NNT will include a ‘discontinuity’, because increasingly smaller risk differences that approach zero will lead to NNTs approaching infinity. Thus, the confidence interval will include both an infinitely large NNTB and an infinitely large NNTH.
15.5 Interpreting results from continuous outcomes (including standardized mean differences)
15.5.1 meta-analyses with continuous outcomes.
Review authors should describe in the study protocol how they plan to interpret results for continuous outcomes. When outcomes are continuous, review authors have a number of options to present summary results. These options differ if studies report the same measure that is familiar to the target audiences, studies report the same or very similar measures that are less familiar to the target audiences, or studies report different measures.
15.5.2 Meta-analyses with continuous outcomes using the same measure
If all studies have used the same familiar units, for instance, results are expressed as durations of events, such as symptoms for conditions including diarrhoea, sore throat, otitis media, influenza or duration of hospitalization, a meta-analysis may generate a summary estimate in those units, as a difference in mean response (see, for instance, the row summarizing results for duration of diarrhoea in Chapter 14, Figure 14.1.b and the row summarizing oedema in Chapter 14, Figure 14.1.a ). For such outcomes, the ‘Summary of findings’ table should include a difference of means between the two interventions. However, when units of such outcomes may be difficult to interpret, particularly when they relate to rating scales (again, see the oedema row of Chapter 14, Figure 14.1.a ). ‘Summary of findings’ tables should include the minimum and maximum of the scale of measurement, and the direction. Knowledge of the smallest change in instrument score that patients perceive is important – the minimal important difference (MID) – and can greatly facilitate the interpretation of results (Guyatt et al 1998, Schünemann and Guyatt 2005). Knowing the MID allows review authors and users to place results in context. Review authors should state the MID – if known – in the Comments column of their ‘Summary of findings’ table. For example, the chronic respiratory questionnaire has possible scores in health-related quality of life ranging from 1 to 7 and 0.5 represents a well-established MID (Jaeschke et al 1989, Schünemann et al 2005).
15.5.3 Meta-analyses with continuous outcomes using different measures
When studies have used different instruments to measure the same construct, a standardized mean difference (SMD) may be used in meta-analysis for combining continuous data. Without guidance, clinicians and patients may have little idea how to interpret results presented as SMDs. Review authors should therefore consider issues of interpretability when planning their analysis at the protocol stage and should consider whether there will be suitable ways to re-express the SMD or whether alternative effect measures, such as a ratio of means, or possibly as minimal important difference units (Guyatt et al 2013b) should be used. Table 15.5.a and the following sections describe these options.
Table 15.5.a Approaches and their implications to presenting results of continuous variables when primary studies have used different instruments to measure the same construct. Adapted from Guyatt et al (2013b)
15.5.3.1 Presenting and interpreting SMDs using generic effect size estimates
The SMD expresses the intervention effect in standard units rather than the original units of measurement. The SMD is the difference in mean effects between the experimental and comparator groups divided by the pooled standard deviation of participants’ outcomes, or external SDs when studies are very small (see Chapter 6, Section 6.5.1.2 ). The value of a SMD thus depends on both the size of the effect (the difference between means) and the standard deviation of the outcomes (the inherent variability among participants or based on an external SD).
If review authors use the SMD, they might choose to present the results directly as SMDs (row 1a, Table 15.5.a and Table 15.5.b ). However, absolute values of the intervention and comparison groups are typically not useful because studies have used different measurement instruments with different units. Guiding rules for interpreting SMDs (or ‘Cohen’s effect sizes’) exist, and have arisen mainly from researchers in the social sciences (Cohen 1988). One example is as follows: 0.2 represents a small effect, 0.5 a moderate effect and 0.8 a large effect (Cohen 1988). Variations exist (e.g. <0.40=small, 0.40 to 0.70=moderate, >0.70=large). Review authors might consider including such a guiding rule in interpreting the SMD in the text of the review, and in summary versions such as the Comments column of a ‘Summary of findings’ table. However, some methodologists believe that such interpretations are problematic because patient importance of a finding is context-dependent and not amenable to generic statements.
15.5.3.2 Re-expressing SMDs using a familiar instrument
The second possibility for interpreting the SMD is to express it in the units of one or more of the specific measurement instruments used by the included studies (row 1b, Table 15.5.a and Table 15.5.b ). The approach is to calculate an absolute difference in means by multiplying the SMD by an estimate of the SD associated with the most familiar instrument. To obtain this SD, a reasonable option is to calculate a weighted average across all intervention groups of all studies that used the selected instrument (preferably a pre-intervention or post-intervention SD as discussed in Chapter 10, Section 10.5.2 ). To better reflect among-person variation in practice, or to use an instrument not represented in the meta-analysis, it may be preferable to use a standard deviation from a representative observational study. The summary effect is thus re-expressed in the original units of that particular instrument and the clinical relevance and impact of the intervention effect can be interpreted using that familiar instrument.
The same approach of re-expressing the results for a familiar instrument can also be used for other standardized effect measures such as when standardizing by MIDs (Guyatt et al 2013b): see Section 15.5.3.5 .
Table 15.5.b Application of approaches when studies have used different measures: effects of dexamethasone for pain after laparoscopic cholecystectomy (Karanicolas et al 2008). Reproduced with permission of Wolters Kluwer
1 Certainty rated according to GRADE from very low to high certainty. 2 Substantial unexplained heterogeneity in study results. 3 Imprecision due to wide confidence intervals. 4 The 20% comes from the proportion in the control group requiring rescue analgesia. 5 Crude (arithmetic) means of the post-operative pain mean responses across all five trials when transformed to a 100-point scale.
15.5.3.3 Re-expressing SMDs through dichotomization and transformation to relative and absolute measures
A third approach (row 1c, Table 15.5.a and Table 15.5.b ) relies on converting the continuous measure into a dichotomy and thus allows calculation of relative and absolute effects on a binary scale. A transformation of a SMD to a (log) odds ratio is available, based on the assumption that an underlying continuous variable has a logistic distribution with equal standard deviation in the two intervention groups, as discussed in Chapter 10, Section 10.6 (Furukawa 1999, Guyatt et al 2013b). The assumption is unlikely to hold exactly and the results must be regarded as an approximation. The log odds ratio is estimated as

