
Published: 25 March 2024 Contributors: Jacob Murel Ph.D., Eda Kavlakoglu
In reinforcement learning, an agent learns to make decisions by interacting with an environment. It is used in robotics and other decision-making settings.
Reinforcement learning (RL) is a type of machine learning process that focuses on decision making by autonomous agents. An autonomous agent is any system that can make decisions and act in response to its environment independent of direct instruction by a human user. Robots and self-driving cars are examples of autonomous agents. In reinforcement learning, an autonomous agent learns to perform a task by trial and error in the absence of any guidance from a human user. 1 It particularly addresses sequential decision-making problems in uncertain environments, and shows promise in artificial intelligence development.
Literature often contrasts reinforcement learning with supervised and unsupervised learning. Supervised learning uses manually labeled data to produce predictions or classifications. Unsupervised learning aims to uncover and learn hidden patterns from unlabeled data. In contrast to supervised learning, reinforcement learning does not use labeled examples of correct or incorrect behavior. But reinforcement learning also differs from unsupervised learning in that reinforcement learning learns by trial-and-error and reward function rather than by extracting information of hidden patterns. 2
Supervised and unsupervised learning methods assume each record of input data is independent of other records in the dataset but that each record actualizes a common underlying data distribution model. These methods learn to predict with model performance measured according to prediction accuracy maximization.
By contrast, reinforcement learning learns to act. It assumes input data to be interdependent tuples—i.e. an ordered sequence of data—organized as state-action-reward. Many applications of reinforcement learning algorithms aim to mimic real-world biological learning methods through positive reinforcement.
Note that, although the two are not often compared in literature, reinforcement learning is distinct from self-supervised learning as well. The latter is a form of unsupervised learning that uses pseudo labels derived from unlabeled training data as a ground truth to measure model accuracy. Reinforcement learning, however, does not produce pseudo labels or measure against a ground truth—it is not a classification method but an action learner. The two have been combined however with promising results. 3
Explore IBM watsonx and learn how to create machine learning models using statistical datasets.
Subscribe to the IBM newsletter
Reinforcement learning essentially consists of the relationship between an agent, environment, and goal. Literature widely formulates this relationship in terms of the Markov decision process (MDP).
The reinforcement learning agent learns about a problem by interacting with its environment. The environment provides information on its current state. The agent then uses that information to determine which actions(s) to take. If that action obtains a reward signal from the surrounding environment, the agent is encouraged to take that action again when in a similar future state. This process repeats for every new state thereafter. Over time, the agent learns from rewards and punishments to take actions within the environment that meet a specified goal. 4
In Markov decision processes, state space refers to all of the information provided by an environment’s state. Action space denotes all possible actions the agent may take within a state. 5
Because an RL agent has no manually labeled input data guiding its behavior, it must explore its environment, attempting new actions to discover those that receive rewards. From these reward signals, the agent learns to prefer actions for which it was rewarded in order to maximize its gain. But the agent must continue exploring new states and actions as well. In doing so, it can then use that experience to improve its decision-making.
RL algorithms thus require an agent to both exploit knowledge of previously rewarded state-actions and explore other state-actions. The agent cannot exclusively pursue exploration or exploitation. It must continuously try new actions while also preferring single (or chains of) actions that produce the largest cumulative reward. 6
Beyond the agent-environment-goal triumvirate, four principal sub-elements characterize reinforcement learning problems.
- Policy. This defines the RL agent’s behavior by mapping perceived environmental states to specific actions the agent must take when in those states. It can take the form of a rudimentary function or more involved computational process. For instance, a policy guiding an autonomous vehicle may map pedestrian detection to a stop action.
- Reward signal. This designates the RL problem’s goal. Each of the RL agent’s actions either receives a reward from the environment or not. The agent’s only objective is to maximize its cumulative rewards from the environment. For self-driving vehicles, the reward signal can be reduced travel time, decreased collisions, remaining on the road and in the proper lane, avoiding extreme de- or accelerations, and so forth. This example shows RL may incorporate multiple reward signals to guide an agent.
- Value function. Reward signal differs from value function in that the former denotes immediate benefit while the latter specifies long-term benefit. Value refers to a state’s desirability per all of the states (with their incumbent rewards) that are likely to follow. An autonomous vehicle may be able to reduce travel time by exiting its lane, driving on the sidewalk, and accelerating quickly, but these latter three actions may reduce its overall value function. Thus, the vehicle as an RL agent may exchange marginally longer travel time to increase its reward in the latter three areas.
- Model. This is an optional sub-element of reinforcement learning systems. Models allow agents to predict environment behavior for possible actions. Agents then use model predictions to determine possible courses of action based on potential outcomes. This can be the model guiding the autonomous vehicle and that helps it predict best routes, what to expect from surrounding vehicles given their position and speed, and so forth. 7 Some model-based approaches use direct human feedback in initial learning and then shift to autonomous leanring.
There are two general methods by which an agent collects data for learning policies:
- Online. Here, an agent collects data directly from interacting with its surrounding environment. This data is processed and collected iteratively as the agent continues interacting with that environment.
- Offline. When an agent does not have direct access to an environment, it can learn through logged data of that environment. This is offline learning. A large subset of research has turned to offline learning given practical difficulties in training models through direct interaction with environments. 8
Reinforcement learning is a vibrant, ongoing area of research, and as such, developers have produced a myriad approaches to reinforcement learning. Nevertheless, three widely discussed and foundational reinforcement learning methods are dynamic programming, monte carlo, and temporal difference learning.
Dynamic programming breaks down larger tasks into smaller tasks. Thus, it models problems as workflows of sequential decision made at discrete time steps. Each decision is made in terms of the resulting possible next state. An agent’s reward ( r ) for a given action is defined as a function of that action ( a ), the current environmental state ( s ), and the potential next state ( s’ ):
This reward function can be used as (part of) the policy governing an agent’s actions. Determining the optimal policy for agent behavior is a chief component of dynamic programming methods for reinforcement learning. Enter the Bellman equation.
The Bellman equation is:
In short, this equation defines v t (s) as the total expected reward starting at time t until the end of a decision workflow. It assumes that the agent begins by occupying state s at time t . The equation ultimately divides the reward at time t into the immediate reward r t (s,a) (i.e. the reward formula) and the agent’s total expected reward. An agent thus maximizes its value function—being the total value of the Bellman equation—by consistently choosing that action which receives a reward signal in each state. 9
Dynamic programming is model-based, meaning it constructs a model of its environment to perceive rewards, identify patterns, and navigate the environment. Monte Carlo , however, assumes a black-box environment, making it model-free.
While dynamic programming predicts potential future states and reward signals in making decisions, Monte Carlo methods are exclusively experience-based, meaning they sample sequences of states, actions, and rewards solely through interaction with the environment. Monte Carlo methods thus learn through trial and error rather than probabilistic distributions.
