Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- Qualitative vs. Quantitative Research | Differences, Examples & Methods

Qualitative vs. Quantitative Research | Differences, Examples & Methods
Published on April 12, 2019 by Raimo Streefkerk . Revised on June 22, 2023.
When collecting and analyzing data, quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings. Both are important for gaining different kinds of knowledge.
Common quantitative methods include experiments, observations recorded as numbers, and surveys with closed-ended questions.
Quantitative research is at risk for research biases including information bias , omitted variable bias , sampling bias , or selection bias . Qualitative research Qualitative research is expressed in words . It is used to understand concepts, thoughts or experiences. This type of research enables you to gather in-depth insights on topics that are not well understood.
Common qualitative methods include interviews with open-ended questions, observations described in words, and literature reviews that explore concepts and theories.
Table of contents
The differences between quantitative and qualitative research, data collection methods, when to use qualitative vs. quantitative research, how to analyze qualitative and quantitative data, other interesting articles, frequently asked questions about qualitative and quantitative research.
Quantitative and qualitative research use different research methods to collect and analyze data, and they allow you to answer different kinds of research questions.

Quantitative and qualitative data can be collected using various methods. It is important to use a data collection method that will help answer your research question(s).
Many data collection methods can be either qualitative or quantitative. For example, in surveys, observational studies or case studies , your data can be represented as numbers (e.g., using rating scales or counting frequencies) or as words (e.g., with open-ended questions or descriptions of what you observe).
However, some methods are more commonly used in one type or the other.
Quantitative data collection methods
- Surveys : List of closed or multiple choice questions that is distributed to a sample (online, in person, or over the phone).
- Experiments : Situation in which different types of variables are controlled and manipulated to establish cause-and-effect relationships.
- Observations : Observing subjects in a natural environment where variables can’t be controlled.
Qualitative data collection methods
- Interviews : Asking open-ended questions verbally to respondents.
- Focus groups : Discussion among a group of people about a topic to gather opinions that can be used for further research.
- Ethnography : Participating in a community or organization for an extended period of time to closely observe culture and behavior.
- Literature review : Survey of published works by other authors.
A rule of thumb for deciding whether to use qualitative or quantitative data is:
- Use quantitative research if you want to confirm or test something (a theory or hypothesis )
- Use qualitative research if you want to understand something (concepts, thoughts, experiences)
For most research topics you can choose a qualitative, quantitative or mixed methods approach . Which type you choose depends on, among other things, whether you’re taking an inductive vs. deductive research approach ; your research question(s) ; whether you’re doing experimental , correlational , or descriptive research ; and practical considerations such as time, money, availability of data, and access to respondents.
Quantitative research approach
You survey 300 students at your university and ask them questions such as: “on a scale from 1-5, how satisfied are your with your professors?”
You can perform statistical analysis on the data and draw conclusions such as: “on average students rated their professors 4.4”.
Qualitative research approach
You conduct in-depth interviews with 15 students and ask them open-ended questions such as: “How satisfied are you with your studies?”, “What is the most positive aspect of your study program?” and “What can be done to improve the study program?”
Based on the answers you get you can ask follow-up questions to clarify things. You transcribe all interviews using transcription software and try to find commonalities and patterns.
Mixed methods approach
You conduct interviews to find out how satisfied students are with their studies. Through open-ended questions you learn things you never thought about before and gain new insights. Later, you use a survey to test these insights on a larger scale.
It’s also possible to start with a survey to find out the overall trends, followed by interviews to better understand the reasons behind the trends.
Qualitative or quantitative data by itself can’t prove or demonstrate anything, but has to be analyzed to show its meaning in relation to the research questions. The method of analysis differs for each type of data.
Analyzing quantitative data
Quantitative data is based on numbers. Simple math or more advanced statistical analysis is used to discover commonalities or patterns in the data. The results are often reported in graphs and tables.
Applications such as Excel, SPSS, or R can be used to calculate things like:
- Average scores ( means )
- The number of times a particular answer was given
- The correlation or causation between two or more variables
- The reliability and validity of the results
Analyzing qualitative data
Qualitative data is more difficult to analyze than quantitative data. It consists of text, images or videos instead of numbers.
Some common approaches to analyzing qualitative data include:
- Qualitative content analysis : Tracking the occurrence, position and meaning of words or phrases
- Thematic analysis : Closely examining the data to identify the main themes and patterns
- Discourse analysis : Studying how communication works in social contexts
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Chi square goodness of fit test
- Degrees of freedom
- Null hypothesis
- Discourse analysis
- Control groups
- Mixed methods research
- Non-probability sampling
- Quantitative research
- Inclusion and exclusion criteria
Research bias
- Rosenthal effect
- Implicit bias
- Cognitive bias
- Selection bias
- Negativity bias
- Status quo bias
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to systematically measure variables and test hypotheses . Qualitative methods allow you to explore concepts and experiences in more detail.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
The research methods you use depend on the type of data you need to answer your research question .
- If you want to measure something or test a hypothesis , use quantitative methods . If you want to explore ideas, thoughts and meanings, use qualitative methods .
- If you want to analyze a large amount of readily-available data, use secondary data. If you want data specific to your purposes with control over how it is generated, collect primary data.
- If you want to establish cause-and-effect relationships between variables , use experimental methods. If you want to understand the characteristics of a research subject, use descriptive methods.
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organizations.
There are various approaches to qualitative data analysis , but they all share five steps in common:
- Prepare and organize your data.
- Review and explore your data.
- Develop a data coding system.
- Assign codes to the data.
- Identify recurring themes.
The specifics of each step depend on the focus of the analysis. Some common approaches include textual analysis , thematic analysis , and discourse analysis .
A research project is an academic, scientific, or professional undertaking to answer a research question . Research projects can take many forms, such as qualitative or quantitative , descriptive , longitudinal , experimental , or correlational . What kind of research approach you choose will depend on your topic.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Streefkerk, R. (2023, June 22). Qualitative vs. Quantitative Research | Differences, Examples & Methods. Scribbr. Retrieved June 28, 2024, from https://www.scribbr.com/methodology/qualitative-quantitative-research/
Is this article helpful?

Raimo Streefkerk
Other students also liked, what is quantitative research | definition, uses & methods, what is qualitative research | methods & examples, mixed methods research | definition, guide & examples, get unlimited documents corrected.
✔ Free APA citation check included ✔ Unlimited document corrections ✔ Specialized in correcting academic texts
- - Google Chrome
Intended for healthcare professionals
- My email alerts
- BMA member login
- Username * Password * Forgot your log in details? Need to activate BMA Member Log In Log in via OpenAthens Log in via your institution
Search form
- Advanced search
- Search responses
- Search blogs
- Three techniques for...
Three techniques for integrating data in mixed methods studies
- Related content
- Peer review
- Alicia O’Cathain , professor 1 ,
- Elizabeth Murphy , professor 2 ,
- Jon Nicholl , professor 1
- 1 Medical Care Research Unit, School of Health and Related Research, University of Sheffield, Sheffield S1 4DA, UK
- 2 University of Leicester, Leicester, UK
- Correspondence to: A O’Cathain a.ocathain{at}sheffield.ac.uk
- Accepted 8 June 2010
Techniques designed to combine the results of qualitative and quantitative studies can provide researchers with more knowledge than separate analysis
Health researchers are increasingly using designs that combine qualitative and quantitative methods, and this is often called mixed methods research. 1 Integration—the interaction or conversation between the qualitative and quantitative components of a study—is an important aspect of mixed methods research, and, indeed, is essential to some definitions. 2 Recent empirical studies of mixed methods research in health show, however, a lack of integration between components, 3 4 which limits the amount of knowledge that these types of studies generate. Without integration, the knowledge yield is equivalent to that from a qualitative study and a quantitative study undertaken independently, rather than achieving a “whole greater than the sum of the parts.” 5
Barriers to integration have been identified in both health and social research. 6 7 One barrier is the absence of formal education in mixed methods research. Fortunately, literature is rapidly expanding to fill this educational gap, including descriptions of how to integrate data and findings from qualitative and quantitative methods. 8 9 In this article we outline three techniques that may help health researchers to integrate data or findings in their mixed methods studies and show how these might enhance knowledge generated from this approach.
Triangulation protocol
Researchers will often use qualitative and quantitative methods to examine different aspects of an overall research question. For example, they might use a randomised controlled trial to assess the effectiveness of a healthcare intervention and semistructured interviews with patients and health professionals to consider the way in which the intervention was used in the real world. Alternatively, they might use a survey of service users to measure satisfaction with a service and focus groups to explore views of care in more depth. Data are collected and analysed separately for each component to produce two sets of findings. Researchers will then attempt to combine these findings, sometimes calling this process triangulation. The term triangulation can be confusing because it has two meanings. 10 It can be used to describe corroboration between two sets of findings or to describe a process of studying a problem using different methods to gain a more complete picture. The latter meaning is commonly used in mixed methods research and is the meaning used here.
The process of triangulating findings from different methods takes place at the interpretation stage of a study when both data sets have been analysed separately (figure ⇓ ). Several techniques have been described for triangulating findings. They require researchers to list the findings from each component of a study on the same page and consider where findings from each method agree (convergence), offer complementary information on the same issue (complementarity), or appear to contradict each other (discrepancy or dissonance). 11 12 13 Explicitly looking for disagreements between findings from different methods is an important part of this process. Disagreement is not a sign that something is wrong with a study. Exploration of any apparent “inter-method discrepancy” may lead to a better understanding of the research question, 14 and a range of approaches have been used within health services research to explore inter-method discrepancy. 15
Point of application for three techniques for integrating data in mixed methods research
- Download figure
- Open in new tab
- Download powerpoint
The most detailed description of how to carry out triangulation is the triangulation protocol, 11 which although developed for multiple qualitative methods, is relevant to mixed methods studies. This technique involves producing a “convergence coding matrix” to display findings emerging from each component of a study on the same page. This is followed by consideration of where there is agreement, partial agreement, silence, or dissonance between findings from different components. This technique for triangulation is the only one to include silence—where a theme or finding arises from one data set and not another. Silence might be expected because of the strengths of different methods to examine different aspects of a phenomenon, but surprise silences might also arise that help to increase understanding or lead to further investigations.
The triangulation protocol moves researchers from thinking about the findings related to each method, to what Farmer and colleagues call meta-themes that cut across the findings from different methods. 11 They show a worked example of triangulation protocol, but we could find no other published example. However, similar principles were used in an iterative mixed methods study to understand patient and carer satisfaction with a new primary angioplasty service. 16 Researchers conducted semistructured interviews with 16 users and carers to explore their experiences and views of the new service. These were used to develop a questionnaire for a survey of 595 patients (and 418 of their carers) receiving either the new service or usual care. Finally, 17 of the patients who expressed dissatisfaction with aftercare and rehabilitation were followed up to explore this further in semistructured interviews. A shift of thinking to meta-themes led the researchers away from reporting the findings from the interviews, survey, and follow-up interviews sequentially to consider the meta-themes of speed and efficiency, convenience of care, and discharge and after care. The survey identified that a higher percentage of carers of patients using the new service rated the convenience of visiting the hospital as poor than those using usual care. The interviews supported this concern about the new service, but also identified that the weight carers gave to this concern was low in the context of their family member’s life being saved.
Morgan describes this move as the “third effort” because it occurs after analysis of the qualitative and the quantitative components. 17 It requires time and energy that must be planned into the study timetable. It is also useful to consider who will carry out the integration process. Farmer and colleagues require two researchers to work together during triangulation, which can be particularly important in mixed methods studies if different researchers take responsibility for the qualitative and quantitative components. 11
Following a thread
Moran-Ellis and colleagues describe a different technique for integrating the findings from the qualitative and quantitative components of a study, called following a thread. 18 They state that this takes place at the analysis stage of the research process (figure ⇑ ). It begins with an initial analysis of each component to identify key themes and questions requiring further exploration. Then the researchers select a question or theme from one component and follow it across the other components—they call this the thread. The authors do not specify steps in this technique but offer a visual model for working between datasets. An approach similar to this has been undertaken in health services research, although the researchers did not label it as such, probably because the technique has not been used frequently in the literature (box)
An example of following a thread 19
Adamson and colleagues explored the effect of patient views on the appropriate use of services and help seeking using a survey of people registered at a general practice and semistructured interviews. The qualitative (22 interviews) and quantitative components (survey with 911 respondents) took place concurrently.
The researchers describe what they call an iterative or cyclical approach to analysis. Firstly, the preliminary findings from the interviews generated a hypothesis for testing in the survey data. A key theme from the interviews concerned the self rationing of services as a responsible way of using scarce health care. This theme was then explored in the survey data by testing the hypothesis that people’s views of the appropriate use of services would explain their help seeking behaviour. However, there was no support for this hypothesis in the quantitative analysis because the half of survey respondents who felt that health services were used inappropriately were as likely to report help seeking for a series of symptoms presented in standardised vignettes as were respondents who thought that services were not used inappropriately. The researchers then followed the thread back to the interview data to help interpret this finding.
After further analysis of the interview data the researchers understood that people considered the help seeking of other people to be inappropriate, rather than their own. They also noted that feeling anxious about symptoms was considered to be a good justification for seeking care. The researchers followed this thread back into the survey data and tested whether anxiety levels about the symptoms in the standardised vignettes predicted help seeking behaviour. This second hypothesis was supported by the survey data. Following a thread led the researchers to conclude that patients who seek health care for seemingly minor problems have exceeded their thresholds for the trade-off between not using services inappropriately and any anxiety caused by their symptoms.
Mixed methods matrix
A unique aspect of some mixed methods studies is the availability of both qualitative and quantitative data on the same cases. Data from the qualitative and quantitative components can be integrated at the analysis stage of a mixed methods study (figure ⇑ ). For example, in-depth interviews might be carried out with a sample of survey respondents, creating a subset of cases for which there is both a completed questionnaire and a transcript. Cases may be individuals, groups, organisations, or geographical areas. 9 All the data collected on a single case can be studied together, focusing attention on cases, rather than variables or themes, within a study. The data can be examined in detail for each case—for example, comparing people’s responses to a questionnaire with their interview transcript. Alternatively, data on each case can be summarised and displayed in a matrix 8 9 20 along the lines of Miles and Huberman’s meta-matrix. 21 Within a mixed methods matrix, the rows represent the cases for which there is both qualitative and quantitative data, and the columns display different data collected on each case. This allows researchers to pay attention to surprises and paradoxes between types of data on a single case and then look for patterns across all cases 20 in a qualitative cross case analysis. 21
We used a mixed methods matrix to study the relation between types of team working and the extent of integration in mixed methods studies in health services research (table ⇓ ). 22 Quantitative data were extracted from the proposals, reports, and peer reviewed publications of 75 mixed methods studies, and these were analysed to describe the proportion of studies with integrated outputs such as mixed methods journal articles. Two key variables in the quantitative component were whether the study was assessed as attempting to integrate qualitative or quantitative data or findings and the type of publications produced. We conducted qualitative interviews with 20 researchers who had worked on some of these studies to explore how mixed methods research was practised, including how the team worked together.
Example of a mixed methods matrix for a study exploring the relationship between types of teams and integration between qualitative and quantitative components of studies* 22
- View inline
The shared cases between the qualitative and quantitative components were 21 mixed methods studies (because one interviewee had worked on two studies in the quantitative component). A matrix was formed with each of the 21 studies as a row. The first column of the matrix contained the study identification, the second column indicated whether integration had occurred in that project, and the third column the score for integration of publications emerging from the study. The rows were then ordered to show the most integrated cases first. This ordering of rows helped us to see patterns across rows.
The next columns were themes from the qualitative interview with a researcher from that project. For example, the first theme was about the expertise in qualitative research within the team and whether the interviewee reported this as adequate for the study. The matrix was then used in the context of the qualitative analysis to explore the issues that affected integration. In particular, it helped to identify negative cases (when someone in the analysis doesn’t fit with the conclusions the analysis is coming to) within the qualitative analysis to facilitate understanding. Interviewees reported the need for experienced qualitative researchers on mixed methods studies to ensure that the qualitative component was published, yet two cases showed that this was neither necessary nor sufficient. This pushed us to explore other factors in a research team that helped generate outputs, and integrated outputs, from a mixed methods study.
Themes from a qualitative study can be summarised to the point where they are coded into quantitative data. In the matrix (table ⇑ ), the interviewee’s perception of the adequacy of qualitative expertise on the team could have been coded as adequate=1 or not=2. This is called “quantitising” of qualitative data 23 ; coded data can then be analysed with data from the quantitative component. This technique has been used to great effect in healthcare research to identify the discrepancy between health improvement assessed using quantitative measures and with in-depth interviews in a randomised controlled trial. 24
We have presented three techniques for integration in mixed methods research in the hope that they will inspire researchers to explore what can be learnt from bringing together data from the qualitative and quantitative components of their studies. Using these techniques may give the process of integration credibility rather than leaving researchers feeling that they have “made things up.” It may also encourage researchers to describe their approaches to integration, allowing them to be transparent and helping them to develop, critique, and improve on these techniques. Most importantly, we believe it may help researchers to generate further understanding from their research.
We have presented integration as unproblematic, but it is not. It may be easier for single researchers to use these techniques than a large research team. Large teams will need to pay attention to team dynamics, considering who will take responsibility for integration and who will be taking part in the process. In addition, we have taken a technical stance here rather than paying attention to different philosophical beliefs that may shape approaches to integration. We consider that these techniques would work in the context of a pragmatic or subtle realist stance adopted by some mixed methods researchers. 25 Finally, it is important to remember that these techniques are aids to integration and are helpful only when applied with expertise.
Summary points
Health researchers are increasingly using designs which combine qualitative and quantitative methods
However, there is often lack of integration between methods
Three techniques are described that can help researchers to integrate data from different components of a study: triangulation protocol, following a thread, and the mixed methods matrix
Use of these methods will allow researchers to learn more from the information they have collected
Cite this as: BMJ 2010;341:c4587
Funding: Medical Research Council grant reference G106/1116
Competing interests: All authors have completed the unified competing interest form at www.icmje.org/coi_disclosure.pdf (available on request from the corresponding author) and declare financial support for the submitted work from the Medical Research Council; no financial relationships with commercial entities that might have an interest in the submitted work; no spouses, partners, or children with relationships with commercial entities that might have an interest in the submitted work; and no non-financial interests that may be relevant to the submitted work.
Contributors: AOC wrote the paper. JN and EM contributed to drafts and all authors agreed the final version. AOC is guarantor.
Provenance and peer review: Not commissioned; externally peer reviewed.
- ↵ Lingard L, Albert M, Levinson W. Grounded theory, mixed methods and action research. BMJ 2008 ; 337 : a567 . OpenUrl FREE Full Text
- ↵ Creswell JW, Fetters MD, Ivankova NV. Designing a mixed methods study in primary care. Ann Fam Med 2004 ; 2 : 7 -12. OpenUrl Abstract / FREE Full Text
- ↵ Lewin S, Glenton C, Oxman AD. Use of qualitative methods alongside randomised controlled trials of complex healthcare interventions: methodological study. BMJ 2009 ; 339 : b3496 . OpenUrl Abstract / FREE Full Text
- ↵ O’Cathain A, Murphy E, Nicholl J. Integration and publications as indicators of ‘yield’ from mixed methods studies. J Mix Methods Res 2007 ; 1 : 147 -63. OpenUrl CrossRef Web of Science
- ↵ Barbour RS. The case for combining qualitative and quantitative approaches in health services research. J Health Serv Res Policy 1999 ; 4 : 39 -43. OpenUrl PubMed
- ↵ O’Cathain A, Nicholl J, Murphy E. Structural issues affecting mixed methods studies in health research: a qualitative study. BMC Med Res Methodol 2009 ; 9 : 82 . OpenUrl CrossRef PubMed
- ↵ Bryman A. Barriers to integrating quantitative and qualitative research. J Mix Methods Res 2007 ; 1 : 8 -22. OpenUrl CrossRef
- ↵ Creswell JW, Plano-Clark V. Designing and conducting mixed methods research . Sage, 2007 .
- ↵ Bazeley P. Analysing mixed methods data. In: Andrew S, Halcomb EJ, eds. Mixed methods research for nursing and the health sciences . Wiley-Blackwell, 2009 :84-118.
- ↵ Sandelowski M. Triangles and crystals: on the geometry of qualitative research. Res Nurs Health 1995 ; 18 : 569 -74. OpenUrl CrossRef PubMed Web of Science
- ↵ Farmer T, Robinson K, Elliott SJ, Eyles J. Developing and implementing a triangulation protocol for qualitative health research. Qual Health Res 2006 ; 16 : 377 -94. OpenUrl Abstract / FREE Full Text
- ↵ Foster RL. Addressing the epistemologic and practical issues in multimethod research: a procedure for conceptual triangulation. Adv Nurs Sci 1997 ; 20 : 1 -12. OpenUrl PubMed
- ↵ Erzerberger C, Prein G. Triangulation: validity and empirically based hypothesis construction. Qual Quant 1997 ; 31 : 141 -54. OpenUrl CrossRef Web of Science
- ↵ Fielding NG, Fielding JL. Linking data . Sage, 1986 .
- ↵ Moffatt S, White M, Mackintosh J, Howel D. Using quantitative and qualitative data in health services research—what happens when mixed method findings conflict? BMC Health Serv Res 2006 ; 6 : 28 . OpenUrl CrossRef PubMed
- ↵ Sampson FC, O’Cathain A, Goodacre S. Is primary angioplasty an acceptable alternative to thrombolysis? Quantitative and qualitative study of patient and carer satisfaction. Health Expectations (forthcoming).
- ↵ Morgan DL. Practical strategies for combining qualitative and quantitative methods: applications to health research. Qual Health Res 1998 ; 8 : 362 -76. OpenUrl Abstract / FREE Full Text
- ↵ Moran-Ellis J, Alexander VD, Cronin A, Dickinson M, Fielding J, Sleney J, et al. Triangulation and integration: processes, claims and implications. Qualitative Research 2006 ; 6 : 45 -59. OpenUrl Abstract / FREE Full Text
- ↵ Adamson J, Ben-Shlomo Y, Chaturvedi N, Donovan J. Exploring the impact of patient views on ‘appropriate’ use of services and help seeking: a mixed method study. Br J Gen Pract 2009 ; 59 : 496 -502. OpenUrl Web of Science
- ↵ Wendler MC. Triangulation using a meta-matrix. J Adv Nurs 2001 ; 35 : 521 -5. OpenUrl CrossRef PubMed Web of Science
- ↵ Miles M, Huberman A. Qualitative data analysis: an expanded sourcebook . Sage, 1994 .
- ↵ O’Cathain A, Murphy E, Nicholl J. Multidisciplinary, interdisciplinary or dysfunctional? Team working in mixed methods research. Qual Health Res 2008 ; 18 : 1574 -85. OpenUrl Abstract / FREE Full Text
- ↵ Sandelowski M. Combining qualitative and quantitative sampling, data collection, and analysis techniques in mixed-method studies. Res Nurs Health 2000 ; 23 : 246 -55. OpenUrl CrossRef PubMed Web of Science
- ↵ Campbell R, Quilty B, Dieppe P. Discrepancies between patients’ assessments of outcome: qualitative study nested within a randomised controlled trial. BMJ 2003 ; 326 : 252 -3. OpenUrl FREE Full Text
- ↵ Mays N, Pope C. Assessing quality in qualitative research. BMJ 2000 ; 320 : 50 -2. OpenUrl FREE Full Text
News alert: UC Berkeley has announced its next university librarian
Secondary menu
- Log in to your Library account
- Hours and Maps
- Connect from Off Campus
- UC Berkeley Home
Search form
Research methods--quantitative, qualitative, and more: overview.
- Quantitative Research
- Qualitative Research
- Data Science Methods (Machine Learning, AI, Big Data)
- Text Mining and Computational Text Analysis
- Evidence Synthesis/Systematic Reviews
- Get Data, Get Help!
About Research Methods
This guide provides an overview of research methods, how to choose and use them, and supports and resources at UC Berkeley.
As Patten and Newhart note in the book Understanding Research Methods , "Research methods are the building blocks of the scientific enterprise. They are the "how" for building systematic knowledge. The accumulation of knowledge through research is by its nature a collective endeavor. Each well-designed study provides evidence that may support, amend, refute, or deepen the understanding of existing knowledge...Decisions are important throughout the practice of research and are designed to help researchers collect evidence that includes the full spectrum of the phenomenon under study, to maintain logical rules, and to mitigate or account for possible sources of bias. In many ways, learning research methods is learning how to see and make these decisions."
The choice of methods varies by discipline, by the kind of phenomenon being studied and the data being used to study it, by the technology available, and more. This guide is an introduction, but if you don't see what you need here, always contact your subject librarian, and/or take a look to see if there's a library research guide that will answer your question.
Suggestions for changes and additions to this guide are welcome!
START HERE: SAGE Research Methods
Without question, the most comprehensive resource available from the library is SAGE Research Methods. HERE IS THE ONLINE GUIDE to this one-stop shopping collection, and some helpful links are below:
- SAGE Research Methods
- Little Green Books (Quantitative Methods)
- Little Blue Books (Qualitative Methods)
- Dictionaries and Encyclopedias
- Case studies of real research projects
- Sample datasets for hands-on practice
- Streaming video--see methods come to life
- Methodspace- -a community for researchers
- SAGE Research Methods Course Mapping
Library Data Services at UC Berkeley
Library Data Services Program and Digital Scholarship Services
The LDSP offers a variety of services and tools ! From this link, check out pages for each of the following topics: discovering data, managing data, collecting data, GIS data, text data mining, publishing data, digital scholarship, open science, and the Research Data Management Program.
Be sure also to check out the visual guide to where to seek assistance on campus with any research question you may have!
Library GIS Services
Other Data Services at Berkeley
D-Lab Supports Berkeley faculty, staff, and graduate students with research in data intensive social science, including a wide range of training and workshop offerings Dryad Dryad is a simple self-service tool for researchers to use in publishing their datasets. It provides tools for the effective publication of and access to research data. Geospatial Innovation Facility (GIF) Provides leadership and training across a broad array of integrated mapping technologies on campu Research Data Management A UC Berkeley guide and consulting service for research data management issues
General Research Methods Resources
Here are some general resources for assistance:
- Assistance from ICPSR (must create an account to access): Getting Help with Data , and Resources for Students
- Wiley Stats Ref for background information on statistics topics
- Survey Documentation and Analysis (SDA) . Program for easy web-based analysis of survey data.
Consultants
- D-Lab/Data Science Discovery Consultants Request help with your research project from peer consultants.
- Research data (RDM) consulting Meet with RDM consultants before designing the data security, storage, and sharing aspects of your qualitative project.
- Statistics Department Consulting Services A service in which advanced graduate students, under faculty supervision, are available to consult during specified hours in the Fall and Spring semesters.
Related Resourcex
- IRB / CPHS Qualitative research projects with human subjects often require that you go through an ethics review.
- OURS (Office of Undergraduate Research and Scholarships) OURS supports undergraduates who want to embark on research projects and assistantships. In particular, check out their "Getting Started in Research" workshops
- Sponsored Projects Sponsored projects works with researchers applying for major external grants.
- Next: Quantitative Research >>
- Last Updated: Apr 25, 2024 11:09 AM
- URL: https://guides.lib.berkeley.edu/researchmethods
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- Qualitative vs Quantitative Research | Examples & Methods
Qualitative vs Quantitative Research | Examples & Methods
Published on 4 April 2022 by Raimo Streefkerk . Revised on 8 May 2023.
When collecting and analysing data, quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings. Both are important for gaining different kinds of knowledge.
Common quantitative methods include experiments, observations recorded as numbers, and surveys with closed-ended questions. Qualitative research Qualitative research is expressed in words . It is used to understand concepts, thoughts or experiences. This type of research enables you to gather in-depth insights on topics that are not well understood.
Table of contents
The differences between quantitative and qualitative research, data collection methods, when to use qualitative vs quantitative research, how to analyse qualitative and quantitative data, frequently asked questions about qualitative and quantitative research.
Quantitative and qualitative research use different research methods to collect and analyse data, and they allow you to answer different kinds of research questions.

Prevent plagiarism, run a free check.
Quantitative and qualitative data can be collected using various methods. It is important to use a data collection method that will help answer your research question(s).
Many data collection methods can be either qualitative or quantitative. For example, in surveys, observations or case studies , your data can be represented as numbers (e.g. using rating scales or counting frequencies) or as words (e.g. with open-ended questions or descriptions of what you observe).
However, some methods are more commonly used in one type or the other.
Quantitative data collection methods
- Surveys : List of closed or multiple choice questions that is distributed to a sample (online, in person, or over the phone).
- Experiments : Situation in which variables are controlled and manipulated to establish cause-and-effect relationships.
- Observations: Observing subjects in a natural environment where variables can’t be controlled.
Qualitative data collection methods
- Interviews : Asking open-ended questions verbally to respondents.
- Focus groups: Discussion among a group of people about a topic to gather opinions that can be used for further research.
- Ethnography : Participating in a community or organisation for an extended period of time to closely observe culture and behavior.
- Literature review : Survey of published works by other authors.
A rule of thumb for deciding whether to use qualitative or quantitative data is:
- Use quantitative research if you want to confirm or test something (a theory or hypothesis)
- Use qualitative research if you want to understand something (concepts, thoughts, experiences)
For most research topics you can choose a qualitative, quantitative or mixed methods approach . Which type you choose depends on, among other things, whether you’re taking an inductive vs deductive research approach ; your research question(s) ; whether you’re doing experimental , correlational , or descriptive research ; and practical considerations such as time, money, availability of data, and access to respondents.
Quantitative research approach
You survey 300 students at your university and ask them questions such as: ‘on a scale from 1-5, how satisfied are your with your professors?’
You can perform statistical analysis on the data and draw conclusions such as: ‘on average students rated their professors 4.4’.
Qualitative research approach
You conduct in-depth interviews with 15 students and ask them open-ended questions such as: ‘How satisfied are you with your studies?’, ‘What is the most positive aspect of your study program?’ and ‘What can be done to improve the study program?’
Based on the answers you get you can ask follow-up questions to clarify things. You transcribe all interviews using transcription software and try to find commonalities and patterns.
Mixed methods approach
You conduct interviews to find out how satisfied students are with their studies. Through open-ended questions you learn things you never thought about before and gain new insights. Later, you use a survey to test these insights on a larger scale.
It’s also possible to start with a survey to find out the overall trends, followed by interviews to better understand the reasons behind the trends.
Qualitative or quantitative data by itself can’t prove or demonstrate anything, but has to be analysed to show its meaning in relation to the research questions. The method of analysis differs for each type of data.
Analysing quantitative data
Quantitative data is based on numbers. Simple maths or more advanced statistical analysis is used to discover commonalities or patterns in the data. The results are often reported in graphs and tables.
Applications such as Excel, SPSS, or R can be used to calculate things like:
- Average scores
- The number of times a particular answer was given
- The correlation or causation between two or more variables
- The reliability and validity of the results
Analysing qualitative data
Qualitative data is more difficult to analyse than quantitative data. It consists of text, images or videos instead of numbers.
Some common approaches to analysing qualitative data include:
- Qualitative content analysis : Tracking the occurrence, position and meaning of words or phrases
- Thematic analysis : Closely examining the data to identify the main themes and patterns
- Discourse analysis : Studying how communication works in social contexts
Quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings.
Quantitative methods allow you to test a hypothesis by systematically collecting and analysing data, while qualitative methods allow you to explore ideas and experiences in depth.
In mixed methods research , you use both qualitative and quantitative data collection and analysis methods to answer your research question .
The research methods you use depend on the type of data you need to answer your research question .
- If you want to measure something or test a hypothesis , use quantitative methods . If you want to explore ideas, thoughts, and meanings, use qualitative methods .
- If you want to analyse a large amount of readily available data, use secondary data. If you want data specific to your purposes with control over how they are generated, collect primary data.
- If you want to establish cause-and-effect relationships between variables , use experimental methods. If you want to understand the characteristics of a research subject, use descriptive methods.
Data collection is the systematic process by which observations or measurements are gathered in research. It is used in many different contexts by academics, governments, businesses, and other organisations.
There are various approaches to qualitative data analysis , but they all share five steps in common:
- Prepare and organise your data.
- Review and explore your data.
- Develop a data coding system.
- Assign codes to the data.
- Identify recurring themes.
The specifics of each step depend on the focus of the analysis. Some common approaches include textual analysis , thematic analysis , and discourse analysis .
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Streefkerk, R. (2023, May 08). Qualitative vs Quantitative Research | Examples & Methods. Scribbr. Retrieved 24 June 2024, from https://www.scribbr.co.uk/research-methods/quantitative-qualitative-research/
Is this article helpful?
Raimo Streefkerk
- Translators
- Graphic Designers
Please enter the email address you used for your account. Your sign in information will be sent to your email address after it has been verified.
Qualitative and Quantitative Research: Differences and Similarities

Qualitative research and quantitative research are two complementary approaches for understanding the world around us.
Qualitative research collects non-numerical data , and the results are typically presented as written descriptions, photographs, videos, and/or sound recordings.