(or approximately 1.81✕SMD). The resulting odds ratio can then be presented as normal, and in a ‘Summary of findings’ table, combined with an assumed comparator group risk to be expressed as an absolute risk difference. The comparator group risk in this case would refer to the proportion of people who have achieved a specific value of the continuous outcome. In randomized trials this can be interpreted as the proportion who have improved by some (specified) amount (responders), for instance by 5 points on a 0 to 100 scale. Table 15.5.c shows some illustrative results from this method. The risk differences can then be converted to NNTs or to people per thousand using methods described in Section 15.4.4 .
Table 15.5.c Risk difference derived for specific SMDs for various given ‘proportions improved’ in the comparator group (Furukawa 1999, Guyatt et al 2013b). Reproduced with permission of Elsevier
15.5.3.4 Ratio of means
A more frequently used approach is based on calculation of a ratio of means between the intervention and comparator groups (Friedrich et al 2008) as discussed in Chapter 6, Section 6.5.1.3 . Interpretational advantages of this approach include the ability to pool studies with outcomes expressed in different units directly, to avoid the vulnerability of heterogeneous populations that limits approaches that rely on SD units, and for ease of clinical interpretation (row 2, Table 15.5.a and Table 15.5.b ). This method is currently designed for post-intervention scores only. However, it is possible to calculate a ratio of change scores if both intervention and comparator groups change in the same direction in each relevant study, and this ratio may sometimes be informative.
Limitations to this approach include its limited applicability to change scores (since it is unlikely that both intervention and comparator group changes are in the same direction in all studies) and the possibility of misleading results if the comparator group mean is very small, in which case even a modest difference from the intervention group will yield a large and therefore misleading ratio of means. It also requires that separate ratios of means be calculated for each included study, and then entered into a generic inverse variance meta-analysis (see Chapter 10, Section 10.3 ).
The ratio of means approach illustrated in Table 15.5.b suggests a relative reduction in pain of only 13%, meaning that those receiving steroids have a pain severity 87% of those in the comparator group, an effect that might be considered modest.
15.5.3.5 Presenting continuous results as minimally important difference units
To express results in MID units, review authors have two options. First, they can be combined across studies in the same way as the SMD, but instead of dividing the mean difference of each study by its SD, review authors divide by the MID associated with that outcome (Johnston et al 2010, Guyatt et al 2013b). Instead of SD units, the pooled results represent MID units (row 3, Table 15.5.a and Table 15.5.b ), and may be more easily interpretable. This approach avoids the problem of varying SDs across studies that may distort estimates of effect in approaches that rely on the SMD. The approach, however, relies on having well-established MIDs. The approach is also risky in that a difference less than the MID may be interpreted as trivial when a substantial proportion of patients may have achieved an important benefit.
The other approach makes a simple conversion (not shown in Table 15.5.b ), before undertaking the meta-analysis, of the means and SDs from each study to means and SDs on the scale of a particular familiar instrument whose MID is known. For example, one can rescale the mean and SD of other chronic respiratory disease instruments (e.g. rescaling a 0 to 100 score of an instrument) to a the 1 to 7 score in Chronic Respiratory Disease Questionnaire (CRQ) units (by assuming 0 equals 1 and 100 equals 7 on the CRQ). Given the MID of the CRQ of 0.5, a mean difference in change of 0.71 after rescaling of all studies suggests a substantial effect of the intervention (Guyatt et al 2013b). This approach, presenting in units of the most familiar instrument, may be the most desirable when the target audiences have extensive experience with that instrument, particularly if the MID is well established.
15.6 Drawing conclusions
15.6.1 conclusions sections of a cochrane review.
Authors’ conclusions in a Cochrane Review are divided into implications for practice and implications for research. While Cochrane Reviews about interventions can provide meaningful information and guidance for practice, decisions about the desirable and undesirable consequences of healthcare options require evidence and judgements for criteria that most Cochrane Reviews do not provide (Alonso-Coello et al 2016). In describing the implications for practice and the development of recommendations, however, review authors may consider the certainty of the evidence, the balance of benefits and harms, and assumed values and preferences.
15.6.2 Implications for practice
Drawing conclusions about the practical usefulness of an intervention entails making trade-offs, either implicitly or explicitly, between the estimated benefits, harms and the values and preferences. Making such trade-offs, and thus making specific recommendations for an action in a specific context, goes beyond a Cochrane Review and requires additional evidence and informed judgements that most Cochrane Reviews do not provide (Alonso-Coello et al 2016). Such judgements are typically the domain of clinical practice guideline developers for which Cochrane Reviews will provide crucial information (Graham et al 2011, Schünemann et al 2014, Zhang et al 2018a). Thus, authors of Cochrane Reviews should not make recommendations.
If review authors feel compelled to lay out actions that clinicians and patients could take, they should – after describing the certainty of evidence and the balance of benefits and harms – highlight different actions that might be consistent with particular patterns of values and preferences. Other factors that might influence a decision should also be highlighted, including any known factors that would be expected to modify the effects of the intervention, the baseline risk or status of the patient, costs and who bears those costs, and the availability of resources. Review authors should ensure they consider all patient-important outcomes, including those for which limited data may be available. In the context of public health reviews the focus may be on population-important outcomes as the target may be an entire (non-diseased) population and include outcomes that are not measured in the population receiving an intervention (e.g. a reduction of transmission of infections from those receiving an intervention). This process implies a high level of explicitness in judgements about values or preferences attached to different outcomes and the certainty of the related evidence (Zhang et al 2018b, Zhang et al 2018c); this and a full cost-effectiveness analysis is beyond the scope of most Cochrane Reviews (although they might well be used for such analyses; see Chapter 20 ).
A review on the use of anticoagulation in cancer patients to increase survival (Akl et al 2011a) provides an example for laying out clinical implications for situations where there are important trade-offs between desirable and undesirable effects of the intervention: “The decision for a patient with cancer to start heparin therapy for survival benefit should balance the benefits and downsides and integrate the patient’s values and preferences. Patients with a high preference for a potential survival prolongation, limited aversion to potential bleeding, and who do not consider heparin (both UFH or LMWH) therapy a burden may opt to use heparin, while those with aversion to bleeding may not.”
15.6.3 Implications for research
The second category for authors’ conclusions in a Cochrane Review is implications for research. To help people make well-informed decisions about future healthcare research, the ‘Implications for research’ section should comment on the need for further research, and the nature of the further research that would be most desirable. It is helpful to consider the population, intervention, comparison and outcomes that could be addressed, or addressed more effectively in the future, in the context of the certainty of the evidence in the current review (Brown et al 2006):
- P (Population): diagnosis, disease stage, comorbidity, risk factor, sex, age, ethnic group, specific inclusion or exclusion criteria, clinical setting;
- I (Intervention): type, frequency, dose, duration, prognostic factor;
- C (Comparison): placebo, routine care, alternative treatment/management;
- O (Outcome): which clinical or patient-related outcomes will the researcher need to measure, improve, influence or accomplish? Which methods of measurement should be used?
While Cochrane Review authors will find the PICO domains helpful, the domains of the GRADE certainty framework further support understanding and describing what additional research will improve the certainty in the available evidence. Note that as the certainty of the evidence is likely to vary by outcome, these implications will be specific to certain outcomes in the review. Table 15.6.a shows how review authors may be aided in their interpretation of the body of evidence and drawing conclusions about future research and practice.
Table 15.6.a Implications for research and practice suggested by individual GRADE domains
The review of compression stockings for prevention of deep vein thrombosis (DVT) in airline passengers described in Chapter 14 provides an example where there is some convincing evidence of a benefit of the intervention: “This review shows that the question of the effects on symptomless DVT of wearing versus not wearing compression stockings in the types of people studied in these trials should now be regarded as answered. Further research may be justified to investigate the relative effects of different strengths of stockings or of stockings compared to other preventative strategies. Further randomised trials to address the remaining uncertainty about the effects of wearing versus not wearing compression stockings on outcomes such as death, pulmonary embolism and symptomatic DVT would need to be large.” (Clarke et al 2016).
A review of therapeutic touch for anxiety disorder provides an example of the implications for research when no eligible studies had been found: “This review highlights the need for randomized controlled trials to evaluate the effectiveness of therapeutic touch in reducing anxiety symptoms in people diagnosed with anxiety disorders. Future trials need to be rigorous in design and delivery, with subsequent reporting to include high quality descriptions of all aspects of methodology to enable appraisal and interpretation of results.” (Robinson et al 2007).
15.6.4 Reaching conclusions
A common mistake is to confuse ‘no evidence of an effect’ with ‘evidence of no effect’. When the confidence intervals are too wide (e.g. including no effect), it is wrong to claim that the experimental intervention has ‘no effect’ or is ‘no different’ from the comparator intervention. Review authors may also incorrectly ‘positively’ frame results for some effects but not others. For example, when the effect estimate is positive for a beneficial outcome but confidence intervals are wide, review authors may describe the effect as promising. However, when the effect estimate is negative for an outcome that is considered harmful but the confidence intervals include no effect, review authors report no effect. Another mistake is to frame the conclusion in wishful terms. For example, review authors might write, “there were too few people in the analysis to detect a reduction in mortality” when the included studies showed a reduction or even increase in mortality that was not ‘statistically significant’. One way of avoiding errors such as these is to consider the results blinded; that is, consider how the results would be presented and framed in the conclusions if the direction of the results was reversed. If the confidence interval for the estimate of the difference in the effects of the interventions overlaps with no effect, the analysis is compatible with both a true beneficial effect and a true harmful effect. If one of the possibilities is mentioned in the conclusion, the other possibility should be mentioned as well. Table 15.6.b suggests narrative statements for drawing conclusions based on the effect estimate from the meta-analysis and the certainty of the evidence.
Table 15.6.b Suggested narrative statements for phrasing conclusions
Another common mistake is to reach conclusions that go beyond the evidence. Often this is done implicitly, without referring to the additional information or judgements that are used in reaching conclusions about the implications of a review for practice. Even when additional information and explicit judgements support conclusions about the implications of a review for practice, review authors rarely conduct systematic reviews of the additional information. Furthermore, implications for practice are often dependent on specific circumstances and values that must be taken into consideration. As we have noted, review authors should always be cautious when drawing conclusions about implications for practice and they should not make recommendations.
15.7 Chapter information
Authors: Holger J Schünemann, Gunn E Vist, Julian PT Higgins, Nancy Santesso, Jonathan J Deeks, Paul Glasziou, Elie Akl, Gordon H Guyatt; on behalf of the Cochrane GRADEing Methods Group
Acknowledgements: Andrew Oxman, Jonathan Sterne, Michael Borenstein and Rob Scholten contributed text to earlier versions of this chapter.
Funding: This work was in part supported by funding from the Michael G DeGroote Cochrane Canada Centre and the Ontario Ministry of Health. JJD receives support from the National Institute for Health Research (NIHR) Birmingham Biomedical Research Centre at the University Hospitals Birmingham NHS Foundation Trust and the University of Birmingham. JPTH receives support from the NIHR Biomedical Research Centre at University Hospitals Bristol NHS Foundation Trust and the University of Bristol. The views expressed are those of the author(s) and not necessarily those of the NHS, the NIHR or the Department of Health.
15.8 References
Aguilar MI, Hart R. Oral anticoagulants for preventing stroke in patients with non-valvular atrial fibrillation and no previous history of stroke or transient ischemic attacks. Cochrane Database of Systematic Reviews 2005; 3 : CD001927.
Aguilar MI, Hart R, Pearce LA. Oral anticoagulants versus antiplatelet therapy for preventing stroke in patients with non-valvular atrial fibrillation and no history of stroke or transient ischemic attacks. Cochrane Database of Systematic Reviews 2007; 3 : CD006186.
Akl EA, Gunukula S, Barba M, Yosuico VE, van Doormaal FF, Kuipers S, Middeldorp S, Dickinson HO, Bryant A, Schünemann H. Parenteral anticoagulation in patients with cancer who have no therapeutic or prophylactic indication for anticoagulation. Cochrane Database of Systematic Reviews 2011a; 1 : CD006652.
Akl EA, Oxman AD, Herrin J, Vist GE, Terrenato I, Sperati F, Costiniuk C, Blank D, Schünemann H. Using alternative statistical formats for presenting risks and risk reductions. Cochrane Database of Systematic Reviews 2011b; 3 : CD006776.
Alonso-Coello P, Schünemann HJ, Moberg J, Brignardello-Petersen R, Akl EA, Davoli M, Treweek S, Mustafa RA, Rada G, Rosenbaum S, Morelli A, Guyatt GH, Oxman AD, Group GW. GRADE Evidence to Decision (EtD) frameworks: a systematic and transparent approach to making well informed healthcare choices. 1: Introduction. BMJ 2016; 353 : i2016.
Altman DG. Confidence intervals for the number needed to treat. BMJ 1998; 317 : 1309-1312.
Atkins D, Best D, Briss PA, Eccles M, Falck-Ytter Y, Flottorp S, Guyatt GH, Harbour RT, Haugh MC, Henry D, Hill S, Jaeschke R, Leng G, Liberati A, Magrini N, Mason J, Middleton P, Mrukowicz J, O'Connell D, Oxman AD, Phillips B, Schünemann HJ, Edejer TT, Varonen H, Vist GE, Williams JW, Jr., Zaza S. Grading quality of evidence and strength of recommendations. BMJ 2004; 328 : 1490.
Brown P, Brunnhuber K, Chalkidou K, Chalmers I, Clarke M, Fenton M, Forbes C, Glanville J, Hicks NJ, Moody J, Twaddle S, Timimi H, Young P. How to formulate research recommendations. BMJ 2006; 333 : 804-806.
Cates C. Confidence intervals for the number needed to treat: Pooling numbers needed to treat may not be reliable. BMJ 1999; 318 : 1764-1765.
Clarke MJ, Broderick C, Hopewell S, Juszczak E, Eisinga A. Compression stockings for preventing deep vein thrombosis in airline passengers. Cochrane Database of Systematic Reviews 2016; 9 : CD004002.
Cohen J. Statistical Power Analysis in the Behavioral Sciences . 2nd edition ed. Hillsdale (NJ): Lawrence Erlbaum Associates, Inc.; 1988.
Coleman T, Chamberlain C, Davey MA, Cooper SE, Leonardi-Bee J. Pharmacological interventions for promoting smoking cessation during pregnancy. Cochrane Database of Systematic Reviews 2015; 12 : CD010078.
Dans AM, Dans L, Oxman AD, Robinson V, Acuin J, Tugwell P, Dennis R, Kang D. Assessing equity in clinical practice guidelines. Journal of Clinical Epidemiology 2007; 60 : 540-546.
Friedman LM, Furberg CD, DeMets DL. Fundamentals of Clinical Trials . 2nd edition ed. Littleton (MA): John Wright PSG, Inc.; 1985.
Friedrich JO, Adhikari NK, Beyene J. The ratio of means method as an alternative to mean differences for analyzing continuous outcome variables in meta-analysis: a simulation study. BMC Medical Research Methodology 2008; 8 : 32.
Furukawa T. From effect size into number needed to treat. Lancet 1999; 353 : 1680.
Graham R, Mancher M, Wolman DM, Greenfield S, Steinberg E. Committee on Standards for Developing Trustworthy Clinical Practice Guidelines, Board on Health Care Services: Clinical Practice Guidelines We Can Trust. Washington, DC: National Academies Press; 2011.
Guyatt G, Oxman AD, Akl EA, Kunz R, Vist G, Brozek J, Norris S, Falck-Ytter Y, Glasziou P, DeBeer H, Jaeschke R, Rind D, Meerpohl J, Dahm P, Schünemann HJ. GRADE guidelines: 1. Introduction-GRADE evidence profiles and summary of findings tables. Journal of Clinical Epidemiology 2011a; 64 : 383-394.
Guyatt GH, Juniper EF, Walter SD, Griffith LE, Goldstein RS. Interpreting treatment effects in randomised trials. BMJ 1998; 316 : 690-693.
Guyatt GH, Oxman AD, Vist GE, Kunz R, Falck-Ytter Y, Alonso-Coello P, Schünemann HJ. GRADE: an emerging consensus on rating quality of evidence and strength of recommendations. BMJ 2008; 336 : 924-926.
Guyatt GH, Oxman AD, Kunz R, Woodcock J, Brozek J, Helfand M, Alonso-Coello P, Falck-Ytter Y, Jaeschke R, Vist G, Akl EA, Post PN, Norris S, Meerpohl J, Shukla VK, Nasser M, Schünemann HJ. GRADE guidelines: 8. Rating the quality of evidence--indirectness. Journal of Clinical Epidemiology 2011b; 64 : 1303-1310.
Guyatt GH, Oxman AD, Santesso N, Helfand M, Vist G, Kunz R, Brozek J, Norris S, Meerpohl J, Djulbegovic B, Alonso-Coello P, Post PN, Busse JW, Glasziou P, Christensen R, Schünemann HJ. GRADE guidelines: 12. Preparing summary of findings tables-binary outcomes. Journal of Clinical Epidemiology 2013a; 66 : 158-172.
Guyatt GH, Thorlund K, Oxman AD, Walter SD, Patrick D, Furukawa TA, Johnston BC, Karanicolas P, Akl EA, Vist G, Kunz R, Brozek J, Kupper LL, Martin SL, Meerpohl JJ, Alonso-Coello P, Christensen R, Schünemann HJ. GRADE guidelines: 13. Preparing summary of findings tables and evidence profiles-continuous outcomes. Journal of Clinical Epidemiology 2013b; 66 : 173-183.
Hawe P, Shiell A, Riley T, Gold L. Methods for exploring implementation variation and local context within a cluster randomised community intervention trial. Journal of Epidemiology and Community Health 2004; 58 : 788-793.
Hoffrage U, Lindsey S, Hertwig R, Gigerenzer G. Medicine. Communicating statistical information. Science 2000; 290 : 2261-2262.
Jaeschke R, Singer J, Guyatt GH. Measurement of health status. Ascertaining the minimal clinically important difference. Controlled Clinical Trials 1989; 10 : 407-415.
Johnston B, Thorlund K, Schünemann H, Xie F, Murad M, Montori V, Guyatt G. Improving the interpretation of health-related quality of life evidence in meta-analysis: The application of minimal important difference units. . Health Outcomes and Qualithy of Life 2010; 11 : 116.
Karanicolas PJ, Smith SE, Kanbur B, Davies E, Guyatt GH. The impact of prophylactic dexamethasone on nausea and vomiting after laparoscopic cholecystectomy: a systematic review and meta-analysis. Annals of Surgery 2008; 248 : 751-762.
Lumley J, Oliver SS, Chamberlain C, Oakley L. Interventions for promoting smoking cessation during pregnancy. Cochrane Database of Systematic Reviews 2004; 4 : CD001055.
McQuay HJ, Moore RA. Using numerical results from systematic reviews in clinical practice. Annals of Internal Medicine 1997; 126 : 712-720.
Resnicow K, Cross D, Wynder E. The Know Your Body program: a review of evaluation studies. Bulletin of the New York Academy of Medicine 1993; 70 : 188-207.
Robinson J, Biley FC, Dolk H. Therapeutic touch for anxiety disorders. Cochrane Database of Systematic Reviews 2007; 3 : CD006240.
Rothwell PM. External validity of randomised controlled trials: "to whom do the results of this trial apply?". Lancet 2005; 365 : 82-93.
Santesso N, Carrasco-Labra A, Langendam M, Brignardello-Petersen R, Mustafa RA, Heus P, Lasserson T, Opiyo N, Kunnamo I, Sinclair D, Garner P, Treweek S, Tovey D, Akl EA, Tugwell P, Brozek JL, Guyatt G, Schünemann HJ. Improving GRADE evidence tables part 3: detailed guidance for explanatory footnotes supports creating and understanding GRADE certainty in the evidence judgments. Journal of Clinical Epidemiology 2016; 74 : 28-39.
Schünemann HJ, Puhan M, Goldstein R, Jaeschke R, Guyatt GH. Measurement properties and interpretability of the Chronic respiratory disease questionnaire (CRQ). COPD: Journal of Chronic Obstructive Pulmonary Disease 2005; 2 : 81-89.
Schünemann HJ, Guyatt GH. Commentary--goodbye M(C)ID! Hello MID, where do you come from? Health Services Research 2005; 40 : 593-597.
Schünemann HJ, Fretheim A, Oxman AD. Improving the use of research evidence in guideline development: 13. Applicability, transferability and adaptation. Health Research Policy and Systems 2006; 4 : 25.
Schünemann HJ. Methodological idiosyncracies, frameworks and challenges of non-pharmaceutical and non-technical treatment interventions. Zeitschrift für Evidenz, Fortbildung und Qualität im Gesundheitswesen 2013; 107 : 214-220.
Schünemann HJ, Tugwell P, Reeves BC, Akl EA, Santesso N, Spencer FA, Shea B, Wells G, Helfand M. Non-randomized studies as a source of complementary, sequential or replacement evidence for randomized controlled trials in systematic reviews on the effects of interventions. Research Synthesis Methods 2013; 4 : 49-62.
Schünemann HJ, Wiercioch W, Etxeandia I, Falavigna M, Santesso N, Mustafa R, Ventresca M, Brignardello-Petersen R, Laisaar KT, Kowalski S, Baldeh T, Zhang Y, Raid U, Neumann I, Norris SL, Thornton J, Harbour R, Treweek S, Guyatt G, Alonso-Coello P, Reinap M, Brozek J, Oxman A, Akl EA. Guidelines 2.0: systematic development of a comprehensive checklist for a successful guideline enterprise. CMAJ: Canadian Medical Association Journal 2014; 186 : E123-142.
Schünemann HJ. Interpreting GRADE's levels of certainty or quality of the evidence: GRADE for statisticians, considering review information size or less emphasis on imprecision? Journal of Clinical Epidemiology 2016; 75 : 6-15.
Smeeth L, Haines A, Ebrahim S. Numbers needed to treat derived from meta-analyses--sometimes informative, usually misleading. BMJ 1999; 318 : 1548-1551.
Sun X, Briel M, Busse JW, You JJ, Akl EA, Mejza F, Bala MM, Bassler D, Mertz D, Diaz-Granados N, Vandvik PO, Malaga G, Srinathan SK, Dahm P, Johnston BC, Alonso-Coello P, Hassouneh B, Walter SD, Heels-Ansdell D, Bhatnagar N, Altman DG, Guyatt GH. Credibility of claims of subgroup effects in randomised controlled trials: systematic review. BMJ 2012; 344 : e1553.
Zhang Y, Akl EA, Schünemann HJ. Using systematic reviews in guideline development: the GRADE approach. Research Synthesis Methods 2018a: doi: 10.1002/jrsm.1313.
Zhang Y, Alonso-Coello P, Guyatt GH, Yepes-Nunez JJ, Akl EA, Hazlewood G, Pardo-Hernandez H, Etxeandia-Ikobaltzeta I, Qaseem A, Williams JW, Jr., Tugwell P, Flottorp S, Chang Y, Zhang Y, Mustafa RA, Rojas MX, Schünemann HJ. GRADE Guidelines: 19. Assessing the certainty of evidence in the importance of outcomes or values and preferences-Risk of bias and indirectness. Journal of Clinical Epidemiology 2018b: doi: 10.1016/j.jclinepi.2018.1001.1013.
Zhang Y, Alonso Coello P, Guyatt G, Yepes-Nunez JJ, Akl EA, Hazlewood G, Pardo-Hernandez H, Etxeandia-Ikobaltzeta I, Qaseem A, Williams JW, Jr., Tugwell P, Flottorp S, Chang Y, Zhang Y, Mustafa RA, Rojas MX, Xie F, Schünemann HJ. GRADE Guidelines: 20. Assessing the certainty of evidence in the importance of outcomes or values and preferences - Inconsistency, Imprecision, and other Domains. Journal of Clinical Epidemiology 2018c: doi: 10.1016/j.jclinepi.2018.1005.1011.
For permission to re-use material from the Handbook (either academic or commercial), please see here for full details.

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
2.1F: Analyzing Data and Drawing Conclusions
- Last updated
- Save as PDF
- Page ID 7916
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
Data analysis in sociological research aims to identify meaningful sociological patterns.
Learning Objectives
- Compare and contrast the analysis of quantitative vs. qualitative data
- Analysis of data is a process of inspecting, cleaning, transforming, and modeling data with the goal of highlighting useful information, suggesting conclusions, and supporting decision making. Data analysis is a process, within which several phases can be distinguished.
- One way in which analysis can vary is by the nature of the data. Quantitative data is often analyzed using regressions. Regression analyses measure relationships between dependent and independent variables, taking the existence of unknown parameters into account.
- Qualitative data can be coded–that is, key concepts and variables are assigned a shorthand, and the data gathered are broken down into those concepts or variables. Coding allows sociologists to perform a more rigorous scientific analysis of the data.
Sociological data analysis is designed to produce patterns. It is important to remember, however, that correlation does not imply causation; in other words, just because variables change at a proportional rate, it does not follow that one variable influences the other.
- Without a valid design, valid scientific conclusions cannot be drawn. Internal validity concerns the degree to which conclusions about causality can be made. External validity concerns the extent to which the results of a study are generalizable.
- correlation : A reciprocal, parallel or complementary relationship between two or more comparable objects.
- causation : The act of causing; also the act or agency by which an effect is produced.
- Regression analysis : In statistics, regression analysis includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables. More specifically, regression analysis helps one understand how the typical value of the dependent variable changes when any one of the independent variables is varied, while the other independent variables are held fixed.
The Process of Data Analysis
Analysis of data is a process of inspecting, cleaning, transforming, and modeling data with the goal of highlighting useful information, suggesting conclusions, and supporting decision making. In statistical applications, some people divide data analysis into descriptive statistics, exploratory data analysis (EDA), and confirmatory data analysis (CDA). EDA focuses on discovering new features in the data and CDA focuses on confirming or falsifying existing hypotheses. Predictive analytics focuses on the application of statistical or structural models for predictive forecasting or classification. Text analytics applies statistical, linguistic, and structural techniques to extract and classify information from textual sources, a species of unstructured data.
Data analysis is a process, within which several phases can be distinguished. The initial data analysis phase is guided by examining, among other things, the quality of the data (for example, the presence of missing or extreme observations), the quality of measurements, and if the implementation of the study was in line with the research design. In the main analysis phase, either an exploratory or confirmatory approach can be adopted. Usually the approach is decided before data is collected. In an exploratory analysis, no clear hypothesis is stated before analyzing the data, and the data is searched for models that describe the data well. In a confirmatory analysis, clear hypotheses about the data are tested.
Regression Analysis
The type of data analysis employed can vary. One way in which analysis often varies is by the quantitative or qualitative nature of the data.
Quantitative data can be analyzed in a variety of ways, regression analysis being among the most popular. Regression analyses measure relationships between dependent and independent variables, taking the existence of unknown parameters into account. More specifically, regression analysis helps one understand how the typical value of the dependent variable changes when any one of the independent variables is varied, while the other independent variables are held fixed.
A large body of techniques for carrying out regression analysis has been developed. In practice, the performance of regression analysis methods depends on the form of the data generating process and how it relates to the regression approach being used. Since the true form of the data-generating process is generally not known, regression analysis often depends to some extent on making assumptions about this process. These assumptions are sometimes testable if a large amount of data is available. Regression models for prediction are often useful even when the assumptions are moderately violated, although they may not perform optimally. However, in many applications, especially with small effects or questions of causality based on observational data, regression methods give misleading results.
Qualitative data can involve coding–that is, key concepts and variables are assigned a shorthand, and the data gathered is broken down into those concepts or variables. Coding allows sociologists to perform a more rigorous scientific analysis of the data. Coding is the process of categorizing qualitative data so that the data becomes quantifiable and thus measurable. Of course, before researchers can code raw data such as taped interviews, they need to have a clear research question. How data is coded depends entirely on what the researcher hopes to discover in the data; the same qualitative data can be coded in many different ways, calling attention to different aspects of the data.