Monte Carlo further differs from dynamic programming in value function determination. Dynamic programming seeks the largest cumulative reward by consistently selecting rewarded actions in successive states. Monte Carlo, by contrast, averages the returns for each state–action pair. This, in turn, means that the Monte Carlo method must wait until all actions in a given episode (or planning horizon) have been completed before calculating its value function, and then updating its policy. 10
Literature widely describes temporal difference (TD) learning as a combination of dynamic programming and Monte Carlo. As in the former, TD updates its policy, and so estimates for future states, after each step without waiting for a final value. As in Monte Carlo, however, TD learns through raw interaction with its environment rather than using a model thereof. 11
Per its name, the TD learning agent revises its policy according to the difference between predicted and actual received rewards in each state. That is, while dynamic programming and Monte Carlo only consider the reward received, TD further weighs the difference between its expectation and received reward. Using this difference, the agent updates its estimates for the next step without waiting until the event planning horizon, contra Monte Carlo. 12
TD has many variations. Two prominent variations are State–action–reward–state–action (SARSA) and Q-learning. SARSA is an on-policy TD method, meaning it evaluates and attempts to improve its decision-governing policy. Q-learning is off-policy. Off-policy methods are those that use two policies: one for exploitation (target policy) and one for exploration to generate behavior (behavior policy). 13
There is a myriad of additional reinforcement learning methods. Dynamic programming is a value-based method, meaning it selects actions based on their estimated values according to a policy that aims to maximize its value function. By contrast, policy gradient methods learn a parameterized policy that can select actions without consulting a value function. These are called policy-based and are considered more effective in high-dimensional environments. 14
Actor-critic methods use both value-based and policy-based. The so-called “actor” is a policy gradient determining which actions to take, while the “critic” is a value function to evaluate actions. Actor-critic methods are, essentially, a form of TD. More specifically, actor-critic evaluates a given action’s value based not only on its own reward but the possible value of the following state, which it adds to the action’s reward. Actor-critic’s advantage is that, due to its implementation of a value function and policy in decision-making, it effectively requires less environment interaction. 15
Given reinforcement learning is centrally concerned with decision-making in unpredictable environments, it has been a core area of interest in robotics. For accomplishing simple and repetitive tasks , decision-making may be straightforward. But more complicated tasks, such as attempts to simulate human behavior or automate driving, involve interaction with high-variable and mutable real-world environments. Research shows deep reinforcement learning with deep neural networks aids such tasks, especially with respect to generalization and mapping high-dimensionally sensory input to controlled systems outputs. 16 Studies suggest that deep reinforcement learning with robots relies heavily on collected datasets, and so recent work explores avenues for collecting real-world data 17 and repurposing prior data 18 to improve reinforcement learning systems.
Recent research suggests leveraging natural language processing techniques and tools—e.g. large language models (LLMs)—may improve generalization in reinforcement learning systems through textual representation of real-world environments. 19 Many studies show how interactive textual environments provide cost-effective alternatives to three-dimensional environments when instructing learning agents in successive decision-making tasks. 20 Deep reinforcement learning also undergirds textual decision-making in chatbots . In fact, reinforcement learning outperforms other methods for improving chatbot dialogue response. 21
Reimagine how you work with AI: our diverse, global team of more than 20,000 AI experts can help you quickly and confidently design and scale AI and automation across your business, working across our own IBM watsonx technology and an open ecosystem of partners to deliver any AI model, on any cloud, guided by ethics and trust.
Operationalize AI across your business to deliver benefits quickly and ethically. Our rich portfolio of business-grade AI products and analytics solutions are designed to reduce the hurdles of AI adoption and establish the right data foundation while optimizing for outcomes and responsible use.
Multiply the power of AI with our next-generation AI and data platform. IBM watsonx is a portfolio of business-ready tools, applications and solutions, designed to reduce the costs and hurdles of AI adoption while optimizing outcomes and responsible use of AI.
Use reinforcement learning to identify actions for states within an environment and train an agent to behave rationally.
Learn about reinforcement learning as compared to other types of machine learning.
IBM researchers propose a choice mechanism in RL to address agent impact on the environment.
Build an AI strategy for your business on one collaborative AI and data platform—IBM watsonx. Train, validate, tune and deploy AI models to help you scale and accelerate the impact of AI with trusted data across your business.
1 Ian Goodfellow, Yoshua Bengio, and Aaron Courville, Deep Learning, MIT Press, 2016.
2 Peter Stone, “Reinforcement Learning,” Encyclopedia of Machine Learning and Data Mining , Springer, 2017.
3 Xiang Li, Jinghuan Shang, Srijan Das, Michael Ryoo, "Does Self-supervised Learning Really Improve Reinforcement Learning from Pixels?" Advances in Neural Information Processing Systems, Vol. 35, 2022, pp. 30865-30881, https://proceedings.neurips.cc/paper_files/paper/2022/hash/c75abb33341363ee874a71f81dc45a3a-Abstract-Conference.html (link resides outside ibm.com).
4 Richard Sutton and Andrew Barto, Introduction to Reinforcement Learning , 2 nd edition, MIT Press, 2018. Michael Hu, The Art of Reinforcement Learning: Fundamentals, Mathematics, and Implementations with Python , Apress, 2023.
5 Brandon Brown and Alexander Zai, Deep Reinforcement Learning in Action , Manning Publications, 2020.
6 Richard Sutton and Andrew Barto, Introduction to Reinforcement Learning , 2 nd edition, MIT Press, 2018. Brandon Brown and Alexander Zai, Deep Reinforcement Learning in Action , Manning Publications, 2020.
7 Richard Sutton and Andrew Barto, Introduction to Reinforcement Learning , 2 nd edition, MIT Press, 2018. B Ravi Kiran, Ibrahim Sobh, Victor Talpaert, Patrick Mannion, Ahmad A. Al Sallab, Senthil Yogamani, and Patrick Pérez, "Deep Reinforcement Learning for Autonomous Driving: A Survey," IEEE Transactions on Intelligent Transportation Systems , Vol. 23, No. 6, 2022, pp. 4909-4926, https://ieeexplore.ieee.org/document/9351818 (link resides outside ibm.com).
8 Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu, "Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems," 2020, https://arxiv.org/abs/2005.01643 (link resides outside ibm.com). Julian Schrittwieser, Thomas Hubert, Amol Mandhane, Mohammadamin Barekatain, Ioannis Antonoglou, and David Silver, "Online and Offline Reinforcement Learning by Planning with a Learned Model," Advances in Neural Information Processing Systems , Vol. 34, 2021, pp. 27580-27591, https://proceedings.neurips.cc/paper_files/paper/2021/hash/e8258e5140317ff36c7f8225a3bf9590-Abstract.html (link resides outside ibm.com).
9 Martin Puterman and Jonathan Patrick, “Dynamic Programming,” Encyclopedia of Machine Learning and Data Mining , Springer, 2017.
10 Richard Sutton and Andrew Barto, Introduction to Reinforcement Learning , 2 nd edition, MIT Press, 2018. Phil Winder, Reinforcement Learning: Industrial Applications of Intelligent Agents , O’Reilly, 2020.
11 Richard Sutton and Andrew Barto, Introduction to Reinforcement Learning , 2 nd edition, MIT Press, 2018.
12 Michael Hu, The Art of Reinforcement Learning: Fundamentals, Mathematics, and Implementations with Python , Apress, 2023.
13 Richard Sutton and Andrew Barto, Introduction to Reinforcement Learning , 2 nd edition, MIT Press, 2018.
14 Richard Sutton and Andrew Barto, Introduction to Reinforcement Learning , 2 nd edition, MIT Press, 2018. Michael Hu, The Art of Reinforcement Learning: Fundamentals, Mathematics, and Implementations with Python , Apress, 2023.