In contrast, quantitative research collects numerical data , and the results are typically presented in tables, graphs, and charts.

Debates about whether to use qualitative or quantitative research methods are common in the social sciences (i.e. anthropology, archaeology, economics, geography, history, law, linguistics, politics, psychology, sociology), which aim to understand a broad range of human conditions. Qualitative observations may be used to gain an understanding of unique situations, which may lead to quantitative research that aims to find commonalities.

Within the natural and physical sciences (i.e. physics, chemistry, geology, biology), qualitative observations often lead to a plethora of quantitative studies. For example, unusual observations through a microscope or telescope can immediately lead to counting and measuring. In other situations, meaningful numbers cannot immediately be obtained, and the qualitative research must stand on its own (e.g. The patient presented with an abnormally enlarged spleen (Figure 1), and complained of pain in the left shoulder.)
For both qualitative and quantitative research, the researcher's assumptions shape the direction of the study and thereby influence the results that can be obtained. Let's consider some prominent examples of qualitative and quantitative research, and how these two methods can complement each other.

Qualitative research example
In 1960, Jane Goodall started her decades-long study of chimpanzees in the wild at Gombe Stream National Park in Tanzania. Her work is an example of qualitative research that has fundamentally changed our understanding of non-human primates, and has influenced our understanding of other animals, their abilities, and their social interactions.
Dr. Goodall was by no means the first person to study non-human primates, but she took a highly unusual approach in her research. For example, she named individual chimpanzees instead of numbering them, and used terms such as "childhood", "adolescence", "motivation", "excitement", and "mood". She also described the distinct "personalities" of individual chimpanzees. Dr. Goodall was heavily criticized for describing chimpanzees in ways that are regularly used to describe humans, which perfectly illustrates how the assumptions of the researcher can heavily influence their work.
The quality of qualitative research is largely determined by the researcher's ability, knowledge, creativity, and interpretation of the results. One of the hallmarks of good qualitative research is that nothing is predefined or taken for granted, and that the study subjects teach the researcher about their lives. As a result, qualitative research studies evolve over time, and the focus or techniques used can shift as the study progresses.
Qualitative research methods
Dr. Goodall immersed herself in the chimpanzees' natural surroundings, and used direct observation to learn about their daily life. She used photographs, videos, sound recordings, and written descriptions to present her data. These are all well-established methods of qualitative research, with direct observation within the natural setting considered a gold standard. These methods are time-intensive for the researcher (and therefore monetarily expensive) and limit the number of individuals that can be studied at one time.
When studying humans, a wider variety of research methods are available to understand how people perceive and navigate their world—past or present. These techniques include: in-depth interviews (e.g. Can you discuss your experience of growing up in the Deep South in the 1950s?), open-ended survey questions (e.g. What do you enjoy most about being part of the Church of Latter Day Saints?), focus group discussions, researcher participation (e.g. in military training), review of written documents (e.g. social media accounts, diaries, school records, etc), and analysis of cultural records (e.g. anything left behind including trash, clothing, buildings, etc).
Qualitative research can lead to quantitative research
Qualitative research is largely exploratory. The goal is to gain a better understanding of an unknown situation. Qualitative research in humans may lead to a better understanding of underlying reasons, opinions, motivations, experiences, etc. The information generated through qualitative research can provide new hypotheses to test through quantitative research. Quantitative research studies are typically more focused and less exploratory, involve a larger sample size, and by definition produce numerical data.
Dr. Goodall's qualitative research clearly established periods of childhood and adolescence in chimpanzees. Quantitative studies could better characterize these time periods, for example by recording the amount of time individual chimpanzees spend with their mothers, with peers, or alone each day during childhood compared to adolescence.
For studies involving humans, quantitative data might be collected through a questionnaire with a limited number of answers (e.g. If you were being bullied, what is the likelihood that you would tell at least one parent? A) Very likely, B) Somewhat likely, C) Somewhat unlikely, D) Unlikely).
Quantitative research example
One of the most influential examples of quantitative research began with a simple qualitative observation: Some peas are round, and other peas are wrinkled. Gregor Mendel was not the first to make this observation, but he was the first to carry out rigorous quantitative experiments to better understand this characteristic of garden peas.
As described in his 1865 research paper, Mendel carried out carefully controlled genetic crosses and counted thousands of resulting peas. He discovered that the ratio of round peas to wrinkled peas matched the ratio expected if pea shape were determined by two copies of a gene for pea shape, one inherited from each parent. These experiments and calculations became the foundation of modern genetics, and Mendel's ratios became the default hypothesis for experiments involving thousands of different genes in hundreds of different organisms.
The quality of quantitative research is largely determined by the researcher's ability to design a feasible experiment, that will provide clear evidence to support or refute the working hypothesis. The hallmarks of good quantitative research include: a study that can be replicated by an independent group and produce similar results, a sample population that is representative of the population under study, a sample size that is large enough to reveal any expected statistical significance.
Quantitative research methods
The basic methods of quantitative research involve measuring or counting things (size, weight, distance, offspring, light intensity, participants, number of times a specific phrase is used, etc). In the social sciences especially, responses are often be split into somewhat arbitrary categories (e.g. How much time do you spend on social media during a typical weekday? A) 0-15 min, B) 15-30 min, C) 30-60 min, D) 1-2 hrs, E) more than 2 hrs).
These quantitative data can be displayed in a table, graph, or chart, and grouped in ways that highlight patterns and relationships. The quantitative data should also be subjected to mathematical and statistical analysis. To reveal overall trends, the average (or most common survey answer) and standard deviation can be determined for different groups (e.g. with treatment A and without treatment B).
Typically, the most important result from a quantitative experiment is the test of statistical significance. There are many different methods for determining statistical significance (e.g. t-test, chi square test, ANOVA, etc.), and the appropriate method will depend on the specific experiment.
Statistical significance provides an answer to the question: What is the probably that the difference observed between two groups is due to chance alone, and the two groups are actually the same? For example, your initial results might show that 32% of Friday grocery shoppers buy alcohol, while only 16% of Monday grocery shoppers buy alcohol. If this result reflects a true difference between Friday shoppers and Monday shoppers, grocery store managers might want to offer Friday specials to increase sales.
After the appropriate statistical test is conducted (which incorporates sample size and other variables), the probability that the observed difference is due to chance alone might be more than 5%, or less than 5%. If the probability is less than 5%, the convention is that the result is considered statistically significant. (The researcher is also likely to cheer and have at least a small celebration.) Otherwise, the result is considered statistically insignificant. (If the value is close to 5%, the researcher may try to group the data in different ways to achieve statistical significance. For example, by comparing alcohol sales after 5pm on Friday and Monday.) While it is important to reveal differences that may not be immediately obvious, the desire to manipulate information until it becomes statistically significant can also contribute to bias in research.
So how often do results from two groups that are actually the same give a probability of less than 5%? A bit less than 5% of the time (by definition). This is one of the reasons why it is so important that quantitative research can be replicated by different groups.
Which research method should I choose?
Choose the research methods that will allow you to produce the best results for a meaningful question, while acknowledging any unknowns and controlling for any bias. In many situations, this will involve a mixed methods approach. Qualitative research may allow you to learn about a poorly understood topic, and then quantitative research may allow you to obtain results that can be subjected to rigorous statistical tests to find true and meaningful patterns. Many different approaches are required to understand the complex world around us.
- Academic Writing Advice
- All Blog Posts
- Writing Advice
- Admissions Writing Advice
- Book Writing Advice
- Short Story Advice
- Employment Writing Advice
- Business Writing Advice
- Web Content Advice
- Article Writing Advice
- Magazine Writing Advice
- Grammar Advice
- Dialect Advice
- Editing Advice
- Freelance Advice
- Legal Writing Advice
- Poetry Advice
- Graphic Design Advice
- Logo Design Advice
- Translation Advice
- Blog Reviews
- Short Story Award Winners
- Scholarship Winners

Need an academic editor before submitting your work?
The differences between qualitative and quantitative research methods
Last updated
15 January 2023
Reviewed by
Two approaches to this systematic information gathering are qualitative and quantitative research. Each of these has its place in data collection, but each one approaches from a different direction. Here's what you need to know about qualitative and quantitative research.
All your data in one place
Analyze your qualitative and quantitative data together in Dovetail and uncover deeper insights
- The differences between quantitative and qualitative research
The main difference between these two approaches is the type of data you collect and how you interpret it. Qualitative research focuses on word-based data, aiming to define and understand ideas. This study allows researchers to collect information in an open-ended way through interviews, ethnography, and observation. You’ll study this information to determine patterns and the interplay of variables.
On the other hand, quantitative research focuses on numerical data and using it to determine relationships between variables. Researchers use easily quantifiable forms of data collection, such as experiments that measure the effect of one or several variables on one another.
- Qualitative vs. quantitative data collection
Focusing on different types of data means that the data collection methods vary.
Quantitative data collection methods
As previously stated, quantitative data collection focuses on numbers. You gather information through experiments, database reports, or surveys with multiple-choice answers. The goal is to have data you can use in numerical analysis to determine relationships.
Qualitative data collection methods
On the other hand, the data collected for qualitative research is an exploration of a subject's attributes, thoughts, actions, or viewpoints. Researchers will typically conduct interviews , hold focus groups, or observe behavior in a natural setting to assemble this information. Other options include studying personal accounts or cultural records.
- Qualitative vs. quantitative outcomes
The two approaches naturally produce different types of outcomes. Qualitative research gains a better understanding of the reason something happens. For example, researchers may comb through feedback and statements to ascertain the reasoning behind certain behaviors or actions.
On the other hand, quantitative research focuses on the numerical analysis of data, which may show cause-and-effect relationships. Put another way, qualitative research investigates why something happens, while quantitative research looks at what happens.
- How to analyze qualitative and quantitative data
Because the two research methods focus on different types of information, analyzing the data you've collected will look different, depending on your approach.
Analyzing quantitative data
As this data is often numerical, you’ll likely use statistical analysis to identify patterns. Researchers may use computer programs to generate data such as averages or rate changes, illustrating the results in tables or graphs.
Analyzing qualitative data
Qualitative data is more complex and time-consuming to process as it may include written texts, videos, or images to study. Finding patterns in thinking, actions, and beliefs is more nuanced and subject to interpretation.
Researchers may use techniques such as thematic analysis , combing through the data to identify core themes or patterns. Another tool is discourse analysis , which studies how communication functions in different contexts.
- When to use qualitative vs. quantitative research
Choosing between the two approaches comes down to understanding what your goal is with the research.
Qualitative research approach
Qualitative research is useful for understanding a concept, such as what people think about certain experiences or how cultural beliefs affect perceptions of events. It can help you formulate a hypothesis or clarify general questions about the topic.
Quantitative research approach
On the other hand, quantitative research verifies or tests a hypothesis you've developed, or you can use it to find answers to those questions.
Mixed methods approach
Often, researchers use elements of both types of research to provide complex and targeted information. This may look like a survey with multiple-choice and open-ended questions.
- Benefits and limitations
Of course, each type of research has drawbacks and strengths. It's essential to be aware of the pros and cons.
Qualitative studies: Pros and cons
This approach lets you consider your subject creatively and examine big-picture questions. It can advance your global understanding of topics that are challenging to quantify.
On the other hand, the wide-open possibilities of qualitative research can make it tricky to focus effectively on your subject of inquiry. It makes it easier for researchers to skew the data with social biases and personal assumptions. There’s also the tendency for people to behave differently under observation.
It can also be more difficult to get a large sample size because it's generally more complex and expensive to conduct qualitative research. The process usually takes longer, as well.
Quantitative studies: Pros and cons
The quantitative methodology produces data you can communicate and present without bias. The methods are direct and generally easier to reproduce on a larger scale, enabling researchers to get accurate results. It can be instrumental in pinning down precise facts about a topic.
It is also a restrictive form of inquiry. Researchers cannot add context to this type of data collection or expand their focus in a different direction within a single study. They must be alert for biases. Quantitative research is more susceptible to selection bias and omitting or incorrectly measuring variables.
- How to balance qualitative and quantitative research
Although people tend to gravitate to one form of inquiry over another, each has its place in studying a subject. Both approaches can identify patterns illustrating the connection between multiple elements, and they can each advance your understanding of subjects in important ways.
Understanding how each option will serve you will help you decide how and when to use each. Generally, qualitative research can help you develop and refine questions, while quantitative research helps you get targeted answers to those questions. Which element do you need to advance your study of the subject? Can both of them hone your knowledge?
Open-ended vs. close-ended questions
One way to use techniques from both approaches is with open-ended and close-ended questions in surveys. Because quantitative analysis requires defined sets of data that you can represent numerically, the questions must be close-ended. On the other hand, qualitative inquiry is naturally open-ended, allowing room for complex ideas.
An example of this is a survey on the impact of inflation. You could include both multiple-choice questions and open-response questions:
1. How do you compensate for higher prices at the grocery store? (Select all that apply)
A. Purchase fewer items
B. Opt for less expensive choices
C. Take money from other parts of the budget
D. Use a food bank or other charity to fill the gaps
E. Make more food from scratch
2. How do rising prices affect your grocery shopping habits? (Write your answer)
We need qualitative and quantitative forms of research to advance our understanding of the world. Neither is the "right" way to go, but one may be better for you depending on your needs.

Learn more about qualitative research data analysis software
Should you be using a customer insights hub.
Do you want to discover previous research faster?
Do you share your research findings with others?
Do you analyze research data?
Start for free today, add your research, and get to key insights faster
Editor’s picks
Last updated: 18 April 2023
Last updated: 27 February 2023
Last updated: 6 February 2023
Last updated: 6 October 2023
Last updated: 5 February 2023
Last updated: 16 April 2023
Last updated: 7 March 2023
Last updated: 9 March 2023
Last updated: 12 December 2023
Last updated: 11 March 2024
Last updated: 6 March 2024
Last updated: 5 March 2024
Last updated: 13 May 2024
Latest articles
Related topics, .css-je19u9{-webkit-align-items:flex-end;-webkit-box-align:flex-end;-ms-flex-align:flex-end;align-items:flex-end;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-flex-direction:row;-ms-flex-direction:row;flex-direction:row;-webkit-box-flex-wrap:wrap;-webkit-flex-wrap:wrap;-ms-flex-wrap:wrap;flex-wrap:wrap;-webkit-box-pack:center;-ms-flex-pack:center;-webkit-justify-content:center;justify-content:center;row-gap:0;text-align:center;max-width:671px;}@media (max-width: 1079px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}}@media (max-width: 799px){.css-je19u9{max-width:400px;}.css-je19u9>span{white-space:pre;}} decide what to .css-1kiodld{max-height:56px;display:-webkit-box;display:-webkit-flex;display:-ms-flexbox;display:flex;-webkit-align-items:center;-webkit-box-align:center;-ms-flex-align:center;align-items:center;}@media (max-width: 1079px){.css-1kiodld{display:none;}} build next, decide what to build next.

Users report unexpectedly high data usage, especially during streaming sessions.

Users find it hard to navigate from the home page to relevant playlists in the app.

It would be great to have a sleep timer feature, especially for bedtime listening.

I need better filters to find the songs or artists I’m looking for.
Log in or sign up
Get started for free
Qualitative and Quantitative Methods in Research
- Living reference work entry
- First Online: 10 August 2022
- Cite this living reference work entry

- Christina Mazzola Nicols 3
44 Accesses
1 Definition
Research that aims to gather an in-depth understanding of human behavior and the factors contributing to the behavior. Frequent methods of qualitative data collection include observation, in-depth interviews, and focus groups. Words, pictures, or objects comprise the resulting data.
A qualitative research method used to understand behaviors in a natural setting. The researcher relies on their observations of the subject to collect and analyze data.
A qualitative method in which an interviewer directs a series of questions to the person he/she is interviewing, typically either in person or by telephone. As an interview progresses, questions tend to move from the general to the specific.
Interviews conducted in small groups of participants instead of individuals. Typically, a trained moderator leads a focused discussion among eight to ten participants over the course of 1–2 h. Focus groups can be conducted in...
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
Institutional subscriptions
Further Readings
Douglas Evans, W. (2016). Social marketing research for global public health: Methods and technologies . Oxford Press.
Book Google Scholar
Hicks, N. J., & Nicols, C. M. (2016). Health industry communication: New media, new methods, new message (2nd ed.). Jones & Bartlett Learning.
Google Scholar
Siegel, M., & Lotenberg, L. D. (2007). Marketing public health: Strategies to promote social change (2nd ed.). Jones and Bartlett Publishers.
Download references
Author information
Authors and affiliations.
Hager Sharp, Washington, DC, USA
Christina Mazzola Nicols
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Christina Mazzola Nicols .
Section Editor information
Milken Institute School of Public Health, George Washington University, Washington, D. C., USA
American University of Beirut, Beirut, Lebanon
Marco Bardus
Rights and permissions
Reprints and permissions
Copyright information
© 2021 The Author(s), under exclusive licence to Springer Nature Switzerland AG
About this entry
Cite this entry.
Nicols, C.M. (2021). Qualitative and Quantitative Methods in Research. In: The Palgrave Encyclopedia of Social Marketing. Palgrave Macmillan, Cham. https://doi.org/10.1007/978-3-030-14449-4_154-1
Download citation
DOI : https://doi.org/10.1007/978-3-030-14449-4_154-1
Received : 11 May 2020
Accepted : 07 July 2021
Published : 10 August 2022
Publisher Name : Palgrave Macmillan, Cham
Print ISBN : 978-3-030-14449-4
Online ISBN : 978-3-030-14449-4
eBook Packages : Springer Reference Business and Management Reference Module Humanities and Social Sciences Reference Module Business, Economics and Social Sciences
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Qualitative vs Quantitative Research Methods & Data Analysis
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
On This Page:
What is the difference between quantitative and qualitative?
The main difference between quantitative and qualitative research is the type of data they collect and analyze.
Quantitative research collects numerical data and analyzes it using statistical methods. The aim is to produce objective, empirical data that can be measured and expressed in numerical terms. Quantitative research is often used to test hypotheses, identify patterns, and make predictions.
Qualitative research , on the other hand, collects non-numerical data such as words, images, and sounds. The focus is on exploring subjective experiences, opinions, and attitudes, often through observation and interviews.
Qualitative research aims to produce rich and detailed descriptions of the phenomenon being studied, and to uncover new insights and meanings.
Quantitative data is information about quantities, and therefore numbers, and qualitative data is descriptive, and regards phenomenon which can be observed but not measured, such as language.
What Is Qualitative Research?
Qualitative research is the process of collecting, analyzing, and interpreting non-numerical data, such as language. Qualitative research can be used to understand how an individual subjectively perceives and gives meaning to their social reality.
Qualitative data is non-numerical data, such as text, video, photographs, or audio recordings. This type of data can be collected using diary accounts or in-depth interviews and analyzed using grounded theory or thematic analysis.
Qualitative research is multimethod in focus, involving an interpretive, naturalistic approach to its subject matter. This means that qualitative researchers study things in their natural settings, attempting to make sense of, or interpret, phenomena in terms of the meanings people bring to them. Denzin and Lincoln (1994, p. 2)
Interest in qualitative data came about as the result of the dissatisfaction of some psychologists (e.g., Carl Rogers) with the scientific study of psychologists such as behaviorists (e.g., Skinner ).
Since psychologists study people, the traditional approach to science is not seen as an appropriate way of carrying out research since it fails to capture the totality of human experience and the essence of being human. Exploring participants’ experiences is known as a phenomenological approach (re: Humanism ).
Qualitative research is primarily concerned with meaning, subjectivity, and lived experience. The goal is to understand the quality and texture of people’s experiences, how they make sense of them, and the implications for their lives.
Qualitative research aims to understand the social reality of individuals, groups, and cultures as nearly as possible as participants feel or live it. Thus, people and groups are studied in their natural setting.
Some examples of qualitative research questions are provided, such as what an experience feels like, how people talk about something, how they make sense of an experience, and how events unfold for people.
Research following a qualitative approach is exploratory and seeks to explain ‘how’ and ‘why’ a particular phenomenon, or behavior, operates as it does in a particular context. It can be used to generate hypotheses and theories from the data.
Qualitative Methods
There are different types of qualitative research methods, including diary accounts, in-depth interviews , documents, focus groups , case study research , and ethnography.
The results of qualitative methods provide a deep understanding of how people perceive their social realities and in consequence, how they act within the social world.
The researcher has several methods for collecting empirical materials, ranging from the interview to direct observation, to the analysis of artifacts, documents, and cultural records, to the use of visual materials or personal experience. Denzin and Lincoln (1994, p. 14)
Here are some examples of qualitative data:
Interview transcripts : Verbatim records of what participants said during an interview or focus group. They allow researchers to identify common themes and patterns, and draw conclusions based on the data. Interview transcripts can also be useful in providing direct quotes and examples to support research findings.
Observations : The researcher typically takes detailed notes on what they observe, including any contextual information, nonverbal cues, or other relevant details. The resulting observational data can be analyzed to gain insights into social phenomena, such as human behavior, social interactions, and cultural practices.
Unstructured interviews : generate qualitative data through the use of open questions. This allows the respondent to talk in some depth, choosing their own words. This helps the researcher develop a real sense of a person’s understanding of a situation.
Diaries or journals : Written accounts of personal experiences or reflections.
Notice that qualitative data could be much more than just words or text. Photographs, videos, sound recordings, and so on, can be considered qualitative data. Visual data can be used to understand behaviors, environments, and social interactions.
Qualitative Data Analysis
Qualitative research is endlessly creative and interpretive. The researcher does not just leave the field with mountains of empirical data and then easily write up his or her findings.
Qualitative interpretations are constructed, and various techniques can be used to make sense of the data, such as content analysis, grounded theory (Glaser & Strauss, 1967), thematic analysis (Braun & Clarke, 2006), or discourse analysis .
For example, thematic analysis is a qualitative approach that involves identifying implicit or explicit ideas within the data. Themes will often emerge once the data has been coded .

Key Features
- Events can be understood adequately only if they are seen in context. Therefore, a qualitative researcher immerses her/himself in the field, in natural surroundings. The contexts of inquiry are not contrived; they are natural. Nothing is predefined or taken for granted.
- Qualitative researchers want those who are studied to speak for themselves, to provide their perspectives in words and other actions. Therefore, qualitative research is an interactive process in which the persons studied teach the researcher about their lives.
- The qualitative researcher is an integral part of the data; without the active participation of the researcher, no data exists.
- The study’s design evolves during the research and can be adjusted or changed as it progresses. For the qualitative researcher, there is no single reality. It is subjective and exists only in reference to the observer.
- The theory is data-driven and emerges as part of the research process, evolving from the data as they are collected.
Limitations of Qualitative Research
- Because of the time and costs involved, qualitative designs do not generally draw samples from large-scale data sets.
- The problem of adequate validity or reliability is a major criticism. Because of the subjective nature of qualitative data and its origin in single contexts, it is difficult to apply conventional standards of reliability and validity. For example, because of the central role played by the researcher in the generation of data, it is not possible to replicate qualitative studies.
- Also, contexts, situations, events, conditions, and interactions cannot be replicated to any extent, nor can generalizations be made to a wider context than the one studied with confidence.
- The time required for data collection, analysis, and interpretation is lengthy. Analysis of qualitative data is difficult, and expert knowledge of an area is necessary to interpret qualitative data. Great care must be taken when doing so, for example, looking for mental illness symptoms.
Advantages of Qualitative Research
- Because of close researcher involvement, the researcher gains an insider’s view of the field. This allows the researcher to find issues that are often missed (such as subtleties and complexities) by the scientific, more positivistic inquiries.
- Qualitative descriptions can be important in suggesting possible relationships, causes, effects, and dynamic processes.
- Qualitative analysis allows for ambiguities/contradictions in the data, which reflect social reality (Denscombe, 2010).
- Qualitative research uses a descriptive, narrative style; this research might be of particular benefit to the practitioner as she or he could turn to qualitative reports to examine forms of knowledge that might otherwise be unavailable, thereby gaining new insight.
What Is Quantitative Research?
Quantitative research involves the process of objectively collecting and analyzing numerical data to describe, predict, or control variables of interest.
The goals of quantitative research are to test causal relationships between variables , make predictions, and generalize results to wider populations.
Quantitative researchers aim to establish general laws of behavior and phenomenon across different settings/contexts. Research is used to test a theory and ultimately support or reject it.
Quantitative Methods
Experiments typically yield quantitative data, as they are concerned with measuring things. However, other research methods, such as controlled observations and questionnaires , can produce both quantitative information.
For example, a rating scale or closed questions on a questionnaire would generate quantitative data as these produce either numerical data or data that can be put into categories (e.g., “yes,” “no” answers).
Experimental methods limit how research participants react to and express appropriate social behavior.
Findings are, therefore, likely to be context-bound and simply a reflection of the assumptions that the researcher brings to the investigation.
There are numerous examples of quantitative data in psychological research, including mental health. Here are a few examples:
Another example is the Experience in Close Relationships Scale (ECR), a self-report questionnaire widely used to assess adult attachment styles .
The ECR provides quantitative data that can be used to assess attachment styles and predict relationship outcomes.
Neuroimaging data : Neuroimaging techniques, such as MRI and fMRI, provide quantitative data on brain structure and function.
This data can be analyzed to identify brain regions involved in specific mental processes or disorders.
For example, the Beck Depression Inventory (BDI) is a clinician-administered questionnaire widely used to assess the severity of depressive symptoms in individuals.
The BDI consists of 21 questions, each scored on a scale of 0 to 3, with higher scores indicating more severe depressive symptoms.
Quantitative Data Analysis
Statistics help us turn quantitative data into useful information to help with decision-making. We can use statistics to summarize our data, describing patterns, relationships, and connections. Statistics can be descriptive or inferential.
Descriptive statistics help us to summarize our data. In contrast, inferential statistics are used to identify statistically significant differences between groups of data (such as intervention and control groups in a randomized control study).
- Quantitative researchers try to control extraneous variables by conducting their studies in the lab.
- The research aims for objectivity (i.e., without bias) and is separated from the data.
- The design of the study is determined before it begins.
- For the quantitative researcher, the reality is objective, exists separately from the researcher, and can be seen by anyone.
- Research is used to test a theory and ultimately support or reject it.
Limitations of Quantitative Research
- Context: Quantitative experiments do not take place in natural settings. In addition, they do not allow participants to explain their choices or the meaning of the questions they may have for those participants (Carr, 1994).
- Researcher expertise: Poor knowledge of the application of statistical analysis may negatively affect analysis and subsequent interpretation (Black, 1999).
- Variability of data quantity: Large sample sizes are needed for more accurate analysis. Small-scale quantitative studies may be less reliable because of the low quantity of data (Denscombe, 2010). This also affects the ability to generalize study findings to wider populations.
- Confirmation bias: The researcher might miss observing phenomena because of focus on theory or hypothesis testing rather than on the theory of hypothesis generation.
Advantages of Quantitative Research
- Scientific objectivity: Quantitative data can be interpreted with statistical analysis, and since statistics are based on the principles of mathematics, the quantitative approach is viewed as scientifically objective and rational (Carr, 1994; Denscombe, 2010).
- Useful for testing and validating already constructed theories.
- Rapid analysis: Sophisticated software removes much of the need for prolonged data analysis, especially with large volumes of data involved (Antonius, 2003).
- Replication: Quantitative data is based on measured values and can be checked by others because numerical data is less open to ambiguities of interpretation.
- Hypotheses can also be tested because of statistical analysis (Antonius, 2003).
Antonius, R. (2003). Interpreting quantitative data with SPSS . Sage.
Black, T. R. (1999). Doing quantitative research in the social sciences: An integrated approach to research design, measurement and statistics . Sage.
Braun, V. & Clarke, V. (2006). Using thematic analysis in psychology . Qualitative Research in Psychology , 3, 77–101.
Carr, L. T. (1994). The strengths and weaknesses of quantitative and qualitative research : what method for nursing? Journal of advanced nursing, 20(4) , 716-721.
Denscombe, M. (2010). The Good Research Guide: for small-scale social research. McGraw Hill.
Denzin, N., & Lincoln. Y. (1994). Handbook of Qualitative Research. Thousand Oaks, CA, US: Sage Publications Inc.
Glaser, B. G., Strauss, A. L., & Strutzel, E. (1968). The discovery of grounded theory; strategies for qualitative research. Nursing research, 17(4) , 364.
Minichiello, V. (1990). In-Depth Interviewing: Researching People. Longman Cheshire.
Punch, K. (1998). Introduction to Social Research: Quantitative and Qualitative Approaches. London: Sage
Further Information
- Mixed methods research
- Designing qualitative research
- Methods of data collection and analysis
- Introduction to quantitative and qualitative research
- Checklists for improving rigour in qualitative research: a case of the tail wagging the dog?
- Qualitative research in health care: Analysing qualitative data
- Qualitative data analysis: the framework approach
- Using the framework method for the analysis of
- Qualitative data in multi-disciplinary health research
- Content Analysis
- Grounded Theory
- Thematic Analysis
Related Articles

Research Methodology
Mixed Methods Research

Conversation Analysis

Discourse Analysis

Phenomenology In Qualitative Research

Ethnography In Qualitative Research

Narrative Analysis In Qualitative Research
Educational resources and simple solutions for your research journey

Qualitative vs Quantitative Research: Differences, Examples, and Methods
There are two broad kinds of research approaches: qualitative and quantitative research that are used to study and analyze phenomena in various fields such as natural sciences, social sciences, and humanities. Whether you have realized it or not, your research must have followed either or both research types. In this article we will discuss what qualitative vs quantitative research is, their applications, pros and cons, and when to use qualitative vs quantitative research . Before we get into the details, it is important to understand the differences between the qualitative and quantitative research.
Table of Contents
Qualitative v s Quantitative Research
Quantitative research deals with quantity, hence, this research type is concerned with numbers and statistics to prove or disapprove theories or hypothesis. In contrast, qualitative research is all about quality – characteristics, unquantifiable features, and meanings to seek deeper understanding of behavior and phenomenon. These two methodologies serve complementary roles in the research process, each offering unique insights and methods suited to different research questions and objectives.
Qualitative and quantitative research approaches have their own unique characteristics, drawbacks, advantages, and uses. Where quantitative research is mostly employed to validate theories or assumptions with the goal of generalizing facts to the larger population, qualitative research is used to study concepts, thoughts, or experiences for the purpose of gaining the underlying reasons, motivations, and meanings behind human behavior .
What Are the Differences Between Qualitative and Quantitative Research
Qualitative and quantitative research differs in terms of the methods they employ to conduct, collect, and analyze data. For example, qualitative research usually relies on interviews, observations, and textual analysis to explore subjective experiences and diverse perspectives. While quantitative data collection methods include surveys, experiments, and statistical analysis to gather and analyze numerical data. The differences between the two research approaches across various aspects are listed in the table below.
| Understanding meanings, exploring ideas, behaviors, and contexts, and formulating theories | Generating and analyzing numerical data, quantifying variables by using logical, statistical, and mathematical techniques to test or prove hypothesis | |
| Limited sample size, typically not representative | Large sample size to draw conclusions about the population | |
| Expressed using words. Non-numeric, textual, and visual narrative | Expressed using numerical data in the form of graphs or values. Statistical, measurable, and numerical | |
| Interviews, focus groups, observations, ethnography, literature review, and surveys | Surveys, experiments, and structured observations | |
| Inductive, thematic, and narrative in nature | Deductive, statistical, and numerical in nature | |
| Subjective | Objective | |
| Open-ended questions | Close-ended (Yes or No) or multiple-choice questions | |
| Descriptive and contextual | Quantifiable and generalizable | |
| Limited, only context-dependent findings | High, results applicable to a larger population | |
| Exploratory research method | Conclusive research method | |
| To delve deeper into the topic to understand the underlying theme, patterns, and concepts | To analyze the cause-and-effect relation between the variables to understand a complex phenomenon | |
| Case studies, ethnography, and content analysis | Surveys, experiments, and correlation studies |

Data Collection Methods
There are differences between qualitative and quantitative research when it comes to data collection as they deal with different types of data. Qualitative research is concerned with personal or descriptive accounts to understand human behavior within society. Quantitative research deals with numerical or measurable data to delineate relations among variables. Hence, the qualitative data collection methods differ significantly from quantitative data collection methods due to the nature of data being collected and the research objectives. Below is the list of data collection methods for each research approach:
Qualitative Research Data Collection
- Interviews
- Focus g roups
- Content a nalysis
- Literature review
- Observation
- Ethnography
Qualitative research data collection can involve one-on-one group interviews to capture in-depth perspectives of participants using open-ended questions. These interviews could be structured, semi-structured or unstructured depending upon the nature of the study. Focus groups can be used to explore specific topics and generate rich data through discussions among participants. Another qualitative data collection method is content analysis, which involves systematically analyzing text documents, audio, and video files or visual content to uncover patterns, themes, and meanings. This can be done through coding and categorization of raw data to draw meaningful insights. Data can be collected through observation studies where the goal is to simply observe and document behaviors, interaction, and phenomena in natural settings without interference. Lastly, ethnography allows one to immerse themselves in the culture or environment under study for a prolonged period to gain a deep understanding of the social phenomena.
Quantitative Research Data Collection
- Surveys/ q uestionnaires
- Experiments
- Secondary data analysis
- Structured o bservations
- Case studies
- Tests and a ssessments
Quantitative research data collection approaches comprise of fundamental methods for generating numerical data that can be analyzed using statistical or mathematical tools. The most common quantitative data collection approach is the usage of structured surveys with close-ended questions to collect quantifiable data from a large sample of participants. These can be conducted online, over the phone, or in person.
Performing experiments is another important data collection approach, in which variables are manipulated under controlled conditions to observe their effects on dependent variables. This often involves random assignment of participants to different conditions or groups. Such experimental settings are employed to gauge cause-and-effect relationships and understand a complex phenomenon. At times, instead of acquiring original data, researchers may deal with secondary data, which is the dataset curated by others, such as government agencies, research organizations, or academic institute. With structured observations, subjects in a natural environment can be studied by controlling the variables which aids in understanding the relationship among various variables. The secondary data is then analyzed to identify patterns and relationships among variables. Observational studies provide a means to systematically observe and record behaviors or phenomena as they occur in controlled environments. Case studies form an interesting study methodology in which a researcher studies a single entity or a small number of entities (individuals or organizations) in detail to understand complex phenomena within a specific context.
Qualitative vs Quantitative Research Outcomes
Qualitative research and quantitative research lead to varied research outcomes, each with its own strengths and limitations. For example, qualitative research outcomes provide deep descriptive accounts of human experiences, motivations, and perspectives that allow us to identify themes or narratives and context in which behavior, attitudes, or phenomena occurs. Quantitative research outcomes on the other hand produce numerical data that is analyzed statistically to establish patterns and relationships objectively, to form generalizations about the larger population and make predictions. This numerical data can be presented in the form of graphs, tables, or charts. Both approaches offer valuable perspectives on complex phenomena, with qualitative research focusing on depth and interpretation, while quantitative research emphasizes numerical analysis and objectivity.