Sociological Data Analysis
Correlation, Causation, and Spurious Relationships : This mock newscast gives three competing interpretations of the same survey findings and demonstrates the dangers of assuming that correlation implies causation.
Conclusions
In terms of the kinds of conclusions that can be drawn, a study and its results can be assessed in multiple ways. Without a valid design, valid scientific conclusions cannot be drawn. Internal validity is an inductive estimate of the degree to which conclusions about causal relationships can be made (e.g., cause and effect), based on the measures used, the research setting, and the whole research design. External validity concerns the extent to which the (internally valid) results of a study can be held to be true for other cases, such as to different people, places, or times. In other words, it is about whether findings can be validly generalized. Learning about and applying statistics (as well as knowing their limitations) can help you better understand sociological research and studies. Knowledge of statistics helps you makes sense of the numbers in terms of relationships, and it allows you to ask relevant questions about sociological phenomena.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Drawing Conclusions and Reporting the Results
Rajiv S. Jhangiani; I-Chant A. Chiang; Carrie Cuttler; and Dana C. Leighton
Learning Objectives
- Identify the conclusions researchers can make based on the outcome of their studies.
- Describe why scientists avoid the term “scientific proof.”
- Explain the different ways that scientists share their findings.
Drawing Conclusions
Since statistics are probabilistic in nature and findings can reflect type I or type II errors, we cannot use the results of a single study to conclude with certainty that a theory is true. Rather theories are supported, refuted, or modified based on the results of research.
If the results are statistically significant and consistent with the hypothesis and the theory that was used to generate the hypothesis, then researchers can conclude that the theory is supported. Not only did the theory make an accurate prediction, but there is now a new phenomenon that the theory accounts for. If a hypothesis is disconfirmed in a systematic empirical study, then the theory has been weakened. It made an inaccurate prediction, and there is now a new phenomenon that it does not account for.
Although this seems straightforward, there are some complications. First, confirming a hypothesis can strengthen a theory but it can never prove a theory. In fact, scientists tend to avoid the word “prove” when talking and writing about theories. One reason for this avoidance is that the result may reflect a type I error. Another reason for this avoidance is that there may be other plausible theories that imply the same hypothesis, which means that confirming the hypothesis strengthens all those theories equally. A third reason is that it is always possible that another test of the hypothesis or a test of a new hypothesis derived from the theory will be disconfirmed. This difficulty is a version of the famous philosophical “problem of induction.” One cannot definitively prove a general principle (e.g., “All swans are white.”) just by observing confirming cases (e.g., white swans)—no matter how many. It is always possible that a disconfirming case (e.g., a black swan) will eventually come along. For these reasons, scientists tend to think of theories—even highly successful ones—as subject to revision based on new and unexpected observations.
A second complication has to do with what it means when a hypothesis is disconfirmed. According to the strictest version of the hypothetico-deductive method, disconfirming a hypothesis disproves the theory it was derived from. In formal logic, the premises “if A then B ” and “not B ” necessarily lead to the conclusion “not A .” If A is the theory and B is the hypothesis (“if A then B ”), then disconfirming the hypothesis (“not B ”) must mean that the theory is incorrect (“not A ”). In practice, however, scientists do not give up on their theories so easily. One reason is that one disconfirmed hypothesis could be a missed opportunity (the result of a type II error) or it could be the result of a faulty research design. Perhaps the researcher did not successfully manipulate the independent variable or measure the dependent variable.
A disconfirmed hypothesis could also mean that some unstated but relatively minor assumption of the theory was not met. For example, if Zajonc had failed to find social facilitation in cockroaches, he could have concluded that drive theory is still correct but it applies only to animals with sufficiently complex nervous systems. That is, the evidence from a study can be used to modify a theory. This practice does not mean that researchers are free to ignore disconfirmations of their theories. If they cannot improve their research designs or modify their theories to account for repeated disconfirmations, then they eventually must abandon their theories and replace them with ones that are more successful.
The bottom line here is that because statistics are probabilistic in nature and because all research studies have flaws there is no such thing as scientific proof, there is only scientific evidence.
Reporting the Results
The final step in the research process involves reporting the results. As described in the section on Reviewing the Research Literature in this chapter, results are typically reported in peer-reviewed journal articles and at conferences.
The most prestigious way to report one’s findings is by writing a manuscript and having it published in a peer-reviewed scientific journal. Manuscripts published in psychology journals typically must adhere to the writing style of the American Psychological Association (APA style). You will likely be learning the major elements of this writing style in this course.
Another way to report findings is by writing a book chapter that is published in an edited book. Preferably the editor of the book puts the chapter through peer review but this is not always the case and some scientists are invited by editors to write book chapters.
A fun way to disseminate findings is to give a presentation at a conference. This can either be done as an oral presentation or a poster presentation. Oral presentations involve getting up in front of an audience of fellow scientists and giving a talk that might last anywhere from 10 minutes to 1 hour (depending on the conference) and then fielding questions from the audience. Alternatively, poster presentations involve summarizing the study on a large poster that provides a brief overview of the purpose, methods, results, and discussion. The presenter stands by their poster for an hour or two and discusses it with people who pass by. Presenting one’s work at a conference is a great way to get feedback from one’s peers before attempting to undergo the more rigorous peer-review process involved in publishing a journal article.
Drawing Conclusions and Reporting the Results Copyright © by Rajiv S. Jhangiani; I-Chant A. Chiang; Carrie Cuttler; and Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
- Foundations
- Write Paper
Search form
- Experiments
- Anthropology
- Self-Esteem
- Social Anxiety
Drawing Conclusions
For any research project and any scientific discipline, drawing conclusions is the final, and most important, part of the process.
This article is a part of the guide:
- Null Hypothesis
- Research Hypothesis
- Defining a Research Problem
- Selecting Method
Browse Full Outline
- 1 Scientific Method
- 2.1.1 Null Hypothesis
- 2.1.2 Research Hypothesis
- 2.2 Prediction
- 2.3 Conceptual Variable
- 3.1 Operationalization
- 3.2 Selecting Method
- 3.3 Measurements
- 3.4 Scientific Observation
- 4.1 Empirical Evidence
- 5.1 Generalization
- 5.2 Errors in Conclusion
Whichever reasoning processes and research methods were used, the final conclusion is critical, determining success or failure. If an otherwise excellent experiment is summarized by a weak conclusion, the results will not be taken seriously.
Success or failure is not a measure of whether a hypothesis is accepted or refuted, because both results still advance scientific knowledge.
Failure lies in poor experimental design, or flaws in the reasoning processes, which invalidate the results. As long as the research process is robust and well designed, then the findings are sound, and the process of drawing conclusions begins.
The key is to establish what the results mean. How are they applied to the world?

What Has Been Learned?
Generally, a researcher will summarize what they believe has been learned from the research, and will try to assess the strength of the hypothesis.
Even if the null hypothesis is accepted, a strong conclusion will analyze why the results were not as predicted.
Theoretical physicist Wolfgang Pauli was known to have criticized another physicist’s work by saying, “it’s not only not right; it is not even wrong.”
While this is certainly a humorous put-down, it also points to the value of the null hypothesis in science, i.e. the value of being “wrong.” Both accepting or rejecting the null hypothesis provides useful information – it is only when the research provides no illumination on the phenomenon at all that it is truly a failure.
In observational research , with no hypothesis, the researcher will analyze the findings, and establish if any valuable new information has been uncovered. The conclusions from this type of research may well inspire the development of a new hypothesis for further experiments.

Generating Leads for Future Research
However, very few experiments give clear-cut results, and most research uncovers more questions than answers.
The researcher can use these to suggest interesting directions for further study. If, for example, the null hypothesis was accepted, there may still have been trends apparent within the results. These could form the basis of further study, or experimental refinement and redesign.
Question: Let’s say a researcher is interested in whether people who are ambidextrous (can write with either hand) are more likely to have ADHD. She may have three groups – left-handed, right-handed and ambidextrous, and ask each of them to complete an ADHD screening.
She hypothesizes that the ambidextrous people will in fact be more prone to symptoms of ADHD. While she doesn’t find a significant difference when she compares the mean scores of the groups, she does notice another trend: the ambidextrous people seem to score lower overall on tests of verbal acuity. She accepts the null hypothesis, but wishes to continue with her research. Can you think of a direction her research could take, given what she has already learnt?
Answer: She may decide to look more closely at that trend. She may design another experiment to isolate the variable of verbal acuity, by controlling for everything else. This may eventually help her arrive at a new hypothesis: ambidextrous people have lower verbal acuity.
Evaluating Flaws in the Research Process
The researcher will then evaluate any apparent problems with the experiment. This involves critically evaluating any weaknesses and errors in the design, which may have influenced the results .
Even strict, ' true experimental ,' designs have to make compromises, and the researcher must be thorough in pointing these out, justifying the methodology and reasoning.
For example, when drawing conclusions, the researcher may think that another causal effect influenced the results, and that this variable was not eliminated during the experimental process . A refined version of the experiment may help to achieve better results, if the new effect is included in the design process.
In the global warming example, the researcher might establish that carbon dioxide emission alone cannot be responsible for global warming. They may decide that another effect is contributing, so propose that methane may also be a factor in global warming. A new study would incorporate methane into the model.
What are the Benefits of the Research?
The next stage is to evaluate the advantages and benefits of the research.
In medicine and psychology, for example, the results may throw out a new way of treating a medical problem, so the advantages are obvious.
In some fields, certain kinds of research may not typically be seen as beneficial, regardless of the results obtained. Ideally, researchers will consider the implications of their research beforehand, as well as any ethical considerations. In fields such as psychology, social sciences or sociology, it’s important to think about who the research serves and what will ultimately be done with the results.
For example, the study regarding ambidexterity and verbal acuity may be interesting, but what would be the effect of accepting that hypothesis? Would it really benefit anyone to know that the ambidextrous are less likely to have a high verbal acuity?
However, all well-constructed research is useful, even if it only strengthens or supports a more tentative conclusion made by prior research.
Suggestions Based Upon the Conclusions
The final stage is the researcher's recommendations based on the results, depending on the field of study. This area of the research process is informed by the researcher's judgement, and will integrate previous studies.
For example, a researcher interested in schizophrenia may recommend a more effective treatment based on what has been learnt from a study. A physicist might propose that our picture of the structure of the atom should be changed. A researcher could make suggestions for refinement of the experimental design, or highlight interesting areas for further study. This final piece of the paper is the most critical, and pulls together all of the findings into a coherent agrument.
The area in a research paper that causes intense and heated debate amongst scientists is often when drawing conclusions .
Sharing and presenting findings to the scientific community is a vital part of the scientific process. It is here that the researcher justifies the research, synthesizes the results and offers them up for scrutiny by their peers.
As the store of scientific knowledge increases and deepens, it is incumbent on researchers to work together. Long ago, a single scientist could discover and publish work that alone could have a profound impact on the course of history. Today, however, such impact can only be achieved in concert with fellow scientists.
Summary - The Strength of the Results
The key to drawing a valid conclusion is to ensure that the deductive and inductive processes are correctly used, and that all steps of the scientific method were followed.
Even the best-planned research can go awry, however. Part of interpreting results also includes the researchers putting aside their ego to appraise what, if anything went wrong. Has anything occurred to warrant a more cautious interpretation of results?
If your research had a robust design, questioning and scrutiny will be devoted to the experiment conclusion, rather than the methods.
Question: Researchers are interested in identifying new microbial species that are capable of breaking down cellulose for possible application in biofuel production. They collect soil samples from a particular forest and create laboratory cultures of every microbial species they discover there. They then “feed” each species a cellulose compound and observe that in all the species tested, there was no decrease in cellulose after 24 hours.
Read the following conclusions below and decide which of them is the most sound:
They conclude that there are no microbes that can break down cellulose.
They conclude that the sampled microbes are not capable of breaking down cellulose in a lab environment within 24 hours.
They conclude that all the species are related somehow.
They conclude that these microbes are not useful in the biofuel industry.
They conclude that microbes from forests don’t break down cellulose.
Answer: The most appropriate conclusion is number 2. As you can see, sound conclusions are often a question of not extrapolating too widely, or making assumptions that are not supported by the data obtained. Even conclusion number 2 will likely be presented as tentative, and only provides evidence given the limits of the methods used.
- Psychology 101
- Flags and Countries
- Capitals and Countries
Martyn Shuttleworth , Lyndsay T Wilson (Jul 22, 2008). Drawing Conclusions. Retrieved May 30, 2024 from Explorable.com: https://explorable.com/drawing-conclusions
You Are Allowed To Copy The Text
The text in this article is licensed under the Creative Commons-License Attribution 4.0 International (CC BY 4.0) .
This means you're free to copy, share and adapt any parts (or all) of the text in the article, as long as you give appropriate credit and provide a link/reference to this page.
That is it. You don't need our permission to copy the article; just include a link/reference back to this page. You can use it freely (with some kind of link), and we're also okay with people reprinting in publications like books, blogs, newsletters, course-material, papers, wikipedia and presentations (with clear attribution).
Want to stay up to date? Follow us!
Get all these articles in 1 guide.
Want the full version to study at home, take to school or just scribble on?
Whether you are an academic novice, or you simply want to brush up your skills, this book will take your academic writing skills to the next level.

Download electronic versions: - Epub for mobiles and tablets - For Kindle here - PDF version here
Save this course for later
Don't have time for it all now? No problem, save it as a course and come back to it later.
Footer bottom
- Privacy Policy

- Subscribe to our RSS Feed
- Like us on Facebook
- Follow us on Twitter
- Walden University
- Faculty Portal
Writing a Paper: Conclusions
Writing a conclusion.
A conclusion is an important part of the paper; it provides closure for the reader while reminding the reader of the contents and importance of the paper. It accomplishes this by stepping back from the specifics in order to view the bigger picture of the document. In other words, it is reminding the reader of the main argument. For most course papers, it is usually one paragraph that simply and succinctly restates the main ideas and arguments, pulling everything together to help clarify the thesis of the paper. A conclusion does not introduce new ideas; instead, it should clarify the intent and importance of the paper. It can also suggest possible future research on the topic.
An Easy Checklist for Writing a Conclusion
It is important to remind the reader of the thesis of the paper so he is reminded of the argument and solutions you proposed.
Think of the main points as puzzle pieces, and the conclusion is where they all fit together to create a bigger picture. The reader should walk away with the bigger picture in mind.
Make sure that the paper places its findings in the context of real social change.
Make sure the reader has a distinct sense that the paper has come to an end. It is important to not leave the reader hanging. (You don’t want her to have flip-the-page syndrome, where the reader turns the page, expecting the paper to continue. The paper should naturally come to an end.)
No new ideas should be introduced in the conclusion. It is simply a review of the material that is already present in the paper. The only new idea would be the suggesting of a direction for future research.
Conclusion Example
As addressed in my analysis of recent research, the advantages of a later starting time for high school students significantly outweigh the disadvantages. A later starting time would allow teens more time to sleep--something that is important for their physical and mental health--and ultimately improve their academic performance and behavior. The added transportation costs that result from this change can be absorbed through energy savings. The beneficial effects on the students’ academic performance and behavior validate this decision, but its effect on student motivation is still unknown. I would encourage an in-depth look at the reactions of students to such a change. This sort of study would help determine the actual effects of a later start time on the time management and sleep habits of students.
Related Webinar
Didn't find what you need? Email us at [email protected] .
- Previous Page: Thesis Statements
- Next Page: Writer's Block
- Office of Student Disability Services
Walden Resources
Departments.
- Academic Residencies
- Academic Skills
- Career Planning and Development
- Customer Care Team
- Field Experience
- Military Services
- Student Success Advising
- Writing Skills
Centers and Offices
- Center for Social Change
- Office of Academic Support and Instructional Services
- Office of Degree Acceleration
- Office of Research and Doctoral Services
- Office of Student Affairs
Student Resources
- Doctoral Writing Assessment
- Form & Style Review
- Quick Answers
- ScholarWorks
- SKIL Courses and Workshops
- Walden Bookstore
- Walden Catalog & Student Handbook
- Student Safety/Title IX
- Legal & Consumer Information
- Website Terms and Conditions
- Cookie Policy
- Accessibility
- Accreditation
- State Authorization
- Net Price Calculator
- Contact Walden
Walden University is a member of Adtalem Global Education, Inc. www.adtalem.com Walden University is certified to operate by SCHEV © 2024 Walden University LLC. All rights reserved.
2.7 Drawing Conclusions and Reporting the Results
Learning objectives.
- Identify the conclusions researchers can make based on the outcome of their studies.
- Describe why scientists avoid the term “scientific proof.”
- Explain the different ways that scientists share their findings.
Drawing Conclusions
Since statistics are probabilistic in nature and findings can reflect type I or type II errors, we cannot use the results of a single study to conclude with certainty that a theory is true. Rather theories are supported, refuted, or modified based on the results of research.
If the results are statistically significant and consistent with the hypothesis and the theory that was used to generate the hypothesis, then researchers can conclude that the theory is supported. Not only did the theory make an accurate prediction, but there is now a new phenomenon that the theory accounts for. If a hypothesis is disconfirmed in a systematic empirical study, then the theory has been weakened. It made an inaccurate prediction, and there is now a new phenomenon that it does not account for.
Although this seems straightforward, there are some complications. First, confirming a hypothesis can strengthen a theory but it can never prove a theory. In fact, scientists tend to avoid the word “prove” when talking and writing about theories. One reason for this avoidance is that the result may reflect a type I error. Another reason for this avoidance is that there may be other plausible theories that imply the same hypothesis, which means that confirming the hypothesis strengthens all those theories equally. A third reason is that it is always possible that another test of the hypothesis or a test of a new hypothesis derived from the theory will be disconfirmed. This difficulty is a version of the famous philosophical “problem of induction.” One cannot definitively prove a general principle (e.g., “All swans are white.”) just by observing confirming cases (e.g., white swans)—no matter how many. It is always possible that a disconfirming case (e.g., a black swan) will eventually come along. For these reasons, scientists tend to think of theories—even highly successful ones—as subject to revision based on new and unexpected observations.
A second complication has to do with what it means when a hypothesis is disconfirmed. According to the strictest version of the hypothetico-deductive method, disconfirming a hypothesis disproves the theory it was derived from. In formal logic, the premises “if A then B ” and “not B ” necessarily lead to the conclusion “not A .” If A is the theory and B is the hypothesis (“if A then B ”), then disconfirming the hypothesis (“not B ”) must mean that the theory is incorrect (“not A ”). In practice, however, scientists do not give up on their theories so easily. One reason is that one disconfirmed hypothesis could be a missed opportunity (the result of a type II error) or it could be the result of a faulty research design. Perhaps the researcher did not successfully manipulate the independent variable or measure the dependent variable.
A disconfirmed hypothesis could also mean that some unstated but relatively minor assumption of the theory was not met. For example, if Zajonc had failed to find social facilitation in cockroaches, he could have concluded that drive theory is still correct but it applies only to animals with sufficiently complex nervous systems. That is, the evidence from a study can be used to modify a theory. This practice does not mean that researchers are free to ignore disconfirmations of their theories. If they cannot improve their research designs or modify their theories to account for repeated disconfirmations, then they eventually must abandon their theories and replace them with ones that are more successful.
The bottom line here is that because statistics are probabilistic in nature and because all research studies have flaws there is no such thing as scientific proof, there is only scientific evidence.
Reporting the Results
The final step in the research process involves reporting the results. As described in the section on Reviewing the Research Literature in this chapter, results are typically reported in peer-reviewed journal articles and at conferences.
The most prestigious way to report one’s findings is by writing a manuscript and having it published in a peer-reviewed scientific journal. Manuscripts published in psychology journals typically must adhere to the writing style of the American Psychological Association (APA style). You will likely be learning the major elements of this writing style in this course.
Another way to report findings is by writing a book chapter that is published in an edited book. Preferably the editor of the book puts the chapter through peer review but this is not always the case and some scientists are invited by editors to write book chapters.
A fun way to disseminate findings is to give a presentation at a conference. This can either be done as an oral presentation or a poster presentation. Oral presentations involve getting up in front of an audience of fellow scientists and giving a talk that might last anywhere from 10 minutes to 1 hour (depending on the conference) and then fielding questions from the audience. Alternatively, poster presentations involve summarizing the study on a large poster that provides a brief overview of the purpose, methods, results, and discussion. The presenter stands by his or her poster for an hour or two and discusses it with people who pass by. Presenting one’s work at a conference is a great way to get feedback from one’s peers before attempting to undergo the more rigorous peer-review process involved in publishing a journal article.