15 Richard Sutton and Andrew Barto, Introduction to Reinforcement Learning , 2 nd edition, MIT Press, 2018.
16 Julian Ibarz, Jie Tan, Chelsea Finn, Mrinal Kalakrishnan, Peter Pastor, and Sergey Levine, "How to train your robot with deep reinforcement learning: lessons we have learned," The International Journal of Robotics Research, Vol. 40, 2021, pp. 969-721, https://journals.sagepub.com/doi/full/10.1177/0278364920987859 (link resides outside ibm.com).
17 Saminda Wishwajith Abeyruwan, Laura Graesser, David B D’Ambrosio, Avi Singh, Anish Shankar, Alex Bewley, Deepali Jain, Krzysztof Marcin Choromanski, and Pannag R Sanketi, "i-Sim2Real: Reinforcement Learning of Robotic Policies in Tight Human-Robot Interaction Loops," Proceedings of The 6th Conference on Robot Learning, PMLR, No. 205, 2023, pp. 212-224, https://proceedings.mlr.press/v205/abeyruwan23a.html (link resides outside ibm.com).
18 Homer Rich Walke, Jonathan Heewon Yang, Albert Yu, Aviral Kumar, Jędrzej Orbik, Avi Singh, and Sergey Levine, "Don’t Start From Scratch: Leveraging Prior Data to Automate Robotic Reinforcement Learning," Proceedings of The 6th Conference on Robot Learning, PMLR, No. 205, 2023, 1652-1662, https://proceedings.mlr.press/v205/walke23a.html (link resides outside ibm.com).
19 Nikolaj Goodger, Peter Vamplew, Cameron Foale, and Richard Dazeley, "Language Representations for Generalization in Reinforcement Learning," Proceedings of The 13th Asian Conference on Machine Learning, PMLR, No. 157, 2021, pp. 390-405, https://proceedings.mlr.press/v157/goodger21a.html (link resides outside ibm.com). Yuqing Du, Olivia Watkins, Zihan Wang, Cédric Colas, Trevor Darrell, Pieter Abbeel, Abhishek Gupta, and Jacob Andreas, "Guiding Pretraining in Reinforcement Learning with Large Language Models," Proceedings of the 40th International Conference on Machine Learning, PMLR, No. 202, 2023, pp. 8657-8677, https://proceedings.mlr.press/v202/du23f.html (link resides outside ibm.com). Kolby Nottingham, Prithviraj Ammanabrolu, Alane Suhr, Yejin Choi, Hannaneh Hajishirzi, Sameer Singh, and Roy Fox, "Do Embodied Agents Dream of Pixelated Sheep: Embodied Decision Making using Language Guided World Modelling," Proceedings of the 40th International Conference on Machine Learning, PMLR , 202, 2023, pp. 26311-26325, https://proceedings.mlr.press/v202/nottingham23a.html (link resides outside ibm.com).
20 Ruoyao Wang and Peter Jansen and Marc-Alexandre Côté and Prithviraj Ammanabrolu, "ScienceWorld: Is your Agent Smarter than a 5th Grader?" Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022, pp. 11279-11298, https://aclanthology.org/2022.emnlp-main.775/ (link resides outside ibm.com). Peter Jansen, "A Systematic Survey of Text Worlds as Embodied Natural Language Environments," Proceedings of the 3rd Wordplay: When Language Meets Games Workshop , 2022, pp. 1-15, https://aclanthology.org/2022.wordplay-1.1 (link resides outside ibm.com).
21 Paloma Sodhi, Felix Wu, Ethan R. Elenberg, Kilian Q Weinberger, and Ryan Mcdonald, "On the Effectiveness of Offline RL for Dialogue Response Generation," Proceedings of the 40th International Conference on Machine Learning, PMLR, No. 202, 2023, pp. 32088-32104, https://proceedings.mlr.press/v202/sodhi23a.html (link resides outside ibm.com). Siddharth Verma, Justin Fu, Sherry Yang, and Sergey Levine, "CHAI: A CHatbot AI for Task-Oriented Dialogue with Offline Reinforcement Learning," Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, 2022, pp. 4471-4491, https://aclanthology.org/2022.naacl-main.332/ (link resides outside ibm.com).

Evolving Reinforcement Learning Algorithms
April 22, 2021
Posted by John D. Co-Reyes, Research Intern and Yingjie Miao, Senior Software Engineer, Google Research
A long-term, overarching goal of research into reinforcement learning (RL) is to design a single general purpose learning algorithm that can solve a wide array of problems. However, because the RL algorithm taxonomy is quite large, and designing new RL algorithms requires extensive tuning and validation, this goal is a daunting one. A possible solution would be to devise a meta-learning method that could design new RL algorithms that generalize to a wide variety of tasks automatically.
In recent years, AutoML has shown great success in automating the design of machine learning components, such as neural networks architectures and model update rules. One example is Neural Architecture Search (NAS), which has been used to develop better neural network architectures for image classification and efficient architectures for running on phones and hardware accelerators . In addition to NAS, AutoML-Zero shows that it’s even possible to learn the entire algorithm from scratch using basic mathematical operations. One common theme in these approaches is that the neural network architecture or the entire algorithm is represented by a graph, and a separate algorithm is used to optimize the graph for certain objectives.
These earlier approaches were designed for supervised learning , in which the overall algorithm is more straightforward. But in RL, there are more components of the algorithm that could be potential targets for design automation (e.g., neural network architectures for agent networks , strategies for sampling from the replay buffer, overall formulation of the loss function ), and it is not always clear what the best model update procedure would be to integrate these components. Prior efforts for the automation RL algorithm discovery have focused primarily on model update rules. These approaches learn the optimizer or RL update procedure itself and commonly represent the update rule with a neural network such as an RNN or CNN , which can be efficiently optimized with gradient-based methods. However, these learned rules are not interpretable or generalizable, because the learned weights are opaque and domain specific.
In our paper “ Evolving Reinforcement Learning Algorithms ”, accepted at ICLR 2021 , we show that it’s possible to learn new, analytically interpretable and generalizable RL algorithms by using a graph representation and applying optimization techniques from the AutoML community. In particular, we represent the loss function, which is used to optimize an agent’s parameters over its experience, as a computational graph , and use Regularized Evolution to evolve a population of the computational graphs over a set of simple training environments. This results in increasingly better RL algorithms, and the discovered algorithms generalize to more complex environments, even those with visual observations like Atari games.
RL Algorithm as a Computational Graph
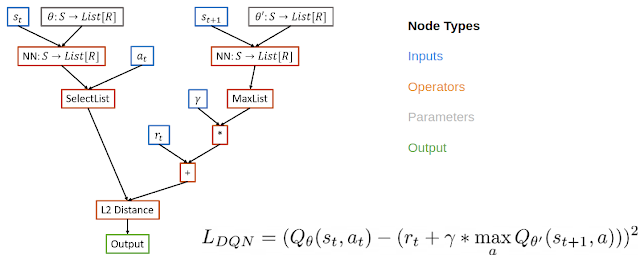
Inspired by ideas from NAS, which searches over the space of graphs representing neural network architectures, we meta-learn RL algorithms by representing the loss function of an RL algorithm as a computational graph. In this case, we use a directed acyclic graph for the loss function, with nodes representing inputs, operators, parameters and outputs. For example, in the computational graph for DQN , input nodes include data from the replay buffer, operator nodes include neural network operators and basic math operators, and the output node represents the loss, which will be minimized with gradient descent.