When to Use Qualitative vs Quantitative Research Approach
The decision to choose between qualitative and quantitative research depends on various factors, such as the research question, objectives, whether you are taking an inductive or deductive approach, available resources, practical considerations such as time and money, and the nature of the phenomenon under investigation. To simplify, quantitative research can be used if the aim of the research is to prove or test a hypothesis, while qualitative research should be used if the research question is more exploratory and an in-depth understanding of the concepts, behavior, or experiences is needed.
Qualitative research approach
Qualitative research approach is used under following scenarios:
- To study complex phenomena: When the research requires understanding the depth, complexity, and context of a phenomenon.
- Collecting participant perspectives: When the goal is to understand the why behind a certain behavior, and a need to capture subjective experiences and perceptions of participants.
- Generating hypotheses or theories: When generating hypotheses, theories, or conceptual frameworks based on exploratory research.
Example: If you have a research question “What obstacles do expatriate students encounter when acquiring a new language in their host country?”
This research question can be addressed using the qualitative research approach by conducting in-depth interviews with 15-25 expatriate university students. Ask open-ended questions such as “What are the major challenges you face while attempting to learn the new language?”, “Do you find it difficult to learn the language as an adult?”, and “Do you feel practicing with a native friend or colleague helps the learning process”?
Based on the findings of these answers, a follow-up questionnaire can be planned to clarify things. Next step will be to transcribe all interviews using transcription software and identify themes and patterns.
Quantitative research approach
Quantitative research approach is used under following scenarios:
- Testing hypotheses or proving theories: When aiming to test hypotheses, establish relationships, or examine cause-and-effect relationships.
- Generalizability: When needing findings that can be generalized to broader populations using large, representative samples.
- Statistical analysis: When requiring rigorous statistical analysis to quantify relationships, patterns, or trends in data.
Example : Considering the above example, you can conduct a survey of 200-300 expatriate university students and ask them specific questions such as: “On a scale of 1-10 how difficult is it to learn a new language?”
Next, statistical analysis can be performed on the responses to draw conclusions like, on an average expatriate students rated the difficulty of learning a language 6.5 on the scale of 10.
Mixed methods approach
In many cases, researchers may opt for a mixed methods approach , combining qualitative and quantitative methods to leverage the strengths of both approaches. Researchers may use qualitative data to explore phenomena in-depth and generate hypotheses, while quantitative data can be used to test these hypotheses and generalize findings to broader populations.
Example: Both qualitative and quantitative research methods can be used in combination to address the above research question. Through open-ended questions you can gain insights about different perspectives and experiences while quantitative research allows you to test that knowledge and prove/disprove your hypothesis.
How to Analyze Qualitative and Quantitative Data
When it comes to analyzing qualitative and quantitative data, the focus is on identifying patterns in the data to highlight the relationship between elements. The best research method for any given study should be chosen based on the study aim. A few methods to analyze qualitative and quantitative data are listed below.
Analyzing qualitative data
Qualitative data analysis is challenging as it is not expressed in numbers and consists majorly of texts, images, or videos. Hence, care must be taken while using any analytical approach. Some common approaches to analyze qualitative data include:
- Organization: The first step is data (transcripts or notes) organization into different categories with similar concepts, themes, and patterns to find inter-relationships.
- Coding: Data can be arranged in categories based on themes/concepts using coding.
- Theme development: Utilize higher-level organization to group related codes into broader themes.
- Interpretation: Explore the meaning behind different emerging themes to understand connections. Use different perspectives like culture, environment, and status to evaluate emerging themes.
- Reporting: Present findings with quotes or excerpts to illustrate key themes.
Analyzing quantitative data
Quantitative data analysis is more direct compared to qualitative data as it primarily deals with numbers. Data can be evaluated using simple math or advanced statistics (descriptive or inferential). Some common approaches to analyze quantitative data include:
- Processing raw data: Check missing values, outliers, or inconsistencies in raw data.
- Descriptive statistics: Summarize data with means, standard deviations, or standard error using programs such as Excel, SPSS, or R language.
- Exploratory data analysis: Usage of visuals to deduce patterns and trends.
- Hypothesis testing: Apply statistical tests to find significance and test hypothesis (Student’s t-test or ANOVA).
- Interpretation: Analyze results considering significance and practical implications.
- Validation: Data validation through replication or literature review.
- Reporting: Present findings by means of tables, figures, or graphs.

Benefits and limitations of qualitative vs quantitative research
There are significant differences between qualitative and quantitative research; we have listed the benefits and limitations of both methods below:
Benefits of qualitative research
- Rich insights: As qualitative research often produces information-rich data, it aids in gaining in-depth insights into complex phenomena, allowing researchers to explore nuances and meanings of the topic of study.
- Flexibility: One of the most important benefits of qualitative research is flexibility in acquiring and analyzing data that allows researchers to adapt to the context and explore more unconventional aspects.
- Contextual understanding: With descriptive and comprehensive data, understanding the context in which behaviors or phenomena occur becomes accessible.
- Capturing different perspectives: Qualitative research allows for capturing different participant perspectives with open-ended question formats that further enrich data.
- Hypothesis/theory generation: Qualitative research is often the first step in generating theory/hypothesis, which leads to future investigation thereby contributing to the field of research.
Limitations of qualitative research
- Subjectivity: It is difficult to have objective interpretation with qualitative research, as research findings might be influenced by the expertise of researchers. The risk of researcher bias or interpretations affects the reliability and validity of the results.
- Limited generalizability: Due to the presence of small, non-representative samples, the qualitative data cannot be used to make generalizations to a broader population.
- Cost and time intensive: Qualitative data collection can be time-consuming and resource-intensive, therefore, it requires strategic planning and commitment.
- Complex analysis: Analyzing qualitative data needs specialized skills and techniques, hence, it’s challenging for researchers without sufficient training or experience.
- Potential misinterpretation: There is a risk of sampling bias and misinterpretation in data collection and analysis if researchers lack cultural or contextual understanding.
Benefits of quantitative research
- Objectivity: A key benefit of quantitative research approach, this objectivity reduces researcher bias and subjectivity, enhancing the reliability and validity of findings.
- Generalizability: For quantitative research, the sample size must be large and representative enough to allow for generalization to broader populations.
- Statistical analysis: Quantitative research enables rigorous statistical analysis (increasing power of the analysis), aiding hypothesis testing and finding patterns or relationship among variables.
- Efficiency: Quantitative data collection and analysis is usually more efficient compared to the qualitative methods, especially when dealing with large datasets.
- Clarity and Precision: The findings are usually clear and precise, making it easier to present them as graphs, tables, and figures to convey them to a larger audience.
Limitations of quantitative research
- Lacks depth and details: Due to its objective nature, quantitative research might lack the depth and richness of qualitative approaches, potentially overlooking important contextual factors or nuances.
- Limited exploration: By not considering the subjective experiences of participants in depth , there’s a limited chance to study complex phenomenon in detail.
- Potential oversimplification: Quantitative research may oversimplify complex phenomena by boiling them down to numbers, which might ignore key nuances.
- Inflexibility: Quantitative research deals with predecided varibales and measures , which limits the ability of researchers to explore unexpected findings or adjust the research design as new findings become available .
- Ethical consideration: Quantitative research may raise ethical concerns especially regarding privacy, informed consent, and the potential for harm, when dealing with sensitive topics or vulnerable populations.
Frequently asked questions
- What is the difference between qualitative and quantitative research?
Quantitative methods use numerical data and statistical analysis for objective measurement and hypothesis testing, emphasizing generalizability. Qualitative methods gather non-numerical data to explore subjective experiences and contexts, providing rich, nuanced insights.
- What are the types of qualitative research?
Qualitative research methods include interviews, observations, focus groups, and case studies. They provide rich insights into participants’ perspectives and behaviors within their contexts, enabling exploration of complex phenomena.
- What are the types of quantitative research?
Quantitative research methods include surveys, experiments, observations, correlational studies, and longitudinal research. They gather numerical data for statistical analysis, aiming for objectivity and generalizability.
- Can you give me examples for qualitative and quantitative research?
Qualitative Research Example:
Research Question: What are the experiences of parents with autistic children in accessing support services?
Method: Conducting in-depth interviews with parents to explore their perspectives, challenges, and needs.
Quantitative Research Example:
Research Question: What is the correlation between sleep duration and academic performance in college students?
Method: Distributing surveys to a large sample of college students to collect data on their sleep habits and academic performance, then analyzing the data statistically to determine any correlations.
Researcher.Life is a subscription-based platform that unifies the best AI tools and services designed to speed up, simplify, and streamline every step of a researcher’s journey. The Researcher.Life All Access Pack is a one-of-a-kind subscription that unlocks full access to an AI writing assistant, literature recommender, journal finder, scientific illustration tool, and exclusive discounts on professional publication services from Editage.
Based on 21+ years of experience in academia, Researcher.Life All Access empowers researchers to put their best research forward and move closer to success. Explore our top AI Tools pack, AI Tools + Publication Services pack, or Build Your Own Plan. Find everything a researcher needs to succeed, all in one place – Get All Access now starting at just $17 a month !
Related Posts

Take Top AI Tools for Researchers for a Spin with the Editage All Access 7-Day Pass!

Thesis Defense: How to Ace this Crucial Step
Qualitative vs Quantitative Research 101
A plain-language explanation (with examples).
By: Kerryn Warren (PhD, MSc, BSc) | June 2020
So, it’s time to decide what type of research approach you’re going to use – qualitative or quantitative . And, chances are, you want to choose the one that fills you with the least amount of dread. The engineers may be keen on quantitative methods because they loathe interacting with human beings and dealing with the “soft” stuff and are far more comfortable with numbers and algorithms. On the other side, the anthropologists are probably more keen on qualitative methods because they literally have the opposite fears.

However, when justifying your research, “being afraid” is not a good basis for decision making. Your methodology needs to be informed by your research aims and objectives , not your comfort zone. Plus, it’s quite common that the approach you feared (whether qualitative or quantitative) is actually not that big a deal. Research methods can be learnt (usually a lot faster than you think) and software reduces a lot of the complexity of both quantitative and qualitative data analysis. Conversely, choosing the wrong approach and trying to fit a square peg into a round hole is going to create a lot more pain.
In this post, I’ll explain the qualitative vs quantitative choice in straightforward, plain language with loads of examples. This won’t make you an expert in either, but it should give you a good enough “big picture” understanding so that you can make the right methodological decision for your research.
Qualitative vs Quantitative: Overview
- Qualitative analysis 101
- Quantitative analysis 101
- How to choose which one to use
- Data collection and analysis for qualitative and quantitative research
- The pros and cons of both qualitative and quantitative research
- A quick word on mixed methods
Qualitative Research 101: The Basics
The bathwater is hot.
Let us unpack that a bit. What does that sentence mean? And is it useful?
The answer is: well, it depends. If you’re wanting to know the exact temperature of the bath, then you’re out of luck. But, if you’re wanting to know how someone perceives the temperature of the bathwater, then that sentence can tell you quite a bit if you wear your qualitative hat .
Many a husband and wife have never enjoyed a bath together because of their strongly held, relationship-destroying perceptions of water temperature (or, so I’m told). And while divorce rates due to differences in water-temperature perception would belong more comfortably in “quantitative research”, analyses of the inevitable arguments and disagreements around water temperature belong snugly in the domain of “qualitative research”. This is because qualitative research helps you understand people’s perceptions and experiences by systematically coding and analysing the data .
With qualitative research, those heated disagreements (excuse the pun) may be analysed in several ways. From interviews to focus groups to direct observation (ideally outside the bathroom, of course). You, as the researcher, could be interested in how the disagreement unfolds, or the emotive language used in the exchange. You might not even be interested in the words at all, but in the body language of someone who has been forced one too many times into (what they believe) was scalding hot water during what should have been a romantic evening. All of these “softer” aspects can be better understood with qualitative research.
In this way, qualitative research can be incredibly rich and detailed , and is often used as a basis to formulate theories and identify patterns. In other words, it’s great for exploratory research (for example, where your objective is to explore what people think or feel), as opposed to confirmatory research (for example, where your objective is to test a hypothesis). Qualitative research is used to understand human perception , world view and the way we describe our experiences. It’s about exploring and understanding a broad question, often with very few preconceived ideas as to what we may find.
But that’s not the only way to analyse bathwater, of course…

Quantitative Research 101: The Basics
The bathwater is 45 degrees Celsius.
Now, what does this mean? How can this be used?
I was once told by someone to whom I am definitely not married that he takes regular cold showers. As a person who is terrified of anything that isn’t body temperature or above, this seemed outright ludicrous. But this raises a question: what is the perfect temperature for a bath? Or at least, what is the temperature of people’s baths more broadly? (Assuming, of course, that they are bathing in water that is ideal to them). To answer this question, you need to now put on your quantitative hat .
If we were to ask 100 people to measure the temperature of their bathwater over the course of a week, we could get the average temperature for each person. Say, for instance, that Jane averages at around 46.3°C. And Billy averages around 42°C. A couple of people may like the unnatural chill of 30°C on the average weekday. And there will be a few of those striving for the 48°C that is apparently the legal limit in England (now, there’s a useless fact for you).
With a quantitative approach, this data can be analysed in heaps of ways. We could, for example, analyse these numbers to find the average temperature, or look to see how much these temperatures vary. We could see if there are significant differences in ideal water temperature between the sexes, or if there is some relationship between ideal bath water temperature and age! We could pop this information onto colourful, vibrant graphs , and use fancy words like “significant”, “correlation” and “eigenvalues”. The opportunities for nerding out are endless…
In this way, quantitative research often involves coming into your research with some level of understanding or expectation regarding the outcome, usually in the form of a hypothesis that you want to test. For example:
Hypothesis: Men prefer bathing in lower temperature water than women do.
This hypothesis can then be tested using statistical analysis. The data may suggest that the hypothesis is sound, or it may reveal that there are some nuances regarding people’s preferences. For example, men may enjoy a hotter bath on certain days.
So, as you can see, qualitative and quantitative research each have their own purpose and function. They are, quite simply, different tools for different jobs .
Need a helping hand?
Qualitative vs Quantitative Research: Which one should you use?
And here I become annoyingly vague again. The answer: it depends. As I alluded to earlier, your choice of research approach depends on what you’re trying to achieve with your research.
If you want to understand a situation with richness and depth , and you don’t have firm expectations regarding what you might find, you’ll likely adopt a qualitative research approach. In other words, if you’re starting on a clean slate and trying to build up a theory (which might later be tested), qualitative research probably makes sense for you.
On the other hand, if you need to test an already-theorised hypothesis , or want to measure and describe something numerically, a quantitative approach will probably be best. For example, you may want to quantitatively test a theory (or even just a hypothesis) that was developed using qualitative research.
Basically, this means that your research approach should be chosen based on your broader research aims , objectives and research questions . If your research is exploratory and you’re unsure what findings may emerge, qualitative research allows you to have open-ended questions and lets people and subjects speak, in some ways, for themselves. Quantitative questions, on the other hand, will not. They’ll often be pre-categorised, or allow you to insert a numeric response. Anything that requires measurement , using a scale, machine or… a thermometer… is going to need a quantitative method.
Let’s look at an example.
Say you want to ask people about their bath water temperature preferences. There are many ways you can do this, using a survey or a questionnaire – here are 3 potential options:
- How do you feel about your spouse’s bath water temperature preference? (Qualitative. This open-ended question leaves a lot of space so that the respondent can rant in an adequate manner).
- What is your preferred bath water temperature? (This one’s tricky because most people don’t know or won’t have a thermometer, but this is a quantitative question with a directly numerical answer).
- Most people who have commented on your bath water temperature have said the following (choose most relevant): It’s too hot. It’s just right. It’s too cold. (Quantitative, because you can add up the number of people who responded in each way and compare them).
The answers provided can be used in a myriad of ways, but, while quantitative responses are easily summarised through counting or calculations, categorised and visualised, qualitative responses need a lot of thought and are re-packaged in a way that tries not to lose too much meaning.
")
Qualitative vs Quantitative Research: Data collection and analysis
The approach to collecting and analysing data differs quite a bit between qualitative and quantitative research.
A qualitative research approach often has a small sample size (i.e. a small number of people researched) since each respondent will provide you with pages and pages of information in the form of interview answers or observations. In our water perception analysis, it would be super tedious to watch the arguments of 50 couples unfold in front of us! But 6-10 would be manageable and would likely provide us with interesting insight into the great bathwater debate.
To sum it up, data collection in qualitative research involves relatively small sample sizes but rich and detailed data.
On the other side, quantitative research relies heavily on the ability to gather data from a large sample and use it to explain a far larger population (this is called “generalisability”). In our bathwater analysis, we would need data from hundreds of people for us to be able to make a universal statement (i.e. to generalise), and at least a few dozen to be able to identify a potential pattern. In terms of data collection, we’d probably use a more scalable tool such as an online survey to gather comparatively basic data.
So, compared to qualitative research, data collection for quantitative research involves large sample sizes but relatively basic data.
Both research approaches use analyses that allow you to explain, describe and compare the things that you are interested in. While qualitative research does this through an analysis of words, texts and explanations, quantitative research does this through reducing your data into numerical form or into graphs.
There are dozens of potential analyses which each uses. For example, qualitative analysis might look at the narration (the lamenting story of love lost through irreconcilable water toleration differences), or the content directly (the words of blame, heat and irritation used in an interview). Quantitative analysis may involve simple calculations for averages , or it might involve more sophisticated analysis that assesses the relationships between two or more variables (for example, personality type and likelihood to commit a hot water-induced crime). We discuss the many analysis options other blog posts, so I won’t bore you with the details here.

Qualitative vs Quantitative Research: The pros & cons on both sides
Quantitative and qualitative research fundamentally ask different kinds of questions and often have different broader research intentions. As I said earlier, they are different tools for different jobs – so we can’t really pit them off against each other. Regardless, they still each have their pros and cons.
Let’s start with qualitative “pros”
Qualitative research allows for richer , more insightful (and sometimes unexpected) results. This is often what’s needed when we want to dive deeper into a research question . When we want to find out what and how people are thinking and feeling , qualitative is the tool for the job. It’s also important research when it comes to discovery and exploration when you don’t quite know what you are looking for. Qualitative research adds meat to our understanding of the world and is what you’ll use when trying to develop theories.
Qualitative research can be used to explain previously observed phenomena , providing insights that are outside of the bounds of quantitative research, and explaining what is being or has been previously observed. For example, interviewing someone on their cold-bath-induced rage can help flesh out some of the finer (and often lost) details of a research area. We might, for example, learn that some respondents link their bath time experience to childhood memories where hot water was an out of reach luxury. This is something that would never get picked up using a quantitative approach.
There are also a bunch of practical pros to qualitative research. A small sample size means that the researcher can be more selective about who they are approaching. Linked to this is affordability . Unless you have to fork out huge expenses to observe the hunting strategies of the Hadza in Tanzania, then qualitative research often requires less sophisticated and expensive equipment for data collection and analysis.

Qualitative research also has its “cons”:
A small sample size means that the observations made might not be more broadly applicable. This makes it difficult to repeat a study and get similar results. For instance, what if the people you initially interviewed just happened to be those who are especially passionate about bathwater. What if one of your eight interviews was with someone so enraged by a previous experience of being run a cold bath that she dedicated an entire blog post to using this obscure and ridiculous example?
But sample is only one caveat to this research. A researcher’s bias in analysing the data can have a profound effect on the interpretation of said data. In this way, the researcher themselves can limit their own research. For instance, what if they didn’t think to ask a very important or cornerstone question because of previously held prejudices against the person they are interviewing?
Adding to this, researcher inexperience is an additional limitation . Interviewing and observing are skills honed in over time. If the qualitative researcher is not aware of their own biases and limitations, both in the data collection and analysis phase, this could make their research very difficult to replicate, and the theories or frameworks they use highly problematic.
Qualitative research takes a long time to collect and analyse data from a single source. This is often one of the reasons sample sizes are pretty small. That one hour interview? You are probably going to need to listen to it a half a dozen times. And read the recorded transcript of it a half a dozen more. Then take bits and pieces of the interview and reformulate and categorize it, along with the rest of the interviews.

Now let’s turn to quantitative “pros”:
Even simple quantitative techniques can visually and descriptively support or reject assumptions or hypotheses . Want to know the percentage of women who are tired of cold water baths? Boom! Here is the percentage, and a pie chart. And the pie chart is a picture of a real pie in order to placate the hungry, angry mob of cold-water haters.
Quantitative research is respected as being objective and viable . This is useful for supporting or enforcing public opinion and national policy. And if the analytical route doesn’t work, the remainder of the pie can be thrown at politicians who try to enforce maximum bath water temperature standards. Clear, simple, and universally acknowledged. Adding to this, large sample sizes, calculations of significance and half-eaten pies, don’t only tell you WHAT is happening in your data, but the likelihood that what you are seeing is real and repeatable in future research. This is an important cornerstone of the scientific method.
Quantitative research can be pretty fast . The method of data collection is faster on average: for instance, a quantitative survey is far quicker for the subject than a qualitative interview. The method of data analysis is also faster on average. In fact, if you are really fancy, you can code and automate your analyses as your data comes in! This means that you don’t necessarily have to worry about including a long analysis period into your research time.
Lastly – sometimes, not always, quantitative research may ensure a greater level of anonymity , which is an important ethical consideration . A survey may seem less personally invasive than an interview, for instance, and this could potentially also lead to greater honesty. Of course, this isn’t always the case. Without a sufficient sample size, respondents can still worry about anonymity – for example, a survey within a small department.

But there are also quantitative “cons”:
Quantitative research can be comparatively reductive – in other words, it can lead to an oversimplification of a situation. Because quantitative analysis often focuses on the averages and the general relationships between variables, it tends to ignore the outliers. Why is that one person having an ice bath once a week? With quantitative research, you might never know…
It requires large sample sizes to be used meaningfully. In order to claim that your data and results are meaningful regarding the population you are studying, you need to have a pretty chunky dataset. You need large numbers to achieve “statistical power” and “statistically significant” results – often those large sample sizes are difficult to achieve, especially for budgetless or self-funded research such as a Masters dissertation or thesis.
Quantitative techniques require a bit of practice and understanding (often more understanding than most people who use them have). And not just to do, but also to read and interpret what others have done, and spot the potential flaws in their research design (and your own). If you come from a statistics background, this won’t be a problem – but most students don’t have this luxury.
Finally, because of the assumption of objectivity (“it must be true because its numbers”), quantitative researchers are less likely to interrogate and be explicit about their own biases in their research. Sample selection, the kinds of questions asked, and the method of analysis are all incredibly important choices, but they tend to not be given as much attention by researchers, exactly because of the assumption of objectivity.

Mixed methods: a happy medium?
Some of the richest research I’ve seen involved a mix of qualitative and quantitative research. Quantitative research allowed the researcher to paint “birds-eye view” of the issue or topic, while qualitative research enabled a richer understanding. This is the essence of mixed-methods research – it tries to achieve the best of both worlds .
In practical terms, this can take place by having open-ended questions as a part of your research survey. It can happen by having a qualitative separate section (like several interviews) to your otherwise quantitative research (an initial survey, from which, you could invite specific interviewees). Maybe it requires observations: some of which you expect to see, and can easily record, classify and quantify, and some of which are novel, and require deeper description.
A word of warning – just like with choosing a qualitative or quantitative research project, mixed methods should be chosen purposefully , where the research aims, objectives and research questions drive the method chosen. Don’t choose a mixed-methods approach just because you’re unsure of whether to use quantitative or qualitative research. Pulling off mixed methods research well is not an easy task, so approach with caution!
Recap: Qualitative vs Quantitative Research
So, just to recap what we have learned in this post about the great qual vs quant debate:
- Qualitative research is ideal for research which is exploratory in nature (e.g. formulating a theory or hypothesis), whereas quantitative research lends itself to research which is more confirmatory (e.g. hypothesis testing)
- Qualitative research uses data in the form of words, phrases, descriptions or ideas. It is time-consuming and therefore only has a small sample size .
- Quantitative research uses data in the form of numbers and can be visualised in the form of graphs. It requires large sample sizes to be meaningful.
- Your choice in methodology should have more to do with the kind of question you are asking than your fears or previously-held assumptions.
- Mixed methods can be a happy medium, but should be used purposefully.
- Bathwater temperature is a contentious and severely under-studied research topic.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
You Might Also Like:

It was helpful

thanks much it has given me an inside on research. i still have issue coming out with my methodology from the topic below: strategies for the improvement of infastructure resilience to natural phenomena
Trackbacks/Pingbacks
- What Is Research Methodology? Simple Definition (With Examples) - Grad Coach - […] Qualitative, quantitative and mixed-methods are different types of methodologies, distinguished by whether they focus on words, numbers or both. This…
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly
A behind-the-scenes blog about research methods at Pew Research Center. For our latest findings, visit pewresearch.org .
- Data Science
How quantitative methods can supplement a qualitative approach when working with focus groups

(Related post: How focus groups informed our study about nationalism and international engagement in the U.S. and UK )
Pew Research Center often collects data through nationally representative surveys, and we use focus groups to supplement those findings in interesting ways and inform the questionnaire design process for future work.
When conducting focus groups, we typically use qualitative methods to understand what our participants are thinking. For example, we tend to hand-code key themes that come up in discussions. But in our latest focus group project, we wondered if we could use quantitative methods, such as topic models, to save time while still gaining valuable insights about questionnaire development.
Some of these methods worked well, others less so. But all of them helped us understand how to approach text-based data in innovative ways. In general, we found that quantitative analysis of focus group transcripts can generate quick, text-based summary findings and help with questionnaire development. But it proved less useful for mimicking traditional focus group analysis and reporting, at least with the specific quantitative techniques we tried.
In the fall of 2019, the Center held focus groups in the United States and United Kingdom to talk with people about their attitudes toward globalization . These discussions focused on three different contexts: participants’ local community, their nation of residence (U.S. or UK) and the international community.
After conducting 26 focus groups across the two nations, we transcribed the discussions into separate files for each group. For our quantitative analysis, we combined all of the files into one .csv document where each participant’s responses — whether one word or a short paragraph — corresponded to one row of the spreadsheet. To prepare the text for analysis, we tokenized the data , or split each line into individual words, and further cleaned it by removing punctuation and applying other preprocessing techniques often used in natural language processing.
Preliminary quantitative findings
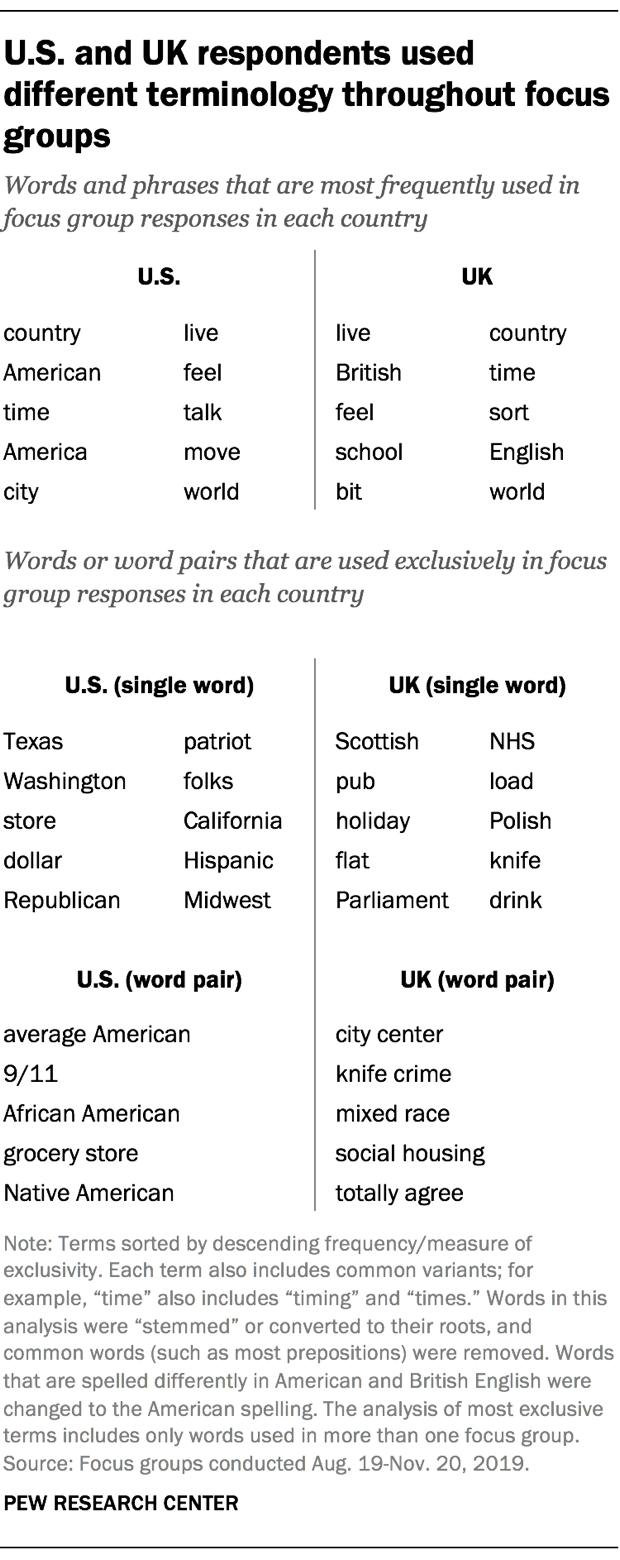
As a first step, we conducted a basic exploration of focus group respondents’ vocabulary. Several words frequently emerged among participants in both the U.S. and UK, including “country,” “live” and “feel,” all of which appeared in at least 250 responses across groups in each country. (This analysis excludes pronouns, articles and prepositions that are common in all spoken English, such as “he,” “she,” “they,” “a,” “the,” “of,” “to,” “from,” etc. Names of cities where focus groups took place and text from group moderators are also excluded from analysis.)
We also found that several words and phrases distinguished the U.S. focus groups from those in the UK. Terms like “dollar” and “Republican” were among the most common terms only used by the American groups, while the UK’s national health system (“NHS”) and legislative body (“parliament”) appeared frequently in the British groups but were never used by Americans.
As an exploratory tool, this kind of analysis can point to linguistic distinctions that stray from the predetermined topics included in a focus group guide. For instance, while we asked the groups in oblique ways about what it takes to be American or British, respectively, we never explicitly asked about immigration or minority groups in their country. Nonetheless, “African Americans” and “Native Americans” exclusively arose in the U.S. groups, while “Polish” and “mixed race” people were discussed in the UK. This told us that it might be worthwhile for future survey questionnaires to explore topics related to race and ethnicity. At the same time, it’s possible that our focus groups may have framed the conversation in a unique way, based on the participants’ racial, ethnic or immigration background.
Word correlations