Share This Book
- Increase Font Size

Psychological Research
Drawing Conclusions from Statistics
Learning objectives.
- Describe the role of random sampling and random assignment in drawing cause-and-effect conclusions
Generalizability

One limitation to the study mentioned previously about the babies choosing the “helper” toy is that the conclusion only applies to the 16 infants in the study. We don’t know much about how those 16 infants were selected. Suppose we want to select a subset of individuals (a sample ) from a much larger group of individuals (the population ) in such a way that conclusions from the sample can be generalized to the larger population. This is the question faced by pollsters every day.
Example 1 : The General Social Survey (GSS) is a survey on societal trends conducted every other year in the United States. Based on a sample of about 2,000 adult Americans, researchers make claims about what percentage of the U.S. population consider themselves to be “liberal,” what percentage consider themselves “happy,” what percentage feel “rushed” in their daily lives, and many other issues. The key to making these claims about the larger population of all American adults lies in how the sample is selected. The goal is to select a sample that is representative of the population, and a common way to achieve this goal is to select a random sample that gives every member of the population an equal chance of being selected for the sample. In its simplest form, random sampling involves numbering every member of the population and then using a computer to randomly select the subset to be surveyed. Most polls don’t operate exactly like this, but they do use probability-based sampling methods to select individuals from nationally representative panels.
In 2004, the GSS reported that 817 of 977 respondents (or 83.6%) indicated that they always or sometimes feel rushed. This is a clear majority, but we again need to consider variation due to random sampling . Fortunately, we can use the same probability model we did in the previous example to investigate the probable size of this error. (Note, we can use the coin-tossing model when the actual population size is much, much larger than the sample size, as then we can still consider the probability to be the same for every individual in the sample.) This probability model predicts that the sample result will be within 3 percentage points of the population value (roughly 1 over the square root of the sample size, the margin of error ). A statistician would conclude, with 95% confidence, that between 80.6% and 86.6% of all adult Americans in 2004 would have responded that they sometimes or always feel rushed.
The key to the margin of error is that when we use a probability sampling method, we can make claims about how often (in the long run, with repeated random sampling) the sample result would fall within a certain distance from the unknown population value by chance (meaning by random sampling variation) alone. Conversely, non-random samples are often suspect to bias, meaning the sampling method systematically over-represents some segments of the population and under-represents others. We also still need to consider other sources of bias, such as individuals not responding honestly. These sources of error are not measured by the margin of error.
Cause and Effect
In many research studies, the primary question of interest concerns differences between groups. Then the question becomes how were the groups formed (e.g., selecting people who already drink coffee vs. those who don’t). In some studies, the researchers actively form the groups themselves. But then we have a similar question—could any differences we observe in the groups be an artifact of that group-formation process? Or maybe the difference we observe in the groups is so large that we can discount a “fluke” in the group-formation process as a reasonable explanation for what we find?
Example 2 : A psychology study investigated whether people tend to display more creativity when they are thinking about intrinsic (internal) or extrinsic (external) motivations (Ramsey & Schafer, 2002, based on a study by Amabile, 1985). The subjects were 47 people with extensive experience with creative writing. Subjects began by answering survey questions about either intrinsic motivations for writing (such as the pleasure of self-expression) or extrinsic motivations (such as public recognition). Then all subjects were instructed to write a haiku, and those poems were evaluated for creativity by a panel of judges. The researchers conjectured beforehand that subjects who were thinking about intrinsic motivations would display more creativity than subjects who were thinking about extrinsic motivations. The creativity scores from the 47 subjects in this study are displayed in Figure 2, where higher scores indicate more creativity.

In this example, the key question is whether the type of motivation affects creativity scores. In particular, do subjects who were asked about intrinsic motivations tend to have higher creativity scores than subjects who were asked about extrinsic motivations?
Figure 2 reveals that both motivation groups saw considerable variability in creativity scores, and these scores have considerable overlap between the groups. In other words, it’s certainly not always the case that those with extrinsic motivations have higher creativity than those with intrinsic motivations, but there may still be a statistical tendency in this direction. (Psychologist Keith Stanovich (2013) refers to people’s difficulties with thinking about such probabilistic tendencies as “the Achilles heel of human cognition.”)
The mean creativity score is 19.88 for the intrinsic group, compared to 15.74 for the extrinsic group, which supports the researchers’ conjecture. Yet comparing only the means of the two groups fails to consider the variability of creativity scores in the groups. We can measure variability with statistics using, for instance, the standard deviation: 5.25 for the extrinsic group and 4.40 for the intrinsic group. The standard deviations tell us that most of the creativity scores are within about 5 points of the mean score in each group. We see that the mean score for the intrinsic group lies within one standard deviation of the mean score for extrinsic group. So, although there is a tendency for the creativity scores to be higher in the intrinsic group, on average, the difference is not extremely large.
We again want to consider possible explanations for this difference. The study only involved individuals with extensive creative writing experience. Although this limits the population to which we can generalize, it does not explain why the mean creativity score was a bit larger for the intrinsic group than for the extrinsic group. Maybe women tend to receive higher creativity scores? Here is where we need to focus on how the individuals were assigned to the motivation groups. If only women were in the intrinsic motivation group and only men in the extrinsic group, then this would present a problem because we wouldn’t know if the intrinsic group did better because of the different type of motivation or because they were women. However, the researchers guarded against such a problem by randomly assigning the individuals to the motivation groups. Like flipping a coin, each individual was just as likely to be assigned to either type of motivation. Why is this helpful? Because this random assignment tends to balance out all the variables related to creativity we can think of, and even those we don’t think of in advance, between the two groups. So we should have a similar male/female split between the two groups; we should have a similar age distribution between the two groups; we should have a similar distribution of educational background between the two groups; and so on. Random assignment should produce groups that are as similar as possible except for the type of motivation, which presumably eliminates all those other variables as possible explanations for the observed tendency for higher scores in the intrinsic group.
But does this always work? No, so by “luck of the draw” the groups may be a little different prior to answering the motivation survey. So then the question is, is it possible that an unlucky random assignment is responsible for the observed difference in creativity scores between the groups? In other words, suppose each individual’s poem was going to get the same creativity score no matter which group they were assigned to, that the type of motivation in no way impacted their score. Then how often would the random-assignment process alone lead to a difference in mean creativity scores as large (or larger) than 19.88 – 15.74 = 4.14 points?
We again want to apply to a probability model to approximate a p-value , but this time the model will be a bit different. Think of writing everyone’s creativity scores on an index card, shuffling up the index cards, and then dealing out 23 to the extrinsic motivation group and 24 to the intrinsic motivation group, and finding the difference in the group means. We (better yet, the computer) can repeat this process over and over to see how often, when the scores don’t change, random assignment leads to a difference in means at least as large as 4.41. Figure 3 shows the results from 1,000 such hypothetical random assignments for these scores.

Only 2 of the 1,000 simulated random assignments produced a difference in group means of 4.41 or larger. In other words, the approximate p-value is 2/1000 = 0.002. This small p-value indicates that it would be very surprising for the random assignment process alone to produce such a large difference in group means. Therefore, as with Example 2, we have strong evidence that focusing on intrinsic motivations tends to increase creativity scores, as compared to thinking about extrinsic motivations.
Notice that the previous statement implies a cause-and-effect relationship between motivation and creativity score; is such a strong conclusion justified? Yes, because of the random assignment used in the study. That should have balanced out any other variables between the two groups, so now that the small p-value convinces us that the higher mean in the intrinsic group wasn’t just a coincidence, the only reasonable explanation left is the difference in the type of motivation. Can we generalize this conclusion to everyone? Not necessarily—we could cautiously generalize this conclusion to individuals with extensive experience in creative writing similar the individuals in this study, but we would still want to know more about how these individuals were selected to participate.

Statistical thinking involves the careful design of a study to collect meaningful data to answer a focused research question, detailed analysis of patterns in the data, and drawing conclusions that go beyond the observed data. Random sampling is paramount to generalizing results from our sample to a larger population, and random assignment is key to drawing cause-and-effect conclusions. With both kinds of randomness, probability models help us assess how much random variation we can expect in our results, in order to determine whether our results could happen by chance alone and to estimate a margin of error.
So where does this leave us with regard to the coffee study mentioned previously (the Freedman, Park, Abnet, Hollenbeck, & Sinha, 2012 found that men who drank at least six cups of coffee a day had a 10% lower chance of dying (women 15% lower) than those who drank none)? We can answer many of the questions:
- This was a 14-year study conducted by researchers at the National Cancer Institute.
- The results were published in the June issue of the New England Journal of Medicine , a respected, peer-reviewed journal.
- The study reviewed coffee habits of more than 402,000 people ages 50 to 71 from six states and two metropolitan areas. Those with cancer, heart disease, and stroke were excluded at the start of the study. Coffee consumption was assessed once at the start of the study.
- About 52,000 people died during the course of the study.
- People who drank between two and five cups of coffee daily showed a lower risk as well, but the amount of reduction increased for those drinking six or more cups.
- The sample sizes were fairly large and so the p-values are quite small, even though percent reduction in risk was not extremely large (dropping from a 12% chance to about 10%–11%).
- Whether coffee was caffeinated or decaffeinated did not appear to affect the results.
- This was an observational study, so no cause-and-effect conclusions can be drawn between coffee drinking and increased longevity, contrary to the impression conveyed by many news headlines about this study. In particular, it’s possible that those with chronic diseases don’t tend to drink coffee.
This study needs to be reviewed in the larger context of similar studies and consistency of results across studies, with the constant caution that this was not a randomized experiment. Whereas a statistical analysis can still “adjust” for other potential confounding variables, we are not yet convinced that researchers have identified them all or completely isolated why this decrease in death risk is evident. Researchers can now take the findings of this study and develop more focused studies that address new questions.
Explore these outside resources to learn more about applied statistics:
- Video about p-values: P-Value Extravaganza
- Interactive web applets for teaching and learning statistics
- Inter-university Consortium for Political and Social Research where you can find and analyze data.
- The Consortium for the Advancement of Undergraduate Statistics
Think It Over
- Find a recent research article in your field and answer the following: What was the primary research question? How were individuals selected to participate in the study? Were summary results provided? How strong is the evidence presented in favor or against the research question? Was random assignment used? Summarize the main conclusions from the study, addressing the issues of statistical significance, statistical confidence, generalizability, and cause and effect. Do you agree with the conclusions drawn from this study, based on the study design and the results presented?
- Is it reasonable to use a random sample of 1,000 individuals to draw conclusions about all U.S. adults? Explain why or why not.
CC licensed content, Original
- Modification, adaptation, and original content. Authored by : Pat Carroll and Lumen Learning. Provided by : Lumen Learning. License : CC BY: Attribution
CC licensed content, Shared previously
- Statistical Thinking. Authored by : Beth Chance and Allan Rossman, California Polytechnic State University, San Luis Obispo. Provided by : Noba. Located at : http://nobaproject.com/modules/statistical-thinking . License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
- The Replication Crisis. Authored by : Colin Thomas William. Provided by : Ivy Tech Community College. License : CC BY: Attribution
related to whether the results from the sample can be generalized to a larger population.
the collection of individuals on which we collect data.
a larger collection of individuals that we would like to generalize our results to.
using a probability-based method to select a subset of individuals for the sample from the population.
the expected amount of random variation in a statistic; often defined for 95% confidence level.
using a probability-based method to divide a sample into treatment groups.
the probability of observing a particular outcome in a sample, or more extreme, under a conjecture about the larger population or process.
related to whether we say one variable is causing changes in the other variable, versus other variables that may be related to these two variables.
General Psychology Copyright © by OpenStax and Lumen Learning is licensed under a Creative Commons Attribution 4.0 International License , except where otherwise noted.
Share This Book
Find Study Materials for
- Explanations
- Business Studies
- Combined Science
- Computer Science
- Engineering
- English Literature
- Environmental Science
- Human Geography
- Macroeconomics
- Microeconomics
- Social Studies
- Browse all subjects
- Read our Magazine
Create Study Materials
- Flashcards Create and find the best flashcards.
- Notes Create notes faster than ever before.
- Study Sets Everything you need for your studies in one place.
- Study Plans Stop procrastinating with our smart planner features.
- Drawing Conclusions
Why do the closing remarks in speeches always begin with the phrase, "In conclusion"? It's remarkably the same thought process that occurs when a group of astronomers look at a blip on a computer screen and soon announce the discovery of some distant celestial object. How is that possible? Well, the person concluding their speech and the enthusiastic astronomer are satisfied that their work is coming to an end. They have done their duty to the best of their ability and are confident that they have covered all the bases, and it is safe to conclude proceedings. In the case of the astronomer, though, the process is a bit more scientifically rigorous. In this article, we will discuss what it means to draw a conclusion and how it can be done, scientifically.

Create learning materials about Drawing Conclusions with our free learning app!
- Instand access to millions of learning materials
- Flashcards, notes, mock-exams and more
- Everything you need to ace your exams
- Astrophysics
- Atoms and Radioactivity
- Circular Motion and Gravitation
- Classical Mechanics
- Conservation of Energy and Momentum
- Electric Charge Field and Potential
- Electricity
- Electricity and Magnetism
- Electromagnetism
- Electrostatics
- Energy Physics
- Engineering Physics
- Famous Physicists
- Fields in Physics
- Fundamentals of Physics
- Further Mechanics and Thermal Physics
- Geometrical and Physical Optics
- Kinematics Physics
- Linear Momentum
- Magnetism and Electromagnetic Induction
- Measurements
- Mechanics and Materials
- Medical Physics
- Modern Physics
- Nuclear Physics
- Oscillations
- Particle Model of Matter
- Physical Quantities And Units
- Physics of Motion
- Quantum Physics
- Rotational Dynamics
- Scientific Method Physics
- Data Collection
- Data Representation
- Equations in Physics
- Uncertainties And Evaluations
- Solid State Physics
- Space Physics
- Thermodynamics
- Torque and Rotational Motion
- Translational Dynamics
- Turning Points in Physics
- Wave Optics
- Waves Physics
- Work Energy and Power
The definition of drawing a conclusion
An experimenter aims to test a hypothesis (which is a statement about what the experimenter expects will happen in the experiment) and possibly answer some larger, important question. At the end of each experiment, an experimenter makes a statement that summarizes what they have learnt from the conducted observation. This is called a conclusion , and we can define the drawing of a conclusion as follows.
We can define the drawing of a conclusion as stating the insight gained from experimenting.
All that is learned during an investigation can be summarised in a concluding statement, called the conclusion . In simple terms, the conclusion of any research should be based purely on the findings of that research. It is supported by facts and proof from the research conducted.
The steps involved in drawing conclusions
In conducting scientific research, an experimenter will follow the scientific method described in the steps below. The experimenter will:
- ask a question and formulate a hypothesis,
- conduct an experiment or investigation,
- collect, represent and analyse information,
- interpret the results,
- and draw a conclusion .
The steps above outline the scientific method very briefly. As scientists, we must first formulate a hypothesis or a research question. This will determine the path that our research journey will take. Next, we will conduct an experiment or investigation to test our hypothesis. The results from our investigation will be collected, analysed and interpreted. We should have gained enough information to answer our research question, and the final step in conducting research is then to draw a conclusion . We'll discuss the scientific method in more detail in the next section. The figure below shows a simple representation of the steps involved in conducting research and arriving at a conclusion.