There are a few benefits of such a representation. This representation is expressive enough to define existing algorithms but also new, undiscovered algorithms. It is also interpretable. This graph representation can be analyzed in the same way as human designed RL algorithms, making it more interpretable than approaches that use black box function approximators for the entire RL update procedure. If researchers can understand why a learned algorithm is better, then they can both modify the internal components of the algorithm to improve it and transfer the beneficial components to other problems. Finally, the representation supports general algorithms that can solve a wide variety of problems.
We implemented this representation using the PyGlove library, which conveniently turns the graph into a search space that can be optimized with regularized evolution.
Evolving RL Algorithms
We use an evolutionary based approach to optimize the RL algorithms of interest. First, we initialize a population of training agents with randomized graphs. This population of agents is trained in parallel over a set of training environments. The agents first train on a hurdle environment — an easy environment, such as CartPole , intended to quickly weed out poorly performing programs.
If an agent cannot solve the hurdle environment, the training is stopped early with a score of zero. Otherwise the training proceeds to more difficult environments (e.g., Lunar Lander , simple MiniGrid environments, etc.). The algorithm performance is evaluated and used to update the population, where more promising algorithms are further mutated. To reduce the search space, we use a functional equivalence checker which will skip over newly proposed algorithms if they are functionally the same as previously examined algorithms. This loop continues as new mutated candidate algorithms are trained and evaluated. At the end of training, we select the best algorithm and evaluate its performance over a set of unseen test environments.
The population size in the experiments was around 300 agents, and we observed the evolution of good candidate loss functions after 20-50 thousand mutations, requiring about three days of training. We were able to train on CPUs because the training environments were simple, controlling for the computational and energy cost of training. To further control the cost of training, we seeded the initial population with human-designed RL algorithms such as DQN.
Learned Algorithms
We highlight two discovered algorithms that exhibit good generalization performance. The first is DQNReg , which builds on DQN by adding a weighted penalty on the Q-values to the normal squared Bellman error. The second learned loss function, DQNClipped , is more complex, although its dominating term has a simple form — the max of the Q-value and the squared Bellman error (modulo a constant). Both algorithms can be viewed as a way to regularize the Q-values. While DQNReg adds a soft constraint, DQNClipped can be interpreted as a kind of constrained optimization that will minimize the Q-values if they become too large. We show that this learned constraint kicks in during the early stage of training when overestimating the Q-values is a potential issue. Once this constraint is satisfied, the loss will instead minimize the original squared Bellman error.
A closer analysis shows that while baselines like DQN commonly overestimate Q-values, our learned algorithms address this issue in different ways. DQNReg underestimates the Q-values, while DQNClipped has similar behavior to double dqn in that it slowly approaches the ground truth without overestimating it.
It’s worth pointing out that these two algorithms consistently emerge when the evolution is seeded with DQN. Learning from scratch, the method rediscovers the TD algorithm . For completeness, we release a dataset of top 1000 performing algorithms discovered during evolution. Curious readers could further investigate the properties of these learned loss functions.
Learned Algorithms Generalization Performance
Normally in RL, generalization refers to a trained policy generalizing across tasks. However, in this work we’re interested in algorithmic generalization performance, which means how well an algorithm works over a set of environments. On a set of classical control environments , the learned algorithms can match baselines on the dense reward tasks (CartPole, Acrobot , LunarLander) and outperform DQN on the sparser reward task, MountainCar .
On a set of sparse reward MiniGrid environments, which test a variety of different tasks, we see that DQNReg greatly outperforms baselines on both the training and test environments, in terms of sample efficiency and final performance. In fact, the effect is even more pronounced on the test environments, which vary in size, configuration, and existence of new obstacles, such as lava.
We visualize the performance of normal DDQN vs. the learned algorithm DQNReg on a few MiniGrid environments. The starting location, wall configuration, and object configuration of these environments are randomized at each reset, which requires the agent to generalize instead of simply memorizing the environment. While DDQN often struggles to learn any meaningful behavior, DQNReg can learn the optimal behavior efficiently.
Even on image-based Atari environments we observe improved performance, even though training was on non-image-based environments. This suggests that meta-training on a set of cheap but diverse training environments with a generalizable algorithm representation could enable radical algorithmic generalization.
In this post, we’ve discussed learning new interpretable RL algorithms by representing their loss functions as computational graphs and evolving a population of agents over this representation. The computational graph formulation allows researchers to both build upon human-designed algorithms and study the learned algorithms using the same mathematical toolset as the existing algorithms. We analyzed a few of the learned algorithms and can interpret them as a form of entropy regularization to prevent value overestimation. These learned algorithms can outperform baselines and generalize to unseen environments. The top performing algorithms are available for further analytical study.
We hope that future work will extend to more varied RL settings such as actor critic algorithms or offline RL. Furthermore we hope that this work can lead to machine assisted algorithm development where computational meta-learning can help researchers find new directions to pursue and incorporate learned algorithms into their own work.
Acknowledgements
We thank our co-authors Daiyi Peng, Esteban Real, Sergey Levine, Quoc V. Le, Honglak Lee, and Aleksandra Faust. We also thank Luke Metz for helpful early discussions and feedback on the paper, Hanjun Dai for early discussions on related research ideas, Xingyou Song, Krzysztof Choromanski, and Kevin Wu for helping with infrastructure, and Jongwook Choi for helping with environment selection. Finally we thank Tom Small for designing animations for this post.
- Algorithms & Theory
- Conferences & Events
Other posts of interest
May 16, 2024
- Conferences & Events ·
- Generative AI ·
- Health & Bioscience ·
- Machine Intelligence ·
- Product ·
- Quantum ·
- Responsible AI

May 1, 2024
- Algorithms & Theory ·
- Machine Intelligence

April 19, 2024
- Distributed Systems & Parallel Computing ·
- Security, Privacy and Abuse Prevention

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- HHS Author Manuscripts
What do Reinforcement Learning Models Measure? Interpreting Model Parameters in Cognition and Neuroscience
Maria k. eckstein.
c Department of Psychology, UC Berkeley, 2121 Berkeley Way West, Berkeley, 94720, CA, USA
Linda Wilbrecht
d Helen Wills Neuroscience Institute, UC Berkeley, 175 Li Ka Shing Center, Berkeley, 94720, CA, USA
Anne G.E. Collins
Reinforcement learning (RL) is a concept that has been invaluable to fields including machine learning, neuroscience, and cognitive science. However, what RL entails differs between fields, leading to difficulties when interpreting and translating findings. After laying out these differences, this paper focuses on cognitive (neuro)science to discuss how we as a field might over-interpret RL modeling results. We too often assume—implicitly—that modeling results generalize between tasks, models, and participant populations, despite negative empirical evidence for this assumption. We also often assume that parameters measure specific, unique (neuro)cognitive processes, a concept we call interpretability , when evidence suggests that they capture different functions across studies and tasks. We conclude that future computational research needs to pay increased attention to implicit assumptions when using RL models, and suggest that a more systematic understanding of contextual factors will help address issues and improve the ability of RL to explain brain and behavior.