We used another computational tool, pairwise correlation , for some exploratory text analysis that measures how often words co-occur compared with how often they are used separately. Using three terms related to key themes that the focus groups were designed to study — “global,” “proud” and “immigrant” — we can get a sense of how focus group participants talked about these themes simply by identifying other words that were positively correlated with these topical terms. By further filtering these other terms to those that were mainly used in just one country, we can capture unique aspects of American and British views on global issues, national pride and immigration.
Both British and American participants discussed their nationalities when the conversation turned to pride. For instance, the words that most commonly appeared alongside “proud” in each country were “British” and “American,” respectively. (We considered the words “America” and “American” as separate terms, rather than variants of the same term.) Though “proud” among Britons often involved discussion of the word “flag,” “proud” in the U.S. correlated with “military.” Of course, correlation alone does not reflect whether these discussions had positive, negative or neutral connotations.
Discussions about migration and global issues — including “globalization,” which we shortened to “global” in our text processing — also varied across the two countries. When U.S. respondents used the word “immigrant,” they were also likely to use words like “illegal,” “legal,” “come” and “take.” By comparison, Britons who used the term were liable to do so alongside terms like “doctor” or “population.”
British participants used the word “global” alongside terms related to business (“company,” “industry,” “cheaper”) and global warming (“climate”). In the U.S., on the other hand, the discussion about globalization and immigration often accompanied terms like “hurt,” “China,” “benefit” and “take.”
Pew Research Center has conducted several surveys on the topics of migration , climate change and views of China , among others. Our focus groups confirmed that these issues play a part in how individuals see their country’s place in the world, though they also highlight that, in different nations, people approach these topics in distinct ways that may not be immediately evident in traditional survey questions.
Topic models
In recent years, the Center has explored the use of topic models for text-based data analysis. This method finds groups of words that appear alongside one another in a large number of documents (here, focus group responses), and in the process finds topics or themes that appear across multiple documents. In our attempt to quantitatively analyze this set of focus group transcripts, we had somewhat limited success with this approach.
On first pass, we used a probabilistic topic model called latent Dirichlet allocation , or LDA. But LDA often created topics that lacked coherence or split the same concept among multiple topics.
Next we turned to structural topic models (STM), a method that groups words from documents into topics but also incorporates metadata about documents into its classification process. Here, we included a country variable as one such “structural” variable. STM allowed us to set the number of topics in advance but otherwise created the topics without our input. (Models like these are often called “unsupervised machine learning.”) We ran several iterations of the model with varying numbers of potential topics before settling on the final number.
( For more on the Center’s use of topic modeling, see: Making sense of topic models )
Our research team started at 15 topics and then increased the number in increments of five, up to 50 topics. With fewer than 35 topics, many word groupings seemed to encompass more than one topic. With more than 35 topics, several topics that appeared distinct began to split apart across topics. There was no magic number, and researchers with the same data could reasonably come to different conclusions. Ultimately, we settled on a model with 35 topics.
Some of these topics clearly coalesced around a certain concept. For instance, we decided to call Topic 11 “Brexit” because its most common terms included “vote,” “leave,” “Brexit,” “party” and “referendum.” But while this topic and others appeared quite clear conceptually, that was not uniformly the case. For example, one topic looked as though it could relate to crime, but some terms in that topic (e.g., “eat” and “Christian”) did not fit that concept as neatly.

We named some of the topics based on the themes we saw — “Legal immigration,” for example, and “European trade.” But as other researchers have noted, that does not necessarily mean the word groupings are definitely about that theme. In this case, we used topic models as an exploratory analysis tool, and further research would be needed to validate each one with a higher degree of certainty and remove conceptually spurious words .
Another important consideration is that topic models sometimes group topics differently than researchers might be thinking about them. For that reason, topic models shouldn’t be used as a measurement instrument unless researchers take extra care to validate them and confirm their assumptions about what the models are measuring. In this project, the topic models simply served to inform questionnaire development for future multinational surveys. For example, Topic 12 in this experiment touches on issues of how spoken language relates to national identity, and future surveys may include a question that addresses this concept.
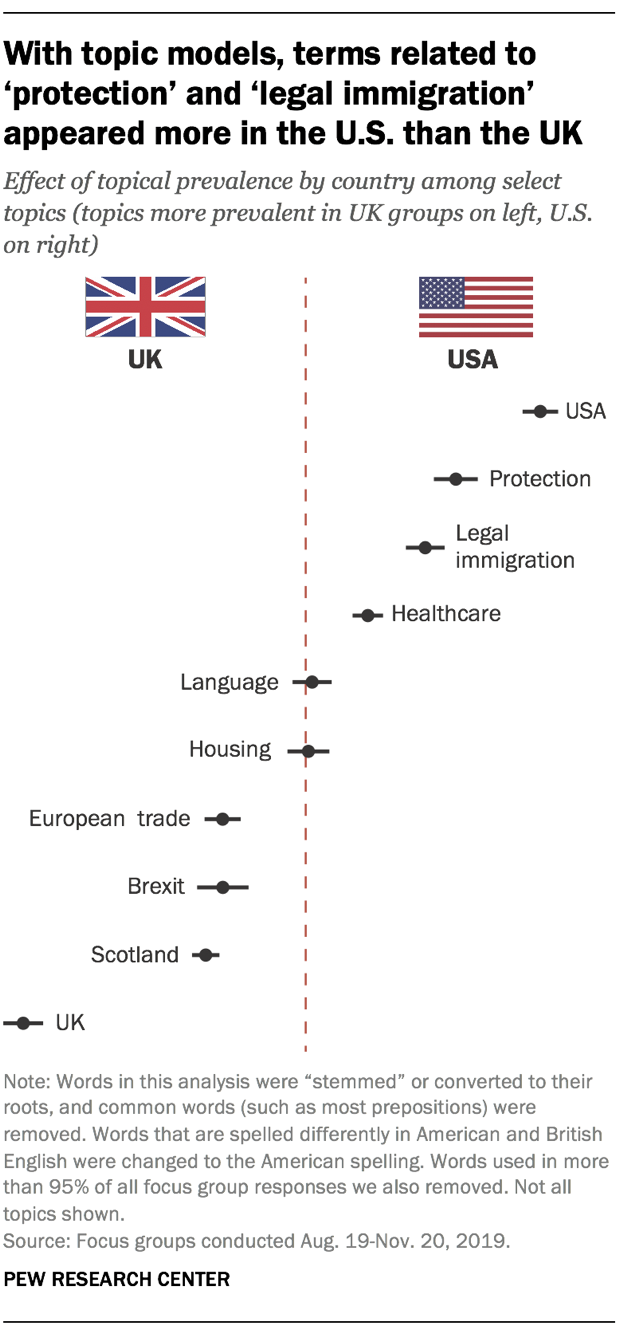
One helpful aspect of the topic model approach is that it allowed us to see which topics were more prevalent in the U.S. or UK, or if they appeared in both. American respondents, for example, more frequently discussed topics related to the U.S. and legal immigration, while British respondents more often discussed topics related to Brexit and trade in Europe. Topics that researchers coded as “language” and “housing” appeared with relatively the same prevalence in both countries.
However, characteristics of the data and problems with initially interpreting topics can cause further difficulties in this analysis. For instance, a topic we labeled “protection” was much more prevalent in American focus group discussions. That might have led us to assume that Americans are more concerned than their British counterparts with safety-related issues. But the focus groups we conducted were not nationally representative of the populations of either country, so we couldn’t draw this type of conclusion from the analysis. Additionally, because the topic itself might include words that have no relation to the concept of protection, researchers would likely need to consult the full transcripts that mention these topics — as well as external resources — before using this for questionnaire development.
Text-based classification
Qualitative coding of focus group transcripts is a resource-intensive process. Researchers who carried out the qualitative analysis of these transcripts considered using a Qualitative Data Analysis Software, or QDAS . These are tools designed for qualitative researchers to analyze all forms of qualitative data, including transcripts, manually assigning text into categories, linking themes and visualizing findings. Many disciplines employ these methods for successfully analyzing qualitative data.
We wondered if quantitative methods would let us achieve similar ends, so we explored ways to potentially streamline procedures with quantitative tools to minimize the time and labor needed to classify text into topics of interest. Unlike with topic models, a text-based classification model uses predetermined topics, or variables, for the algorithm to classify. (This falls into a broader category called “ supervised machine learning .”) A successful classification algorithm would mean that we could avoid having to read every transcript to determine what content belonged to certain groups, or having to make the kind of subjective judgments that are necessary with qualitative software.
We used an extreme gradient boosting model (XGBoost) to classify focus group responses as relevant or not relevant to three different topics: immigration, the economy and the local community. We chose these topics because each emerged in the course of the focus group discussion — some as overt topics from prompts in the focus group guide (e.g., the local community), others as organic themes when people discussed their neighborhoods, national identity and issues of globalization (e.g., immigration and the economy).
Two of our researchers coded the same set of randomly selected focus group responses, about 6% of approximately 13,000 responses from all groups combined. They used a 1 to indicate the response was about a topic and 0 to show it was not. From the set of coded responses, each of the three topics appeared at least 70 times.

The model’s performance proved lackluster. When we compared the model to our hand coding, the accuracy rate ranged from 85% to 93%. But it also failed to identify the topic in most cases where it occurred, meaning that much of the accuracy was driven by matching on instances coded as 0 (i.e. the response is not about that topic) since 0 was much more prevalent across categories. One can liken this to a test for a rare disease. If only 1% of people in a population have a disease and the test returns only negative results to all people tested, the accuracy would be high — 99% of tests would be correct. But the test would have little utility since there would be no positive matches in instances where people were actually infected.
Using a measure similar to accuracy called the kappa , a statistic that examines agreement while adjusting for chance agreement, we found that the classifier performed poorly with a kappa of no more than .37 for two of our topics. In addition, we looked at the models’ precision and recall , metrics that help evaluate the effectiveness of a model. Precision ranged from 20% to 100%, while recall ranged from 4% to 27% among two of the topics. On the third topic — the local community — the model assigned zero to all cases.
The quantitative techniques that we explored in this post do not completely replace a traditional approach to qualitative research with focus group data. Using a quantitative approach, however, can aid in exploratory analysis and refining questionnaire development without having to attend every group in person or read through hundreds of pages of text. The tools we used are far from exhaustive, and as the Center continues to use focus groups as part of the research process, we are hopeful that we can learn more about how to employ innovative techniques in our analysis.
This post benefited from feedback provided by the following Pew Research Center staff: Dennis Quinn, Patrick van Kessel and Adam Hughes.
Categories:
- Qualitative Methods
More from Decoded
Measuring news consumption in a digital era.
As news outlets morph and multiply, both surveys and passive data collection tools face challenges.
Rising share of lawmakers – but few Republicans – are using the term Latinx on social media
One-quarter of United States lawmakers mentioned the term on Facebook or Twitter during the 116th Congress.
Sharp decline in remittances expected in 2020 amid COVID-19 lockdowns in top sending nations
Remittances – money sent by migrants to their home countries – are projected to fall by a record 20% this year.
What is machine learning, and how does it work?
Our latest Methods 101 video explains the basics of machine learning and how it allows our researchers to analyze data on a large scale.
For Global Legislators on Twitter, an Engaged Minority Creates Outsize Share of Content
Although most national officials use the platform, their posts receive only a small number of likes and retweets.
MORe from decoded
To browse all of Pew Research Center findings and data by topic, visit pewresearch.org
About Decoded
This is a blog about research methods and behind-the-scenes technical matters at Pew Research Center. To get our latest findings, visit pewresearch.org .
Copyright 2024 Pew Research Center
Qualitative vs. Quantitative Research: Comparing the Methods and Strategies for Education Research

No matter the field of study, all research can be divided into two distinct methodologies: qualitative and quantitative research. Both methodologies offer education researchers important insights.
Education research assesses problems in policy, practices, and curriculum design, and it helps administrators identify solutions. Researchers can conduct small-scale studies to learn more about topics related to instruction or larger-scale ones to gain insight into school systems and investigate how to improve student outcomes.
Education research often relies on the quantitative methodology. Quantitative research in education provides numerical data that can prove or disprove a theory, and administrators can easily share the number-based results with other schools and districts. And while the research may speak to a relatively small sample size, educators and researchers can scale the results from quantifiable data to predict outcomes in larger student populations and groups.
Qualitative vs. Quantitative Research in Education: Definitions
Although there are many overlaps in the objectives of qualitative and quantitative research in education, researchers must understand the fundamental functions of each methodology in order to design and carry out an impactful research study. In addition, they must understand the differences that set qualitative and quantitative research apart in order to determine which methodology is better suited to specific education research topics.
Generate Hypotheses with Qualitative Research
Qualitative research focuses on thoughts, concepts, or experiences. The data collected often comes in narrative form and concentrates on unearthing insights that can lead to testable hypotheses. Educators use qualitative research in a study’s exploratory stages to uncover patterns or new angles.
Form Strong Conclusions with Quantitative Research
Quantitative research in education and other fields of inquiry is expressed in numbers and measurements. This type of research aims to find data to confirm or test a hypothesis.
Differences in Data Collection Methods
Keeping in mind the main distinction in qualitative vs. quantitative research—gathering descriptive information as opposed to numerical data—it stands to reason that there are different ways to acquire data for each research methodology. While certain approaches do overlap, the way researchers apply these collection techniques depends on their goal.
Interviews, for example, are common in both modes of research. An interview with students that features open-ended questions intended to reveal ideas and beliefs around attendance will provide qualitative data. This data may reveal a problem among students, such as a lack of access to transportation, that schools can help address.
An interview can also include questions posed to receive numerical answers. A case in point: how many days a week do students have trouble getting to school, and of those days, how often is a transportation-related issue the cause? In this example, qualitative and quantitative methodologies can lead to similar conclusions, but the research will differ in intent, design, and form.
Taking a look at behavioral observation, another common method used for both qualitative and quantitative research, qualitative data may consider a variety of factors, such as facial expressions, verbal responses, and body language.
On the other hand, a quantitative approach will create a coding scheme for certain predetermined behaviors and observe these in a quantifiable manner.
Qualitative Research Methods
- Case Studies : Researchers conduct in-depth investigations into an individual, group, event, or community, typically gathering data through observation and interviews.
- Focus Groups : A moderator (or researcher) guides conversation around a specific topic among a group of participants.
- Ethnography : Researchers interact with and observe a specific societal or ethnic group in their real-life environment.
- Interviews : Researchers ask participants questions to learn about their perspectives on a particular subject.
Quantitative Research Methods
- Questionnaires and Surveys : Participants receive a list of questions, either closed-ended or multiple choice, which are directed around a particular topic.
- Experiments : Researchers control and test variables to demonstrate cause-and-effect relationships.
- Observations : Researchers look at quantifiable patterns and behavior.
- Structured Interviews : Using a predetermined structure, researchers ask participants a fixed set of questions to acquire numerical data.
Choosing a Research Strategy
When choosing which research strategy to employ for a project or study, a number of considerations apply. One key piece of information to help determine whether to use a qualitative vs. quantitative research method is which phase of development the study is in.
For example, if a project is in its early stages and requires more research to find a testable hypothesis, qualitative research methods might prove most helpful. On the other hand, if the research team has already established a hypothesis or theory, quantitative research methods will provide data that can validate the theory or refine it for further testing.
It’s also important to understand a project’s research goals. For instance, do researchers aim to produce findings that reveal how to best encourage student engagement in math? Or is the goal to determine how many students are passing geometry? These two scenarios require distinct sets of data, which will determine the best methodology to employ.
In some situations, studies will benefit from a mixed-methods approach. Using the goals in the above example, one set of data could find the percentage of students passing geometry, which would be quantitative. The research team could also lead a focus group with the students achieving success to discuss which techniques and teaching practices they find most helpful, which would produce qualitative data.
Learn How to Put Education Research into Action
Those with an interest in learning how to harness research to develop innovative ideas to improve education systems may want to consider pursuing a doctoral degree. American University’s School of Education online offers a Doctor of Education (EdD) in Education Policy and Leadership that prepares future educators, school administrators, and other education professionals to become leaders who effect positive changes in schools. Courses such as Applied Research Methods I: Enacting Critical Research provides students with the techniques and research skills needed to begin conducting research exploring new ways to enhance education. Learn more about American’ University’s EdD in Education Policy and Leadership .
What’s the Difference Between Educational Equity and Equality?
EdD vs. PhD in Education: Requirements, Career Outlook, and Salary
Top Education Technology Jobs for Doctorate in Education Graduates
American University, EdD in Education Policy and Leadership
Edutopia, “2019 Education Research Highlights”
Formplus, “Qualitative vs. Quantitative Data: 15 Key Differences and Similarities”
iMotion, “Qualitative vs. Quantitative Research: What Is What?”
Scribbr, “Qualitative vs. Quantitative Research”
Simply Psychology, “What’s the Difference Between Quantitative and Qualitative Research?”
Typeform, “A Simple Guide to Qualitative and Quantitative Research”
Request Information
- Request new password
- Create a new account
An Applied Guide to Research Design: Quantitative, Qualitative, and Mixed Methods
Student resources, discussion questions.
- Why is the concept of control not a factor when conducting research with the qualitative method?
- How important is the concept of validity when discussing the qualitative method?
- Develop a hypothetical research scenario that would warrant the application of the case study. What type of approach within the qualitative method would be used? Why or why not?
- Discuss why memoing is an important strategy to utilize with the grounded theory approach.
- Use the companion website and locate a full-text version of any one of the designs under the qualitative method. Did the authors discuss any aspects related to validity? Expand on your answer as to why or not this is an important aspect to the study.
- Develop a hypothetical research scenario that would warrant the application of the grounded theory approach. What type of design would be best utilized along with this approach?
- Develop a hypothetical research scenario that would warrant the application of the ethnographic approach. What type of design would be best utilized along with this approach?
- Develop a hypothetical research scenario that would warrant the application of the narrative approach. What type of design would be best utilized along with this approach?
- Develop a hypothetical research scenario that would warrant the application of the phenomenological approach. What type of design would be best utilized along with this approach?
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
Enter the email address you signed up with and we'll email you a reset link.
- We're Hiring!
- Help Center

Critical discussion between qualitative and quantitative research approaches

2021, UNICAF University - Zambia
Related Papers
Right Magejo
Temitope Idowu
Fernando Almeida
Scientific research adopts qualitative and quantitative methodologies in the modeling and analysis of numerous phenomena. The qualitative methodology intends to understand a complex reality and the meaning of actions in a given context. On the other hand, the quantitative methodology seeks to obtain accurate and reliable measurements that allow a statistical analysis. Both methodologies offer a set of methods, potentialities and limitations that must be explored and known by researchers. This paper concisely maps a total of seven qualitative methods and five quantitative methods. A comparative analysis of the most relevant and adopted methods is done to understand the main strengths and limitations of them. Additionally, the work developed intends to be a fundamental reference for the accomplishment of a research study, in which the researcher intends to adopt a qualitative or quantitative methodology. Through the analysis of the advantages and disadvantages of each method, it becomes possible to formulate a more accurate, informed and complete choice.
Munyaradzi Moyo
Kirathe Wanjiku
UNICAF University - Zambia
Ivan Steenkamp
Anang Mardani
The following 8-point definition is adapted from Cobb and Hagermaster (1987): 1. Importance of context There is attention to the social context in which events occur and have meaning. According to qualitative researchers, this is because events can only be properly understood in context. Contrast this feature with the approach of the quantitative researcher who treats the context as a distraction, a source of error, that is, something that has to be controlled. 2. Emic view of the world There is an emphasis on understanding the social world from the point of view of the participants in it. This is known as an emic point of view. With quantitative methods the researcher is not interested in how subjects see the world except in relation to the variables that are being measured. This is known as an etic point of view. 3. Inductive approach The approach is primarily inductive which means the researcher develops a hunch while in the field and systematically looks for evidence to confirming or refute it. By way of contrast, in quantitative studies the researcher uses theory and empirical research to develop a small number of propositions. In other words, the conclusion of the study is deduced from the theory and experimental or quasi-experimental evidence. 4. Interaction with participants Common data collection procedures include interviewing, participant observation, examination of personal documents and other printed materials. The researcher personally interacts with participants. 5. Focus on understanding and description The concern is primarily with understanding and description rather than explanations based on causal relationships. Understanding, according to qualitative researchers, need not be reduced to a series of statements about causal relationships. 6. Ongoing development of hypotheses Hypotheses are usually developed during the research rather than a priori. The reason for this is simple: the researcher develops a better understanding of the phenomenon being studied the longer they stay in the field. 7. Ongoing development of instruments Procedures for data gathering are subject to ongoing revision in the field. These can't be developed until the hypotheses have been formulated. 8. Narrative form Analysis is usually presented in narrative rather than in numerical form.
Tracie Seidelman
Loading Preview
Sorry, preview is currently unavailable. You can download the paper by clicking the button above.
RELATED PAPERS
M.Lib.I.Sc. Project, Panjab University, under guidance of Dr. Shiv Kumar
SUBHAJIT PANDA
Jennifer Chase
Rachel Irish Kozicki
Tinashe Paul
Abey Dubale
Symeou, L. & Lamprianou, J.
Loizos Symeou , Iasonas Lamprianou
Sufrida Fida
Psychology Lover
IRJET Journal
mubashar yaqoob
Rajib Timalsina
SEID A H M E D MUHE
Yuanita Damayanti
Pattamawan Jimarkon
Evaluation and Program Planning
Souraya Sidani
Nguyen Tran
Nathan Neal
IJIP Journal
Darya Lebedeva
Journal of African Interdisciplinary Studies
Ronald Mensah
Evidence Based Nursing
temitope oludoun
Dr. Purnima Trivedi
Josiane A Parrouty
Robert Eppel
RELATED TOPICS
- We're Hiring!
- Help Center
- Find new research papers in:
- Health Sciences
- Earth Sciences
- Cognitive Science
- Mathematics
- Computer Science
- Academia ©2024

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Perspect Clin Res
- v.14(1); Jan-Mar 2023
- PMC10003579
Introduction to qualitative research methods – Part I
Shagufta bhangu.
Department of Global Health and Social Medicine, King's College London, London, United Kingdom
Fabien Provost
Carlo caduff.
Qualitative research methods are widely used in the social sciences and the humanities, but they can also complement quantitative approaches used in clinical research. In this article, we discuss the key features and contributions of qualitative research methods.
INTRODUCTION
Qualitative research methods refer to techniques of investigation that rely on nonstatistical and nonnumerical methods of data collection, analysis, and evidence production. Qualitative research techniques provide a lens for learning about nonquantifiable phenomena such as people's experiences, languages, histories, and cultures. In this article, we describe the strengths and role of qualitative research methods and how these can be employed in clinical research.
Although frequently employed in the social sciences and humanities, qualitative research methods can complement clinical research. These techniques can contribute to a better understanding of the social, cultural, political, and economic dimensions of health and illness. Social scientists and scholars in the humanities rely on a wide range of methods, including interviews, surveys, participant observation, focus groups, oral history, and archival research to examine both structural conditions and lived experience [ Figure 1 ]. Such research can not only provide robust and reliable data but can also humanize and add richness to our understanding of the ways in which people in different parts of the world perceive and experience illness and how they interact with medical institutions, systems, and therapeutics.

Examples of qualitative research techniques
Qualitative research methods should not be seen as tools that can be applied independently of theory. It is important for these tools to be based on more than just method. In their research, social scientists and scholars in the humanities emphasize social theory. Departing from a reductionist psychological model of individual behavior that often blames people for their illness, social theory focuses on relations – disease happens not simply in people but between people. This type of theoretically informed and empirically grounded research thus examines not just patients but interactions between a wide range of actors (e.g., patients, family members, friends, neighbors, local politicians, medical practitioners at all levels, and from many systems of medicine, researchers, policymakers) to give voice to the lived experiences, motivations, and constraints of all those who are touched by disease.
PHILOSOPHICAL FOUNDATIONS OF QUALITATIVE RESEARCH METHODS
In identifying the factors that contribute to the occurrence and persistence of a phenomenon, it is paramount that we begin by asking the question: what do we know about this reality? How have we come to know this reality? These two processes, which we can refer to as the “what” question and the “how” question, are the two that all scientists (natural and social) grapple with in their research. We refer to these as the ontological and epistemological questions a research study must address. Together, they help us create a suitable methodology for any research study[ 1 ] [ Figure 2 ]. Therefore, as with quantitative methods, there must be a justifiable and logical method for understanding the world even for qualitative methods. By engaging with these two dimensions, the ontological and the epistemological, we open a path for learning that moves away from commonsensical understandings of the world, and the perpetuation of stereotypes and toward robust scientific knowledge production.

Developing a research methodology
Every discipline has a distinct research philosophy and way of viewing the world and conducting research. Philosophers and historians of science have extensively studied how these divisions and specializations have emerged over centuries.[ 1 , 2 , 3 ] The most important distinction between quantitative and qualitative research techniques lies in the nature of the data they study and analyze. While the former focus on statistical, numerical, and quantitative aspects of phenomena and employ the same in data collection and analysis, qualitative techniques focus on humanistic, descriptive, and qualitative aspects of phenomena.[ 4 ]
For the findings of any research study to be reliable, they must employ the appropriate research techniques that are uniquely tailored to the phenomena under investigation. To do so, researchers must choose techniques based on their specific research questions and understand the strengths and limitations of the different tools available to them. Since clinical work lies at the intersection of both natural and social phenomena, it means that it must study both: biological and physiological phenomena (natural, quantitative, and objective phenomena) and behavioral and cultural phenomena (social, qualitative, and subjective phenomena). Therefore, clinical researchers can gain from both sets of techniques in their efforts to produce medical knowledge and bring forth scientifically informed change.
KEY FEATURES AND CONTRIBUTIONS OF QUALITATIVE RESEARCH METHODS
In this section, we discuss the key features and contributions of qualitative research methods [ Figure 3 ]. We describe the specific strengths and limitations of these techniques and discuss how they can be deployed in scientific investigations.