Using the scientific method to draw a conclusion
The steps above, from creating a hypothesis to drawing a conclusion, form the scientific method, as we've just mentioned. There are other steps in the scientific method that we have omitted for brevity (e.g. communicating findings), but for now, we'll deal with the experiment and its immediate outcomes. The figure below shows how this process can be repeated to continuously refute science with better science.

Ideally, the conclusion of an investigation should prove or disprove the hypothesis and answer the research question. This is not always the case, as the scientific inferences may leave the scientist no nearer to the answer they require.
An example of drawing a conclusion
The example below outlines the steps involved in the scientific method and eventually reaches the final step, which is the focus of this article; drawing a conclusion.
Assume Mark and Joseph create a hypothesis regarding the January temperatures in their neighbourhood. They have followed the steps mentioned above to come to a conclusion.
Step 1: Formulating the hypothesis
Hypothesis 1: January days are hottest before 14:00, according to Mark.
Hypothesis 2: The warmest time of January days is after four o'clock in the afternoon, according to Joseph.
After setting their hypotheses, they want to perform an experiment and gather data to validate them.
Step 2: Performing an experiment
They decide to use a digital thermometer to measure the temperature outside at specific times during each day for January.
Step 3: Collecting and representing the data
The temperature data is collected for January and then averaged, as indicated in the diagram below.
Step 4: Interpretation of results
By simply looking at the data that is visualized by the vertical bar graph above, one can notice that t he temperature increases from 08:00 until 12:00, at which point it reaches a maximum and decreases thereafter.
Step 5: Drawing conclusions
Joseph can tell from the graph that the investigation's findings contradict his ideas. Based on the data recorded and the observations, the hottest temperature occurs before 14:00, and not after 4 o'clock in the afternoon.
The findings corroborate Mark's premise and he can derive the following conclusion that validates his initial hypothesis.
Conclusion: Winter days are the hottest before 14:00.
The example above highlights the importance of representing data. Data that is well-collected and well-represented can make analysis and inference much easier. In turn, this can make it easier to draw conclusions.
Even if you put major efforts into preparing data, analyzing results, and performing observations, the conclusion is crucial in deciding whether the project will succeed or fail.
On one hand, the results will not be taken seriously if an otherwise good experiment is summarized by a poor conclusion. On the other hand, even if the set-up and the data gathered are valid, but the conclusion drawn is not correct, the experiment will not be valid.
Keep in mind that whether a theory is accepted or disproven is not a measure of success or failure, because both outcomes contribute to scientific knowledge.
The differences between inferences and drawing conclusions
It may seem as if the words are interchangeable but there are differences between inferences and conclusions.
An inference is a fact that is assumed based on the information that is provided.
Simply, an inference is an assumed fact based on other facts. Here's an example that will make this idea clearer.
Imagine that you observe someone slamming a door. You might infer that this person is angry. That is, you used the fact that the door was slammed to assume the fact that this person is angry.
Inferences are important because scientists can often pose and answer questions about things that are not immediately apparent. Next, we can define a conclusion.
A conclusion refers to an explanation or interpretation of an observation . It is the next step in the information process and comes after critical thought and logical reasoning.
Let us revisit the previous example to illustrate the difference between inference and conclusion.
Imagine that you observe someone slamming a door. You might infer that this person is angry. This cannot be your conclusion, however, since critically you would know that more information is required. A conclusion could be that this person is strong enough to slam a door.
We can see that there is a clear difference between making an inference and drawing a conclusion. A good scientific example would be the one below.
Dinosaurs have been extinct for millions of years, so simply observing them is not a possible way of determining their diet. What we can do is study fossils of dinosaur droppings and determine the type of food they ate. The following events would occur in the given order.
Observation : Studies of some dinosaur droppings show signs of crushed bones.
Inference : These dinosaurs preyed on herbivores that were smaller than themselves. This is a pretty safe assumption to make but we don't know this for certain.
Conclusion : These dinosaurs ate animals. However, they could have been predators, scavengers, or maybe even cannibals.
Drawing Conclusions - Key takeaways
- Drawing conclusions is the final step in any research or any scientific investigation.
We can define the drawing of a conclusion as the insight gained from experimenting. All that is learned during an investigation can be summarised in a concluding statement.
- Ideally, the conclusion of an investigation should prove or disprove the hypothesis and answer the research question.
- and draw a conclusion.
- A conclusion refers to an explanation or interpretation of an observation . It is the next step in the information process and comes after critical thought and logical reasoning. It is a fact that follows logically from the information that is provided.
- Fig. 1- Four stage scientific method (https://commonswikimedia.org/wiki/File:4_stage_Scientific_Method.jpg) by Brightyellowjeans is licensed by CC BY-SA 4.0 (https://creativecommons.org/licenses/by-sa/4.0/deed.en).
- Fig. 2- The Scientific Method (https://commons.wikimedia.org/wiki/File:The_Scientific_Method.svg) by Efbrazil is licensed by CC BY-SA 4.0 (https://creativecommons.org/licenses/by-sa/4.0/deed.en).
Flashcards inDrawing Conclusions 15
How can we define the phrase "drawing a conclusion"?
Is the conclusion linked to the hypothesis?
Yes. Ideally, the conclusion of an investigation should prove or disprove the hypothesis.
Drawing conclusions is the last step of the scientific method.
A conclusion for a scientific experiment can be drawn without collecting data or conducting research.
On what part of the experiment should the conclusion be based?
How do you support your conclusion of an experiment?
It should be supported with particular facts and proof from the experiment.

Learn with 15 Drawing Conclusions flashcards in the free StudySmarter app
We have 14,000 flashcards about Dynamic Landscapes.
Already have an account? Log in
Frequently Asked Questions about Drawing Conclusions
What is drawing conclusion ?
The drawing conclusion is a statement, at the end of each experiment, that summarizes what the experimenter have learnt from the conducted observation. This is what we call drawing conclusions.
What is an example of drawing conclusion ?
An example of drawing conclusion can be the following situation:
After repeating the experiment 10 times, we were able to validate the initial hypothesis, and confirm that the distilled water boils at 100 degrees Celsius. This is an example of a conclusion. The process of reaching this conclusion is called drawing a conclusion.
What are the 3 steps for drawing conclusions?
The 3 steps for drawing conclusions are:
- Refer to your experiment's hypothesis.
- Examine the results of your experiment. Analyze the data, doing any computations or graphs necessary to spot trends or patterns in your findings.
- Check to see if your evidence backs up your theory or proves it to be wrong. Make a statement that summarizes your findings.
How to draw a conclusion in the scientific method ?
To draw a conclusion in the scientific method, we can follow the next steps:
- State if you agree or disagree with your hypothesis.
- Support your statement with particular facts (proof) from your experiment.
- Talk about if the problem/question has been resolved.
- Describe further difficulties or experiments that should be carried out.
What is the differences between drawing conclusion and inferences?
The differences between drawing conclusion and interferences are that an inference is a fact that is assumed based on the information provided. A conclusion is logically and factually based on data that is observed, recorded and well represented.
Test your knowledge with multiple choice flashcards
Scientists discover crushed bones in the fossils of dinosaur droppings. They decide that the dinosaur had eaten other dinosaurs. In this case, did the scientists provide a conclusion or inference?

Join the StudySmarter App and learn efficiently with millions of flashcards and more!
Keep learning, you are doing great.

About StudySmarter
StudySmarter is a globally recognized educational technology company, offering a holistic learning platform designed for students of all ages and educational levels. Our platform provides learning support for a wide range of subjects, including STEM, Social Sciences, and Languages and also helps students to successfully master various tests and exams worldwide, such as GCSE, A Level, SAT, ACT, Abitur, and more. We offer an extensive library of learning materials, including interactive flashcards, comprehensive textbook solutions, and detailed explanations. The cutting-edge technology and tools we provide help students create their own learning materials. StudySmarter’s content is not only expert-verified but also regularly updated to ensure accuracy and relevance.
StudySmarter Editorial Team
Team Drawing Conclusions Teachers
- 9 minutes reading time
- Checked by StudySmarter Editorial Team
Study anywhere. Anytime.Across all devices.
Create a free account to save this explanation..
Save explanations to your personalised space and access them anytime, anywhere!
By signing up, you agree to the Terms and Conditions and the Privacy Policy of StudySmarter.
Sign up to highlight and take notes. It’s 100% free.
Join over 22 million students in learning with our StudySmarter App
The first learning app that truly has everything you need to ace your exams in one place
- Flashcards & Quizzes
- AI Study Assistant
- Study Planner
- Smart Note-Taking

If you're seeing this message, it means we're having trouble loading external resources on our website.
If you're behind a web filter, please make sure that the domains *.kastatic.org and *.kasandbox.org are unblocked.
To log in and use all the features of Khan Academy, please enable JavaScript in your browser.

Letters to the Editor | Readers speak: Draw your own conclusions on Trump
Share this:.
- Click to share on Facebook (Opens in new window)
- Click to share on X (Opens in new window)
Daily e-Edition
Evening e-Edition
Letters to the Editor
Breaking news, letters to the editor | bear euthanized after ransacking ct home; another bear tested positive for rabies, subscriber only.

Draw your own conclusions on Trump
Most of us will never be a juror in a criminal court, but like it or not we are all in the court of public opinion.
In that court we are not constricted to “beyond reasonable doubt,” so all those waiting for a verdict in Donald Trump’s cases are possibly hiding behind a shield because they want to. Just because someone is found not guilty in criminal court that for sure does not mean they are innocent. They are two totally different things, as the O J Simpson case proved. We bend over backwards to make sure we don’t convict innocent people and, sadly, guilty people can walk away because of that. That’s our system but it should not stop is from using our common sense to make our own decision.
Vincent Curcuru, Simsbury
Using headlights helps visibility
It’s afternoon and you’re driving on Interstate 91. It’s raining, there’s light fog, and heavy spray is cast from nearby trucks.
Your vehicle is light gray. Your headlights are not on. You are invisible.
Truly invisible. You blend in with the mist and the spray and the rain, even during daylight hours.
You are invisible. I strongly suspect that if you were in an accident, you’d be considered at fault even if you weren’t at fault, because other drivers can’t be liable if they can’t see you.
Turn on your wipers, turn on your headlights. It’s the law.
M. Regina Cram, Glastonbury
More in Letters to the Editor

Commentary | Readers Speak: Letting CT high school seniors ‘assassinate’ each other is no game
")
Commentary | Readers speak: Absentee ballots to all CT voters would improve democratic process

Opinion | CT Op-Eds, columns, and takes aplenty: The Opinion newsletter

Commentary | Readers Speak: Choose your presidential vote wisely
Some Dinosaurs Evolved to Be Warm-Blooded 180 Million Years Ago, Study Suggests
Researchers studied the geographic distribution of dinosaurs to draw conclusions about whether they could regulate their internal temperatures
/https://tf-cmsv2-smithsonianmag-media.s3.amazonaws.com/accounts/headshot/Will-Sullivan-photo.png "drawing of conclusions in research")
Will Sullivan
Daily Correspondent
:focal(384x241:385x242)/https://tf-cmsv2-smithsonianmag-media.s3.amazonaws.com/filer_public/9f/ec/9fec1bc6-f957-41bd-a805-6c5e5458aa08/dromaeosaur_in_the_snow_by_davide_bonadonna_squared_-_hd_cropped_again.jpg "drawing of conclusions in research")
Two major groups of dinosaurs may have been warm-blooded —having evolved the ability to regulate their body temperatures—around 180 million years ago, according to a new study.
Scientists used to think that all dinosaurs were cold-blooded , meaning that, like modern lizards, their body temperatures were dependent on their surroundings. While scientists have since discovered that some dinosaurs were actually warm-blooded, they haven’t been able to pinpoint when this adaptation evolved, according to a statement from University College London.
The new findings suggest that theropods, a group of mostly carnivorous dinosaurs including Tyrannosaurus rex and Velociraptor , as well as the ornithischians, which include the mostly plant-eating relatives of Stegosaurus and Triceratops , may have both developed warm-bloodedness in the early Jurassic Period. This change might have been prompted by global warming that followed volcanic eruptions, according to the results published Wednesday in the journal Current Biology .
The study is the “first real attempt to quantify broad patterns that some of us had thought about previously,” Anthony Fiorillo , executive director of the New Mexico Museum of Natural History & Science who was not involved in the work, tells CNN ’s Katie Hunt. “Their modeling helps create a robustness to our biogeographical understanding of dinosaurs and their related physiology.”
Warm-blooded animals, which include mammals and birds, use energy from food to maintain a constant body temperature. Their bodies can shiver to generate heat, and they may sweat, pant or dilate their blood vessels to cool off. As a result, these animals can live in a wide range of environments.
On the other hand, cold-blooded creatures must move to different environments to control their body temperature. They might lie in the sun to warm up and move under a rock or into the water to cool off.
Previous work had uncovered evidence of warm-bloodedness in both theropods and ornithischians, such as feathers that trap body heat, according to the university’s statement. In the new study, the researchers studied the geographic spread of dinosaurs during the Mesozoic Era, which lasted from 230 million to 66 million years ago, by examining 1,000 fossils, climate models and dinosaur evolutionary trees.
They found that theropods and ornithischians lived in wide-ranging climates, and during the early Jurassic, these two groups migrated to colder areas. This suggested they had developed the ability to generate their own heat.
“If something is capable of living in the Arctic, or very cold regions, it must have some way of heating up,” Alfio Allesandro Chiarenza , a co-author of the study and a paleontologist at University College London, tells Adithi Ramakrishnan of the Associated Press (AP).
Long-necked sauropods, on the other hand, which include the Brontosaurus , seemed restricted to areas with higher temperatures. The team suggests this means sauropods could have been cold-blooded.
“It reconciles well with what we imagine about their ecology,” Chiarenza says to CNN. “They were the biggest terrestrial animals that ever lived. They probably would have overheated if they were hot-blooded.”
At around the same time, volcanic eruptions led to global warming and the extinction of some plant species.
“The adoption of endothermy, perhaps a result of this environmental crisis, may have enabled theropods and ornithischians to thrive in colder environments, allowing them to be highly active and sustain activity over longer periods, to develop and grow faster and produce more offspring,” Chiarenza says in the statement.
Jasmina Wiemann , a paleobiologist at the Field Museum of Natural History who was not involved in the new research, published a study in 2022 that came to a different conclusion: Based on oxygen intake in dinosaur fossils, she found that ornithischians were more likely cold-blooded, while sauropods were more likely warm-blooded.
She tells the AP that considering information on dinosaurs’ body temperatures and diets, not just their geographic distribution, can help scientists understand when dinosaurs evolved to be warm-blooded.
Get the latest stories in your inbox every weekday.
/https://tf-cmsv2-smithsonianmag-media.s3.amazonaws.com/accounts/headshot/Will-Sullivan-photo.png "drawing of conclusions in research")
Will Sullivan | | READ MORE
Will Sullivan is a science writer based in Washington, D.C. His work has appeared in Inside Science and NOVA Next .
Take the Quiz: Find the Best State for You »
What's the best state for you », nikki haley writes 'finish them' on israeli artillery shell, drawing criticism.
Nikki Haley Writes 'Finish Them' on Israeli Artillery Shell, Drawing Criticism

Former Republican presidential contender Nikki Haley tours Kibbutz Nir Oz in the aftermath of the deadly October 7 attack by Palestinian Islamist group Hamas, southern Israel May 27, 2024. REUTERS/Amir Cohen/File Photo
By Kanishka Singh
WASHINGTON (Reuters) - Republican former presidential contender Nikki Haley wrote "Finish Them!" on an Israeli artillery shell during a recent visit to Israel, amid an ongoing assault on Gaza that has left tens of thousands dead in the past eight months.
An image of Haley crouched in front of pallets of shells, writing with a marker on one, was shared on social media by Danny Danon, an Israeli politician and former ambassador to the United Nations. A second image he shared showed Haley's signed message: "Finish them - America [HEART] Israel, Always."
Danon had accompanied Haley, a former U.S. ambassador to the United Nations when Donald Trump was president, during the visit this past weekend.
War in Israel and Gaza

Haley was quickly criticized for the message by human rights groups.
"Conflict is no place for stunts. Conflict has rules. Civilians must be protected," Amnesty International said in a statement on Wednesday while reacting to Haley's act.
Israel's three-week-old offensive in Gaza's Rafah has prompted an outcry from global leaders after an airstrike on Sunday killed at least 45 people when a blaze ignited in a tent camp in a western district.
The World Court last week ordered Israel to immediately halt its military assault on Rafah, in a landmark emergency ruling in South Africa's case accusing Israel of genocide. Israel denies genocide allegations.
Kenneth Roth, a former Human Rights Watch executive director, said of Haley in a post on X on Tuesday night: "Why not just sign I favor Israeli war crimes."
Later on Wednesday, Haley posted on X: "Israel must do whatever is necessary to protect her people from evil," adding that Israel was fighting "enemies" of the United States.
Reuters could not reach Haley for comment immediately on Wednesday.
Haley has been a longstanding supporter of Israel, whose war in Gaza has come under mounting international criticism, divided U.S. lawmakers over the Biden administration's support and prompted protests at campuses across the United States.
The local Palestinian health ministry puts the death toll from the war at over 36,000. There is also widespread hunger in the narrow coastal enclave and nearly its entire 2.3 million population has been displaced.
Israel says it is acting in self-defense after the militant Palestinian group Hamas attacked Israel on Oct. 7, killing around 1,200 people and seizing more than 250 hostages, according to Israeli tallies.
(Reporting by Kanishka Singh in Washington; editing by Heather Timmons and Leslie Adler)
Copyright 2024 Thomson Reuters .
Join the Conversation
Tags: United States , Israel , Middle East
America 2024

Health News Bulletin
Stay informed on the latest news on health and COVID-19 from the editors at U.S. News & World Report.
Sign in to manage your newsletters »
Sign up to receive the latest updates from U.S News & World Report and our trusted partners and sponsors. By clicking submit, you are agreeing to our Terms and Conditions & Privacy Policy .
You May Also Like
The 10 worst presidents.
U.S. News Staff Feb. 23, 2024

Cartoons on President Donald Trump
Feb. 1, 2017, at 1:24 p.m.