1. Introduction
Reinforcement learning (RL) is an exploding field. In the domain of machine learning, it has led to tremendous progress in the last decade, ranging from the creation of artificial agents that can beat humans at complex games, such as Go [ 1 ] and StarCraft [ 2 ], to successful deployment in industrial settings, such as the autonomous navigation of internet balloons in the stratosphere [ 3 ]. In cognitive neuroscience, RL models have been used successfully to capture a broad range of latent learning-related phenomena, at the level of both behavior [ 4 , 5 ] and neural signals [ 6 ]. However, the impression that RL can help us identify reasonable and predictive latent variables hides heterogeneity in what RL variables reflect, even within cognitive neuroscience. The success of RL has fed a notion of omniscience that RL can peer into the brain and behavior and surgically isolate and measure essential functions. As this notion grows with the popular uptake of RL methods, it sometimes leads to overgeneralization and overinterpretation of findings.
Here, we argue that a more nuanced view is better supported empirically and theoretically. We first discuss how RL is used in distinct subfields, highlighting shared and distinct components. Then, we examine where cognitive neuroscience may be overstepping in its interpretation, and conclude that, when properly contexualized, RL models retain great value for the field.
2. RL in Machine Learning, Psychology, and Neuroscience
In machine learning, RL is defined as a class of learning problems and a family of algorithms that solve these problems. An RL agent can be in any of a set of states, take actions to change states, and receive rewards/punishments ( Fig. 1 , top-right). RL agents are designed to optimize a specific objective: the expected sum of discounted future rewards. A wide family of RL algorithms offers solutions that achieve this objective [ 10 ], for example model-free RL, which estimates the values of actions based on reward prediction errors ( Fig. 2A , top).

The meaning of "RL" differs between neuroscience, machine learning, and psychology, reflecting a specific brain network, a family of problems and algorithms, and a type of learning, respectively. The concepts are related: RL models successfully capture aspects of RL behavior and brain signals, and some RL behaviors rely on the RL brain network. The dopamine reward prediction error hypothesis combines ideas from all three fields. However, there are also significant discrepancies in what RL means across fields, such that activity in the brain's RL network might not relate to RL behavior and might not be captured by RL models (e.g., dopamine ramping in neuroscience). Importantly, RL behavior may rely on non-RL brain systems and may or may not be captured by RL algorithms. Recent trends have aimed to increase communication between fields and emphasize areas of mutual benefits [ 7 , 8 ]. RL in neuroscience inset shows the neurosynth automated meta-analysis for "reinforcement learning" (x=10, y=4, z=-8), highlighting striatal function [ 9 ]. RL in cognition inset shows that participants become more likely to select a rewarded choice the more previous rewards they have experienced (data replotted from [ 5 ]). RL in machine learning shows the agent-environment loop at the basis of RL theory [ 10 ].

Fitting standard RL models can lead to the wrong impression that cognitive processing is purely based on RL. (A) Update equations for the RL-WM model. Q ( a | s ) indicates the RL state-action value of action a in state s , which is updated based on the reward prediction error RPE . W ( a | s ) is the working-memory weight of a in s , and ϕ is a forgetting parameter, β is the decision noise, and η the mixing parameter combining RL and working memory processes. For model details, see [ 5 , 29 ]. (B) When separate standard RL models are fit to different contexts within the same task (here, the number of stimuli [ 6 ]), they provide different answers as to how age affects RL model parameters (decision noise β , top; learning rate α , bottom). Contexts with fewer stimuli ("Set size 3", left) suggest that age does not affect learning rates, whereas contexts with more stimuli ("Set size 5", right) suggest that learning rates increase with age. Inset statistics show non-parametric Spearman correlation coefficients ρ and p-values (N=187, * p < 0:05, ** p < 0:01, *** p < 0:001). (C)-(E) When using a model that fits all contexts jointly by combining RL processes with working memory ("RL-WM" model), these discrepancies are resolved [ 5 ]. (C) The RL-WM model reveals that the relative contributions of RL compared to working memory differ between contexts. A standard RL model would falsely attribute working-memory processes in contexts with small sizes to the RL system, in this example suggesting that learning rates do not change with age (A, set size 3). (D) Working memory capacity in the RL-WM model was not related to participants' ages, explaining why learning rates did not increase with age in (A, set size 3), in which working memory contributed most to learning. (E) RL learning rates in the RL-WM model increased with age. Since RL contributed more to learning in set size 5 (C), this was detected in the standard RL model of only set size 5 (B). Data reanalyzed from [ 5 ].
In psychology, RL defines a psychological process and a method for its study. RL occurs when an organism learns to make choices (or predict outcomes) directly based on experienced rewards/punishments (rather than indirectly through instructions, for example). This includes simple situations, such as those historically studied by behaviorists (classical [ 6 , 11 ] and instrumental conditioning [ 12 ]), as well as more complex ones, such as learning over longer time horizons [ 13 , 14 ], meta-learning [ 15 ], and learning across multiple contexts [ 16 , 17 ].
Neuroscientists investigating RL usually focus on a well-defined network of regions that implements value learning. These include cortico-basal-ganglia loops, and in particular the striatum ( Fig. 1A ), thought to encode RL values, and dopamine neurons, thought to signal temporal-difference reward-prediction errors (RPEs ; Fig. 2A ) [ 6 , 9 , 18 , 19 , 20 , 21 ].
The meaning of "RL" overlaps in these three communities ( Fig. 1 ), and RL algorithms from AI have been successful at capturing biological RL behavior and neural function. However, there are also important discrepancies. For example, many functions of the brain's RL network do not relate to RL behavior, such as dopamine's role in motor control [ 22 ] or cognitive effort [ 23 ]. On the other hand, some RL brain functions that do relate to RL behavior are poorly explained by classic RL models, such as dopamine's role in value-independent learning [ 11 ]. Furthermore, many aspects of learning from reward do not depend on the brain's RL network, whether they are captured by RL algorithms or not. For example, hippocampal episodic memory [ 24 , 25 ] and prefrontal working memory [ 26 , 27 , 28 ] contribute to RL behavior, but are often not explicitly modeled in RL, obscuring the contribution of non-RL neural processes to learning.
Because of these differences in meaning, the term "RL" can cause ambiguity and lead to misinterpretations. Fig. 2 provides an example in which an RL model leads to conflicting conclusions as to how RL parameters change with age when applied to two slight variants of the same task. This conflict is reconciled, however, by recognizing that working memory contributes most learning in one variant, whereas RL does in the other [ 5 ].
Because RĽs meaning is ambiguous, it is often unclear how RL model variables (e.g., parameters such as learning rates or decision noise; reward prediction errors; RL values) should be interpreted in models of human and animal learning. In the following, we show that the field often optimistically assumes that model variables are readily interpretable and naturally generalize between studies. We then show that these beliefs are oftentimes not well supported, and offer an alternative interpretation.
3. Interpretability and Generalizability of RL Model Variables
3.1. what do "cognitive" models measure.
RL models attempt to approximate behavior by fitting free parameters [ 30 , 31 , 32 , 33 ], and are used by most researchers to elucidate cognitive and/or neural function ( Box 1 ): RL “has emerged as a key framework for modeling and understanding decision-making ” 1 [ 34 ]. The reason why models of behavior are used as “cognitive models” is that they implement hypotheses about cognition. Therefore, the good fit of a model to behavior implies that participants could have employed the modeled algorithm cognitively. Nevertheless, stronger conclusions are often drawn: For example, the good fit of inference algorithms to human behavior and brain function has been taken as evidence that human brains implement inference [ 17 ]. However, there always is an infinite number of alternative algorithms that would fit behavior equally well, such that inferring participants' cognitive algorithms through model fitting is impossible [ 33 , 35 , 36 ].
Representative statements from the literature that imply interpretability and generalizability. a
•. interpretability:.