Key features of qualitative research methods
One of the most important contributions of qualitative research methods is that they provide rigorous, theoretically sound, and rational techniques for the analysis of subjective, nebulous, and difficult-to-pin-down phenomena. We are aware, for example, of the role that social factors play in health care but find it hard to qualify and quantify these in our research studies. Often, we find researchers basing their arguments on “common sense,” developing research studies based on assumptions about the people that are studied. Such commonsensical assumptions are perhaps among the greatest impediments to knowledge production. For example, in trying to understand stigma, surveys often make assumptions about its reasons and frequently associate it with vague and general common sense notions of “fear” and “lack of information.” While these may be at work, to make such assumptions based on commonsensical understandings, and without conducting research inhibit us from exploring the multiple social factors that are at work under the guise of stigma.
In unpacking commonsensical understandings and researching experiences, relationships, and other phenomena, qualitative researchers are assisted by their methodological commitment to open-ended research. By open-ended research, we mean that these techniques take on an unbiased and exploratory approach in which learnings from the field and from research participants, are recorded and analyzed to learn about the world.[ 5 ] This orientation is made possible by qualitative research techniques that are particularly effective in learning about specific social, cultural, economic, and political milieus.
Second, qualitative research methods equip us in studying complex phenomena. Qualitative research methods provide scientific tools for exploring and identifying the numerous contributing factors to an occurrence. Rather than establishing one or the other factor as more important, qualitative methods are open-ended, inductive (ground-up), and empirical. They allow us to understand the object of our analysis from multiple vantage points and in its dispersion and caution against predetermined notions of the object of inquiry. They encourage researchers instead to discover a reality that is not yet given, fixed, and predetermined by the methods that are used and the hypotheses that underlie the study.
Once the multiple factors at work in a phenomenon have been identified, we can employ quantitative techniques and embark on processes of measurement, establish patterns and regularities, and analyze the causal and correlated factors at work through statistical techniques. For example, a doctor may observe that there is a high patient drop-out in treatment. Before carrying out a study which relies on quantitative techniques, qualitative research methods such as conversation analysis, interviews, surveys, or even focus group discussions may prove more effective in learning about all the factors that are contributing to patient default. After identifying the multiple, intersecting factors, quantitative techniques can be deployed to measure each of these factors through techniques such as correlational or regression analyses. Here, the use of quantitative techniques without identifying the diverse factors influencing patient decisions would be premature. Qualitative techniques thus have a key role to play in investigations of complex realities and in conducting rich exploratory studies while embracing rigorous and philosophically grounded methodologies.
Third, apart from subjective, nebulous, and complex phenomena, qualitative research techniques are also effective in making sense of irrational, illogical, and emotional phenomena. These play an important role in understanding logics at work among patients, their families, and societies. Qualitative research techniques are aided by their ability to shift focus away from the individual as a unit of analysis to the larger social, cultural, political, economic, and structural forces at work in health. As health-care practitioners and researchers focused on biological, physiological, disease and therapeutic processes, sociocultural, political, and economic conditions are often peripheral or ignored in day-to-day clinical work. However, it is within these latter processes that both health-care practices and patient lives are entrenched. Qualitative researchers are particularly adept at identifying the structural conditions such as the social, cultural, political, local, and economic conditions which contribute to health care and experiences of disease and illness.
For example, the decision to delay treatment by a patient may be understood as an irrational choice impacting his/her chances of survival, but the same may be a result of the patient treating their child's education as a financial priority over his/her own health. While this appears as an “emotional” choice, qualitative researchers try to understand the social and cultural factors that structure, inform, and justify such choices. Rather than assuming that it is an irrational choice, qualitative researchers try to understand the norms and logical grounds on which the patient is making this decision. By foregrounding such logics, stories, fears, and desires, qualitative research expands our analytic precision in learning about complex social worlds, recognizing reasons for medical successes and failures, and interrogating our assumptions about human behavior. These in turn can prove useful in arriving at conclusive, actionable findings which can inform institutional and public health policies and have a very important role to play in any change and transformation we may wish to bring to the societies in which we work.
Financial support and sponsorship
Conflicts of interest.
There are no conflicts of interest.
- Open access
- Published: 25 June 2024
Achieving research impact in medical research through collaboration across organizational boundaries: Insights from a mixed methods study in the Netherlands
- Jacqueline C. F. van Oijen ORCID: orcid.org/0000-0002-5100-0671 1 ,
- Annemieke van Dongen-Leunis 1 ,
- Jeroen Postma 1 ,
- Thed van Leeuwen 2 &
- Roland Bal 1
Health Research Policy and Systems volume 22 , Article number: 72 ( 2024 ) Cite this article
59 Accesses
Metrics details
In the Netherlands, university medical centres (UMCs) bear primary responsibility for conducting medical research and delivering highly specialized care. The TopCare program was a policy experiment lasting 4 years in which three non-academic hospitals received funding from the Dutch Ministry of Health to also conduct medical research and deliver highly specialized care in specific domains. This study investigates research collaboration outcomes for all Dutch UMCs and non-academic hospitals in general and, more specifically, for the domains in the non-academic hospitals participating in the TopCare program. Additionally, it explores the organizational boundary work employed by these hospitals to foster productive research collaborations.
A mixed method research design was employed combining quantitative bibliometric analysis of publications and citations across all Dutch UMCs and non-academic hospitals and the TopCare domains with geographical distances, document analysis and ethnographic interviews with actors in the TopCare program.
Quantitative analysis shows that, over the period of study, international collaboration increased among all hospitals while national collaboration and single institution research declined slightly. Collaborative efforts correlated with higher impact scores, and international collaboration scored higher than national collaboration. A total of 60% of all non-academic hospitals’ publications were produced in collaboration with UMCs, whereas almost 30% of the UMCs’ publications were the result of such collaboration. Non-academic hospitals showed a higher rate of collaboration with the UMC that was nearest geographically, whereas TopCare hospitals prioritized expertise over geographical proximity within their specialized domains. Boundary work mechanisms adopted by TopCare hospitals included aligning research activities with organizational mindset (identity), bolstering research infrastructure (competence) and finding and mobilizing strategic partnerships with academic partners (power). These efforts aimed to establish credibility and attractiveness as collaboration partners.
Conclusions
Research collaboration between non-academic hospitals and UMCs, particularly where this also involves international collaboration, pays off in terms of publications and impact. The TopCare hospitals used the program’s resources to perform boundary work aimed at becoming an attractive and credible collaboration partner for academia. Local factors such as research history, strategic domain focus, in-house expertise, patient flows, infrastructure and network relationships influenced collaboration dynamics within TopCare hospitals and between them and UMCs.
Peer Review reports
Introduction
Research collaboration has taken flight worldwide in recent decades [ 1 ], as reflected by the growing number of authors listed on research papers [ 2 , 3 ]. Collaborative research has become the norm for many, if not most, scientific disciplines [ 4 , 5 , 6 , 7 , 8 ]. Several studies have found a positive relationship between collaboration and output [ 9 , 10 , 11 , 12 , 13 ]. Publications resulting from research collaborations tend to be cited more frequently [ 14 , 15 , 16 , 17 , 18 ] and to be of higher research quality [ 5 , 14 , 19 , 20 ]. In particular, international collaboration can lead to more citations [ 17 , 21 , 22 , 23 , 24 ], although there are major differences internationally and between fields [ 25 ]. Moreover, international collaboration is often set as an eligibility requirement for European research grants, which have become necessary as national-level resources dwindle. Funding consortia also encourage and require boundary crossings, such as research collaborations between academia and societal partners. Collaboration within public research organizations and universities further plays a crucial role in the international dissemination of knowledge [ 26 ].
In the medical domain, initiatives have been rolled out in numerous countries to encourage long-term collaboration and the exchange of knowledge and research findings. Each initiative takes a strategic approach to assembling the processes needed to support these exchanges across the boundaries of stakeholder groups. In the Netherlands, medical research has traditionally been concentrated in public academia, especially the university medical centres (UMCs). Increasingly, however, research activities are being undertaken in non-academic teaching hospitals (hereafter, non-academic hospitals), driven by their changing patterns of patient influx. In 2013, a Dutch study based on citation analysis showed that collaboration between UMCs and non-academic hospitals leads to high-quality research [ 27 ]. There was further encouragement for medical research in Dutch non-academic hospitals in 2014, when a 4-year policy experiment, the TopCare program, was launched, with three such hospitals receiving additional funding from the Ministry of Health to also provide highly specialized care and undertake medical research. Funding for this combination of care and research is available for UMCs under the budgetary “academic component” of the Dutch healthcare system. Such additional funds are not available for non-academic hospitals, nor can they allocate their regular budgets to research. In the past, these hospitals managed to conduct research and provide specialized care through their own financial and time investments, or by securing occasional external research funding. The TopCare policy experiment was thus meant to find new ways of organizing and funding highly specialized care and medical research in non-academic hospitals.
Despite the increasing emphasis on research collaboration, we still know little about its impact and how it can be achieved. This study integrates two sides of research collaboration in Dutch hospitals and combines elements of quantitative and qualitative research for a broad (output and impact) and deep (boundary work to achieve collaboration) understanding of the phenomenon. We define research collaboration as collaboration between two or more organizations (at least one being a UMC or non-academic hospital) that has resulted in a co-authored (joint) scientific publication [ 28 ]. The research questions are: How high is the level of collaboration in the Dutch medical research field, what is the impact of collaboration, and how are productive research collaborations achieved?
To answer these questions, we performed mixed methods research in UMCs and non-academic hospitals. To examine the impact of various collaboration models – namely, single institution, national and international – across all eight Dutch UMCs and 28 non-academic hospitals between 2009 and 2018/2019, we conducted a bibliometric analysis of publications and citations. We additionally carried out a similar analysis for the TopCare non-academic hospitals between 2010 and 2016 to examine the effects of collaboration in the two domains funded through the program at each hospital. The latter timeframe was chosen to match the duration of the program, 2014–2018. We further conducted an in-depth qualitative analysis of the organizational boundary work done by two non-academic hospitals participating in the TopCare program to initiate and enhance productive research collaborations around specialized research and care within and between hospitals on a national level. Historically, such endeavours have been predominantly reserved for UMCs. The program was therefore a unique opportunity to examine such boundary work.
Background and theory
The landscape of medical research in the netherlands, collaboration in medical research.
The Netherlands has a three-tiered hospital system: general hospitals (including non-academic hospitals), specialized hospitals focusing on a specific medical field or patient population, and UMCs. Nowadays, there are 7 UMCs, 17 specialized hospitals and 58 general hospitals, of which 26 are non-academic [ 29 ].
UMCs receive special funding (the budgetary “academic component”) for research and oversee medical training programs in their region. Non-academic hospitals do not receive structural government funding for medical research and have less chance of obtaining other funding because they are not formally acknowledged as knowledge-producing organizations. Research has less priority in most of these hospitals than in UMCs. On the introduction of government policies regarding competition in healthcare and the development of quality guidelines emphasizing high-volume treatments, some non-academic hospitals began focusing on specific disease areas, in a bid to distinguish themselves from other hospitals and to perform research in and hence develop more knowledge about these priority areas. This led to a greater concentration of highly specialized care [ 30 ]. Non-academic hospitals have also become important partners in medical research for UMCs due to their large patient volumes.
The TopCare program
To further stimulate research in non-academic hospitals, the Ministry of Health awarded three such hospitals €28.8 million in funding over a 4-year period (2014–2018) to support medical research and specialized care for which they do not normally receive funding [ 31 ]. It should be noted that, in non-academic hospitals, the concept of highly specialized research and care applies not to the entire hospital but rather to specific departments or disease areas. This is why the TopCare non-academic hospitals have been evaluated on the basis of specific domains. The funding recipients were two non-academic hospitals and one specialized hospital. In this article, we focus on UMCs and general non-academic hospitals and therefore excluded the specialized hospital from our analysis. Hospital #1 is the largest non-academic hospital in the Netherlands (1100 beds), even larger than some UMCs. Its fields of excellence (known as “domains”) are lung and heart care. Hospital #2 is a large non-academic hospital (950 beds) that focuses on emergency care and neurology. According to the two hospitals, these four highly specialized care and research-intensive domains are comparable to high-complexity care and research in UMCs [ 31 ].
The TopCare program ran through ZonMw, the Netherlands Organization for Health Research and Development, the main funding body for health research in the Netherlands. ZonMw established a committee to assess the research proposals and complex care initiatives of the participating hospitals and to set several criteria for funding eligibility. One requirement was that participating hospitals had to collaborate with universities or UMCs on research projects and were not allowed to conduct basic research in the context of the program, as this was seen as the special province of UMCs.
Boundary work
In the qualitative part of this study, we analyse the boundary work done by actors to influence organizational boundaries as well as the practices undertaken to initiate or enhance collaboration between TopCare non-academic hospitals and academia (universities and UMCs). We refer to boundary work when actors create, shape or disrupt organizational boundaries [ 32 , 33 , 34 , 35 ]. In particular, boundary work involves opening a boundary for collaboration and creating linkages with external partners [ 36 ]. In this article, we use three organizational boundary concepts – “identity”, “competence” and “power” – out of four presented by Santos and Eisenhardt. These concepts are concerned with fostering collaboration, whereas the fourth is concerned with “efficiency” and is less relevant here. Identity involves creating a reputation for research to become an attractive partner while preserving identity. Competence involves creating opportunities for research, for example, in manpower and infrastructure. Finally, power involves creating a negotiating position vis-à-vis relevant others [ 35 ].
The data for this study consist of different types of analysis: (1) quantitative bibliometric data on the publications and citations of all eight Dutch UMCs and 28 non-academic hospitals, and (2) quantitative bibliometric data on the publications and citations in the four domains of two TopCare non-academic hospitals, qualitative (policy) document analysis and in-depth ethnographic interviews with various actors in the Dutch TopCare program. The quantitative data collected from Dutch UMCs and non-academic hospitals were utilized to contextualize data gathered within the TopCare program. We discuss and explain the data collection and methodology in detail in the two sections below.
Quantitative approach: bibliometric analysis of all 8 Dutch UMCs and 28 non-academic hospitals
Data collection
We performed a bibliometric analysis of the publications of 28 non-academic hospitals and 8 UMCs Footnote 1 in the Netherlands between 2009 and 2018. Data for the study were derived from the Center for Science and Technology Studies’ (CWTS) in-house version of the Web of Science (WoS) database. The year 2009 was chosen because the address affiliations in publications are more accurately defined from this year onward. To examine trends over time, we divided the period 2009–2018/2019 into two blocks of 4 years and an additional year for citation impact measurement (2009–2012/2013 and 2014–2017/2018; see explanation in Appendix 1).
Methodology
The bibliometric analysis includes several bibliometric indicators that describe both the output and impact of the relevant research (Table 5 in Appendix 1). One of the indicators, the mean normalized citation score (MNCS), reveals the average impact of a hospital’s publications compared with the average score of all other publications in that area of research. If the MNCS is higher than 1, then on average, the output of that hospital’s domain is cited more often than an “average” publication in that research area.
To map the ways hospitals cooperate, we follow two lines of analysis. The first is centred around a typology of scientific activities and differentiates between (i) a single institution (SI; all publications with only one address) and (ii) international collaboration (IC; collaboration with at least one international partner). All other publications are grouped as (iii) national collaboration (NC; collaboration with Dutch organizations only).
The second line is centred around geographical distance and size of collaboration. The geographical distances between each non-academic hospital and each of the eight UMCs were measured in Google Maps. The size of collaboration was measured by counting the joint publications of each non-academic hospital and the eight UMCs. Subsequently, we assessed whether the non-academic hospitals also had the most joint publications with the nearest UMC.
Quantitative and qualitative approach to the two TopCare hospitals and their four domains, the “TopCare program” case study
Quantitative approach
The quantitative approach to the TopCare program relies on a bibliometric analysis of publications within each hospital’s two domains: lung and heart care in TopCare non-academic hospital #1, and trauma and neurology in TopCare non-academic hospital #2. Our bibliometric analysis focused on publications within the four selected TopCare domains between 2010 and 2016, following the same methodology described in the previous section under ‘Data collection’. Each domain provided an overview of its publications. The number of publications produced by the two domains at each TopCare hospital is combined in the results. Although this timeframe differs from the broader analysis of all UMCs and non-academic hospitals, comparing these two periods offers insights into the “representative position” of the two domains of each non-academic hospital participating in the TopCare program, in terms of publications and citations.
Qualitative approach
We took a qualitative approach to analysing the collaborative activities in the two TopCare non-academic hospitals, where each domain has its own leadership arrangements, regional demographic priorities and history of research collaboration [cf. 37 ]. This part of the study consisted of interviews and document analysis.
Ethnographic interviews
Over the course of the 4-year program, J.P. and/or R.B. conducted and recorded 90 semi-structured interviews that were then transcribed. For this study, we used repeated in-depth ethnographic interviews with the main actors in the Dutch TopCare program, which took place between 2014 and 2018. We conducted a total of 27 interviews; 20 of the interviews were with a single person, 5 with two persons, and 2 with three persons. The interviews were held with 20 different respondents; 12 respondents were interviewed multiple times. Table 1 presents the different respondents in non-academic hospitals #1 and #2.
Document analysis
Desk research was performed for documents related to the TopCare program (Table 6 – details of document analysis in Appendix 1).
The bibliometric analysis of the four domains in the two TopCare non-academic hospitals follows the same methodology as described in Abramo et al. [ 1 ].
We tested the assumption that joint publications are most frequent between a non-academic hospital and its nearest UMC. If the geographical distance between TopCare non-academic hospitals and their collaborative academic partners is described as “nearby”, then they both work within the same region.
The ethnographic interviews were audio-recorded and transcribed in full with the respondents’ permission. These transcripts were subject to close reading and coding by two authors, J.P. and J.O., to identify key themes derived from the theory [ 35 ] (Table 7 in the Appendix). These were then discussed and debated with the wider research team with the goal of developing a critical interpretation of the boundary work done to initiate or enhance research collaboration [cf. 37 ]. The processed interview data were submitted to the respondents for member check. All respondents gave permission to use the data for this study, including the specific quotes. In the Netherlands, this research requires no ethical approval.
Triangulating the results of the document analysis and the interviews enables us to identify different overarching themes within each boundary concept (identity, competence and power). These themes were utilized as a framework for structuring individual paragraphs, which we explain in greater detail in Table 4 in the Results.
Bibliometric analysis of all Dutch UMCs and non-academic hospitals
This section reports the results of the quantitative bibliometric analysis of the output, trends and impact of collaboration between all UMCs and non-academic hospitals from 2009 to 2018/2019. It provides a broad picture of the output – in terms of research publications – of both existing and ongoing collaborations between all UMCs and non-academic hospitals within the specified timeframe. It furthermore describes the analysis results concerning the relationship between collaboration and the geographical distance between two collaborating hospitals.
Output: distribution of the types of collaboration for UMCs and non-academic hospitals from 2009 to 2018/2019
The first step in understanding the degree of collaboration between hospitals is to measure the research output by number of publications. The total number of publications between 2009 and 2018 is shown in Table 8 ( Appendix 1) and Fig. 1 .

Types of collaboration for UMCs and non-academic hospitals from 2009 to 2018/2019. # Total number of publications. Percentage of total (100%) accounted for by single institution, national collaboration and international collaboration
The majority of these publications (89%) are affiliated with UMCs. UMCs, in particular, tend to have a relatively higher proportion of single-institution publications and are more engaged in international collaboration. This pattern may be indicative of UMCs’ enhanced access to research grants and EU subsidies, as well as their active involvement in international consortia.
Collaboration between UMCs and non-academic hospitals appears to be more prevalent and impactful for non-academic hospitals than for UMCs: 70% of all publications originating from a non-academic hospital were the result of joint efforts between a UMC and a non-academic hospital, whereas only 8% of all UMC publications were produced in collaboration with a non-academic hospital (Table 8 in Appendix 1).
Trend analysis of collaboration in relative number of publications
Table 9 Appendix 1) and Fig. 2 show the relative number of publications of all 8 UMCs and all 28 non-academic hospitals in the two periods: 2009–2012/2013 and 2014–2017/2018. For both UMCs and non-academic hospitals, international collaboration accounted for a relatively larger share of publications in recent years.

Type of research collaboration for UMCs and non-academic hospitals over time. Percentage of total (100%) accounted for by single institution, national collaboration and international collaboration in each period
Analysis of relationship between distance and collaboration
As the non-academic hospitals often collaborate with UMCs, it is interesting to analyse these collaborations geographically (distance). The assumption is that geographical proximity matters, with the most-frequent joint publications being between a non-academic hospital and the nearest UMC.
Figure 3 shows that 61% (17 out of 28) of the non-academic hospitals collaborate most frequently with the nearest UMCs. Geographical proximity is thus an important but not the only determining factor in collaboration.