Photos: Obama Behind the Scenes
April 8, 2022

Photos: Who Supports Joe Biden?
March 11, 2020

When Will the Israel-Hamas War End?
Cecelia Smith-Schoenwalder May 29, 2024

Biden Tries to Energize Black Voters
Laura Mannweiler May 29, 2024

Report: Global Executions Rose in 2023
Elliott Davis Jr. May 29, 2024

Fed: Economy Still Expanding
Tim Smart May 29, 2024

The GOP’s Risky Garland Contempt Vote
Aneeta Mathur-Ashton May 29, 2024

Jurors Face 'Weight' of Trump Decision
Lauren Camera May 28, 2024

Return-to-Office Orders: A Survey Analysis of Employment Impacts
How did employers expect return-to-office (RTO) orders to affect employment? Were those expectations correct? We use special questions from the Richmond Fed business surveys to shed light on these questions. Overall, RTO orders were expected to reduce employment, but there was both substantial uncertainty and heterogeneity in expectations. Some employers even expected that RTO would increase employment. Ex post, employers believe RTO orders had a muted effect on employment. We find that the service sector was more likely to both issue RTO orders and expect and experience a reduction in employment.
The COVID-19 pandemic changed the way that both employers and employees think about the location of work. 1 The advent of remote work en masse in 2020 has been followed by a gradual implementation of requiring workers to work from the office, at least for some of their workweek. These forced return-to-office (RTO) orders have come with controversy: Many employers have implemented these policies, while many employees have resisted.
In this article, we attempt to shed light on the effects of RTO by reporting on special questions we asked in the March Richmond Fed business surveys . Specifically, these questions shed light on both the anticipated and realized employment outcomes of RTO orders from the employer's perspective. We find that uncertainty in the decision-making process was prevalent, but also that realized outcomes were generally muted. RTO did have an expected and actual negative effect on employment, but only in some sectors and for some employers. For others, RTO was a means of increasing employment. Our results highlight the large uncertainty in the pandemic, the heterogeneity of firms and the large heterogeneity of workers.
Why Examine the Impacts of RTO Orders?
This survey builds on a recent literature investigating the implications of remote work for workers, businesses and local economies . Uniquely, it attempts to discern how business leaders anticipated RTO policies would impact their firms as well as the actual impact on employment within their firms. Although there is work evaluating the benefits and costs to employers in terms of productivity or labor/non-labor costs, 2 there has been little work to understand the firm-by-firm implication of articulating and enforcing an RTO order.
Research indicates that hybrid options are highly valued by employees , 3 but how many separations can be attributed to an RTO policy? There is evidence that managers value in-person work more than employees, 4 but does that result in actual separations when RTO orders are implemented? Our results suggest the effects of these policies were muted.
There is also evidence of wide variation in employee hybrid-work preferences and in their willingness to pay for the option to work from home 5 as well as evidence that the value workers place on the "amenity" of remote or hybrid work has implications for aggregate wage changes in the macroeconomy. 6 Our work indicates this heterogeneity in preferences may have dampened the effect of RTO orders on employment. Our results are consistent with a literature that is still relatively mixed about the net effect on employers and workers of remote or on-site policies.
Methodology
The Federal Reserve Bank of Richmond has surveyed CEOs and other business leaders across the Fifth Federal Reserve District 7 for almost 30 years, currently gathering around 200-250 responses per month. The survey panel underweights the smallest firms and, due to the history of the survey, manufacturing firms make up about one-third of respondents even though they make up a much smaller share of establishments in the Fifth District or the nation.
In addition to a series of questions about variables such as demand, employment and prices, respondents are commonly asked a set of ad hoc questions. Here, we focus on a set of questions asked in March 2024 regarding the extent to which respondents articulated and enforced a mandatory RTO policy and what they expected upon its implementation. Emily Corcoran reported on employers' on-site general expectations for employees and how those have changed. But here, we focus on business leaders' expectations of RTO policy effects, providing insight into the anticipated and unanticipated employment effects of RTO orders. We begin by assessing whether the establishment implemented RTO. These results are tabulated in Table 1.
Overall, explicit RTO orders were relatively rare, with only 20 percent of respondents articulating RTO orders in the last three years. This small percentage is partly because 37 percent of respondents — many of them manufacturing firms — were fully on-site before the end of 2020, and an additional 26 percent of respondents said RTO wasn't applicable for their companies. 8 Of the remaining companies, there is a roughly equal split between firms that have an explicit RTO policy (20 percent of the full sample) and those that do not (16 percent of the full sample).
We asked these 20 percent of employers about the expected consequences of issuing RTO orders. Did they expect workers to quit because of these policies? Were they sure about the effect on employment? We also asked employers about their assessment of realized outcomes. Did workers quit as anticipated? Did RTO help the firm recruit workers?
What Did Employers Expect, and What Actually Happened?
Perhaps surprisingly, we found two-thirds of employers expected no impact on (net) employment from RTO orders, while 16 percent were too unsure of the impact to answer (Table 2). Among the 18 percent that expected some impact, the anticipated outcome was split between those that expected a decrease in employment (11 percent) and those that expected an increase (7 percent).
Why might employment increase? One possibility derives from employees feeling more connected to their co-workers with greater mentoring opportunities when in the office. 9 This could reduce quitting and improve hiring, as one survey respondent reported that, "...the employees that [formerly] chose to work remotely decided that they were more productive in the office. We are [now] 90+ percent in the office."
Additionally, RTO orders have often been hybrid, 10 potentially allowing the benefits of office culture to be obtained without sacrificing all of the flexibility associated with remote work.
We also asked employers about their evaluation of outcomes, and the results are given in Table 3. Here, a greater percentage reported no impact (82 percent), while 4 percent assessed that RTO had decreased employment, and 4 percent assessed that RTO had actually increased employment. (Nine percent were still unsure.)
Sectoral level analysis reveals employment impacts (both expected and realized) were concentrated in the service sector. In manufacturing, no firms concretely expected a change in employment (though some were unsure), and ex post they believe RTO did not cause them to lose workers. In services, however, only 59 percent expected no impact, while 16 percent expected a negative impact on employment. Ex post, impact on employment was less than expected.
While our analysis is suggestive, there are a few limitations. Foremost, our effective sample size was small, meaning some of these results could be driven by sampling error. Second, it has been years since some employers implemented RTO policies, so their memories of their expectations could be inaccurate. Third, our survey did not control for any other firm changes — such as changes in wages or product demand — that could confound our findings. Fourth, although our findings provide insight into net employment gains and losses, they do not speak to hiring and firing separately. 11
With these caveats in mind, however, our results show that RTO — while still a common topic of conversation — is not necessarily important to employers' and workers' employment decisions. Concerns about employment effects ex ante mostly did not materialize. Employment effects that did materialize were concentrated in services and resulted in a net gain of employees in some cases, rather than a loss.
Grey Gordon is a senior economist and Sonya Ravindranath Waddell is a vice president and economist, both in the Research Department of the Federal Reserve Bank of Richmond. The authors thank Jason Kosakow for helping to develop and execute the survey and for providing the tabulations underlying this analysis and thank RC Balaban, Zach Edwards and Claudia Macaluso for providing feedback on an earlier draft.
See, for example, the 2023 paper " The Evolution of Work From Home " by Jose Maria Barrero, Nicholas Bloom and Steven Davis.
See, for example, the 2024 working paper " The Big Shift in Working Arrangements: Eight Ways Unusual " by Steven Davis.
See, for example, the 2023 working paper " How Hybrid Working From Home Works Out " by Nicholas Bloom, Ruobing Han and James Liang.
See the previously cited paper " How Hybrid Working From Home Works Out ."
See, for example, the 2021 working paper " Why Working From Home Will Stick " by Jose Maria Barrero, Nicholas Bloom and Steven Davis.
See, for example, the 2024 working paper " Job Amenity Shocks and Labor Reallocation (PDF) " by Sadhika Bagga, Lukas Mann, Aysegul Sahin and Giovanni Violante.
The Fifth District comprises the District of Columbia, Maryland, North Carolina, South Carolina, Virginia and most of West Virginia.
Those who answered "not applicable" are presumably firms where work is necessarily done in person.
See, for example, the 2023 article " About a Third of U.S. Workers Who Can Work From Home Now Do So All the Time " by Kim Parker.
The previously cited article by Emily Corcoran noted that 38 percent of firms are in the office in between one and four days a week.
See the 2022 article " Changing Recruiting Practices and Methods in the Tight Labor Market " by Claudia Macaluso and Sonya Ravindranath Waddell for an analysis of how hiring practices have changed in the tight labor market that has prevailed since 2020.
This article may be photocopied or reprinted in its entirety. Please credit the authors, source, and the Federal Reserve Bank of Richmond and include the italicized statement below.
V iews expressed in this article are those of the authors and not necessarily those of the Federal Reserve Bank of Richmond or the Federal Reserve System.
Subscribe to Economic Brief
Receive a notification when Economic Brief is posted online.
By submitting this form you agree to the Bank's Terms & Conditions and Privacy Notice.
Thank you for signing up!
As a new subscriber, you will need to confirm your request to receive email notifications from the Richmond Fed. Please click the confirm subscription link in the email to activate your request.
If you do not receive a confirmation email, check your junk or spam folder as the email may have been diverted.
Phone Icon Contact Us
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 29 May 2024
Research on underwater robot ranging technology based on semantic segmentation and binocular vision
- Qing Hu 1 ,
- Kekuan Wang 2 ,
- Fushen Ren 1 &
- Zhongyang Wang 1
Scientific Reports volume 14 , Article number: 12309 ( 2024 ) Cite this article
Metrics details
- Computer science
- Mechanical engineering
Based on the principle of light refraction and binocular ranging, the underwater imaging model is obtained. It provides a theoretical basis for underwater camera calibration. In order to meet the requirement of underwater vehicle to identify and distance underwater target, a new underwater vehicle distance measurement system based on semantic segmentation and binocular vision is proposed. The system uses Deeplabv3 + to identify the underwater target captured by the binocular camera and generate the target map, which is then used for binocular ranging. Compared with the binocular ranging using the original drawing, the measurement accuracy of the proposed method has not changed, the measurement speed is increased by 30%, and the error rate is controlled within 5%, which meets the needs of underwater robot operations.
Similar content being viewed by others

A Dataset with Multibeam Forward-Looking Sonar for Underwater Object Detection

Deep visual domain adaptation and semi-supervised segmentation for understanding wave elevation using wave flume video images

Weakly supervised underwater fish segmentation using affinity LCFCN
Introduction.
The ocean accounts for more than 70% of the earth's total area and is rich in biological and mineral resources. All countries are racing to study the technology related to underwater robots to speed up the development and utilization of Marine resources. Whether it is the study of Marine life and submarine environment, or the detection of submarine pipeline and the salvage operation, it is inseparable from the target location and distance measurement. Compared with sonar, laser and radar, underwater optical equipment has the advantages of low cost, easy deployment and high resolution. Binocular vision technology can accurately measure underwater objects at close range, and help underwater robots perceive and locate the surrounding environment more accurately, thus improving their efficiency and safety in underwater tasks.At present, some progress has been made in the research of underwater binocular vision ranging technology. On the one hand, researchers have improved the accuracy and robustness of ranging by optimizing algorithms such as camera calibration, image preprocessing, and stereo matching. For example, using Zhang Zhengyou calibration method or other optimization algorithms to calibrate binocular cameras accurately can eliminate the distortion and error and improve the ranging accuracy. At the same time, in view of the special properties of underwater images, researchers have also proposed a variety of image enhancement and denoising methods to improve image quality and provide a better basis for subsequent stereo matching and ranging. On the other hand, with the continuous development of artificial intelligence technologies such as deep learning, underwater binocular visual ranging technology has also begun to be combined with these advanced technologies 1 , 2 .By training deep neural networks for feature extraction and matching, the accuracy and efficiency of ranging can be further improved. In addition, deep learning can also be used to deal with complex lighting conditions and noise disturbances in underwater environments, improving the robustness of the system.
The deep learning method has stronger flexibility and adaptability in dealing with the binocular vision ranging problem under water, and can automatically learn the strategy of extracting features and matching from images without too much manual intervention. However, deep learning methods often require large amounts of labeled data for training, and the model is complex and computationally expensive. Especially in underwater environments, obtaining high-quality, diverse annotated data can be a challenge. If the training data is insufficient or unevenly distributed, the model may have poor generalization ability and be difficult to adapt to different underwater scenes.
In contrast, stereo matching algorithm may have poor matching effect due to the change of lighting conditions and the loss of texture, and requires a lot of calculation to find the optimal matching result, which may lead to a slow running speed of the algorithm and difficult to meet the real-time requirements. However, it performs well in some scenarios and is more versatile and practical. The stereo matching algorithm calculates the depth information according to the parallax principle by directly comparing the corresponding points of the left and right views. This approach is intuitive and easy to understand, making it easy for engineers and researchers to debug and optimize. In the case of proper optimization, the stereo matching method can achieve high computational efficiency, especially when dealing with fixed mode scenes. In addition, stereo matching methods typically do not require large amounts of training data, so they may be more practical in some applications.
Deep learning method and stereo matching algorithm have unique advantages in underwater binocular vision ranging, but there are also some disadvantages. In practical application, it is necessary to choose the appropriate method according to the specific application scenario and demand, and take corresponding measures to overcome its disadvantages, so as to improve the accuracy and reliability of ranging.
Zhang 3 proposed a target recognition and ranging system, built a convolutional neural network model, used image processing technology to identify the target and the triangular similarity principle to calculate the target distance, and finally achieved the purpose of recognition and detection. Yang 4 used SGBM(Semi-Global Block Matching) stereo matching algorithm to enhance image contrast, reduce the influence of image color spots, ensure the robustness of the algorithm, and improve the matching search speed. Xu 5 proposed a binocular vision guidance method, which used the image adaptive binarization algorithm and the pseudo-light source elimination algorithm to obtain the pixel coordinates of the light source identification center of the left and right images, extracted and matched the light source features, completed the accurate matching of the light source in the left and right images, and finally conducted three-dimensional ranging of the light source array.Liu 6 proposed a novel underwater binocular depth sensing imaging element optical device. The advantage of binocular lens is that it does not require distortion correction or camera calibration. With deep-learning support, this stereo vision system can realize the fast underwater object’s depth and image computation for real-time processing capability. Meanwhile,He 7 also proposed a stereo vision meta-lens imaging system for assisted driving vision, a comprehensive perception including imaging, object detection, instance segmentation, and depth information. The assisted driving vision provides multimodal perception by integrating the raw image, instance labels, bounding boxes, segmentation masks in depth pseudo color, and depth information for each detected object.
In this paper, a binocular vision ranging method based on semantic segmentation image is proposed by taking full advantage of deep learning and stereo matching algorithm. The method uses Deeplabv3+ semantic segmentation model to segment the object, and removes the background and retains only the object region. In the process of stereo matching, by limiting the search range of parallax to the object segmentation region, the calculation burden of irrelevant region is reduced, and the speed of binocular vision ranging is effectively improved. The experimental results show that compared with the binocular measurement results using the original image, the measurement speed is increased by nearly 30% while the measurement accuracy is unchanged.
Binocular ranging principle
Binocular distance measurement is a principle that simulates biological binocular distance measurement 8 , 9 . The left and right images are obtained by binocular camera, and the acquired images are transmitted to the computer for analysis and calculation of parallax, and then the three-dimensional spatial information of the target object is obtained. In an ideal situation, binocular distance measurement is obtained by two identical and parallel cameras, and the target distance information is calculated 10 , 11 . Its schematic diagram is shown in Figure 1 : Suppose P is the target to be measured, O l and O r are the photocentroid of the left and right cameras, T is the photocentroid distance of the left and right cameras, also known as the baseline distance, f is the focal length of the camera, P l and P r are the coordinates of point P in the image coordinate system of the left and right cameras, and Z is the vertical distance from point P to the camera.

Binocular visual ranging principle.
As can be seen from Fig. 1 , \(\Delta PP_{l} P_{r} \sim \Delta PO_{l} O_{r}\) ,formula ( 1 ) can be obtained:
Then, the expression of distance Z between the target to be measured and the camera can be derived as follows: Formula ( 2 ):
where, \(X_{l}\) and \(X_{r}\) are the horizontal coordinates of pixel points in the left and right images of point P respectively, d is the parallax between the left and right cameras, \(d = X_{l} - X_{r}\) , and the focal length f and baseline distance T can be obtained by camera calibration. Therefore, the distance information of the target to be measured can be obtained only by obtaining parallax d.
In the imaging of binocular stereo vision system, it is mainly to convert spatial three-dimensional coordinates to pixel coordinates, and the relationship between the four coordinate systems involved is shown in Fig. 2 . Where in, the image coordinate system \((x,y)\) : the coordinate system takes the center of the image Oi as the origin, the x axis and y axis directions are consistent with the horizontal direction and vertical direction of the image respectively, and the physical length of the unit pixel in the x axis and y axis directions are \(dx\) and \(dy\) respectively. Pixel coordinate system \((u,v)\) : The origin O o of the coordinate system is the upper left corner of the image, and the u axis and v axis are parallel to the coordinate system of the image coordinate system, which is mainly used to describe the pixel position of a certain point in the image 12 , 13 . Camera coordinate system \((X_{C} ,Y_{C} ,Z_{C} )\) : The coordinate system takes the optical center of the camera Oc as the origin, and the image coordinate system is a transmission projection relationship, so the X and Y axes of the coordinate system are consistent with the horizontal and vertical directions of the picture, and the Z axis is parallel to the optical axis of the lens 14 , 15 . The distance between the origin of the camera coordinate system and the origin of the plane coordinate system of the picture is the focal length of the camera. World coordinate system \((X_{W} ,Y_{W} ,Z_{W} )\) : This coordinate system is an absolute coordinate system in real space to determine the relative position of the camera and the target in space, and the origin can be selected by oneself subjectively.