Computational models have been described as “illuminating [...] cognitive processes or neural representations that are otherwise difficult to tease apart” [ 37 ]; clarifying “the neural processes underlying decision-making ” [ 18 ]; and revealing “what computations are performed in neuronal populations that support a particular cognitive process ” b [ 38 ]. This highlights the common assumption that computational models can reveal cognitive and neural processes and identify specific, “theoretically meaningful” [ 39 ] elements of (neuro)cognitive function.
Models are thereby often expected to provide the “linking propositions” [ 40 ] between cognition and neural function, “ mapping latent decision-making processes onto dissociable neural substrates” [ 41 ] and “ link[ing] cognitive mechanisms to [clinical] symptoms” [ 38 ].
These links are often assumed to be specific one-to-one mappings: “Dopamine neurons code an error in the prediction of reward” [ 20 ]; “corticostriatal loops enable state-dependent value-based choice” [ 27 ]; “striatal areas [...] support reinforcement learning, and frontoparietal attention areas [...] support executive control processes” [ 42 ]; “individual differences in DA clearance and frontostriatal coordination may serve as markers for RL” [ 43 ]; and “BOLD activity in the VS, dACC, and vmPFC is correlated with learning rate, expected value, and prediction error, respectively” [ 44 ]. This shows that computational variables are often interpreted as specific (neuro)cognitive functions, revealing an assumption of interpretability .
•. Generalizability:
Empirical parameter distributions obtained in one task were described as “fairly transferable ” [ 45 ] and used as priors when fitting parameters to a new task [ 46 ], revealing the belief that model parameters generalize between studies, tasks, and models.
Developmental research has aimed to illuminate “the tuning of the learning rate parameter across development” and the “developmental change in the inverse temperature parameter” [ 37 ], suggesting that parameters are person-specific but task-independent.
Many have aimed to find regularities in parameter findings between studies: “[D]fferential learning rates tend to be biased in the direction of learning from positive RPEs” [ 47 ]; “this finding [supports] previous results on decreased involvement of the reinforcement learning system when cortical resources [...] support task execution” [ 42 ]; from our own work: “there was [...] a bias towards learning from positive feedback, which is consistent with other work ” [ 5 ].
a We acknowledge that these statements may not represent the full complexity of researchers' knowledge, as many are aware of modeling limitations.
b All emphases added.
3.2. Interpretability and Generalizability
This notion that computational models—astonishingly—isolate and measure intrinsic (neuro)cognitive processes from observable behavior has contributed to their attractiveness as a research method. However, we believe we need to temper our optimism in two areas: interpretability and generalizability ( Fig. 3 ).

What model variables (e.g., parameters) measure in psychology and neuroscience. (A) View based on interpretability and generalizability. In this view—implicitly taken by much current research—models are fitted in order to reveal individuals' intrinsic characteristics, whereby model parameters reflect clearly delineated, separable, and unique (neuro)cognitive processes. This concept of interpretability is shown in the figure in that every model parameter captures one specific cognitive process (bidirectional arrows between parameter and process), and that cognitive processes are separable from each other (no connections between processes). Specific task characteristics are neglected as irrelevant, a concept we call generalizability , which is evident in that parameters of “any learning task” (within reason) are expected to capture the same cognitive processes. (B) In our empirical study [ 76 ], participants worked on three learning tasks with similar structure (left), but slight differences (middle), reflecting the literature. We created three RL models that captured the behavior in each task [ 4 , 5 , 69 ]. Compared between tasks but within participants, learning rate parameters showed poor interpretability and generalizability [ 76 ]: Both absolute values and age trajectories (right, bottom) differed vastly, and individual differences in one task could not be predicted by those in other tasks, as would be expected if they were interpretable as the same (neuro)cognitive substrate. Other parameters, most notably decision noise (right, top), were more generalizable and interpretable, in accordance with emerging patterns in the literature [ 37 ], even though they also lacked a shared core of variance across tasks (more for more dissimilar tasks). In contrast, the mappings between parameters and behavioral features were consistent across tasks, suggesting that parameters generalized in terms of behavioral processes, but not cognitive ones. (C) Updated view that acknowledges the role of context in computational modeling (e.g., task characteristics, model parameterization, participant characteristics). Which cognitive processes are captured by each model parameter is influenced by the task (green, orange, blue), as shown by distinct connections between parameters and cognitive processes. Different parameters within the same task can capture overlapping cognitive processes (not interpretable), and the same parameters can capture different processes depending on the task (not generalizable). However, parameters likely capture consistent behavioral patterns across tasks (thick vertical arrows).
Interpretability means that model variables (e.g., parameters, reward prediction errors) isolate specific, fundamental, and invariant elements of (neuro)cognitive processing: Decomposing behavior into model variables is seen as a way of carving cognition at its joints, producing model variables that are of essential nature. Generalizability means that model variables capture inherent individual characteristics (e.g., a person with a high learning rate), such that we can robustly infer the same parameter for the same person across different contexts, tasks, and model variants.
Though rarely stated explicitly, assumptions about interpretability and generalizability lie at the heart of much current computational cognitive research (including our own), as we show in the literature survey below ( Box 1 ), and play a consequential role in interpreting and guiding future research. However, we also show that empirical support for interpretability and generalizability is ambivalent at best, and often negative. We highlight a recent multi-task within-participants study from our group that explores precisely when model parameters do and do not generalize between tasks, and how dissimilar the cognitive processes are they capture (interpretability).
3.2.1. Interpretability
Many research practices are deeply invested in the interpretability of RL ( Box 1 ). The computational neurosciences, for example, aim to link computational variables to specific neural functions, searching for one-to-one mappings that would allow the inference of one from the other [ 6 , 12 , 43 , 48 ]. Prominent examples of interpretable mappings are the links between the midbrain-dopamine system and RL reward prediction errors [ 20 , 49 , 50 ], and between striatal function and value learning [ 19 , 51 , 52 , 53 ]. Computational psychiatry aims to map model variables onto psychiatric diagnoses or symptoms, in an effort to obtain diagnostic tools and causal explanations of aberrant processing [ 38 , 39 , 41 , 54 ]. Developmental research aims to map age-related changes in model variables onto developing neural function and real-world behavior [ 37 , 55 , 56 ]. In sum, the conviction in model interpretability is evident in the practice of interpreting model variables as specific cognitive processes, unique neural substrates, and well-delineated psychiatric symptoms.
3.2.2. Generalizability
Assumptions about parameter generalizability are also widespread. In computational neuroscience, model variables are routinely expected to measure the same latent neural substrates, even when the underlying task, model, or participant samples differ [ 18 , 19 , 20 , 57 , 58 , 59 , 60 ]. For example, fields studying individual differences, such as clinical [ 38 , 39 ] and developmental psychology [ 37 , 55 , 56 ], aim to identify how model variables covary with other variables of interest (e.g., age, traits, symptoms) in a systematic way across studies, and review articles and discussion sections confidently compare modeling variables between studies.
3.3. Evidence Against Interpretability and Generalizability
However, meta-reviews suggest that interpretability and generalizability might be overassumptions, common in classic psychological research [ 61 ] and RL modeling [ 41 ]. RL appears interpretable because multiple studies have replicated mappings between RL variables and specific neural function. However, these mappings are not as consistent as expected: The famous mapping between dopamine / striatal activity and reward prediction errors, for example, supported by classic and recent research [ 6 , 20 ], varies considerably between studies based on details of the experimental protocol, as shown in several recent meta-analyses [ 57 , 59 , 62 ].