Collaboration with nearest UMC from 2009 to 2018
Impact of collaboration on bibliometric output of UMCs and non-academic hospitals
The mean normalized citation scores (MNCS) shown in Table 2 cover all 8 UMCs and 28 non-academic hospitals.
The MNCS in Table 2 and the mean normalized journal scores (MNJS) in Table 10 (Appendix 1) show similar patterns. The impact score for both UMCs and non-academic hospitals is greatest for international collaboration. Non-academic hospitals’ single-institution publications score lower than the global average, which was defined as 1.
In sum, quantitative analysis exposes two trends. The first is growth in international collaboration for all UMCs and non-academic hospitals over time, also revealing that collaboration leads to higher MNCS impact scores. Second, geographical proximity between UMCs and non-academic hospitals is an important but not the only determining factor in collaboration. This is the context in which the TopCare program operated in 2014–2018.
“TopCare program” case study
This section presents the results of our analysis of the collaboration networks of the two TopCare non-academic hospitals, consisting of: (1) quantitative bibliometric analysis of the output and impact of these networks between 2010 and 2016, along with the geographical distance to their academic partners, and (2) qualitative ethnographic interviews to identify the boundary work conducted by these hospitals.
Bibliometric analysis of the two TopCare non-academic hospitals’ international and national collaboration networks across four domains
The results of the bibliometric analysis indicate the representative positions of the two domains within each TopCare non-academic hospital. Between 2010 and 2016, these hospitals generated a higher number of single-institution publications compared with the average of all non-academic hospitals. Percentage-wise, their output resembled that of the UMCs, underscoring their leading positions in their respective domains. The percentage of publications based on national collaboration in the domains of TopCare hospital #2 is comparable to that of non-academic hospitals overall, while there is more international collaboration in the domains of TopCare hospital #1 than at non-academic hospitals overall (Fig. 4 , Appendix 1 and Fig. 1 ). The impact of the research is above the global average, and the publications have a higher average impact when there is collaboration with international partners; this is true across all four domains (Table 11 in Appendix 1).
In terms of geographical distance, only the neurology domain of TopCare hospital #2 collaborates with an academic partner within the same region. All other domains collaborate with partners outside the region, a striking difference from the geographical results shown in Fig. 3 .
Ethnographic analysis
This section reviews the results of our ethnographic analysis of the two TopCare hospitals from 2014 to 2018. To analyse the boundary work these hospitals performed to initiate and/or enhance productive research collaborations, we use the framework suggested by Santos and Eisenhardt (2005) for examining organizational boundary work through the concepts of identity, competence and power. Table 3 provides a description of each boundary and how these concepts are defined in our case study on the basis of the overarching themes in the document analysis and the interviews.
Identity: enhancing hospitals’ value proposition
In the TopCare program, the non-academic hospitals used their unique history and expertise to create a joint research focus in a domain and to enhance their positions and influence their collaboration with UMCs and universities.
A manager in hospital #1’s lung domain explained the work being done from a historical perspective, emphasizing not only the innovative history of the hospital but also its central position in patient care:
The first-ever lung lavage, lung transplant and angioplasty were performed in this hospital. Nationally, this hospital has always, and we’re talking about 50–60 years ago now, been at the forefront, and has always invested in this line of research and care. So that is truly institutionally built, there is just that history and you can’t just copy that. And we have the numbers: for interstitial lung diseases, we have 2000 patients in our practice and receive 600 new patients per year. (interview with manager at hospital #1 in 2018).
To explain why patient care and research into rare interstitial lung diseases is centred in hospital #1 as a strategic domain focus, a leading international pulmonary physician – a “boundary spanner” (see below) – pointed to the importance of building team expertise and creating facilities:
I lead that care program for interstitial lung diseases and preside over the related research. I’ve often been asked: you’re a professor, so why don’t you go to a UMC, couldn’t you do much more there? But the care was developed here [in this hospital]. The expertise needed to recognize interstitial lung diseases depends not only on me but also on the radiologist and pathologist; together we have a team that can do this. We have created facilities that no other hospital has for these diseases. If I leave to do the same work in a UMC, I’d have to start over and I’d be going back 30 years. (interview with pulmonary physician at hospital #1 in 2014).
The doctors working in this hospital’s lung and heart domains finance the working hours they put into research themselves. “This fits in with the spirit of a top clinical hospital and the entrepreneurial character of our hospital.” (interview with project leader at hospital #1 in 2018).
Hospital #2, the result of a merger in 2016, struggled to find its strategic focus. A surgical oncologist at this hospital clarified one of the disadvantages of the merger: “People are [still] busy dealing with the money and positions, and the gaze is turned inward, the primary processes. So clinical research is very low on the agenda.” She continued by saying that a small project team acting on behalf of the hospital’s board of directors (BoD) was seeking the best-fit profile for the program, which had raised some opposition in departments excluded from the chosen strategic focus. As a consequence, the hospital had begun to showcase its highly specialized care in the field of neurosurgical treatments. It had a long history and was the first to use a Gamma Knife device for treating brain tumours. The experts in this domain could thus act as authorities, and they became a national centre of expertise. Their strategic partner was a nearby UMC, and they treated relevant patients from other hospitals in their region.
To generate impact, research priorities in a domain are aligned with the focus of the hospital. A member of the BoD of hospital #2 stressed the urgency of “specializing or focusing on a particular area of care” and emphasized that the TopCare budget was being utilized to create a joint focus within a domain. The resulting collective identity mobilized internal affairs and was recognized as valuable by third parties. An important reason for joining the TopCare program for both hospitals was to be able to position themselves strategically as attractive and credible research partners:
The focus is on the domains of neurology and trauma because we think as a non-academic hospital we have something extra to offer: the very close relationship between patient care and research, because we have a larger number of patients of this type here than the universities. (interview with care manager at hospital #2 in 2013).
In short, the boundary of identity requires a closer alignment between these hospitals’ research activities and their strategic objectives and organizational mindset, and demands that they also showcase their staff’s expertise. The TopCare program offered opportunities to transform and consolidate their identity by enhancing their value proposition, that is, their unique history, strategic domain focus, expertise and number of patients.
Competence: Enhancing research infrastructures
All domains in the TopCare program chose to utilize the TopCare funding to invest in their research infrastructure, and to build research networks to share and learn. A research infrastructure consists of all the organizational, human, material and technological facilities needed for specialist care and research [ 31 ].
The TopCare data show that funding is essential for generating research impact. A manager at hospital #1 described its current financial circumstances:
A lot of research and much of the care is currently not funded, it is actually paid for mostly by the hospital... We have had massive budgetary adjustments the past two or three years. ...It is increasingly difficult to finance these kinds of activities within your own operation. (interview with manager at hospital #1 in 2018).
The TopCare funding was used to enhance the material infrastructure in hospital #1’s heart domain:
A number of things in healthcare are really terribly expensive, and there is simply no financing at all for them. …Cardiac devices, for example. We are constantly trying things out, but there’s no compensation for it. (interview with project leader at hospital #1 in 2018).
Hospital #1 had a long-standing and firm relationship with a UMC in the lung domain, giving it a solid material infrastructure. For example, there were spaces where researchers, especially PhD students, could meet, collaborate and share knowledge [ 31 ]. Another essential part of the material infrastructure for the lung domain was the biobank, as highlighted by a leading international pulmonary physician:
Our board of directors made funds available through the innovation fund to start up a biobank, but developing it and keeping it afloat has now been made possible thanks to the TopCare funding. It’s a gift from heaven! It will allow for further expansion and we can now seek international cooperation. (interview with pulmonary physician at hospital #1 in 2014).
Notably, the program allowed both non-academic hospitals to digitize their infrastructure, for example, with clinical registration and data management systems. According to an orthopaedic surgeon at hospital #2, “Logistics have been created, which can very easily be applied to other areas. By purchasing a data system, everyone can record data in a similar way.”
Besides investing in data infrastructure, the human dimension was another crucial factor in the research infrastructure. Instead of working on research “at night”, it became embedded in physicians’ working hours. All domains indicated the importance of having researchers, statisticians and data management expertise available to ensure and enhance the quality of research, and both hospitals invested in research staffing.
After losing many research-minded traumatologists to academia, hospital #2 decided to invest in dedicated researchers to form an intermediate layer of full-time senior researchers linked to clinicians within the two domains.
I personally think this is the most important layer in a hospital, with both a doctor and a senior researcher supervising students and PhD candidates. Clinicians ask practical questions and researchers ask a lot of theoretical questions. Both perspectives are needed to change practices. I have also learned that it takes a few years before the two can understand each other’s language. (interview with neurosurgeon at hospital #2 in 2018).
Competence: Finding alignments within hospitals and research networks
The program offered the hospitals opportunities to structure internal forms of collaboration and build a knowledge base within a domain. For example, hospital #1 organized educational sessions with all PhD students in the heart domain.
Having more researchers working in our hospital has given the whole research culture a boost, as well as the fact that they are producing more publications and dissertations. (interview with cardiologist at hospital #1 in 2018).
Hospital #2 also encouraged cross-domain learning by organizing meetings between the neurology and trauma domains.
You know, you may not be able to do much together content-wise, but you can learn a lot from each other in terms of the obstacles you face (interview with project manager at hospital #2 in 2016).
At the beginning there was resistance to participating in the program.
It was doom and gloom; without more support, groups refused to join. That kind of discussion. So the financial details have been important in terms of willingness to participate. (interview with surgical oncologist at hospital #2 in 2018).
Another obstacle was local approval for multicentre studies, which led to considerable delay (interview with psychologist at hospital #2 in 2018). Overall, the TopCare program created a flywheel effect for other domains that proved essential for internal collaborations (interview with surgical oncologist at hospital #2 in 2018).
In hospital #1, collaboration between the heart and lung domains grew closer.
Divisions between the different disciplines are much less pronounced in our hospital than in UMCs. So it’s much easier to work together. We’d already collaborated closely on lung diseases, and this has improved during the program. (interview with cardiologist at hospital #1 in 2016)
At the network level, the TopCare data show that most researchers participated in national networks. For example, the neurology domain in hospital #2 had established a network of 16 non-academic hospitals. Limited funding prevented researchers at non-academic hospitals from attending many international seminars, and they had more trouble building their international networks. One exception concerned the researchers in the lung domain of hospital #1, who expanded their international network by organizing an international seminar during the TopCare program and by contributing to other national and international seminars.
Each TopCare domain provided highly specialized care and wanted to become a centre of expertise. However, a hospital can only provide highly specialized care if research is conducted to determine the best treatment strategies. The data show how the two are interwoven.
For example, a PhD student has sought to collaborate with a UMC on a specific aorta subject in which we have greater expertise and more volume in terms of patients than UMCs. Based on this link with this UMC, a different policy was drawn up and also implemented immediately in all kinds of other UMCs. (interview with cardiologist at hospital #1 in 2018).
Often, a leading scientist who is the driving force behind a domain in a hospital is a “boundary spanner”, a person in a unique position to bridge organizational boundaries and foster research collaboration by “enabling exchange between production and use of knowledge” [ 40 , p. 1176], [ 41 ]. For example, the leading pulmonary physician in hospital #1 is a boundary spanner who has done a huge amount of work to enhance collaboration. With interstitial lung disease care being concentrated here, this professor can offer fellowships and stimulate virtual knowledge-sharing by video conferencing for “second-opinion” consultations. The TopCare funding was used to finance this. The network is successful at a non-academic level.
These consultations are with colleagues in other hospitals and they avoid patients having to be referred. (interview with project leader at hospital #1 in 2018). Our network now [in 2018] consists of more than 14 hospitals, which we call every week to discuss patients with an interstitial lung disease. …UMCs participate indirectly in this network. For example, the north has a specific centre for this disease in a non-academic hospital and a nearby UMC refers patients to this centre, who are then discussed in our network. (interview with pulmonary physician at hospital #1 in 2018).
This physician also noted that the network was still growing; other colleagues from non-academic hospitals wanted to join it.
Yesterday, colleagues from XX and XX were here. And they all said, “I’ve never learned so much about interstitial lung diseases.” We’re imparting enormous amounts of expertise. (interview with pulmonary physician at hospital #1 in 2018).
In sum, focusing on the boundary of competence, the TopCare hospitals created and mobilized resources to invest in their research infrastructure. In every domain, this infrastructure was used to strengthen the relationship between research, care and education, and to build and enhance internal and external research networks to share and learn.
Power: Enhancing the relationship with or finding and mobilizing strategic academic partners
For TopCare non-academic hospitals, the boundary of power is concerned with creating the right sphere of influence, meaning BoDs and administrators attempt to find and mobilize new strategic partners and build mutual relationships with various stakeholders at different levels.
A project leader at hospital #2 emphasized that the additional resources of the TopCare program created an opportunity for the non-academic hospitals “to show our collaborative partners that we’re a valuable partner.” For once, the tables were turned:
We’ve always had a good relationship with one UMC; they always used the data from our surgeries. But it’s nice that we can finally ask them whether they want to join us. That makes it a little more equal, and we can be a clinical partner. (interview with neurosurgeon at hospital #2 in 2018).
One of the requirements in each domain when applying to ZonMw for funding was alignment with academia in a research and innovation network. Collaboration often appeared more difficult at the administrative level when the academic partners worked in the same field of expertise, and tended to be more successful when the partners focused on different fields, where their interests did not conflict. According to a board member at hospital #2 who played a crucial role in a partnership agreement, a conscious decision was taken beforehand to seek partners beyond the medical domain as well.
There may be conflict with other groups within the walls of a UMC and I don’t see that as promising. You have to work together and we aren’t in a real position to do so. (interview with board member at hospital #2 in 2018).
Just before the end of the program, it was announced that this hospital had concluded a partnership agreement with a university to broaden their joint research program alongside neurology and trauma. An important prerequisite was that both organizations invest 1 million euros in the partnership. The board member revealed that the relationship with this university had in fact existed for some time:
So we went and talked to the university and they became interested. Then the top level was reorganized and replaced and we had to start from scratch again. That took a lot of time. Our goals were to awaken the enthusiasm of the board and at least three deans, otherwise it would be a very isolated matter. And we succeeded. Last week we had a matchmaking meeting at the university and there were about 50 pitches showing how we could be of value to each other. (interview with board member at hospital #2 in 2018)
Looking back, he defined the conditions for a successful collaboration with academia:
In terms of substance, the two sides have to be going in the same direction and complement each other, for example, in expertise, techniques, and/or facilities. And what is really important is that people know each other and are willing to meet each other…and there must be appreciation. (interview with board member at hospital #2 in 2018).
The trauma domain in hospital #2 wanted to become a trauma research centre in its region, and after investing in its research infrastructure, it found a new strategic academic partner:
We have also found new partners, for example, the Social Health Care Department of a UMC [name]. And that really has become a strong partnership; the intent was there for years, but we had no money. (interview with epidemiologist at hospital #2 in 2018).
The neurology domain at this hospital worked to form a network with a university of technology and a university social science department.
Officially, our hospital can’t serve as a co-applicant for funding and that is frustrating. However, I am pleased to show that we are contributing to innovation. (interview with neurosurgeon at hospital #2 in 2018).
A board member at this hospital reflected on the qualities needed for research and concluded: “The neuro group has more of those intrinsic qualities than the trauma group. …I think the trauma group is actually at a crossroads and will think twice about whether they can attract capacity to develop the research side or fall back to a very basic level.”
In hospital #1, administrators rejected a proposal to collaborate with the nearest UMC submitted by medical specialists in the heart domain. Past conflicts and unsuccessful ventures still influenced the present, even though the individuals involved had already left.
A further factor was raised by a manager at hospital #1, who reflected on the importance of obtaining a professorship in the heart domain:
If we can, even on the basis of any kind of appointment, obtain a professorship from the heart centre, then yes, that helps! …I think it just helps throughout the whole operation, politically speaking, as extra confirmation, extra legitimization for that status. (interview with manager at hospital #1 in 2016).
Eventually, hospital #1 managed to find alignment with a UMC in another region during the program and a medical specialist from the hospital became a professor by special appointment.
This UMC showed the greatest determination, actually, while we could have chosen to collaborate with the nearest UMC [but we didn’t]. And there was actually also a real click between both the administrators and the specialists. (interview with manager at hospital #1 in 2018).
Additionally, the TopCare data show that, while there may be close alignment with the nearest UMC, collaboration is not limited to this and proximity can sometimes even be detrimental (for example, in some cases hospitals compete for patients). As research and care in the TopCare hospitals’ domains became more specialized, they required the specific expertise of UMCs in other regions.
One critical dependency in the collaboration between a university or UMC and a non-academic hospital is the distribution of dissertation premiums, valued at about €100,000 per successful PhD track. Currently, after completion of a dissertation, the premium goes entirely to the university or UMC, even when much of the candidate’s research and supervision takes place in a non-academic hospital [ 31 ]. This structural difference makes collaboration less financially valuable to non-academic hospitals. For example, the leading pulmonary physician in hospital #1 is a professor who is affiliated with both a UMC and non-academic hospital, a boundary spanner who works across organizational boundaries, is successful in research, and bears responsibility for a significant proportion of the research output in the lung domain and in the collaboration with other organizations. Moreover, he does most of the PhD supervision, and his students do their work in hospital #1. Despite all this work, the dissertation premium goes to the UMC. Although efforts have been made to change this, certain institutional structures are so strongly embedded that it is difficult to open the organizational boundary.
Power: Aligning with the BoDs and administrators of the TopCare non-academic hospitals
During our research, we observed how the BoDs and administrators of the two TopCare hospitals discussed the progress of the program and worked together to learn from each other.
We can learn a lot from hospital #1 regarding the organization of our research, we think. That has been very inspiring. …On the other hand, the focus has been very centred on getting the domain and project requests funded at all. (interview with care manager at hospital #2 in 2013).
The BoDs opted for an approach aimed at building mutual trust and understanding. As a result, their alliance became more intensive during the program. By the time the program’s final report was released, both BoDs were leveraging their power to influence ZonMw’s next step: the follow-up to TopCare. They had a targeted plan for their lobbying. For example, after mutual coordination, the BoD of each hospital sent a letter to the Ministry of Health sketching their vision for the future.
In summary, for the TopCare hospitals, the boundary of power centred on finding alignment with strategic academic partners and the other BoDs and administrators in the TopCare program. Moreover, ties with strategic partners were important for extending the organization’s sphere of influence [ 33 ] in building and enhancing productive research collaborations. These hospitals recognized that they could not dismantle the existing structure of research funding, and they therefore committed themselves to trying to extend the TopCare program. Table 4 summarizes the opportunities and challenges within the three boundary concepts.
In our study, we used a mixed methods research design to explore research collaborations by focusing on the research output and impact of UMCs and non-academic hospitals in the Netherlands and by zeroing in on the boundary work of two Dutch non-academic hospitals for achieving collaboration.
Our bibliometric analysis shows that collaboration matters, especially for non-academic hospitals. Access to research grants, EU funding and international collaborations is harder for non-academic hospitals, and they need to collaborate with UMCs to generate research impact, assessed by means of MNCS impact scores. Conversely, non-academic hospitals are important for UMCs because they have a larger volume of patients. When UMCs and non-academic hospitals collaborate, their impact scores are higher. Impact scores are, moreover, higher for international collaborative publications across all types of hospital and all periods. More in-depth research is needed into why collaboration increases impact.
Bibliometric analysis of the domains of the two TopCare non-academic hospitals underscores their leading role in these domains. Upon receiving TopCare funding, the hospitals had to engage in various forms of boundary work to meet the requirement mandated by ZonMw of establishing a research collaboration with academia. They used the additional program resources to invest [ 33 ] in opening a boundary for research collaboration with academic partners.
Identity work involves creating an image of the organizational unit that legitimizes its research and care status in line with the dominant mindset of the organization. In practice, the relevant unit needs to establish a distinctive history and domain focus that aligns with the organizational strategy of the hospital, in-house expertise and patient flow. This requires coordination work with the BoD. However, not all domains have been successful in creating such an identity. It proved much more difficult for the trauma domain, for example, because their research is not as highly specialized as and more fragmented than the other domains.
Competence work focuses on organizational (a well-functioning science support unit), technological (registration systems) and material (floor space or biobank) infrastructure, depending on individual requirements. Additionally, tremendous efforts go into the human dimension of infrastructure, as TopCare hospitals consider research staff and making time available for doctors to be important conditions for building structurally supportive research programs. In a previous study, we highlighted that collaboration between all non-academic hospitals within the Association of Top Clinical Teaching Hospitals (STZ) is essential for strengthening their research infrastructure [ 42 ], and can also be seen as a matter of efficiency [ 35 ]. Moreover, in each TopCare hospital, competence work served to bring domains together to facilitate shared learning. Knowledge-sharing across departments or communities is an example of opening boundaries to facilitate integration, convergence or enrichment of points of view [ 36 , 43 , 44 ].
Professors with double affiliations can act as boundary spanners. They play a significant role as experts in a domain by creating its distinctive character, and they surmount borders and break down barriers through their network relationships with other hospitals. Additionally, these persons are responsible for a significant share of the research output in their domain and conduct research with worldwide impact in collaboration with other organizations. Their boundary work must be recognized as essential because they bring usable knowledge to the table, create opportunities for improved relationships across disciplines, enhance communication between stakeholders and facilitate more productive research collaborations [cf. 45 ].
The TopCare hospitals do much less work in the power dimension because the domains in which they operate are adjacent to those of academia. Our study shows that more successful, productive research collaborations are created when the hospital’s academic partner works in a complementary but not identical field. Only in one case, the heart domain, did collaboration succeed in an identical field, but that was because the academic partner was located outside of the hospital’s region and was therefore not a competitor. According to Joo et al., a potential partner’s suitability is determined not only by complementarity, their unique contribution to research collaboration in terms of expertise, skills, knowledge, contexts or resources but also by compatibility and capacity. Partner compatibility involves alignment in vision, commitment, trust, culture, values, norms and working styles, which facilitate rapport-building and cross-institutional collaboration [ 46 ]. TopCare data indicate that research collaborations should be managed to ensure all partners can operate as equals [ 47 ]. Partner capacity refers to the ability to provide timely resources (for example, expertise, skills or knowledge) for projects, as well as leadership commitment, community engagement and institutional support for long-term, mission-driven goals, such as the joint research program in neurology and trauma at hospital #2 and a university.
These three qualitative criteria – partner compatibility, complementarity and capacity – are aspects of power dynamics that influence strategic decisions about recruiting research partners. Generally, power dynamics shape a hospital’s strategic choices regarding whether to collaborate, with whom to partner and the extent of the research collaboration [ 48 ]. Future research should examine these power dynamics in a more integrated manner to unlock the full potential of collaboration [ 46 ].
It was possible to unravel how non-academic hospitals participating in the TopCare program engaged in research collaborations with academia. As the program did not interfere with the existing care, research and financing structures within the UMCs, it allowed TopCare non-academic hospitals to also combine top clinical care and research. The boundary concepts allow us to observe a dual dynamic in the collaboration: the opening of boundaries while simultaneously maintaining certain limits. Opening boundaries refers to facilitating collaboration through activities related to identity and competence, while maintaining them involves the power balance. The temporary program did not disrupt the existing power balance associated with the budgetary “academic component” and the dissertation premiums that accrue to academia. Overall, then, the power dimension may well be the primary factor that made it impossible for the TopCare non-academic hospitals to attain their ultimate goal: secure a consistent form of funding for their research and top clinical care. Instead, the national authorities introduced a new, temporary funding program for non-academic hospitals, and preserved the status quo favouring academia.
A key finding is that, if a hospital is successful in establishing coherence between the different forms of boundary work, it can create productive research collaborations and generate research impact. The TopCare hospitals performed boundary work to strengthen their research infrastructure (competence) and their research status (identity) and create a favourable negotiating position opposite academia (power). For example, choosing the lung domain as the hospital’s strategic focus (identity) and establishing a database as a fundamental source of information for research by a boundary spanner (competence) generated sufficient power to make the hospital a key player in this field and a much-respected collaboration partner, nationally and internationally. However, some restrictions remained in place, such as the national lung research network consisting only of non-academic hospitals, with UMCs participating only indirectly.
Another key finding is that possessing a substantial budget is not in itself enough to ensure successful research collaboration. It is clear from this study that extensive boundary work is also needed to facilitate research collaboration. Given the absence of structural funding, the TopCare non-academic hospitals were under pressure to deliver results during the program, making research collaboration even more crucial for them than for the UMCs in this context. Additionally, because highly specialized care and research at the TopCare non-academic hospitals required unique expertise, they had a growing need for collaboration at the national level. Contrary to assumptions and the findings of our analysis of UMCs and non-academic hospitals overall, their collaborative partners were not predominantly located at the nearest UMC.
Does our study align with the literature and support the results of similar initiatives, such as the establishment of Collaborations for Leadership in Applied Health Research and Care (CLAHRC), a regional multi-agency research network of universities and local national health service (NHS) organizations focused on improving patient outcomes in England by conducting and utilizing applied health research [ 49 ]? And what does it contribute to previous research?
While differences exist between the National Health Service (NHS) and the healthcare system in the Netherlands, there are also noteworthy parallels that render a comparison possible. These include encouraging networks to boost research productivity, fostering collaboration within a competitive system and funding research that is relevant to public health priorities. Moreover, building upon the findings of CLAHRC regarding boundary work within a competitive system and developing and funding research that is relevant to patient needs and public health priorities, there are further parallels, such as creating strong local research infrastructures and local networks [ 49 ], and using influential and skilled boundary spanners [ 49 , 50 ]. In addition, we found that research history, strategic domain focus, in-house expertise, patient flows, and network relationships pre-conditioned the TopCare hospitals’ collaboration with academia. Our results further show that, for non-academic hospitals seeking to create productive research collaborations, it is essential to work in complementary fields and to establish a coherence between identity, competence and power.
Our findings indicate that, after opening a boundary with academia, the focus of the TopCare hospitals was on searching for mutual engagement. These hospitals tried to clarify their added value by creating boundaries to distinguish themselves from UMCs, and attempted to extend the TopCare program without it overlapping with the budgetary “academic component”, so that it posed no threat to the UMCs. Boundary-crossing involves a two-way interaction of mutual engagement and commitment to change in practices [ 51 ]. It is likely that the program did not last long enough to instigate changes in practices, as it can take time to develop mutual understanding and foster trusting relationships [ 52 ].
Based on the CLAHRC results and our research findings, the trend towards regionalization in the Netherlands [ 53 ] and a new leading and coordinating role for UMCs in this research landscape [ 52 , 54 ] can only be successful if boundary work is conducted, allowing research-minded non-academic hospitals to:
Build a “collaborative identity” [ 50 , 55 , 56 ] over time with their academic partners (identity);
Establish added value in their research infrastructures compared with that of their academic partners (competence);
Create solid networks for learning and sharing knowledge [ 55 , 57 ] with their academic partners (competence);
Mobilize boundary spanners to bridge disciplinary and professional boundaries in research, teaching and practice [ 49 , 50 , 55 , 58 ] and publish articles in collaboration with academic partners with high research impact (competence);
Find the inspiration and confidence to increase their co-dependence to, for example, gain benefits from interacting with different partners in the field [ 35 ] (power); and
Create long-term collaborations with academia across sectors over time, as well as within sectors; this requires iterative and continual engagement between clinicians, academics, managers, practitioners and patients (power) [ 49 , 52 ].
It is conceivable that the evaluation of the follow-up study to the TopCare program, which will extend to 2025, could unravel these next steps.
Our results demonstrate that collaboration in research is important and should be encouraged. However, the current methods used to assess researchers underestimate this importance. Reward systems and metrics focus on the performance of individual researchers and may even discourage the development of medical research networks and collaboration [ 52 , 59 ]. There is ongoing debate about and rising criticism of the dominance of scientific impact scores as a measure of the performance of health researchers and research organizations [ 60 ]. Other forms of impact, such as the societal impact of medical research, are becoming more important, and different metrics are being developed. Research collaboration among individuals and organizations should be incentivized and rewarded, and should also be embedded in performance assessment and the core competences of all actors involved [ 61 ]. New ways of rewarding research collaboration within organizations should therefore be explored.
Limitations
This study is limited, both geographically and institutionally, to the Netherlands, and factors other than national and international research collaborations may explain the increase in research output and impact. For example, the research articles in our sample have not been analysed on substantive aspects such as methodology and funding. A bias may therefore have been introduced. Furthermore, the research output and impact of the TopCare non-academic hospitals that we measured was limited to the 4-year program period. A further limitation was the use of these hospitals’ research output as a measure of the influence of the TopCare program, as we were interested not only in the short-term effects (publications) but also in the long-term ones (on the work conducted to build research infrastructures). Moreover, the focus in the qualitative material concerning the TopCare program was on the two TopCare non-academic hospitals and, more specifically, on their national rather than their international collaborations.
Research collaboration between non-academic hospitals and academia in the Netherlands pays off in terms of publications and impact. For the publication of scientific articles, collaboration between UMCs and non-academic hospitals appears to be more prevalent and impactful for non-academic hospitals than for UMCs. When UMCs and non-academic hospitals collaborate, their impact scores tend to be higher. More research is needed into why collaboration leads to more impact.
Non-academic hospitals showed a higher rate of collaboration with the nearest UMC, whereas collaborative partners of TopCare hospitals were not predominantly located at the nearest UMC. TopCare hospitals prioritized expertise over geographical proximity as a predicator of their collaborative efforts, particularly as research and care in their domains became more specialized.
Drawing on the additional resources of the TopCare program, participating non-academic hospitals invested significantly in boundary work to open boundaries for research collaboration with academic partners and, simultaneously, to create boundaries that distinguished them from UMCs. Identity work was performed to ensure that their history and domain focuses were coherent with the dominant mindset of their organization, while competence work was done to enhance their research infrastructure. The human dimension of the infrastructure received considerable attention: more research staff, time made available for doctors and recognition that boundary spanners facilitate research collaborations.
Power work to find and mobilize strategic academic partners was mostly focused on complementary fields, as non-academic hospitals work in domains adjacent to those of academia. The TopCare hospitals tended to avoid power conflicts, resulting in a preservation of the status quo favouring academia.
The local research history, strategic domain focus, in-house expertise, patient flows, infrastructure and network relationships of each TopCare hospital influenced collaboration with academia [cf. 37 , 58 . Increased coherence between the different forms of boundary work led to productive research collaborations and generated research impact. To meet future requirements, such as regionalization, further boundary work is needed to create long-term collaborations and new ways of rewarding research collaboration within organizations.
Availability of data and materials
The datasets used and/or analysed during the study are available from the corresponding author upon reasonable request.
The names of the UMCs and non-academic hospitals and their numbers are not up to date due to mergers in the intervening period. The database contains data on eight UMCs; today there are seven, as two UMCs in Amsterdam merged in 2018. There are 28 non-academic hospitals in the database, whereas today 27 such hospitals are members of the Association of Top Clinical Teaching Hospitals ( https://www.stz.nl ). To ensure data consistency, the database remains unchanged.
Abbreviations
Board of directors
Center for Science and Technology Studies
International collaboration
Mean normalized citation score
Mean normalized journal score
National collaboration
Netherlands Federation of University Medical Centers
Single institution
Association of Top Clinical Teaching Hospitals
University medical centre
Abramo G, D’Angelo CA, Di Costa F. Research collaboration and productivity: is there correlation? High Educ. 2009. https://doi.org/10.1007/s10734-008-9139-z .
Article Google Scholar
De Solla Price DJ. Little science, big science. New York: Columbia University Press; 1963.
Book Google Scholar
Narin F, Carpenter MP. National publication and citation comparisons. JASIS&T. 1975. https://doi.org/10.1002/asi.4630260203 .
Beaver D, Rosen R. Studies in scientific collaboration: part III – professionalization and the natural history of modern scientific co-authorship. Scientometrics. 1979. https://doi.org/10.1007/BF02016308 .
Katz JS, Martin BR. What is research collaboration? Res Policy. 1997. https://doi.org/10.1016/S0048-7333(96)00917-1 .
Clark BY, Llorens JJ. Investments in scientific research: examining the funding threshold effects on scientific collaboration and variation by academic discipline. PSJ. 2012. https://doi.org/10.1111/j.1541-0072.2012.00470.x .
Bozeman B, Fay D, Slade CP. Research collaboration in universities and academic entrepreneurship: the-state-of-the-art. J Technol Transf. 2013. https://doi.org/10.1007/s10961-012-9281-8 .
Van Raan AF. Measuring science. In: Moed HF, Glänzel W, Schmoch U, editors. Handbook of quantitative science and technology research: the use of patent and publication statistics in studies of S&T systems. Dordrecht: Springer; 2004. p. 19–50. https://doi.org/10.1007/1-4020-2755-9_2 .
Chapter Google Scholar
Lotka AJ. The frequency distribution of scientific productivity. J Wash Acad Sci. 1926;16:317–23.
Google Scholar
De Solla Price DJ, Beaver D. Collaboration in an invisible college. Am Psychol. 1966. https://doi.org/10.1037/h0024051 .
Zuckerman H. Nobel laureates in science: patterns of productivity, collaboration, and authorship. Am Sociol Rev. 1967;32:391–403.
Article CAS PubMed Google Scholar
Morrison PS, Dobbie G, McDonald FJ. Research collaboration among university scientists. High Educ Res Dev. 2003. https://doi.org/10.1080/0729436032000145149 .
Lee S, Bozeman B. The impact of research collaboration on scientific productivity. Soc Stud Sci. 2005. https://doi.org/10.1177/0306312705052359 .
Beaver DB. Collaboration and teamwork in physics. Czechoslov J Phys B. 1986. https://doi.org/10.1007/BF01599717 .
Acedo FJ, Barroso C, Casanueva C, Galán JL. Co-authorship in management and organizational studies: an empirical and network analysis. J Manag Stud. 2006. https://doi.org/10.1111/j.1467-6486.2006.00625.x .
Wuchty S, Jones BF, Uzzi B. The increasing dominance of teams in production of knowledge. Science. 2007. https://doi.org/10.1126/science.1136099 .
Article PubMed Google Scholar
Sooryamoorthy R. Do types of collaboration change citation? Collaboration and citation patterns of South African science publications. Scientometrics. 2009. https://doi.org/10.1007/s11192-009-2126-z .
Gazni A, Didegah F. Investigating different types of research collaboration and citation impact: a case study of Harvard University’s publications. Scientometrics. 2011. https://doi.org/10.1007/s11192-011-0343-8 .
Landry R, Traore N, Godin B. An econometric analysis of the effect of collaboration on academic research productivity. High Educ. 1996. https://doi.org/10.1007/BF00138868 .
Laband DN, Tollison RD. Intellectual collaboration. J Political Econ. 2000. https://doi.org/10.1086/262132 .
Van Raan A. The influence of international collaboration on the impact of research results: some simple mathematical considerations concerning the role of self-citations. Scientometrics. 1998;42(3):423–8.
Glänzel W. National characteristics in international scientific co-authorship relations. Scientometrics. 2001. https://doi.org/10.1023/a:1010512628145 .
Glänzel W, Schubert A. Analysing scientific networks through co-authorship. In: Moed HF, Glänzel W, Schmoch U, editors. Handbook of quantitative science and technology research: the use of patent and publication statistics in studies of S&T systems. Dordrecht: Kluwer; 2004. p. 257–76. https://doi.org/10.1007/1-4020-2755-9_20 .
Didegah F, Thelwall M. Which factors help authors produce the highest impact research? Collaboration, journal and document properties. J Informetr. 2013. https://doi.org/10.1016/J.JOI.2013.08.006 .
Thelwall M, Maflahi N. Academic collaboration rates and citation associations vary substantially between countries and fields. J Assoc Inf Sci Technol. 2020. https://doi.org/10.1002/asi.24315 .
Archibugi D, Coco A. International partnerships for knowledge in business and academia: a comparison between Europe and the USA. Technovation. 2004. https://doi.org/10.1016/S0166-4972(03)00141-X .
Levi M, Sluiter HE, Van Leeuwen T, Rook M, Peeters G. Medisch-wetenschappelijk onderzoek in Nederland: Hoge kwaliteit door samenwerking UMC’s en opleidingsziekenhuizen. NTvG. 2013;157:A6081.
Abramo G, D’Angelo CA, Di Costa F. University-industry research collaboration: a model to assess university capability. High Educ. 2011. https://doi.org/10.48550/arXiv.1811.01763 .
Centraal Bureau voor de Statistiek. Health care institutions; key figures, finance and personnel. https://www.cbs.nl/nl-nl/cijfers/detail/83652ENG . Accessed 6 Mar 2024.
Postma J, Zuiderent-Jerak T. Beyond volume indicators and centralization: toward a broad perspective on policy for improving quality of emergency care. Ann Emerg Med. 2017. https://doi.org/10.1016/j.annemergmed.2017.02.020 .
Postma JP, Van Dongen-Leunis A, Van Hakkaart-van Roijen L, Bal RA. Evaluatie Topzorg. Een evaluatie van 4 jaar specialistische zorg en wetenschappelijk onderzoek in het St. Antonius Ziekenhuis, het Oogziekenhuis en het ETZ. Rotterdam: Erasmus School of Health Policy & Management; 2018.
Gieryn TF. Boundary-work and the demarcation of science from non-science: strains and interests in professional ideologies of scientists. Am Sociol Rev. 1983. https://doi.org/10.2307/2095325 .
Gieryn TF. Cultural boundaries of science: credibility on the line. Chicago: University of Chicago Press; 1999.
Abbott A. The system of professions. Chicago: University of Chicago Press; 1988.
Santos FM, Eisenhardt KM. Organizational boundaries and theories of organization. Organ Sci. 2005. https://doi.org/10.1287/orsc.1050.0152 .
Chreim S, Langley A, Comeau-Vallée M, Huq JL, Reay T. Leadership as boundary work in healthcare teams. Leadership. 2013. https://doi.org/10.1177/174271501246 .
Waring J, Crompton A, Overton C, Roe B. Decentering health research networks: framing collaboration in the context of narrative incompatibility and regional geo-politics. Public Policy Adm. 2022. https://doi.org/10.1177/0952076720911686 .
Siaw CA, Sarpong D. Dynamic exchange capabilities for value co-creation in ecosystems. J Bus Res. 2021. https://doi.org/10.1016/j.jbusres.2021.05.060 .
Velter M, Bitzer V, Bocken N, Kemp R. Boundary work for collaborative sustainable business model innovation: the journey of a Dutch SME. J Bus Models. 2021. https://doi.org/10.5278/jbm.v9i4.6267 .
Bednarek AT, Wyborn C, Cvitanovic C, Meyer R, Colvin RM, Addison PF, et al. Boundary spanning at the science–policy interface: the practitioners’ perspectives. Sustain Sci. 2018. https://doi.org/10.1007/s11625-018-0550-9 .
Article PubMed PubMed Central Google Scholar
Neal JW, Neal ZP, Brutzman B. Defining brokers, intermediaries, and boundary spanners: a systematic review. Evid Policy. 2022. https://doi.org/10.1332/174426420X16083745764324 .
Van Oijen JCF, Wallenburg I, Bal R, Grit KJ. Institutional work to maintain, repair, and improve the regulatory regime: how actors respond to external challenges in the public supervision of ongoing clinical trials in the Netherlands. PLoS ONE. 2020. https://doi.org/10.1371/journal.pone.0236545 .
Carlile PR. Transferring, translating, and transforming: an integrative framework for managing knowledge across boundaries. Organ Sci. 2004. https://doi.org/10.1287/ORSC.1040.0094 .
Orlikowski WJ. Knowing in practice: enacting a collective capability in distributed organizing. Organ Sci. 2002. https://doi.org/10.1287/orsc.13.3.249.2776 .
Goodrich KA, Sjostrom KD, Vaughan C, Nichols L, Bednarek A, Lemos MC. Who are boundary spanners and how can we support them in making knowledge more actionable in sustainability fields? Curr Opin Environ Sustain. 2020. https://doi.org/10.1016/j.cosust.2020.01.001 .
Joo J, Selingo J, Alamuddin R. Unlocking the power of collaboration. How to develop a successful collaborative network in and around higher education. Ithaka S+R; 2019.
McDonald J, Jayasuriya R, Harris MF. The influence of power dynamics and trust on multidisciplinary collaboration: a qualitative case study of type 2 diabetes mellitus. BMC Health Serv Res. 2012. https://doi.org/10.1186/1472-6963-12-63 .
Harrington S, Fox S, Molinder HT. Power, partnership, and negotiations: the limits of collaboration. WPA-LOGAN. 1998;21:52–64.
Soper B, Hinrichs S, Drabble S, Yaqub O, Marjanovic S, Hanney S, et al. Delivering the aims of the Collaborations for Leadership in Applied Health Research and Care: understanding their strategies and contributions. Health Serv Deliv Res. 2015. https://doi.org/10.3310/hsdr03250 .
Lockett A, El Enany N, Currie G, Oborn E, Barrett M, Racko G, Bishop S, Waring J. A formative evaluation of Collaboration for Leadership in Applied Health Research and Care (CLAHRC): institutional entrepreneurship for service innovation. Health Serv Deliv Res. 2014. https://doi.org/10.3310/hsdr02310 .
Engeström Y. The horizontal dimension of expansive learning: weaving a texture of cognitive trails in the terrain of health care in Helsinki. In: Achtenhagen F, John EG, editors. Milestones of vocational and occupational education and training. Bielefelt: W Bertelmanns Verlag; 2003. p. 152–79.
Gezondheidsraad. Onderzoek waarvan je beter wordt: Een heroriëntatie op umc-onderzoek. Den Haag: Gezondheidsraad; 2016.
van der Woerd O, Schuurmans J, Wallenburg I, van der Scheer W, Bal R. Heading for health policy reform: transforming regions of care from geographical place into governance object. Policy Politics. 2024. https://doi.org/10.1332/03055736Y2024D000000030 .
Iping R, Kroon M, Steegers C, van Leeuwen T. A research intelligence approach to assess the research impact of the Dutch university medical centers. Health Res Policy Syst. 2022. https://doi.org/10.1186/s12961-022-00926-y .
Rycroft-Malone J, Burton C, Wilkinson JE, Harvey G, McCormack B, Baker R, et al. Collective action for knowledge moblisation: a realist evaluation of the collaborations for leadership in applied Health Research and care. Health Serv Deliv Res. 2015. https://doi.org/10.3310/hsdr03440 .
Kislov R, Harvey G, Walshe K. Collaborations for leadership in applied health research and care: lessons from the theory of communities of practice. Implement Sci. 2011. https://doi.org/10.1186/1748-5908-6-64 .
Harvey G, Fitzgerald L, Fielden S, McBride A, Waterman H, Bamford D, et al. The NIHR collaboration for leadership in applied health research and care (CLAHRC) for Greater Manchester: combining empirical, theoretical and experiential evidence to design and evaluate a large-scale implementation strategy. Implement Sci. 2011. https://doi.org/10.1186/1748-5908-6-96 .
Currie G, Lockett A, Enany NE. From what we know to what we do: lessons learned from the translational CLAHRC initiative in England. J Health Serv Res Policy. 2013. https://doi.org/10.1177/1355819613500484 .
Hurley TJ. Collaborative leadership: engaging collective intelligence to achieve results across organisational boundaries. White Paper. Oxford Leadership. 2011.
DORA. The declaration. https://sfdora.org/read . Accessed 6 Mar 2024.
O’Leary R, Gerard C. Collaboration across boundaries: insights and tips from federal senior executives. Washington: IBM Center for The Business of Government; 2012.
Traag VA, Waltman L, Van Eck NJ. From Louvain to Leiden: guaranteeing well-connected communities. Sci Rep. 2019;9(1):5223. https://doi.org/10.1038/s41598-019-41695-z .
Article CAS Google Scholar
Download references
Acknowledgements
The authors thank the two reviewers and the members of the Health Care Governance department of Erasmus School of Health Policy & Management, Erasmus University Rotterdam for their helpful comments on earlier drafts. We are particularly indebted to Kor Grit for his helpful comments and critical appraisal of this paper.
The TopCare program was funded by the Netherlands Organization for Health Research and Development (ZonMw) ( www.zonmw.nl/en ) under Grant [Number 80-84200-98-14001]. ZonMw had no role in the design or conduct of the study; the collection, management, analysis and interpretation of the data; or the preparation, review and approval of the manuscript.
Author information
Authors and affiliations.
Erasmus School of Health Policy & Management, Erasmus University Rotterdam, P.O. Box 1738, 3000 DR, Rotterdam, The Netherlands
Jacqueline C. F. van Oijen, Annemieke van Dongen-Leunis, Jeroen Postma & Roland Bal
Centre for Science and Technology Studies, Leiden University, Leiden, The Netherlands
Thed van Leeuwen
You can also search for this author in PubMed Google Scholar
Contributions
Conceptualization: J.v.O., A.v.D.L. and T.v.L. (bibliometric analysis of UMCs and non-academic hospitals); A.v.D.L. and T.v.L. (bibliometric analysis of TopCare domains); and J.v.O., J.P. and R.B. (ethnographic interviews in the TopCare program). Formal analysis: J.v.O., A.v.D.L. and T.v.L. (bibliometric analysis of UMCs and non-academic hospitals); A.v.D.L and T.v.L. (bibliometric analysis of TopCare domains); J.v.O., J.B. and R.B. (ethnographic interviews in the TopCare program). Funding acquisition: R.B. (TopCare program). Investigation: A.v.D.L and T.v.L. (database analysis of UMCs and non-academic hospitals and TopCare domains) and J.v.O., J.B. and R.B. (ethnographic interviews in the TopCare program). Methodology: J.v.O., A.v.D.L and T.v.L. (bibliometric analysis of UMCs and non-academic hospitals); A.v.D.L and T.v.L. (bibliometric analysis of TopCare domains); and J.v.O., J.B. and R.B. (ethnographic interviews in the TopCare program). Project administration: T.v.L. and A.v.D.L (bibliometric analysis of UMCs and non-academic hospitals and TopCare domains) and J.P. (TopCare program). Supervision: T.v.L. (bibliometric analysis of UMCs and non-academic hospitals and TopCare domains) and R.B. (bibliometric analysis of UMCs and non-academic hospitals and TopCare domains, and ethnographic interviews in the TopCare program). Visualization: A.v.D.L and T.v.L. (bibliometric analysis of UMCs and non-academic hospitals and TopCare domains). Original draft: J.v.O., A.v.D.L and R.B. Draft & revision: J.v.O., A.v.D.L, J.P., T.v.L. and R.B. All authors read and approved the final manuscript (and agreed to be both personally accountable for their own contributions and to ensure that questions related to the accuracy or integrity of any part of the work, even ones in which the author was not personally involved, would be appropriately investigated and resolved and that the resolution would be documented in the literature).
Corresponding author
Correspondence to Jacqueline C. F. van Oijen .
Ethics declarations
Ethics approval and consent to participate.
Not applicable; at the time we were conducting the research, ethical approval was not required. Nowadays our facility has an Ethics Committee that assesses research proposals involving human subjects (including interview studies), but this was not the case then. This study is not subject to the Dutch Medical Research Involving Human Subjects Act (WMO); it concerns collaboration on medical research in TopCare non-academic hospitals. For research not subject to the WMO, local policy and applicable procedures apply; as the TopCare program began in 2014, there were, as yet, no institutional rules in this area.
Consent for publication
Member check is part of our policy of informed consent of respondents and consent for publication. Specifically, we gave respondents the opportunity to peruse and add to quotes from their semi-structured interviews and to confirm our interpretation. The focus was on confirming and amending the quote and verifying the interpretation. The research team discussed the feedback received from the respondents and weighed it against the context of data analysis. Any disagreement on a respondent’s feedback was discussed directly with the respondent until consensus was reached. The STZ and NFU have given permission to use the data collected by CWTS on behalf of the NFU and STZ for the bibliometric analysis of this study. They have taken note of the results of this study and agreed to its publication.
Competing interests
The authors declare that they have no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
See Fig. 4 and Tables 5 , 6 , 7 , 8 , 9 , 10 and 11 .
UMCs produce 18 times (= 27,592/1503) more SI, four times (= 42,557/10880) more NC and 14 times (82,540/5896) more IC publications than non-academic hospitals.
Of all publications, 89% (= 152,688/170967) are attributed to UMCs and 11% (18,279/170967) to non-academic hospitals.
Joint publications in national collaboration: 82% (= 8943/10880) non-academic hospitals and 21% (= 8943/42557) UMCs.
Joint international publications: 66% (= 3874/5896) non-academic hospitals and 5% (= 3874/82540) UMCs.
Joint publications: 70% (= 12,816/18279) non-academic hospitals and 8% (= 12,816/152688) UMCs.
Relationship between joint publications and total publications in each type of collaboration: 17% (= 8943/53436) national collaboration and 4% (= 3874/88435) international collaboration.