Relation diagram of the four coordinate systems.
The conversion process between the four coordinate systems is shown in Figure 3 :

Transformation diagram of the four coordinate systems.
If O i is set as \((u_{0} ,v_{0} )\) in pixel coordinate system, the corresponding relation of a point on the imaging plane in pixel coordinate system \(p(x,y)\) is shown in formula ( 3 ).
Written in matrix form as in formula ( 4 ):
According to the triangular similarity principle, the corresponding relationship between point P \((X_{C} ,Y_{C} ,Z_{C} )\) on the space and point p on the imaging plane can be obtained as shown in formula ( 5 ):
where f is the focal length of the camera, then the homogeneous linear transformation form can be expressed as formula ( 6 ):
By substituting formula ( 6 ) into formula ( 4 ), the corresponding relationship between point P on space and pixel coordinate system can be obtained, as shown in formula ( 7 ):
The conversion between the world coordinate system and the camera coordinate system only needs to be realized through the rotation matrix R and the translation vector T 16 , 17 , then the corresponding relationship is shown in Formula ( 8 ):
Then substitute formula ( 8 ) into formula ( 7 ) to obtain the correspondence between the world coordinate system and the pixel coordinate system, as shown in formula ( 9 ):
Simplified as formula ( 10 ):
where, \(M_{1}\) represents the camera internal parameter matrix; \(M_{2}\) represents the camera external parameter matrix.
Underwater imaging model analysis
During the propagation of light from the underwater object to the camera lens, it undergoes two refractions, which occur at the interface between water and glass and the interface between glass and air. Because the glass is thin and uniform in texture, the refraction effect of the glass plate can be ignored 18 , 19 . Two refractions are equivalent to one refraction from water to air. For the convenience of the study, we assume that the optical axis of the camera is perpendicular to the refraction plane. After the above equivalence, the underwater imaging model can be simplified to Figure 4 .

Underwater imaging model.
In Fig. 4 , \(P\left( {X_{W} ,Y_{W} ,Z_{W} } \right)\) is the target point to be measured, \(O_{{1 }}\) is the real position of the camera, \(O_{{2 }}\) is the intersection point of the extension line of incident light in water on the optical axis of the camera, which is taken as the virtual camera position, \(O\) is the refraction point of incident light on the interface between water and air 20 , 21 , A is the intersection point of the camera optical axis and the interface between water and air, \(\theta_{{1 }}\) and \(\theta_{{2 }}\) are respectively the incidence Angle and the refraction Angle.
\(n_{{1}}\) and \(n_{{2 }}\) are the refractive indices of water and air respectively. According to triangle similarity and refraction law \(n_{{1 }} \sin \theta_{{1 }} = n_{{2 }} \sin \theta_{{2 }}\) , it can be obtained:
Because the optical axis of the real camera and the virtual camera coincide, the projection length of \(OA\) on the two cameras is the same, that is, \(X_{{1 }} = X_{{2 }}\) , \(X_{{1 }}\) and \(X_{{2 }}\) are the imaging lengths of \(OA\) in the real camera and the virtual camera, respectively. As a result:
According to formulas ( 12 ) and ( 13 ):
Equations ( 11 ) and ( 14 ), we get:
When the Angle between the light and the normal is small, the virtual focal length of the camera can be calculated by formula ( 16 ):
According to the above analysis, it is found that the actual focal length of the camera under water changes, and in a certain range, this change can be regarded as a linear change. Therefore, when the camera is used underwater, the focal length of the virtual camera can be obtained according to the refractive index. In other words, under normal circumstances, the focal length obtained by the water calibration should be 1.33 times that of the air 22 .
The camera itself is biased during the manufacturing and installation process, and the effect of underwater refraction on image imaging can produce even greater distortion. Figure 5 shows the schematic diagram of imaging deviation caused by underwater refraction 23 .

Diagram of distortion caused by underwater refraction.
In the figure, \(P\) is the three-dimensional coordinate point, \(p_{2}\) is the actual imaging point, \(p_{1}\) is the ignored refraction imaging point, \(f\) is the focal length, \(d\) is the distance from the camera to the waterproof plane, \(\theta_{1}\) and \(\theta_{2}\) are respectively the incidence Angle and the refraction Angle. The following relationship can be obtained through geometric relations:
From formulas ( 17 ) and ( 18 ):
Since \(X_{W} \gg d\) , according to \(n_{{1}} \sin \theta_{{1}} = n_{{2}} \sin \theta_{{2}}\) , we can get:
It can be found that the distance between the imaging point and the imaging center and the distance between the luminous point and the optical axis is no longer a linear relationship in the pinhole imaging model, but a nonlinear relationship, which causes imaging deviation and intensifies image distortion, and the distortion becomes more obvious with the increase of distance.
Through the above analysis, it is found that the deviation caused by underwater refraction can be partially corrected by equivalent focal length change. However, this deviation is not linear, and for the nonlinear part, it needs to be corrected by using the image distortion correction polynomial.
According to underwater imaging analysis, it is found that underwater refraction has two main effects on the camera:
(1) The equivalent focal length of the camera changes, and the change in focal length can be regarded as the product of the original focal length and the ratio of refractive index in a certain Angle of view;
(2) The image distortion is intensified, so that the previous distortion correction does not meet the underwater use, and the distortion increases with the increase of the distance from the imaging center, similar to the pillow distortion.
In order to ensure the accuracy of underwater target ranging and size measurement, the following formula is used to correct the distortion and ensure the measurement accuracy of the system.
(1) As the distance from the imaging point to the image center increases, the radial distortion increases accordingly, so the quadratic and higher-order polynomial functions related to the distance are used to correct the radial distortion. The radial distortion correction formula is as follows:
In the formula, \((x,y)\) is the coordinate of the distortion point in the image before correction, \((x_{r} ,y_{r} )\) is the coordinate of the distortion point in the image after correction, r is the distance from the distortion point to the image center, and \(k_{1}\) , \(k_{2}\) and \(k_{3}\) are the radial distortion coefficients.
(2) The optical axis of the lens is not perpendicular to the image plane, causing tangential distortion. Tangential distortion correction formula is as follows:
In the formula, \(p_{1}\) and \(p_{2}\) are tangential distortion coefficients.
Image semantic segmentation based on Deeplabv3+
Semantic segmentation is an important technique in the field of computer vision, which aims to assign each pixel in an image to a specific semantic category 24 , 25 . Unlike ordinary image segmentation, semantic segmentation does not just divide the image into different areas, but requires the classification of each pixel so that each pixel can be assigned a specific semantic label, such as people, cars, roads, trees, etc. This fine pixel-level classification can provide a richer and more detailed understanding of images, providing an important foundation for many computer vision tasks 26 , 27 .
DeepLabV3+, UNet, FCN, and PSPNet are all commonly used semantic segmentation models with some differences in network structure and performance. Using encoder-decoder structure, UNet network can effectively extract image features and restore image resolution, but the model parameters are too large, the training and reasoning speed is slow, and the semantic segmentation effect is not ideal for some complex scenes. FCN network uses the full convolutional network structure to classify the entire image at the pixel level. Because it does not consider the fusion of multi-scale features and the use of context information, the semantic segmentation effect is not ideal for some complex scenes, and the detection effect is not ideal for some small targets. PSPNet network adopts pyramid pool module, which can capture features of different scales and improve the model's receptor field and context information. Because the fusion of multi-scale features is not considered, the semantic segmentation effect in some complex scenes is not ideal, and the detection effect in some small targets is not ideal. DeepLabV3+ uses hollow convolution and multi-scale feature fusion, which can effectively improve the accuracy and robustness of semantic segmentation. ASPP module can capture features of different scales and improve the receptive field and context information of the model. At the same time, DeepLabV3+ can be equipped with lightweight backbone network MobileNetv2, which has high detection accuracy and speed. The experimental results show that the detection accuracy can reach more than 88% and the detection speed can reach 89FPS, which fully meets the real-time requirements of ROV underwater detection.
The DeepLabv3+ model reduces the size and calculation amount of the model while maintaining high accuracy, so that it is more suitable for deployment and application on underwater vehicles. Figure 6 shows the binocular camera of the underwater robot photographing the steel pipe target in the laboratory environment.

Underwater robot.
The image after semantic segmentation can generally be visualized in three ways, as shown in b, c and d in Figure 7 . The steel pipe in Figure 7 a is the underwater detection target simulated by us; Figure 7 b is a mixed image of segmentation target and image background. The background of the mixed image is dark, and all segmentation targets are marked in red 28 , 29 . In Figure 7 c, the background is deleted and only the segmented target is retained. All the steel pipe parts are marked in red. Figure 7 d is the object map with the background removed and only the segmented object retained. Complex images may require more computing resources, resulting in slower operations. Figure 7 c and Figure 7 d are deducted from the background, the use of images is more concise, the contrast is better, saving computing resources, improve the stereo matching speed.

Semantic segmentation of visual images, ( a ) Original drawing, ( b ) Hybrid graph, ( c ), Spanning graph, ( d ) Object map.
In binocular vision, stereo matching is the process of finding the corresponding points in the images of the left and right cameras. The traditional stereo matching algorithm will search the whole image range, which is computationally heavy and easy to be disturbed by background noise. However, after using semantic segmentation, pixel matching only needs to be limited to the segmentation Region, that is, focusing on region ROI (Region of Interest), and the parallax search range is only within ROI when calculating the global energy function. The algorithm only calculates and matches parallax in this region, thus reducing the computation and improving the processing efficiency. That Narrows the search area considerably. As can be seen from Figure 7 d, the target map of the semantic segmentation image only contains the outline of the pile leg, and the background information is removed. Only the pixels on the pile leg need to be considered during matching, thus reducing the matching search range and improving the matching speed. Although Figure 7 c only shows the pile leg region, all of them are marked in red, resulting in the same features of all pixels in the pile leg, without any difference, and the pixel blocks cannot be correctly matched, resulting in large measurement errors, so they cannot be used.
It is assumed that the semantic segmentation images captured by the left camera and the right camera are L and R respectively, the corresponding pixels are \((x_{l} ,y)\) and \((x_{r} ,y)\) , and the parallax is d. The width of the entire image is W, the number of pixels on the pile leg is N, the time to match each pixel is \(t_{m}\) , and the time to match the entire pile leg can be expressed as:
In the case of the original image, all pixels of the entire image need to be matched, and the matching time can be expressed as:
The proportion of semantic segmentation image matching time to original image matching time is:
By removing the background and keeping only the target object, the matching time will be greatly reduced. Taking Figure 7 as an example, the matching time of the original image is only about 1/7.
Binocular ranging experiment
Binocular ranging experiment environment and hardware used in the experiment: desktop computer and underwater high-definition binocular camera are shown in Figure 8 . The desktop computer configuration is as follows: CPU is Intel i7, memory is 32GB, GPU is NVIDIA GeForce RTX 3070; Underwater binocular camera configuration: underwater high-definition binocular camera, image resolution 1920×960, baseline length 60mm. The software environment is windows 10, Matlab 2021b, OpenCV.

Underwater HD binocular camera.
The target ranging process based on binocular vision is shown in Figure 9 . Firstly, matlab toolbox is used to calibrate the left and right cameras, and the left and right checkerboard images are imported to carry out single target calibration and binocular calibration respectively, and the internal and external parameters of binocular cameras are obtained. After that, the Deeplabv3+ model is semantically segmpled to the images captured by the binocular camera, and the generated map with the background removed is obtained 30 . Finally, the two eyes of the image generated by semantic segmentation are corrected, and three-dimensional matching is carried out by SGBM method. A point is selected on the simulated pile leg, and the distance between the ROV and the selected point of the target object is measured.

Flow chart of target ranging based on binocular vision.
Calibration and alignment of binocular cameras
In this paper, Zhang Zhengyou calibration method is used to calibrate binocular cameras 31 . First, an 8 ×11 checkerboard calibration board image was made, the size of each square was 22mm×22mm, and it was fixed on the cardboard. Open the binocular camera, and capture 23 sets of checkerboard images at different angles in the air and water tank by constantly moving the calibration plate, Then the camera is calibrated by calculating and analyzing the corners of the checkerboard (solving the internal and external parameters of the camera).as shown in Fig. 10 .

Image calibration, ( a ) Airborne calibration ( b ) Underwater calibration.
In Matlab, 20 groups of calibration images are read in turn, the corner of each calibration image is accurately extracted clockwise from the upper left corner of the calibration image, and the parameters of the monomer camera are obtained, and the corner error distribution Fig. 11 a and the 3D view of the position of a single camera and the calibration board Fig. 11 b are obtained. It can be seen that most corner points are distributed between [-0.4,0.4], with dense distribution and high precision 32 .

Single objective rendering, ( a ) Corner error distribution diagram ( b ) Single camera with calibration board position 3D view.
The calibration parameters of the left and right monocular cameras were input into Matlab, and the binocular cameras were continued to be calibrated. The calibration parameters of the binocular camera in air and binocular camera in water were obtained respectively, as shown in Table 1 and Table 2 . The air and underwater camera parameter data in Table 1 and Table 2 were compared and analyzed. The actual baseline of the camera was 60mm, the underwater calibration baseline was 58.6325mm, and the air calibration baseline was 59.2756mm, all of which were within the acceptable range. The fx and fy of the left camera are 852.875 and 851.195 in water, which are quite different from the calibration results in air. According to the above analysis, the focal length of the camera in water is about 1.33 times that in air under certain circumstances, and the experimental data,852.8751/634.1084=1.344 and 851.193/631.9197 =1.346, are all about 1.33, thus verifying the correctness of the above analysis. By comparing the distortion coefficient of the camera, it can be seen that the distortion coefficient of the underwater camera is greater than that of the air, which is also in line with the above analysis of the influence of underwater refraction on camera distortion.
After the camera calibration is completed, the OpenCV computer vision library is used to perform binocular alignment. The comparison between the effect before and after correction is shown in Figure 12 .

Before and after binocular correction. ( a ) Binocular vision image before correction ( b ) binocular vision image after correction.
Binocular ranging
Under the condition that the camera position is fixed, a steel pipe is placed in front of the binational camera of the underwater robot, and images are taken at different distances in order in both air and underwater environments. The Deeplabv3+ model is used to conduct semantic segmentation of the above images, and the hybrid image of target and background recognition and the generated image of target recognition are generated respectively. Only the object map that identifies the object and removes the background. SGBM algorithm is used to carry out distance measurement experiments on the same pixel coordinates of the above three semantic segmentation maps and the original images, and finally the distance information of the target is obtained by using the binocular distance measurement formula. The actual effect of target distance measurement based on binocular vision and semantic segmentation is shown in Figure 13 , showing the distance measurement effect of 0.27m and 0.87m.The image in the first row of the same measured distance in Figure 13 is the stereo matching original. The image in the second row is the parallax map generated after stereo matching. In the left and right binocular images, parallax refers to the horizontal distance between the center pixels of the two matching blocks, which reflects the depth information of the object in three-dimensional space. Each pixel value represents the parallax size of the corresponding point. The magnitude of the parallax is inversely proportional to the distance of the object from the camera. That is, the larger the parallax value, the closer the object is to the camera. In a parallax chart, different colors represent different parallax values. The image in the third row is the calculated distance value for each pixel.

Comparison of binocular ranging effect of different semantic segmentation graphs.
The measurement results of different distances and images in the air are shown in Table 3 , and the measurement results of different distances and images under water are shown in Table 4 .
As can be seen from the binocular ranging data in Table 3 and Table 4 above, the distance information calculated by SGBM stereoscopic matching has relatively small error with the real distance during short-range ranging, and has high accuracy. In the long distance distance, the error is relatively large, the accuracy becomes low. The reason for this phenomenon is that when the target is relatively close to the camera, the target has more effective pixels in the imaging plane, and these pixels will be simpler and more accurate to find the best matching point, so the accuracy of the ranging is higher; However, when the target is farther and farther from the camera, the effective pixels of the target in the imaging plane become less, the matching difficulty increases, and the matching error becomes larger, so the accuracy of the ranging is correspondingly lower. The greater the actual distance, the greater the relative error.
Since the pixels of target recognition are all changed to red in the mixed map and the generated map, the target area is exactly the same without difference, and the target recognition area is all the same and can be matched, resulting in calculation errors, which should not be used in actual distance measurement. The ranging results of the target map and the original map are exactly the same. The mixed map and the generated map change the recognition area of the target uniformly to red, resulting in the disappearance of the image features of the underwater pile leg, which can not be accurately matched in stereo, and thus cause a large error in the ranging results. The stereo matching effect between the target image and the original image is the best, and the error is small. The mixed image and the original image have high complexity, long stereo matching time, and the ranging time is 0.1s/ time. The generated image and the target image reduce the complexity of the image and improve the stereo matching speed because the background is removed. The ranging time is 0.07s/ time, and the ranging speed is increased by 30%. Therefore, using the generated target map to measure the distance after the underwater object is identified not only improves the measurement speed, but also ensures that the measurement accuracy is not reduced.
The influence of underwater environment on binocular rangingg
In the real underwater environment, binocular vision ranging will be affected by many factors such as illumination and environmental scattering. Such as suspended particles and water molecules. These scattering media will cause the light to scatter during the propagation process, making the image blurred and distorted. As shown in Figure 14 , the scattering phenomenon of Image1 and Image2 is serious, resulting in blurred images, and the recognition accuracy of Deeplabv3+ is also decreased. There is a large gap in the recognition area of Image1, and the segmentation of the right edge line of the target object in Image2 is not smooth, thus increasing the error and uncertainty of ranging. The binocular vision system may not be able to accurately match the corresponding pixels, thus affecting the accuracy of the ranging results. Image3 is an enhanced image of Image2, and its right edge line segmentation effect is better than Image2, and the right edge line is smoother.