Discrepancies are also evident in the mapping between RL variables and cognitive function. For example, learning rates are often interpreted as incremental updating (dopamine-driven neural plasticity) in classical conditioning [ 20 ], but also as reward sensitivity [ 63 ], sampling from (hippocampal) episodic memory [ 25 ], the ability to optimally weigh decision outcomes [ 64 ], or approximate inference [ 4 ], in other tasks. There is substantial variance between studies in terms of which neural and which cognitive processes underlie the same RL variables, contradicting the notion of interpretability.
Evidence for generalizability is also weak: Similar adult samples have differed strikingly in terms of their average estimated RL learning rates (0.05–0.7) [ 44 , 63 , 65 , 66 ] and "positivity bias" [ 47 , 67 , 68 ], depending on the underlying task and model parameterization. In developmental samples, the trajectories of RL learning rates have shown increases [ 5 , 63 , 69 ], decreases [ 70 ], U-shaped trajectories [ 4 ], or no change [ 71 ] in the same age range. Similar discrepancies have also arisen in the computational psychiatry literature [ 38 , 39 , 72 , 73 ]. These inconsistencies would not be expected if model variables were an inherent property of participants that could be assessed independently of study specifics, i.e., if models were generalizable.
Many in our community have noticed such discrepancies and invoked methodological differences between studies to explain them [ 12 , 37 , 44 , 62 , 74 , 75 ]. However, this insight has rarely been put into practice, and model variables keep being compared between studies ( Box 1 ). To remedy this, we assessed interpretability and generalizability empirically, comparing RL parameters from three tasks performed by the same subjects in a developmental sample (291 subjects aged 8–30; Fig. 3B ) [ 4 , 5 , 69 , 76 ]. We found generalizability but poor interpretability for decision noise, and a fundamental lack of both interpretability and generalizability for learning rates ( Fig. 3C ).
A likely reason why generalizability and interpretability are lacking in many cases is that computational models are fundamentally models of behavior, and not cognition. Because participants—reasonably—behave differently in different tasks (e.g., repeating non-rewarded actions in stochastic, but not deterministic tasks [ 76 ]), estimated parameters (e.g., learning rates) differ as well. Such differences do not necessarily reflect a failure of computational models to measure intrinsic processes, but likely the fact that the same parameters capture different behaviors and different cognitive processes when applied to different tasks ( Fig. 3B , ,3C) 3C ) [ 76 ].
Another reason for lacking generalizability and interpretability is that the design of computational models, a researcher degree of freedom [ 35 , 36 ], can impact parameters severely, as recent research has highlighted [ 47 , 67 , 68 ]. Because the same models can be parameterized differently [ 77 ], and models with different equations can approximate similar processes [ 4 ], model differences are a ubiquitous feature of computational modeling.
To explain parameter discrepancies, others have argued that participants adapt their parameter values to tasks based on optimality [ 37 ], or that task characteristics (e.g., uncertainty) influence neural processing (e.g., dopamine function), which is reflected in differences in model variables (e.g., reward prediction errors) [ 78 , 79 ]. Whether choices are aligned with participants' goals also fundamentally impacts neural RL processes [ 80 ], and so do other common task characteristics [ 59 ]. This shows that small task differences impact behavior, neural processing, and computational variables. Even though RL models might successfully capture behavior in each task, parameters likely capture different aspects each time, leading to a lack of interpretability and generalizability.
4. Conclusion and Outlook
A tremendous literature has shown RĽs potential and successes—this opinion piece emphasizes some caveats, showing that RL is not a single concept and that RL models are a broad family that reflects a range of cognitive and neural processes.
A lack of interpretability and generalizability has major implications for the comparison of model variables between tasks, a practice that forms the basis for many review articles, meta-analyses, introduction and discussion sections of empirical papers, and for directing future research. Evidence suggests that in many cases, parameters cannot directly be compared between studies, and capture different (neuro)cognitive processes depending on task characteristics. Future research needs to determine which model variables do and do not generalize, over which domain, and what the determining factors are. In the meantime, researchers should be more nuanced when comparing results between studies, and acknowledge contextual factors that might limit generalizability. Lastly, what model variables measure might differ for each task, and researchers should provide additional validation on a task-by-task basis, relating variables to behavioral measures or individuals' traits, and using simulations to determine the role of model variables in specific tasks.
Another solution is to explicitly model variability between features that should be generalized over, including task characteristics ( Fig. 2 ), models, participants, and potentially even neural processes [ 61 ]. Several studies have made strides in this direction, incorporating features that are intrinsic to participants (working memory [ 5 , 29 ], attention [ 28 ], development [ 37 , 81 , 56 ]), or extrinsic (task time horizon [ 13 , 14 ], context changes [ 16 ]), thus broadening the domain over which models generalize. However, infinitely many features likely affect RL processes, rendering entirely general models infeasible. Researchers therefore need to select a domain of interest for each model, and acknowledge this choice. As authors, reviewers, and editors, we should balance our excitement about general statements with our knowledge about the inherent limitations of all models, including RL. Future research needs to determine whether similar issues arise for other model families, such as sequential sampling [ 82 , 83 ], Bayesian inference [ 4 , 28 , 84 ], and others.
We hope that this explicit discussion of assumptions and overassumptions will help our field solve the mysteries of the brain as modeling—with its limitations—is embraced by a growing audience.
- "Reinforcement Learning" (RL) refers to different concepts in machine learning, psychology, and neuroscience.
- In psychology and neuroscience, RL models have provided successful methods for describing and predicting complex behavioral processes and brain activity.
- However, RL variables often do not generalize from one task to another and need to be interpreted in context.
- RL computations also do not always reflect the same underlying cognitive and neural processes.
- A more nuanced understanding of RL and its variables (e.g., reward prediction errors, parameters) is necessary to move the field forward.
5. Acknowledgements
This work was in part supported by National Science Foundation grant 1640885 SL-CN: Science of Learning in Adolescence to AGEC and LW, NIH grant 1U19NS113201 to LW, and NIMH RO1MH119383 to AGEC.