Types of collaboration involving TopCare hospitals #1 and #2 between 2010 and 2016. #, total number of publications
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
van Oijen, J.C.F., van Dongen-Leunis, A., Postma, J. et al. Achieving research impact in medical research through collaboration across organizational boundaries: Insights from a mixed methods study in the Netherlands. Health Res Policy Sys 22 , 72 (2024). https://doi.org/10.1186/s12961-024-01157-z
Download citation
Received : 31 December 2022
Accepted : 31 May 2024
Published : 25 June 2024
DOI : https://doi.org/10.1186/s12961-024-01157-z
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Collaboration
- Research impact
- Bibliometric analysis
- Organizational boundary work
Health Research Policy and Systems
ISSN: 1478-4505
- Submission enquiries: Access here and click Contact Us
- General enquiries: [email protected]
Pardon Our Interruption
As you were browsing something about your browser made us think you were a bot. There are a few reasons this might happen:
- You've disabled JavaScript in your web browser.
- You're a power user moving through this website with super-human speed.
- You've disabled cookies in your web browser.
- A third-party browser plugin, such as Ghostery or NoScript, is preventing JavaScript from running. Additional information is available in this support article .
To regain access, please make sure that cookies and JavaScript are enabled before reloading the page.
- Open access
- Published: 22 June 2024
Saliency-driven explainable deep learning in medical imaging: bridging visual explainability and statistical quantitative analysis
- Yusuf Brima 1 &
- Marcellin Atemkeng 2
BioData Mining volume 17 , Article number: 18 ( 2024 ) Cite this article
223 Accesses
Metrics details
Deep learning shows great promise for medical image analysis but often lacks explainability, hindering its adoption in healthcare. Attribution techniques that explain model reasoning can potentially increase trust in deep learning among clinical stakeholders. In the literature, much of the research on attribution in medical imaging focuses on visual inspection rather than statistical quantitative analysis.
In this paper, we proposed an image-based saliency framework to enhance the explainability of deep learning models in medical image analysis. We use adaptive path-based gradient integration, gradient-free techniques, and class activation mapping along with its derivatives to attribute predictions from brain tumor MRI and COVID-19 chest X-ray datasets made by recent deep convolutional neural network models.
The proposed framework integrates qualitative and statistical quantitative assessments, employing Accuracy Information Curves (AICs) and Softmax Information Curves (SICs) to measure the effectiveness of saliency methods in retaining critical image information and their correlation with model predictions. Visual inspections indicate that methods such as ScoreCAM, XRAI, GradCAM, and GradCAM++ consistently produce focused and clinically interpretable attribution maps. These methods highlighted possible biomarkers, exposed model biases, and offered insights into the links between input features and predictions, demonstrating their ability to elucidate model reasoning on these datasets. Empirical evaluations reveal that ScoreCAM and XRAI are particularly effective in retaining relevant image regions, as reflected in their higher AUC values. However, SICs highlight variability, with instances of random saliency masks outperforming established methods, emphasizing the need for combining visual and empirical metrics for a comprehensive evaluation.
The results underscore the importance of selecting appropriate saliency methods for specific medical imaging tasks and suggest that combining qualitative and quantitative approaches can enhance the transparency, trustworthiness, and clinical adoption of deep learning models in healthcare. This study advances model explainability to increase trust in deep learning among healthcare stakeholders by revealing the rationale behind predictions. Future research should refine empirical metrics for stability and reliability, include more diverse imaging modalities, and focus on improving model explainability to support clinical decision-making.
Peer Review reports
The field of medical image analysis has seen significant advancements in explainability methods for deep learning (DL) models, driven by the imperative for trustworthy artificial intelligence systems in healthcare [ 1 ]. Traditional medical imaging modalities like Computed Tomography (CT), Magnetic Resonance Imaging (MRI), Functional Magnetic Resonance Imaging (fMRI), Positron Emission Tomography (PET), Mammography, Ultrasound, and X-ray play a crucial role in disease detection and diagnosis, often relying on the expertise of radiologists and physicians [ 2 ]. However, the healthcare field faces a growing demand for skilled professionals, leading to potential fatigue and highlighting the need for computer-aided diagnostic (CAD) tools. The rapid advancements in DL architectures and compute have fueled significant progress in automated medical image analysis [ 3 , 4 , 5 , 6 , 7 ]. The maturation of DL offers a promising solution, accelerating the adoption of computer-assisted systems to support experts and reduce reliance on manual analysis. DL holds particular promise for democratizing healthcare globally by alleviating the cost burden associated with scarce expertise [ 8 ]. However, successful clinical adoption hinges on establishing trust in the robustness and explainability of these models [ 9 ]. Despite their inherent complexity, DL models can be illuminated to understand their inference mechanisms, that is, how they process medical images to generate predictions . An adjacent line of work, explainability , focuses on understanding the inner workings of the models, while explainability focuses on explaining the decisions made by these models. Explainable models enable a human-in-the-loop approach, enhancing diagnostic performance through collaboration between domain experts and artificial intelligence.
Various techniques have been proposed, each with distinct advantages and limitations. Concept learning, for example, facilitates multi-stage prediction by leveraging high-level concepts. Studies such as [ 10 , 11 , 12 ] illustrate the potential of concept learning in disease categorization. However, these methods often require extensive annotation to define concepts accurately and risk information leakage if concepts do not align well with the disease pathology. Case-Based Models (CBMs) learn class-specific, disentangled representations and feature mappings, achieving final classification through similarity measurements between input images and stored base templates [ 13 , 14 , 15 ]. While CBMs are robust to noise and compression artifacts, their training is complex, particularly for the large and diverse datasets typical of medical imaging. Counterfactual explanation methods generate pseudo-realistic perturbations of input images to produce opposite predictions, aiming to identify influential features for the model’s original prediction. However, generating realistic perturbations for medical images, which often contain subtle anatomical details, is challenging and can lead to misleading explanations [ 16 , 17 , 18 , 19 , 20 , 21 , 22 , 23 ]. Unrealistic perturbations compromise the trustworthiness of these explanations. Another approach involves visualizing internal network representations of learned features in CNN kernels [ 24 ]. Interpreting these feature maps in the context of medical image analysis is difficult due to the abstract nature of the features learned by DL models [ 25 , 26 ]. This abstraction challenges human experts in deriving clinically meaningful insights.
Attribution maps are visual representations that highlight regions of an image most relevant to the predictions made by a DL model. Serving as potent post-hoc explainability tools, these maps provide crucial insights into how models make decisions based on input images. Several studies have demonstrated the application of attribution maps in medical imaging tasks. For instance, Bohle et al. [ 27 ] utilized layer-wise relevance propagation to elucidate deep neural network decisions in MRI-based Alzheimer’s disease classification. Camalan et al. [ 28 ] employed a deep CNN-based Grad-CAM approach for classifying oral lesions in clinical photographs. Similarly, Kermany et al. [ 29 ] applied Grad-CAM for oral dysplasia classification. Shi et al. presented an explainable attention-based model for COVID-19 automatic diagnosis, showcasing the integration of attention mechanisms to improve explainability in radiographic imaging [ 30 ]. Another study by Shi et al. introduced an attention transfer deep neural network for COVID-19 automatic diagnosis, further enhancing the explainability and performance of diagnostic models [ 31 ]. Recently, Nhlapho et al. [ 32 ] presented an overview of select image-based attribution methods for brain tumor detection, though their approach lacked ground-truth segmentation masks and did not quantitatively evaluate the chosen saliency methods.
Building on these efforts, our research leverages both gradient-based and gradient-free image-based saliency methods. However, the deployment of attribution maps alone is insufficient for establishing comprehensive model explainability. A rigorous evaluation framework is essential. We propose a comprehensive evaluation framework that extends beyond qualitative assessment. This framework includes metrics specifically designed to evaluate image-based saliency methods. By incorporating performance information curves (PICs) such as Accuracy Information Curves (AICs) and Softmax Information Curves (SICs), we objectively assess the correlation between saliency map intensity and model predictions. This robust evaluation aims to enhance the transparency and trustworthiness of DL models in clinical settings. Given this context, this paper centers on How effective are state-of-the-art (SoTA) image-based saliency methods in aiding the explainability of DL models for medical image analysis tasks? By investigating this question, we aim to contribute to the broader effort of enhancing the trustworthiness, transparency, and reliability of DL applications in healthcare.
To this end, we leverage the proposed framework to systematically analyze model predictions on brain tumor MRI [ 33 ] and COVID-19 chest X-ray [ 34 ] datasets. Resulting attribution maps highlight the salient features within the input images that most significantly influence the model’s predictions. By evaluating these techniques both qualitatively and quantitatively across different SoTA DL architectures and the aforementioned medical imaging modalities, we aim to assess their effectiveness in promoting explainability. Our assessment is focused on several key aspects:
Clarity of Insights: Do these saliency methods provide clear non-spurious and explainable insights into the relationship between medical image features and model predictions? We achieve this assessment by comparing the highlighted features in the attribution maps with the known anatomical structures and disease signatures relevant to the specific medical imaging task (e.g., brain tumor location in MRI).
Biomarker Identification: Can these techniques aid in identifying potential biomarkers for disease detection or classification? We investigate whether the saliency methods consistently highlight specific image features that correlate with known or emerging disease biomarkers. This analysis can provide valuable insights into potential new avenues for clinical research.
Model Bias Detection: Do saliency methods help uncover potential biases within the DL used for medical image analysis? We explore whether the saliency maps reveal a consistent focus on irrelevant features or artifacts that might not be clinically meaningful. This analysis can help identify potential biases in the training data or model architecture that may require mitigation strategies.
Quantitative Effectiveness: How quantitatively effective are these methods in capturing the relationship between image features and model predictions? We explore this by employing PICs such as AICs and SICs. These metrics assess the correlation between the saliency map intensity and the model’s accuracy or class probabilities.
Contributions
We proposed a comprehensive framework to evaluate SoTA image-based saliency methods applied to Deep Convolutional Neural Networks (CNNs) for medical image classification tasks. Our study included MRI and X-ray modalities, focusing on tasks such as brain tumor classification and COVID-19 detection within these respective imaging techniques. For a novel quantitative evaluation, beyond the visual inspection of saliency maps, we used AICs and SICs to measure the effectiveness of the saliency methods. AICs measure the relationship between the model’s predicted accuracy and the intensity of the saliency map. A strong correlation between high-intensity areas on the saliency map and high model accuracy indicates that the method effectively emphasizes relevant image features. Meanwhile, SICs examine the link between the saliency map and the model’s class probabilities (softmax outputs). An effective saliency method should highlight areas that guide the model toward the correct classification, corresponding to the disease’s localized region in the image.
To our knowledge, this study is the first empirical investigation that uses AICs and SICs to assess saliency methods in medical image analysis using DL. This offers a solid and objective framework for determining the efficacy of saliency methods in elucidating the decision-making mechanisms of DL models for classification and detection tasks in medical imaging.
Paper outline
The paper is organized as follows. Materials and methods section describes the materials and methods employed in this paper. Results section presents experimental results on two datasets. Conclusion section concludes and proposes future directions.
Materials and methods
This section introduces the deep CNN models used for conducting experiments. We also detail the training process for these models and present our proposed framework, which provides an in-depth explanation of image-based saliency methods and their direct applications to DL-based models in medical image analysis.
We use two medical image data modalities to test the attribution framework. The choice of the two modalities depends on the availability of data. Other types of modalities are also applicable to the attribution framework. We leave this for future work.
The brain tumors MRI dataset [ 33 ] is used. MRI data typically comprises a 3D tensor. However, the dataset provided in [ 33 ] is transformed from 3D tensors into 2D slices. Specifically, it includes contrast-enhanced MRI (CE-MRI) T1-weighted images, amounting to 3064 slices obtained from 233 patients. It includes 708 Meningiomas, 1426 Gliomas, and 930 Pituitary tumors. In each slice, the tumor boundary is manually delineated and verified by radiologists. We have plotted 16 random samples from the three classes with tumor borders depicted in red as shown in Fig. 1 . These 2D slices of T1-weighted images train standard deep CNNs for a 3-class classification task into Glioma, Meningioma, and Pituitary tumors. The input to each model is a \(\mathbb {R}^{225\times 225\times 1}\) tensor that is a resized version of the original \(\mathbb {R}^{512\times 512}\) image slices primarily due to computational concerns. Unlike the brain cancer MRI dataset which comes with segmentation masks from experts in the field, the COVID-19 X-ray dataset [ 34 ] used in this work has no ground truth segmentation masks. This was chosen as an edge-case analysis because a vast majority of datasets do not have segmentation masks. This dataset was curated from multiple international COVID-19 X-ray testing facilities during several periods. The dataset is made up of an unbalanced percentage of the four classes in which we have 48.2 \(\%\) normal X-ray images, 28.4 \(\%\) cases with lung opacity, 17.1 \(\%\) of COVID-19 patients and \(6.4\%\) of patients with viral pneumonia of the 19,820 total images in the dataset. This unbalanced nature of the dataset comes with its classification challenges, which has prompted several researchers to implement DL methods to classify the dataset. Out of the four classes, for consistency with the other datasets used in this work, we choose to classify three classes (i.e., Normal, Lung Opacity, and COVID-19). For an in-depth discussion of works that deal with this dataset, we refer to [ 35 ]. Figure 2 shows 16 selected random samples. Table 1 summarizes those three datasets.

MRI Scans of Various Brain Tumors with Annotated Tumor Regions. This figure shows MRI images of different brain tumor types, with the tumor region boundaries highlighted in red. The tumor types include pituitary tumors, gliomas, and meningiomas. Each image presents a different view (axial, sagittal, or coronal) of the brain, illustrating the diversity in tumor appearance and location

Sample chest X-ray images from the dataset used in this study, labeled with their respective conditions. The conditions include Normal, Lung opacity, and Covid. The dataset was curated from multiple international COVID-19 X-ray testing centers during several periods. The diversity in conditions showcases the varying features that the models need to identify for accurate classification
Deep learning architectures
We use 9 standard CNN architectures: Visual Geometric Group (VGG16 and VGG19 [ 7 ]), Deep Residual Network (ResNet50, ResNet50V2) [ 4 ], Densely Connected Convolutional Networks (DenseNet) [ 36 ], DL with Depthwise Separable Convolutions (Xception) [ 5 ], Going deeper with convolutions (Inception) [ 37 ], a hybrid deep Inception and ResNet and EfficientNet: Rethinking model scaling for convolutional neural networks [ 38 ] for classifying COVID-19 X-ray images and brain tumors from the T1-weighted MRI slices. The choice of these deep models is explained by the fact that they are modern techniques that are widely used in solving vision tasks and by extension medical image feature extraction for prediction.
Image-based saliency methods and proposed framework
To facilitate the explainability of model inference mechanisms, which is crucial for building trust in clinical applications of DL-based CAD systems, we have investigated a variety of saliency methods. These saliency methods are integrated into the proposed framework, depicted in Fig. 3 . According to [ 39 ], effective attribution methods must satisfy the fundamental axioms of Sensitivity and Implementation Invariance . All selected saliency methods in this study adhere to these axioms.

An illustration of model development and explainability pipeline for a path-based saliency method. A dataset of m samples say T1-weighted contrast-enhanced image slices, for example, is the input to a standard CNN classification model depicted in the figure as \(h(\cdot )\) that learns the non-linear mapping of the features to the output labels. \(h(\cdot )\) is utilized with an attribution operator \(A_h\) to attribute salient features \(\hat{\textbf{x}}\) of the input image. \(A_h\) is an operator that can be used with varied different architectures. This proposed framework is general and can be applied to any problem instances where explainability is vital
The saliency methods evaluated include both gradient-based and gradient-free techniques. Adaptive path-based integrated gradients (APMs), which are gradient-based, are useful in reducing noise in attribution maps, which is critical for medical imaging diagnostics. Gradient-free techniques do not rely on model gradients, making them suitable for non-differentiable models or scenarios where gradients are noisy. Class Activation Mapping (CAM) and its derivatives are effective in highlighting high-level activations for visual localization, providing clear insights into decision-making processes. Each method’s distinct characteristics justify their inclusion and comparison in this study, aimed at enhancing diagnostic and patient outcomes in medical imaging.
The specific saliency methods employed in this study include several prominent techniques. Vanilla Gradient [ 40 ] computes the gradient of the output with respect to the input image, highlighting the most influential pixels for the target class prediction. Integrated Gradients (IG)[ 39 ], which are gradient-based, attribute the model’s prediction to its input features by integrating the gradients along the path from a baseline to the input image. SmoothGrad IG [ 41 ] enhances IG by averaging the gradients of multiple noisy copies of the input image, thus reducing visual noise in the saliency maps. Guided Integrated Gradient (GIG) [ 42 ] refines IG further by guiding the gradients to produce less noisy and more interpretable saliency maps. eXplanation with Ranked Area Integrals (XRAI) [ 43 ] generates region-based attributions by ranking areas based on their contribution to the prediction, providing a more holistic view of important regions. GradCAM [ 21 ] uses the gradients of the target class flowing into the final convolutional layer to produce a coarse localization map of important regions in the image. GradCAM++ [ 44 ] improves upon GradCAM by providing better localization by considering the importance of each neuron in the last convolutional layer. ScoreCAM [ 45 ], unlike gradient-based methods, uses the model’s confidence scores to weigh the importance of each activation map, potentially leading to more accurate and less noisy explanations.
These methods are integrated into the proposed framework to analyze the attribution of salient features in medical images. As shown in Fig. 3 , a dataset of m samples is input into a standard CNN classification model. The model, represented as \(h(\cdot )\) , learns the non-linear mapping of features to output labels. The trained model is then utilized together with an attribution operator \(A_h\) , which could be any of the saliency methods, to attribute salient features \(\hat{\textbf{x}}\) of the input image. This operator \(A_h\) is versatile and can be applied to any problem where explainability is essential for building trust in the model’s inference mechanism.
Quantitative and empirical assessment of saliency methods
In this work, we adapted and applied empirical methods from Kapishnikov et al. (2021) [ 42 ] for evaluating saliency frameworks in the field of medical image analysis, making slight adjustments to the image entropy calculation. Our adaptation maintained the core approach of using saliency methods to attribute importance to regions within medical images while tailoring them to meet the specific demands of medical imaging.
Our method for estimating image entropy involves computing the Shannon entropy of the image histogram. We begin by deriving the histogram of the original image with 256 bins and density normalization, followed by using the entropy computation as shown in Equation 1 . In contrast, their method estimates image entropy by determining the file size of the image after lossless compression and calculating the buffer length as a proxy for entropy. While both approaches aim to gauge the information content of an image, ours relies on pixel intensity distribution, while theirs assesses file size post-compression.
where, H ( X ) represents the entropy of the image X , \(p_i\) is the probability of occurrence of each intensity level i in the image histogram, and n is the total number of intensity levels (256 in our case).
Our approach provides a direct measure of the information content inherent in the pixel intensity distribution, capturing the relative importance of different intensity levels and offering a comprehensive understanding of the image’s complexity. In contrast, using file size post-compression as a proxy for entropy may not fully capture the nuances of the image’s content. By focusing on pixel intensity distribution, our approach offers a more intrinsic and nuanced measure of image information content, particularly crucial for tasks such as medical image analysis or pattern recognition.
This evaluation framework entails initiating the process with a completely blurred version of the medical image and incrementally reintroducing pixels identified as significant by the saliency method. We then measure the resulting image’s entropy and conduct classification tasks to correlate the model’s performance, such as accuracy, with the calculated entropy or information level for each medical image, resulting in Performance Information Curves (PICs). Thus, two variants of PICs were introduced – Accuracy Information Curve (AIC) and Softmax Information Curve (SIC) – to provide a more nuanced evaluation of the saliency methods’ effectiveness.
Experimental setup
We conducted all experiments on Nvidia Quadro RTX 8000 hardware, leveraging its robust computational capabilities to handle the extensive DL training processes. For the implementation, we used the Keras API with the TensorFlow backend, enabling efficient and flexible development of the CNNs.
In this section, we present a comprehensive analysis of our experimental findings, structured around three key questions: (i) How good are these models on standard classification performance metrics? (ii) How visually explainable are studied image-based saliency-based methods? (iii) How empirically comparable are image-based saliency methods?
How good are these models on standard classification performance metrics?
We evaluated the performance of the 9 DL model architectures on classification tasks using standard metrics such as F1 score and confusion matrices as depicted in Figs. 4 and 5 . Appendix 1 shows the optimal hyperparameters for training the DL models. The results provide insights into the effectiveness of each model in terms of classification accuracy and error distribution.

The F1 scores (top-panel) for each model are compared to assess their accuracy and robustness in classifying brain tumors into three categories: Meningioma, Glioma, and Pituitary tumor. The bottom-panel shows the confusion matrix for the top-performing model, InceptionResNetV2
The performance of various DL models on brain tumor MRI classification is illustrated in Fig. 4 . Figure 4 (top-panel) The bar plot presents the F1 scores of various DL model architectures evaluated on the brain MRI image testset classification task. The F1 scores for these models range from 0.76 to 0.95. The InceptionResNetV2 model achieves the highest F1 score of 0.95, indicating superior performance in accurately classifying brain tumors. EfficientNetB0, on the other hand, scores the lowest with an F1 score of 0.76, showing a relatively lower performance compared to the other models. Figure 4 (bottom-panel) shows the confusion matrix for the top-performing model, InceptionResNetV2, which displays the number of correctly and incorrectly classified cases for different types of brain tumors. The matrix shows that out of the 72 cases of Meningioma, 69 cases are correctly predicted, 1 case is misclassified as Glioma, and 2 cases are misclassified as Pituitary tumor. Out of the 143 cases of Glioma, 133 cases are correctly predicted, 10 cases are misclassified as Meningioma, and no case is misclassified as a Pituitary tumor. Out of the 92 Pituitary tumor cases, 91 cases are correctly predicted, 1 case is misclassified as Glioma, and no cases misclassified as Meningioma. This detailed breakdown demonstrates the model’s effectiveness in correctly identifying the majority of cases while highlighting specific areas where misclassifications occur, particularly in distinguishing between Meningioma and Glioma.
Figure 5 shows the performance comparison of different model architectures for COVID-19 X-ray image classification. The models were evaluated based on their ability to classify images into Normal, Lung Opacity, and COVID-19 categories. Figure 5 (top-panel) shows the F1 scores of various DL model architectures evaluated for COVID-19 classification. The F1 scores range from 0.87 to 0.89. The models perform consistently well, with minimal variation in F1 scores. Figure 5 (bottom-panel) shows the confusion matrix for the Xception model and provides a detailed view of its classification performance for chest X-ray images. The matrix shows that out of the 208 Lung opacity cases, 247 cases are correctly predicted, 1 case is misclassified as COVID-19, and 60 cases are misclassified as Normal. Out of the 19 COVID-19 cases, 7 cases are correctly predicted, 5 cases are misclassified as Lung opacity, and 7 cases are misclassified as Normal. Out of the 651 Normal cases, 621 cases are correctly predicted, no case is misclassified as COVID-19, and 30 cases are misclassified as Lung opacity. This confusion matrix highlights the Xception model’s strengths and weaknesses in COVID-19 classification. While it correctly identifies a large number of cases, there are notable misclassifications, particularly with Lung opacity being misclassified as Normal in 60 instances.

The F1 scores (top panel) for each model are compared to assess their accuracy and robustness in classifying chest X-ray images into three categories: Normal, Lung Opacity, and COVID-19. The bottom panel shows the confusion matrix for the top-performing model, Xception
The results from the F1 scores and confusion matrices demonstrate the effectiveness of various DL architectures in medical image classification tasks. InceptionResNetV2 consistently outperforms other models in brain tumor classification, achieving the highest F1 score and demonstrating excellent accuracy. The detailed confusion matrix for InceptionResNetV2 reveals minimal misclassifications, underscoring its reliability. The performance of models on the COVID-19 X-ray dataset shows high F1 scores across different architectures, with models like Xception also performing exceptionally well. The confusion matrix for Xception indicates strong classification capabilities, although some misclassifications are present, particularly in distinguishing between Lung opacity and Normal. These results underscore the importance of selecting appropriate model architectures for specific medical image classification tasks. The high F1 scores and detailed confusion matrices provide valuable insights into each model’s strengths and areas for improvement. However, the focus of this study is not to beat SoTA performance but to provide a basis for investigating the chosen saliency methods. Therefore, the top-performing models, InceptionResNetV2 for brain tumor classification and Xception for COVID-19 classification will serve as the basis for further analysis Sections in How visually explainable are image-based saliency methods? and How empirically comparable are image-based saliency methods? sections.
How visually explainable are image-based saliency methods?
Figure 6 presents the visualization of feature attributions for brain tumor classification using our proposed framework and various explainability methods applied to the Inception-ResNetV2 model. The attribution maps provide insights into the regions of the input images that significantly influence the model’s predictions for three types of brain tumors: Glioma, Meningioma, and Pituitary Tumor. The top row represents the input image with ground-truth tumor boundaries, and the other rows are attribution maps produced by each method.

Visualization of feature attributions for brain tumor classification using various explainability methods for the best-performing model, Inception-ResNetV2. This figure displays the feature attribution maps generated by different explainability techniques for the model on three types of brain tumors: Glioma, Meningioma, and Pituitary Tumor. The columns represent the input image with ground-truth tumor boundaries followed by the attribution maps produced by each method. From visual inspection, Fast XRAI 30% and ScoreCAM outperform other methods. For Glioma, ScoreCAM effectively focuses on the tumor regions. For Meningioma, ScoreCAM highlights some tumor regions, though the heatmap shows three regions instead of the actual two. Most other methods, except GradCAM++ for Glioma, generate coarse and noisy saliency maps, particularly Vanilla Gradient and SmoothGrad. Path-integration methods tend to be more susceptible to image edges compared to GradCAM, GradCAM++, and ScoreCAM methods
From visual inspection, Fast XRAI 30% and ScoreCAM outperform other methods. For Glioma, ScoreCAM effectively focuses on the tumor regions, providing clear and accurate attributions. For Meningioma, ScoreCAM highlights some tumor regions, although the heatmap shows three regions instead of the actual two. Other methods, such as Vanilla Gradient and SmoothGrad, produce coarse and noisy saliency maps. GradCAM and GradCAM++ generate more focused heatmaps but are still less precise than ScoreCAM. Path-integration methods, like Integrated Gradients, are more susceptible to highlighting image edges rather than the tumor regions, reducing their clinical explainability.
Figure 7 illustrates our proposed framework and application of various explainability methods on chest X-ray images for differentiating between Normal, Lung Opacity, and COVID-19 cases using the Xception model. The figure includes input X-ray images in the first row, followed by the attribution maps generated by different explainability methods. GradCAM, GradCAM++, and ScoreCAM tend to produce more focused and clinically explainable heatmaps, accurately highlighting relevant regions such as lung abnormalities. Other methods, like Vanilla Gradient and SmoothGrad, show more dispersed activations, making it challenging to interpret the model’s focus. XRAI and Fast XRAI provide region-based explanations that are intermediate, balancing between detailed local features and broader regions of interest.

Comparison of various explainability methods applied to chest X-ray images for distinguishing between Normal, Lung Opacity, and COVID-19 cases. The figure includes the input X-ray images in the first column, followed by visualization results from different explainability methods across the subsequent columns. For each condition (Normal, Lung Opacity, and COVID-19), the visualization techniques highlight different regions of the X-ray images that contribute to the model’s decision-making process. GradCAM, GradCAM++, and ScoreCAM methods tend to produce more focused and clinically interpretable heatmaps, while other methods show more dispersed activations. XRAI and Fast XRAI provide region-based explanations that are intermediate. Unlike the brain tumor dataset, this dataset does not have ground-truth biomarkers
The comparison of these saliency methods on the two datasets reveals the strengths and limitations of each technique in providing visual explanations. The presence of ground-truth biomarkers in the brain tumor dataset allows for a more nuanced assessment of the methods’ accuracy, whereas the COVID-19 dataset lacks such markers, relying on visual plausibility for evaluation. Overall, the findings suggest that methods like ScoreCAM, XRAI, GradCAM, and GradCAM++ offer more precise and clinically useful explanations, which are crucial for enhancing the transparency and trustworthiness of DL models in medical applications.
How empirically comparable are image-based saliency methods?
While visual explanations provide valuable qualitative insights, it is crucial to quantitatively evaluate the effectiveness of different saliency methods. In this section, we empirically compare these methods using PICs, specifically AICs and SICs. These metrics allow us to objectively assess the correlation between the saliency map intensity and the model’s predictions, providing a comprehensive understanding of each method’s performance.
In Fig. 8 , we present the aggregated AICs for over 1200 data points for various saliency methods applied to brain tumor MRI classification. The AUC values indicate the effectiveness of each method in retaining critical image information necessary for accurate classification. We observe that ScoreCAM achieves the highest AUC of 0.084, followed by XRAI at 0.033. This suggests that these methods are more effective in highlighting relevant regions for the model’s predictions. In contrast, methods like Guided IG, Vanilla IG, SmoothGrad IG, GradCAM, and GradCAM++ show minimal to zero AUC values, indicating limited effectiveness. These empirical results align with our visual inspection findings, where ScoreCAM and XRAI also provided clearer and more accurate attributions.