Influence of underwater environment on target recognition results. ( a ) Picture name ( b ) Underwater target map ( c ) Underwater target identification map.
Table 5 shows the influence of different underwater environments on binocular ranging results. Clear underwater images are superior to fuzzy underwater images in both accuracy and speed. The weakening of underwater light intensity and scattering phenomenon make the edges and details of objects blurred, and the number of pixels occupied by the target in the image will be reduced, resulting in a decrease in pixel density. Lower pixel densities can result in more difficulty in accurately extracting and matching target features, reducing the accuracy of ranging. If the image is blurred, the system needs to spend more time to search and match the corresponding feature points, which will increase the time of stereo matching and reduce the measurement speed. In addition, the instability of underwater illumination direction may also lead to misjudgment of binocular vision system, which further affects the accuracy of ranging.
The advantages of using segmentation image to calculate parallax compared with using original image are mainly reflected in the following aspects:
(1) Improve the accuracy of the calculation: the segmentation image can limit the scope of the calculation parallax to the target object, avoiding background interference, thus improving the accuracy of the calculation.
(2) Improve computing efficiency: Segmentation of images can reduce the number of pixels to calculate parallax, thus improving the efficiency of calculation.
(3) Enhance the understanding of the target object: segmented images can provide the semantic information of the target object, which is conducive to the understanding and analysis of the target object.
In general, the calculation of parallax using segmentation image can improve the accuracy and efficiency of the calculation and enhance the understanding of the target object compared with the calculation of parallax using ordinary image.
Conclusions
Aiming at the technical requirements of target detection and target ranging in underwater vehicle operation, this paper designs a set of underwater vehicle target ranging system based on Deeplabv3+ semantic segmentation and binocular vision. The system uses Zhang Zhengyou calibration method to calibrate the binocular camera, and uses SGBM algorithm to carry out stereoscopic matching of binocular images and measure the distance. Through ranging experiments in air and water, the target object is less than 1m, and the measurement error is less than 5%. However, due to the scattering and refraction of light in the underwater environment, interference factors in the imaging plane will increase with the increase of distance. The difficulty of binocular stereo matching is increased, the matching accuracy is reduced, and the measurement error is increased correspondingly. At the same time, it is also verified that the accuracy of the measurement is unchanged and the measurement speed is increased by nearly 30% by using the target map after semantic segmentation.
Data availability
All data generated or analysed during this study are included in this published article.
Chen, M. K., Liu, X., Sun, Y. & Tsai, D. P. Artificial Intelligence in Meta-optics. Chem. Rev. 122 (19), 15356–15413 (2022).
Article CAS PubMed PubMed Central Google Scholar
Liu, X. et al. Meta-Lens Particle Image Velocimetry. Adv. Mater. 36 , 2310134 (2023).
Article Google Scholar
Zhang,R. Design of recognition and ranging system based on binocular vision. Wireless Internet Technology, China, 40–43, 2023.
Xie,Q. Development of obstacle avoidance system of underwater robot based on binocular stereo vision technology. China, Master’s thesis. 2022.
Xu,s.Binocular visual positioning of autonomous recovery of intelligent underwater robot.Journal of Harbin Engineering University.China.2022,43,8.
Liu, X. et al. Underwater binocular meta-lens. ACS Photonics 10 , 2382–2389 (2023).
Article CAS Google Scholar
Liu X,Li W, Yamaguchi T,Geng Z,Tanaka T, Tsai D P, Chen M K. Stereo Vision Meta-Lens-Assisted Driving Vision. ACS Photonics 2024, first online.
Han, D. Y., Wang, Z. M., Song, Y. C., Zhao, J. F. & Wang, D. Y. Numerical analysis of depressurization production of natural gas hydrate from different lithology oceanic reservoirs with isotropic and anisotropic permeability. J. Nat. Gas. Sci. Eng. 46 , 575–591 (2017).
Sels, S., Ribbens, B., Vanlanduit, S. & Penne, R. Camera Calibration Using Gray Code. Sensors 19 , 246 (2019).
Article ADS PubMed PubMed Central Google Scholar
Chen, B. & Pan, B. Camera calibration using synthetic random speckle pattern and digital image correlation. Opt. Lasers Eng. 126 , 105919 (2020).
Guan, J. et al. Extrinsic calibration of camera networks using a sphere. Sensors 15 , 18985–19005 (2015).
Poulin-Girard, A. S., Thibault, S. & Laurendeau, D. Influence of camera calibration conditions on the accuracy of 3D reconstruction. Opt. Express 24 , 2678–2686 (2016).
Article ADS PubMed Google Scholar
Chen, X. et al. Camera calibration with global LBP-coded phase-shifting wedge grating arrays. Opt. Lasers Eng. 136 , 106314 (2021).
Abdel-Aziz, Y. I. & Karara, H. M. Direct Linear Transformation from Comparator Coordinates into Object Space Coordinates in Close-Range Photogrammetry. Photogramm. Eng. Remote Sens. 81 , 103–107 (2015).
Tsai, R. A versatile camera calibration technique for high-accuracy 3D machine vision metrology using off-the-shelf TV cameras and lenses. IEEE J. Robot. Autom. 3 , 323–344 (1987).
Shi, Z. C., Shang, Y., Zhang, X. F. & Wang, G. DLT-Lines based camera calibration with lens radial and tangential distortion. Exp. Mech. 61 , 1237–1247 (2021).
Zhang, J., Duan, F. & Ye, S. An easy accurate calibration technique for camera. Chin. J. Sci. 20 , 193–196 (1999).
CAS Google Scholar
Zheng, H. et al. A non-coplanar high-precision calibration method for cameras based on affine coordinate correction model. Meas. Sci. Technol. 34 , 095018 (2023).
Article ADS Google Scholar
Wei Jingyang. Underwater high-precision 3D Reconstruction Method based on Binocular stereo vision [D]. Harbin Inst. Technol. 20–30 (2017).
Weimin, Y., Guangxi, Y. & Shuang, S. Application of camera calibration technology in oilfield monitoring equipment [J]. Inform. Syst. Eng. 05 , 90–91 (2020).
Google Scholar
Yangyang, L. Research on Binocular Vision Target Detection and Ranging Method of UAV [D] (Chongqing University, 2019).
Peng, D., Feng, Z., Zhao, Y. W., Mi, Z. & Xianping, Fu. Automatic size measurement method of underwater sea cucumber based on binocular vision [J]. Comput. Eng. Appl. 57 , 271–278 (2021).
Li Ke, Wu. & Tao, L. Q. Human contour extraction based on depth map and improved canny algorithm. Comput. Technol. Dev. 31 (05), 67–72 (2021).
Mingji, W., Qiumeng, C. & Fushen, R. Target distance measurement system based on binocular vision. Autom. Instrument. 7 , 5–8. https://doi.org/10.14016/j.carolcarrollnki.1001-9227,2022.07.005 (2022).
Minaee, S. et al. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 44 , 3523–3542 (2022).
PubMed Google Scholar
Chen, L.-C. et al. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Computer Vision (eds Ferrari, V. et al. ) (Springer International Publishing, 2018).
Panboonyuen, T., Jitkajornwanich, K., Lawawirojwong, S., Srestasathiern, P. & Vateekul, P. Semantic segmentation on remotely sensed images using an enhanced global convolutional network with channel attention and domain specific transfer learning. Remote Sens. 11 , 83 (2019).
Guo, Y., Liu, Y., Georgiou, T. & Lew, M. S. A Review of Semantic Segmentation Using Deep Neural Networks. Int. J. Multimed. Inf. Retr. 7 , 87–93 (2018).
Rong, D., Rao, X. & Ying, Y. Computer vision detection of surface Defecton oranges by means of a sliding comparison window local segmentation algorithm. Comput. Electron. Agric. 137 , 59–68 (2017).
Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015 (IEEE, Piscataway, NJ, USA, 2015).
Zhang Zhengyou. Flexible and Novel camera calibration Technology [R]. Institute of Computing Technology, Chinese Academy of Sciences, (1998).
Zhuang Sufeng, Tu., Dawei, Z. X. & Qinzhou, Y. Binocular stereo vision underwater corresponding points matching and 3 d reconstruction method research. J. Instrum. Meters https://doi.org/10.19650/j.carolcarrollnkicjsi.J2209215 (2022).
Download references
This research was funded by Supported by the specific research fund of The Innovation Platform for Academicians of Hainan Province (YSPTZX202301), High-tech project of Hainan Province-Intelligent ROV R&D and application technology of integrated inspection operation (ZDYF2023GXJS004), Scientific Research and Technology Development Project of China National Petroleum Corporation Limited—Research on Development of Intelligent ROV System and Supporting Technology of Jacket Operation (2021DJ2504).
Author information
Authors and affiliations.
Sanya Offshore Oil and Gas Research Institute, Northeast Petroleum University, Sanya, 572025, China
Qing Hu, Fushen Ren & Zhongyang Wang
CNPC Engineering Technology Research Company Limited, Tianjin, 300451, China
Kekuan Wang
You can also search for this author in PubMed Google Scholar
Contributions
Conceptualization, F.R. ; methodology, F.R.; software Q.H.; validation, Q.H. ; formal analysis, Q.H.; investigation, Q.H.; resources,F.R.; data curation, F.R.; writing—original draft preparation, K.W.; writing—review and editing, K.W.; visualization, K.W..; supervision, Z.W.; project administration,Z.W.; funding acquisition, Z.W. All authors have read and agreed to the published version of the manuscript.
Corresponding authors
Correspondence to Qing Hu or Zhongyang Wang .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Hu, Q., Wang, K., Ren, F. et al. Research on underwater robot ranging technology based on semantic segmentation and binocular vision. Sci Rep 14 , 12309 (2024). https://doi.org/10.1038/s41598-024-63017-8
Download citation
Received : 25 November 2023
Accepted : 23 May 2024
Published : 29 May 2024
DOI : https://doi.org/10.1038/s41598-024-63017-8
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Underwater robot
- Binocular vision
- Semantic segmentation
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: AI and Robotics newsletter — what matters in AI and robotics research, free to your inbox weekly.

IMAGES
VIDEO
COMMENTS
Key Takeaways. Because research generates further research, the conclusions you draw from your research are important. To test the validity of your conclusions, you will have to review both the content of your paper and the way in which you arrived at the content. Mailing Address: 3501 University Blvd. East, Adelphi, MD 20783.
Table of contents. Step 1: Restate the problem. Step 2: Sum up the paper. Step 3: Discuss the implications. Research paper conclusion examples. Frequently asked questions about research paper conclusions.
For this reason you need to support your conclusions with structured, logical reasoning. Having drawn your conclusions you can then make recommendations. These should flow from your conclusions. They are suggestions about action that might be taken by people or organizations in the light of the conclusions that you have drawn from the results ...
The conclusion is intended to help the reader understand why your research should matter to them after they have finished reading the paper. A conclusion is not merely a summary of the main topics covered or a re-statement of your research problem, but a synthesis of key points derived from the findings of your study and, if applicable, where you recommend new areas for future research.
The conclusion in a research paper is the final section, where you need to summarize your research, presenting the key findings and insights derived from your study. Check out this article on how to write a conclusion for a research paper, with examples. ... If you are drawing a direct quote or paraphrasing a specific source in your research ...
A research paper conclusion is the final section of a research paper that summarizes the key findings, significance, and implications of the research. It is the writer's opportunity to synthesize the information presented in the paper, draw conclusions, and make recommendations for future research or actions.
Begin with a clear statement of the principal findings. This will reinforce the main take-away for the reader and set up the rest of the discussion. Explain why the outcomes of your study are important to the reader. Discuss the implications of your findings realistically based on previous literature, highlighting both the strengths and ...
The study reviewed coffee habits of more than 402,000 people ages 50 to 71 from six states and two metropolitan areas. Those with cancer, heart disease, and stroke were excluded at the start of the study. Coffee consumption was assessed once at the start of the study. About 52,000 people died during the course of the study.
Drawing conclusions is a defining moment in psychological research. It's the culmination of a complex process that starts with a question and, through careful design and analysis, ends with insights that can deepen our understanding of the human mind and behavior.
As you'll learn in a moment, it encompasses a wide variety of techniques, so there isn't one single definition. 1. Deduction. Common in: philosophy, mathematics. Structure: If X, then Y, due to the definitions of X and Y. X applies to this case. Therefore Y applies to this case.
Drawing Conclusions. Since statistics are probabilistic in nature and findings can reflect type I or type II errors, we cannot use the results of a single study to conclude with certainty that a theory is true. Rather theories are supported, refuted, or modified based on the results of research.
Table 15.6.a shows how review authors may be aided in their interpretation of the body of evidence and drawing conclusions about future research and practice. Table 15.6.a Implications for research and practice suggested by individual GRADE domains. Domain. Implications for research.
Key Points. Analysis of data is a process of inspecting, cleaning, transforming, and modeling data with the goal of highlighting useful information, suggesting conclusions, and supporting decision making. Data analysis is a process, within which several phases can be distinguished. One way in which analysis can vary is by the nature of the data.
Drawing Conclusions. Since statistics are probabilistic in nature and findings can reflect type I or type II errors, we cannot use the results of a single study to conclude with certainty that a theory is true. Rather theories are supported, refuted, or modified based on the results of research. If the results are statistically significant and ...
Drawing Conclusions. For any research project and any scientific discipline, drawing conclusions is the final, and most important, part of the process. Whichever reasoning processes and research methods were used, the final conclusion is critical, determining success or failure. If an otherwise excellent experiment is summarized by a weak ...
Writing a Conclusion. A conclusion is an important part of the paper; it provides closure for the reader while reminding the reader of the contents and importance of the paper. It accomplishes this by stepping back from the specifics in order to view the bigger picture of the document. In other words, it is reminding the reader of the main ...
Drawing Conclusions. Since statistics are probabilistic in nature and findings can reflect type I or type II errors, we cannot use the results of a single study to conclude with certainty that a theory is true. Rather theories are supported, refuted, or modified based on the results of research.
Statistical thinking involves the careful design of a study to collect meaningful data to answer a focused research question, detailed analysis of patterns in the data, and drawing conclusions that go beyond the observed data. Random sampling is paramount to generalizing results from our sample to a larger population, and random assignment is ...
One of the most critical parts of the research is to be able to analyze, apply and draw conclusions from the information and then ultimately make the best recommendations. This is the ability to ...
Drawing conclusions is the final step in any research or any scientific investigation. We can define the drawing of a conclusion as the insight gained from experimenting. All that is learned during an investigation can be summarised in a concluding statement.
Strategies. Put it in your own words: Often you will be asked to draw a conclusion from a specific idea contained in the passage. It can be helpful to sum up the idea in your own words before considering the choices. Use process of elimination to get rid of conclusions that can't be supported, until you find one that is.
The ability to draw conclusions is an important skill in academic arenas and life. People draw conclusions based on what they see, hear, and read every day. A teenager who stomps to her bedroom ...
Draw your own conclusions on Trump. Most of us will never be a juror in a criminal court, but like it or not we are all in the court of public opinion.
Jasmina Wiemann, a paleobiologist at the Field Museum of Natural History who was not involved in the new research, published a study in 2022 that came to a different conclusion: Based on oxygen ...
US News is a recognized leader in college, grad school, hospital, mutual fund, and car rankings. Track elected officials, research health conditions, and find news you can use in politics ...
NEW YORK -- For those in the business of evaluating professional baseball teams, Memorial Day tends to be the first notable inflection point from which to draw conclusions. April doesn't provide a large enough sample size. April and May combined offer a more comprehensive look. One day after the unofficial
We share research, data and resources and regularly engage regional leaders and policymakers to understand and address community‑specific economic issues. Small Town & Rural Initiative; ... Conclusion. While our analysis is suggestive, there are a few limitations. Foremost, our effective sample size was small, meaning some of these results ...
BACKGROUND: Chronically elevated neurohumoral drive, and particularly elevated adrenergic tone leading to β-adrenergic receptor (β-AR) overstimulation in cardiac myocytes, is a key mechanism involved in the progression of heart failure. β1-AR (β1-adrenergic receptor) and β2-ARs (β2-adrenergic receptor) are the 2 major subtypes of β-ARs present in the human heart; however, they elicit ...
Students and a staff member from University of Central Arkansas presented original research that spanned K-12 education, corruption, occupational licensing, and health economics within the state of Arkansas. This state-relevant research remains important in shaping public policy and promoting open discussion around certain issues.
Based on the principle of light refraction and binocular ranging, the underwater imaging model is obtained. It provides a theoretical basis for underwater camera calibration. In order to meet the ...