Aggregated AICs for evaluating the effectiveness of different saliency methods in attributing importance to regions of Brain Tumor MRI images for classification. The plot shows the prediction score as a function of the fraction of the image retained after reintroducing pixels identified as important by each saliency method. The area under the curve (AUC) values are provided for each method, indicating their performance in retaining critical image information necessary for accurate classification. ScoreCAM demonstrates the highest AUC of 0.084, suggesting it retains the most relevant image regions effectively, followed by XRAI with an AUC of 0.033. Other methods, including Guided IG, Vanilla IG, SmoothGrad IG, GradCAM, and GradCAM++, show minimal to zero AUC values, indicating limited effectiveness in this evaluation
Figure 9 illustrates the aggregated SICs for over 1300 samples of a brain tumor MRI dataset. The SIC evaluates how well the saliency methods identify regions that contribute to the model’s class probabilities. Surprisingly, the Random saliency mask shows the highest AUC of 0.705, followed by ScoreCAM (0.579), XRAI (0.574), and Guided IG (0.536). This anomaly indicates that the Random saliency mask may retain some critical regions by chance, emphasizing the need for careful interpretation of this metric. While Guided IG and ScoreCAM perform well, their AUC values suggest that these methods provide moderately effective attributions. These findings partly contrast with our visual evaluations and AICs, where ScoreCAM was a top performer, highlighting the importance of combining visual and empirical assessments for a holistic understanding.

Aggregated SICs for evaluating the effectiveness of different saliency methods in attributing importance to regions of Brain Tumor MRI images. The plot shows the prediction score as a function of the fraction of the image retained after reintroducing pixels identified as significant by each saliency method. The AUC values are provided for each method, indicating their performance in retaining critical image information necessary for accurate classification. Random saliency mask, surprisingly, exhibits the highest AUC of 0.705, followed by ScoreCAM (AUC=0.579), XRAI (AUC=0.574), and Guided IG (AUC=0.536). GradCAM, GradCAM++, Vanilla IG, and SmoothGrad IG show lower AUC values, indicating less effectiveness. This analysis highlights the variability in performance among different saliency methods when applied to medical image analysis, with the Random saliency mask unexpectedly showing the highest effectiveness under this specific evaluation criterion, which indicates the instability of this metric
In Fig. 10 , we evaluate the performance of various saliency methods on chest X-ray classification tasks using the Aggregated AIC. XRAI shows a noticeable deviation from the baseline with an AUC of 0.055, indicating some effectiveness in identifying relevant regions. Other methods, including ScoreCAM, Guided IG, and Vanilla IG, closely follow the random with AUC values of 0.000, suggesting limited effectiveness in this context. This observation is consistent with our visual inspection, where methods like ScoreCAM and XRAI provided intermediate-level explanations compared to others.

Aggregated AICs evaluating the performance of various saliency attribution methods on the chest X-ray image classification problem. The x-axis represents the fraction of the original image retained based on the saliency maps generated by each method. The y-axis shows the corresponding prediction score or accuracy. The curve for XRAI (AUC=0.055) deviates slightly from the baselines, indicating a minimal ability to identify relevant image regions for the classification task. Other methods, including ScoreCAM, Guided IG, GradCAM, and Vanilla IG, show negligible scores with an AUC of 0.000. This plot highlights the limited efficacy of these saliency techniques in attributing importance to salient regions within medical images for model explainability in this specific evaluation
Figure 11 shows the aggregated SICs for chest X-ray classification. Guided IG achieves the highest AUC of 0.735, outperforming the random mask (0.683), Vanilla IG (0.711), and SmoothGrad IG (0.639). This suggests that Guided IG is particularly effective in highlighting regions that influence the model’s class probabilities. The performance of XRAI, GradCAM, GradCAM++, and ScoreCAM is moderate, with lower AUC values (0.610, 0.594, 0.493, and 0.491 respectively), indicating less effective saliency attribution compared to Guided IG. These empirical results, similar to those for the brain tumor dataset, do not align with our visual analysis and AICs, where methods like XRAI, GradCAM, GradCAM++, and ScoreCAM provided more focused and explainable heatmaps. Thus, this metric should be cautiously used for evaluating saliency methods in given datasets.

Aggregated SICs comparing the performance of various saliency methods on the chest X-ray image classification task. The x-axis represents the fraction of the image retained based on the saliency maps, and the y-axis denotes the corresponding prediction score. The guided integrated gradients (Guided IG) method achieves the highest AUC of 0.735, outperforming the random mask (AUC=0.683), vanilla integrated gradients (Vanilla IG, AUC=0.711), SmoothGrad integrated gradients (SmoothGrad IG, AUC=0.639), and other saliency methods like XRAI (AUC=0.610), GradCAM (AUC=0.594), GradCAM++ (AUC=0.493), and ScoreCAM (AUC=0.491)
In summary, the empirical evaluation using AICs closely aligns with the visual results. However, SICs highlight the variability in performance among different saliency methods, with instances of a random mask outperforming established saliency methods. While our visual inspections revealed clear strengths for methods like ScoreCAM and GradCAM++, the empirical metrics provide a nuanced understanding of each method’s effectiveness in retaining and highlighting relevant image regions. By combining visual and empirical analyses, we ensure a robust evaluation of saliency methods, enhancing their applicability in clinical settings.
Further analysis results are included in Appendix 2 . We present a saliency analysis of the second and third-best models for each dataset. Additionally, AICs and SICs based on the entropy method from Kapishnikov et al. (2021) are provided in Appendix 2 “ Buffer-size-based AICs and SICs evaluations ” section. We also explore varied blurred versions of the top-performing saliency methods and their scores in Appendix 2 “ Computed saliency scores for top performing models for each image-based saliency method ” section.
In this study, we proposed a saliency-based attribution framework and assessed various state-of-the-art saliency methods for enhancing the explainability of DL models in medical image analysis, focusing on brain tumor classification using MRI scans and COVID-19 detection using chest X-ray images. Both qualitative and quantitative evaluations provided insights into these methods’ utility in clinical settings.
Qualitative assessments showed that ScoreCAM, XRAI, GradCAM, and GradCAM++ consistently produced focused and clinically interpretable attribution maps. These methods highlighted relevant regions that aligned with known anatomical structures and disease markers, thereby enhancing model transparency and trustworthiness.
This study is the first to use AICs and SICs to quantitatively evaluate these saliency methods for medical image analysis. The AICs confirmed that ScoreCAM and XRAI effectively retained critical image information, while SICs revealed variability, with random saliency masks sometimes outperforming established methods. This underscores the need for combining qualitative and quantitative metrics for a comprehensive evaluation. Our results highlight the importance of selecting appropriate saliency methods for specific tasks. While visual explanations are valuable, empirical metrics offer a nuanced understanding of each method’s effectiveness. Combining these approaches ensures robust assessments, fostering greater trust and adoption of DL models in clinical settings.
Future research should refine empirical metrics for stability and reliability across different models and datasets, include more diverse imaging modalities, and focus on enhancing model explainability to support clinical decision-making.
Availability of data and materials
This research used the brain tumor dataset from the School of Biomedical Engineering Southern Medical University, Guangzhou, contains 3064 T1-weighted contrast-enhanced images with three kinds of brain tumors. The data is publicly available at Brain Tumor Dataset . The Chest X-ray dataset is publicly available at: Chest X-Ray Images (Pneumonia) Dataset .
Code availability
The code is available at XAIBiomedical for reproducibility.
Giuste F, Shi W, Zhu Y, Naren T, Isgut M, Sha Y, et al. Explainable artificial intelligence methods in combating pandemics: A systematic review. IEEE Rev Biomed Eng. 2022;16:5–21.
Article Google Scholar
Litjens G, Kooi T, Bejnordi BE, Setio AAA, Ciompi F, Ghafoorian M, et al. A survey on deep learning in medical image analysis. Med Image Anal. 2017;42:60–88.
Article PubMed Google Scholar
Rumelhart DE, Hinton GE, Williams RJ. Learning representations by back-propagating errors. Nature. 1986;323(6088):533–6.
He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: Proceedings of the IEEE conference on computer vision and pattern recognition. 2016. pp. 770–8.
Chollet F. Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017. pp. 1251–258.
Krizhevsky A, Sutskever I, Hinton GE. Imagenet classification with deep convolutional neural networks. Adv Neural Inf Process Syst. 2012;25. https://proceedings.neurips.cc/paper/2012/hash/c399862d3b9d6b76c8436e924a68c45b-Abstract.html .
Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. 2014. https://arxiv.org/abs/1409.1556 . arXiv preprint arXiv:14091556.
Murtaza G, Shuib L, Abdul Wahab AW, Mujtaba G, Nweke HF, Al-garadi MA, et al. Deep learning-based breast cancer classification through medical imaging modalities: state of the art and research challenges. Artif Intell Rev. 2020;53(3):1655–720.
Reyes M, Meier R, Pereira S, Silva CA, Dahlweid FM, Tengg-Kobligk HV, et al. On the interpretability of artificial intelligence in radiology: challenges and opportunities. Radiol Artif Intell. 2020;2(3):e190043.
Article PubMed PubMed Central Google Scholar
Koh PW, Nguyen T, Tang YS, Mussmann S, Pierson E, Kim B, Liang P. Concept bottleneck models. International Conference on Machine Learning. Vienna: PMLR; 2020. pp. 5338–48.
Sabour S, Frosst N, Hinton GE. Dynamic routing between capsules. Adv Neural Inf Process Syst. 2017;30.
Shen S, Han SX, Aberle DR, Bui AA, Hsu W. An interpretable deep hierarchical semantic convolutional neural network for lung nodule malignancy classification. Expert Syst Appl. 2019;128:84–95.
Bass C, da Silva M, Sudre C, Tudosiu PD, Smith S, Robinson E. Icam: Interpretable classification via disentangled representations and feature attribution mapping. Adv Neural Inf Process Syst. 2020;33:7697–709.
Google Scholar
Kim E, Kim S, Seo M, Yoon S. XProtoNet: diagnosis in chest radiography with global and local explanations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2021. pp. 15719–28.
Li O, Liu H, Chen C, Rudin C. Deep learning for case-based reasoning through prototypes: A neural network that explains its predictions. In: Proceedings of the AAAI Conference on Artificial Intelligence. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2018. p. 1.
Baumgartner CF, Koch LM, Tezcan KC, Ang JX, Konukoglu E. Visual feature attribution using wasserstein gans. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2018. pp. 8309–19.
Cohen JP, Brooks R, En S, Zucker E, Pareek A, Lungren MP, et al. Gifsplanation via latent shift: a simple autoencoder approach to counterfactual generation for chest x-rays. In: Medical Imaging with Deep Learning. PMLR; 2021. pp. 74–104.
Lenis D, Major D, Wimmer M, Berg A, Sluiter G, Bühler K. Domain aware medical image classifier interpretation by counterfactual impact analysis. In: International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer; 2020. pp. 315–25.
Schutte K, Moindrot O, Hérent P, Schiratti JB, Jégou S. Using stylegan for visual interpretability of deep learning models on medical images. 2021. arXiv preprint arXiv:210107563.
Seah JC, Tang JS, Kitchen A, Gaillard F, Dixon AF. Chest radiographs in congestive heart failure: visualizing neural network learning. Radiology. 2019;290(2):514–22.
Selvaraju RR, Cogswell M, Das A, Vedantam R, Parikh D, Batra D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE international conference on computer vision. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017. pp. 618–26.
Simonyan K, Vedaldi A, Zisserman A. Deep inside convolutional networks: Visualising image classification models and saliency maps. 2013. arXiv preprint arXiv:13126034.
Singla S, Pollack B, Wallace S, Batmanghelich K. Explaining the black-box smoothly-a counterfactual approach. 2021. arXiv preprint arXiv:210104230.
Brima Y, Atemkeng M, Tankio Djiokap S, Ebiele J, Tchakounté F. Transfer learning for the detection and diagnosis of types of pneumonia including pneumonia induced by COVID-19 from chest X-ray images. Diagnostics. 2021;11(8):1480.
Article CAS PubMed PubMed Central Google Scholar
Bau D, Zhou B, Khosla A, Oliva A, Torralba A. Network dissection: Quantifying interpretability of deep visual representations. In: Proceedings of the IEEE conference on computer vision and pattern recognition. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017. pp. 6541–9.
Natekar P, Kori A, Krishnamurthi G. Demystifying brain tumor segmentation networks: interpretability and uncertainty analysis. Front Comput Neurosci. 2020;14:6.
Böhle M, Eitel F, Weygandt M, Ritter K. Layer-wise relevance propagation for explaining deep neural network decisions in MRI-based Alzheimer’s disease classification. Front Aging Neurosci. 2019;11:194.
Camalan S, Mahmood H, Binol H, Araújo ALD, Santos-Silva AR, Vargas PA, et al. Convolutional neural network-based clinical predictors of oral dysplasia: class activation map analysis of deep learning results. Cancers. 2021;13(6):1291.
Kermany DS, Goldbaum M, Cai W, Valentim CC, Liang H, Baxter SL, et al. Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell. 2018;172(5):1122–31.
Article CAS PubMed Google Scholar
Shi W, Tong L, Zhuang Y, Zhu Y, Wang MD. Exam: an explainable attention-based model for covid-19 automatic diagnosis. In: Proceedings of the 11th ACM international conference on bioinformatics, computational biology and health informatics. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2020. pp. 1–6.
Shi W, Tong L, Zhu Y, Wang MD. COVID-19 automatic diagnosis with radiographic imaging: Explainable attention transfer deep neural networks. IEEE J Biomed Health Inform. 2021;25(7):2376–87.
Nhlapho W, Atemkeng M, Brima Y, Ndogmo JC. Bridging the Gap: Exploring Interpretability in Deep Learning Models for Brain Tumor Detection and Diagnosis from MRI Images. Information. 2024;15(4):182.
Cheng J. Brain tumor dataset. figshare. 2017. https://doi.org/10.6084/m9.figshare.1512427.v5 .
Chowdhury MEH, Rahman T, Khandakar A, Mazhar R, Kadir MA, Mahbub ZB, et al. Can AI Help in Screening Viral and COVID-19 Pneumonia? IEEE Access. 2020;8:132665–76. https://doi.org/10.1109/ACCESS.2020.3010287 .
Brima Y, Atemkeng M, Tankio Djiokap S, Ebiele J, Tchakounté F. Transfer Learning for the Detection and Diagnosis of Types of Pneumonia including Pneumonia Induced by COVID-19 from Chest X-ray Images. Diagnostics. 2021;11(8). https://doi.org/10.3390/diagnostics11081480 .
Huang G, Liu Z, Van Der Maaten L, Weinberger KQ. Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2017. pp. 4700–8.
Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2015. pp. 1–9.
Tan M, Le Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In: International conference on machine learning. PMLR; 2019. pp. 6105–14.
Sundararajan M, Taly A, Yan Q. Axiomatic attribution for deep networks. In: International conference on machine learning. PMLR; 2017. pp. 3319–28.
Shrikumar A, Greenside P, Kundaje A. Learning important features through propagating activation differences. In: International conference on machine learning. PMLR; 2017. pp. 3145–53.
Smilkov D, Thorat N, Kim B, Viégas F, Wattenberg M. Smoothgrad: removing noise by adding noise. 2017. arXiv preprint arXiv:170603825.
Kapishnikov A, Venugopalan S, Avci B, Wedin B, Terry M, Bolukbasi T. Guided integrated gradients: An adaptive path method for removing noise. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2021. pp. 5050–8.
Kapishnikov A, Bolukbasi T, Viégas F, Terry M. Xrai: Better attributions through regions. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2019. pp. 4948–57.
Chattopadhay A, Sarkar A, Howlader P, Balasubramanian VN. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In: 2018 IEEE winter conference on applications of computer vision (WACV). IEEE; 2018. pp. 839–47.
Wang H, Wang Z, Du M, Yang F, Zhang Z, Ding S, et al. Score-CAM: Score-weighted visual explanations for convolutional neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. Honolulu: IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 2020. pp. 24–5.
Download references
Acknowledgements
We extend our gratitude to the reviewers for providing constructive feedback and valuable suggestions.
Open Access funding enabled and organized by Projekt DEAL. This research received no external funding.
Author information
Authors and affiliations.
Computer Vision, Institute of Cognitive Science, Osnabrück University, Osnabrueck, D-49090, Lower Saxony, Germany
Yusuf Brima
Department of Mathematics, Rhodes University, Grahamstown, 6140, Eastern Cape, South Africa
Marcellin Atemkeng
You can also search for this author in PubMed Google Scholar
Yusuf Birma: Conception and designed experiments, data preprocessing, Analysis, and Interpretation of results. Proofreaded and drafted the article. Marcellin Atemkeng: Mathematical modeling, statistical analysis and Interpretation of results, Data Analysis. Proofreaded and drafted the article.
Corresponding authors
Correspondence to Yusuf Brima or Marcellin Atemkeng .
Ethics declarations
Ethics approval and consent to participate.
Not applicable.
Consent for publication
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Models’ configuration
Table 2 shows the optimal hyperparameters for training the DL models discussed in this paper.
Exaplanability results
Visual explainability for top 2nd and 3rd models for each dataset.

Comparative assessment of saliency techniques applied to brain MRI data using the DenseNet121 model, the second-best performing model on this dataset. Among these, ScoreCAM and GradCAM++ appear to provide the more focused highlighting of the tumor regions across all types of tumors, suggesting that they are more effective in localizing and interpreting the model’s important feature areas for accurate prediction

The figure presents a comparison of various saliency techniques applied to brain MRI data using a ResNetV2 model. We noticed that Fast XRAI at 30% feature masking was able to highlight relevant tumor regions across the three disease classes. Other methods produced more coarse-grained saliency masks as depicted in the plot

This figure illustrates a comparative evaluation of various techniques applied to chest X-ray images using an InceptionResNetV2 model, which is identified as the second-best performing model on this chest X-ray dataset. Here, we noticed that most methods other than XRAI, Fast XRAI 30%, and GradCAM did not produce clinically meaningful saliency masks contrary to the models’ prediction performance. It is, however, hard to qualitatively evaluate these methods since the dataset does not have a ground-truth segmentation mask

Visualization of feature importance for different chest X-ray classifications using a VGG16 model. Rows correspond to different diagnostic categories: Lung Opacity, Normal, and COVID-19. Columns represent various explainability methods. We noticed that XRAI Full, Fast XRAI 30%, GradCAM++, and ScoreCAM highlighted more meaningful features compared to other methods. It is also noticed that Fast XRAI has consistent salient features across InceptionResNetV2 and VGG16 models
Computed saliency scores for top performing models for each image-based saliency method

Visualization of GIG SIC scores at varying blurring thresholds for the best-performing model, Inception-ResNetV2, on the Brain Tumor dataset. Each panel displays the GIG Blurred image for a specific threshold, with the corresponding score indicating the model’s confidence level. The thresholds range from 0 to 1.0, showcasing the progression of identified significant regions as the threshold increases. Higher thresholds emphasize more critical features, aligning with the model’s high-confidence predictions, thus offering insights into the explainability and robustness of the Inception-ResNetV2 model in detecting and analyzing brain tumor regions

Visualization of GradCAM SIC scores at varying thresholds for the same Inception-ResNetV2, on the Brain Tumor dataset. Unlike GIG, scores only converge at higher thresholds, row three of this plot

Visualization of GradCAM++ SIC scores at varying thresholds for the best-performing model, Inception-ResNetV2, on the Brain Tumor dataset. Like GradCAM, we noticed a similar trend in score convergence. However, the score converged at a threshold of 0.5 instead of 0.34 as in GradCAM

Visualization of XRAI SIC scores at varying thresholds for the best-performing model, Inception-ResNetV2, on the Brain Tumor dataset. This method also converges in the last three thresholds as depicted in the figure

Visualization of GIG Blurred SIC scores at varying thresholds for the best-performing model, Xception, on the Chest X-ray dataset. Unlike the Brain Tumor case, we noticed a different pattern here. The scores remain constant at the different thresholds which is unexpected and counter-intuitive

Visualization of GradCAM scores at varying thresholds for the best-performing model, Xception, on the Chest X-ray dataset. Like the previous result, we noticed a similar pattern here as the scores remain invariant across varied thresholds of blurring. This is the case for GradCAM++ and XRAI full
Buffer-size-based AICs and SICs evaluations

Aggregated AICs comparing the performance of various saliency methods on the Brain Tumor MRI image classification task. Vanilla IG achieves the highest AUC of 0.871, followed closely by SmoothGrad IG (0.866) and Guided IG (0.835), suggesting these methods are particularly effective in retaining relevant image regions. ScoreCAM shows a respectable AUC of 0.706, indicating good performance as well. GradCAM and GradCAM++ display moderate effectiveness with AUC values of 0.595 and 0.560, respectively. XRAI has an AUC of 0.511, and the Random saliency mask shows an AUC of 0.493, suggesting that some important regions might be retained by chance. This comparison highlights the variability of the entropy estimation to compute the saliency metric scores across datasets. This is primarily because the AUCs are not in agreement with the visual saliency results nor the Shannon entropy-based approach

Aggregated SICs comparing the performance of various saliency methods on the Brain Tumor MRI image classification task. Vanilla IG achieves the highest AUC of 0.893, closely followed by SmoothGrad IG (0.884) and Guided IG (0.865), suggesting these methods are particularly effective in highlighting regions that influence the model’s class probabilities. ScoreCAM also performs well with an AUC of 0.768. GradCAM++ and GradCAM show moderate performance with AUC values of 0.634 and 0.620, respectively. XRAI shows an AUC of 0.530, and the Random saliency mask exhibits an AUC of 0.573, indicating some critical regions might be retained by chance. This comparison highlights the variability in this evaluation metric irrespective of the underlying approach to estimating image entropy

Aggregated AICs evaluating the performance of various saliency attribution methods on the Chest X-ray image classification task. ScoreCAM demonstrates the highest AUC of 0.077, suggesting it retains the most relevant image regions effectively. This is followed by XRAI with an AUC of 0.071, Vanilla IG with an AUC of 0.053, and Guided IG with an AUC of 0.042. Methods like SmoothGrad IG, GradCAM, and GradCAM++ show minimal to zero AUC values, indicating limited effectiveness in this evaluation. The overall trend highlights that some methods, particularly ScoreCAM and XRAI, provide better retention of relevant regions compared to others. This result is in line with the Shannon entropy-based approach

Aggregated SICs comparing the performance of various saliency methods on the Chest X-ray images. The overall trend shows that Vanilla IG achieves the highest AUC of 0.972, closely followed by SmoothGrad IG (0.970) and Guided IG (0.961). Random saliency exhibits a high AUC of 0.828, suggesting that some important regions might be retained by chance. Other methods, including XRAI (0.731), GradCAM (0.694), ScoreCAM (0.692), and GradCAM++ (0.660), show moderate performance. This detailed comparison highlights a somewhat inverse relation with the visual explainability results
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Brima, Y., Atemkeng, M. Saliency-driven explainable deep learning in medical imaging: bridging visual explainability and statistical quantitative analysis. BioData Mining 17 , 18 (2024). https://doi.org/10.1186/s13040-024-00370-4
Download citation
Received : 07 August 2023
Accepted : 10 June 2024
Published : 22 June 2024
DOI : https://doi.org/10.1186/s13040-024-00370-4
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
BioData Mining
ISSN: 1756-0381
- General enquiries: [email protected]
A comprehensive strategy for quality evaluation of Changan powder by fingerprinting combined with rapid qualitative and quantitative multi‑ingredients profiling
- Wang, Zheyong
- Zhang, Yumeng
- Zhao, Chunjie
IntroductionChangan powder (CAP) is mainly used to treat various intestinal diseases. Few studies on CAP have been reported; therefore, it is necessary to clarify the material basis of CAP to lay the foundation for further elucidating its functional mechanism and support the rational use of drugs.ObjectivesIn the present study, we aimed to propose a methodology for the quality control of CAP based on qualitative and quantitative analysis of its components.MethodsAn ultra‑performance liquid chromatography coupled with Fourier transform ion cyclotron resonance mass spectrometry (UPLC‑FT‑ICR‑MS) method was developed to identify chemical components in CAP. In addition, fingerprints of 10 different batches of CAP were established, and quantitative analysis based on UPLC was performed to analyze the quality of CAP.ResultsA total of 58 compounds were preliminarily characterized. The similarity of 10 batches of CAP was greater than 0.995, and 23 common peaks were calibrated. Investigation of the quantitative analytical methodology showed that the four components had good linear relationships within their respective concentration ranges (r2 ≥ 0.9992), and the relative standard deviation (RSD) of precision and stability was less than 2%. The RSD of sample recovery ranged from 0.78% to 1.52%.ConclusionThe established method can quickly and effectively identify the chemical components of CAP and accurately quantify the known components in CAP. The established fingerprinting and content determination method is stable, reliable, and easy to operate and can be applied in quality control and in vivo research on CAP.Changan powder (CAP) consists of Viburnum betulifolium Batal. and Terminalia chebula Retz., mainly used to treat various intestinal diseases. In this study, a total of 58 components were identified in the CAP, and the contents of four index components were determined by UPLC. The established method can rapidly and effectively identify the chemical components of CAP, and the established fingerprint and content determination methods are stable, reliable, and easy to operate.
COMMENTS
INTRODUCTION. Scientific research is usually initiated by posing evidenced-based research questions which are then explicitly restated as hypotheses.1,2 The hypotheses provide directions to guide the study, solutions, explanations, and expected results.3,4 Both research questions and hypotheses are essentially formulated based on conventional theories and real-world processes, which allow the ...
When collecting and analyzing data, quantitative research deals with numbers and statistics, while qualitative research deals with words and meanings. Both are important for gaining different kinds of knowledge. Quantitative research. Quantitative research is expressed in numbers and graphs. It is used to test or confirm theories and assumptions.
Abstract. This paper aims to provide an overview of the use and assessment of qualitative research methods in the health sciences. Qualitative research can be defined as the study of the nature of phenomena and is especially appropriate for answering questions of why something is (not) observed, assessing complex multi-component interventions ...
Health researchers are increasingly using designs that combine qualitative and quantitative methods, and this is often called mixed methods research.1 Integration—the interaction or conversation between the qualitative and quantitative components of a study—is an important aspect of mixed methods research, and, indeed, is essential to some definitions.2 Recent empirical studies of mixed ...
About Research Methods. This guide provides an overview of research methods, how to choose and use them, and supports and resources at UC Berkeley. As Patten and Newhart note in the book Understanding Research Methods, "Research methods are the building blocks of the scientific enterprise. They are the "how" for building systematic knowledge.
This type of research can be used to establish generalisable facts about a topic. Common quantitative methods include experiments, observations recorded as numbers, and surveys with closed-ended questions. Qualitative research. Qualitative research is expressed in words. It is used to understand concepts, thoughts or experiences.
Qualitative research and quantitative research are two complementary approaches for understanding the world around us. Qualitative research collects non-numerical data, and the results are typically presented as written descriptions, photographs, videos, and/or sound recordings. The goal of qualitative research is often to learn about situations that aren't well understood by reading ...
Qualitative research focuses on word-based data, aiming to define and understand ideas. This study allows researchers to collect information in an open-ended way through interviews, ethnography, and observation. You'll study this information to determine patterns and the interplay of variables. On the other hand, quantitative research focuses ...
Qualitative research, in its broader sense, aims to describe, explore and understand phenomena through non-numerical based inquires and predominantly focuses on meanings, understandings and experiences. Qualitative research can be undertaken as a standalone study or when combined with quantitative research as a mixed methods study. Typically ...
1 Definition. Qualitative methods: Research that aims to gather an in-depth understanding of human behavior and the factors contributing to the behavior. Frequent methods of qualitative data collection include observation, in-depth interviews, and focus groups. Words, pictures, or objects comprise the resulting data. Observation:
The main difference between quantitative and qualitative research is the type of data they collect and analyze. Quantitative research collects numerical data and analyzes it using statistical methods. The aim is to produce objective, empirical data that can be measured and expressed in numerical terms.
For example, qualitative research usually relies on interviews, observations, and textual analysis to explore subjective experiences and diverse perspectives. While quantitative data collection methods include surveys, experiments, and statistical analysis to gather and analyze numerical data. The differences between the two research approaches ...
This is an important cornerstone of the scientific method. Quantitative research can be pretty fast. The method of data collection is faster on average: for instance, a quantitative survey is far quicker for the subject than a qualitative interview. The method of data analysis is also faster on average.
The quantitative techniques that we explored in this post do not completely replace a traditional approach to qualitative research with focus group data. Using a quantitative approach, however, can aid in exploratory analysis and refining questionnaire development without having to attend every group in person or read through hundreds of pages ...
Qualitative research focuses on thoughts, concepts, or experiences. The data collected often comes in narrative form and concentrates on unearthing insights that can lead to testable hypotheses. Educators use qualitative research in a study's exploratory stages to uncover patterns or new angles. Form Strong Conclusions with Quantitative Research
Discussion Questions. Why is the concept of control not a factor when conducting research with the qualitative method? How important is the concept of validity when discussing the qualitative method? Develop a hypothetical research scenario that would warrant the application of the case study. What type of approach within the qualitative method ...
Discussion on Qualitative Research Qualitative research is divided into different types, such as phenomenology, grounded theory, and ethnography. ... By using quantitative and qualitative research methods, it is possible to provide insights into research results and enhance data that would otherwise be impossible to collect (Bryman, 2007). ...
PLCY805 - Mod 01 DISCUSSION THREAD Researcher brings philosophical assumptions and theories that inform the conduct of the study. Three Major Components of a Research Approach (p06) The broad research approach is the plan or proposal to conduct research, involving the intersection of philosophy, research design, and specific methods. (Figure 1.1, p06).
Statement 2 Quantitative research methods are the best! "Researchers using this methodology seek objectivity through testable hypotheses and carefully designed studies." (Crawford, 2018, pg. 70) In quantitative research, specific behaviors that are quantified are examined to interpret data accurately. There are numerous advantages to quantitative research, including its ease of ...
When both quantitative and qualitative research methods are used in the same research, mixed-method research is applied.25 This combination provides a complete view of the research problem and achieves triangulation to corroborate findings, complementarity to clarify results, expansion to extend the study's breadth, and explanation to ...
Qualitative research methods refer to techniques of investigation that rely on nonstatistical and nonnumerical methods of data collection, analysis, and evidence production. ... Before carrying out a study which relies on quantitative techniques, qualitative research methods such as conversation analysis, interviews, surveys, or even focus ...
Discussion Thread: Qualitative and Quantitative Research Methods MANAGE DISCUSSION This is a graded discussion: 75 points possible due Mar 30 41 41 unread replies. 89 89 replies. Topic: Consider these statements: "Qualitative research methods are the best!" "Quantitative research methods are the best!" Thread Prompt: Present an argument in your thread that supports EACH of these 2 statements.
Document analysis. Desk research was performed for documents related to the TopCare program (Table 6 - details of document analysis in Appendix 1). Methodology Quantitative approach. The bibliometric analysis of the four domains in the two TopCare non-academic hospitals follows the same methodology as described in Abramo et al. [].We tested the assumption that joint publications are most ...
Mixed Methods Designs in Your Research (7a) In my research on workplace motivation, I would employ the sequential explanatory mixed methods design. It is a method where a qualitative phase follows after collecting the quantitative information through a simple procedure to probe in depth. In this research, I can begin the exploration by giving a survey to staff members, which helps to find out ...
Statement 1: "Qualitative research methods are the best!" "Qualitative research uses inductive logic in the various qualitative approaches, according to Crawford (2019). Researchers that use qualitative approaches seek understanding through the in-depth gathering of potentially subjective data, with the aim of hypotheses developing from the data (pp. 70)."
Deep learning shows great promise for medical image analysis but often lacks explainability, hindering its adoption in healthcare. Attribution techniques that explain model reasoning can potentially increase trust in deep learning among clinical stakeholders. In the literature, much of the research on attribution in medical imaging focuses on visual inspection rather than statistical ...
Topic: Consider these statements: "Qualitative research methods are the best!" "Quantitative research methods are the best!" Thread Prompt: Present an argument in your thread that supports EACH of these 2 statements. Separate your writings (do not mix these 2 statements as 1 statement), and label them as "Statement 1" and "Statement 2" in your thread.
IntroductionChangan powder (CAP) is mainly used to treat various intestinal diseases. Few studies on CAP have been reported; therefore, it is necessary to clarify the material basis of CAP to lay the foundation for further elucidating its functional mechanism and support the rational use of drugs.ObjectivesIn the present study, we aimed to propose a methodology for the quality control of CAP ...