1 emphasis added
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Published: 25 February 2015
Human-level control through deep reinforcement learning
- Volodymyr Mnih 1 na1 ,
- Koray Kavukcuoglu 1 na1 ,
- David Silver 1 na1 ,
- Andrei A. Rusu 1 ,
- Joel Veness 1 ,
- Marc G. Bellemare 1 ,
- Alex Graves 1 ,
- Martin Riedmiller 1 ,
- Andreas K. Fidjeland 1 ,
- Georg Ostrovski 1 ,
- Stig Petersen 1 ,
- Charles Beattie 1 ,
- Amir Sadik 1 ,
- Ioannis Antonoglou 1 ,
- Helen King 1 ,
- Dharshan Kumaran 1 ,
- Daan Wierstra 1 ,
- Shane Legg 1 &
- Demis Hassabis 1
Nature volume 518 , pages 529–533 ( 2015 ) Cite this article
514k Accesses
12k Citations
1544 Altmetric
Metrics details
- Computer science
The theory of reinforcement learning provides a normative account 1 , deeply rooted in psychological 2 and neuroscientific 3 perspectives on animal behaviour, of how agents may optimize their control of an environment. To use reinforcement learning successfully in situations approaching real-world complexity, however, agents are confronted with a difficult task: they must derive efficient representations of the environment from high-dimensional sensory inputs, and use these to generalize past experience to new situations. Remarkably, humans and other animals seem to solve this problem through a harmonious combination of reinforcement learning and hierarchical sensory processing systems 4 , 5 , the former evidenced by a wealth of neural data revealing notable parallels between the phasic signals emitted by dopaminergic neurons and temporal difference reinforcement learning algorithms 3 . While reinforcement learning agents have achieved some successes in a variety of domains 6 , 7 , 8 , their applicability has previously been limited to domains in which useful features can be handcrafted, or to domains with fully observed, low-dimensional state spaces. Here we use recent advances in training deep neural networks 9 , 10 , 11 to develop a novel artificial agent, termed a deep Q-network, that can learn successful policies directly from high-dimensional sensory inputs using end-to-end reinforcement learning. We tested this agent on the challenging domain of classic Atari 2600 games 12 . We demonstrate that the deep Q-network agent, receiving only the pixels and the game score as inputs, was able to surpass the performance of all previous algorithms and achieve a level comparable to that of a professional human games tester across a set of 49 games, using the same algorithm, network architecture and hyperparameters. This work bridges the divide between high-dimensional sensory inputs and actions, resulting in the first artificial agent that is capable of learning to excel at a diverse array of challenging tasks.
This is a preview of subscription content, access via your institution
Access options
Subscribe to this journal
Receive 51 print issues and online access
185,98 € per year
only 3,65 € per issue
Buy this article
- Purchase on Springer Link
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout
Similar content being viewed by others

Using deep neural networks as a guide for modeling human planning

Grandmaster level in StarCraft II using multi-agent reinforcement learning

Mastering Atari, Go, chess and shogi by planning with a learned model
Sutton, R. & Barto, A. Reinforcement Learning: An Introduction (MIT Press, 1998)
MATH Google Scholar
Thorndike, E. L. Animal Intelligence: Experimental studies (Macmillan, 1911)
Book Google Scholar
Schultz, W., Dayan, P. & Montague, P. R. A neural substrate of prediction and reward. Science 275 , 1593–1599 (1997)
Article CAS Google Scholar
Serre, T., Wolf, L. & Poggio, T. Object recognition with features inspired by visual cortex. Proc. IEEE. Comput. Soc. Conf. Comput. Vis. Pattern. Recognit. 994–1000 (2005)
Google Scholar
Fukushima, K. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biol. Cybern. 36 , 193–202 (1980)
Tesauro, G. Temporal difference learning and TD-Gammon. Commun. ACM 38 , 58–68 (1995)
Article Google Scholar
Riedmiller, M., Gabel, T., Hafner, R. & Lange, S. Reinforcement learning for robot soccer. Auton. Robots 27 , 55–73 (2009)
Diuk, C., Cohen, A. & Littman, M. L. An object-oriented representation for efficient reinforcement learning. Proc. Int. Conf. Mach. Learn. 240–247 (2008)
Bengio, Y. Learning deep architectures for AI. Foundations and Trends in Machine Learning 2 , 1–127 (2009)
Krizhevsky, A., Sutskever, I. & Hinton, G. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 25 , 1106–1114 (2012)
Hinton, G. E. & Salakhutdinov, R. R. Reducing the dimensionality of data with neural networks. Science 313 , 504–507 (2006)
Article ADS MathSciNet CAS Google Scholar
Bellemare, M. G., Naddaf, Y., Veness, J. & Bowling, M. The arcade learning environment: An evaluation platform for general agents. J. Artif. Intell. Res. 47 , 253–279 (2013)
Legg, S. & Hutter, M. Universal Intelligence: a definition of machine intelligence. Minds Mach. 17 , 391–444 (2007)
Genesereth, M., Love, N. & Pell, B. General game playing: overview of the AAAI competition. AI Mag. 26 , 62–72 (2005)
Bellemare, M. G., Veness, J. & Bowling, M. Investigating contingency awareness using Atari 2600 games. Proc. Conf. AAAI. Artif. Intell. 864–871 (2012)
McClelland, J. L., Rumelhart, D. E. & Group, T. P. R. Parallel Distributed Processing: Explorations in the Microstructure of Cognition (MIT Press, 1986)
LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 86 , 2278–2324 (1998)
Hubel, D. H. & Wiesel, T. N. Shape and arrangement of columns in cat’s striate cortex. J. Physiol. 165 , 559–568 (1963)
Watkins, C. J. & Dayan, P. Q-learning. Mach. Learn. 8 , 279–292 (1992)
Tsitsiklis, J. & Roy, B. V. An analysis of temporal-difference learning with function approximation. IEEE Trans. Automat. Contr. 42 , 674–690 (1997)
Article MathSciNet Google Scholar
McClelland, J. L., McNaughton, B. L. & O’Reilly, R. C. Why there are complementary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory. Psychol. Rev. 102 , 419–457 (1995)
O’Neill, J., Pleydell-Bouverie, B., Dupret, D. & Csicsvari, J. Play it again: reactivation of waking experience and memory. Trends Neurosci. 33 , 220–229 (2010)
Lin, L.-J. Reinforcement learning for robots using neural networks. Technical Report, DTIC Document. (1993)
Riedmiller, M. Neural fitted Q iteration - first experiences with a data efficient neural reinforcement learning method. Mach. Learn.: ECML 3720 , 317–328 (Springer, 2005)
Van der Maaten, L. J. P. & Hinton, G. E. Visualizing high-dimensional data using t-SNE. J. Mach. Learn. Res. 9 , 2579–2605 (2008)
Lange, S. & Riedmiller, M. Deep auto-encoder neural networks in reinforcement learning. Proc. Int. Jt. Conf. Neural. Netw. 1–8 (2010)
Law, C.-T. & Gold, J. I. Reinforcement learning can account for associative and perceptual learning on a visual decision task. Nature Neurosci. 12 , 655 (2009)
Sigala, N. & Logothetis, N. K. Visual categorization shapes feature selectivity in the primate temporal cortex. Nature 415 , 318–320 (2002)
Article ADS CAS Google Scholar
Bendor, D. & Wilson, M. A. Biasing the content of hippocampal replay during sleep. Nature Neurosci. 15 , 1439–1444 (2012)
Moore, A. & Atkeson, C. Prioritized sweeping: reinforcement learning with less data and less real time. Mach. Learn. 13 , 103–130 (1993)
Jarrett, K., Kavukcuoglu, K., Ranzato, M. A. & LeCun, Y. What is the best multi-stage architecture for object recognition? Proc. IEEE. Int. Conf. Comput. Vis. 2146–2153 (2009)
Nair, V. & Hinton, G. E. Rectified linear units improve restricted Boltzmann machines. Proc. Int. Conf. Mach. Learn. 807–814 (2010)
Kaelbling, L. P., Littman, M. L. & Cassandra, A. R. Planning and acting in partially observable stochastic domains. Artificial Intelligence 101 , 99–134 (1994)
Download references
Acknowledgements
We thank G. Hinton, P. Dayan and M. Bowling for discussions, A. Cain and J. Keene for work on the visuals, K. Keller and P. Rogers for help with the visuals, G. Wayne for comments on an earlier version of the manuscript, and the rest of the DeepMind team for their support, ideas and encouragement.
Author information
Volodymyr Mnih, Koray Kavukcuoglu and David Silver: These authors contributed equally to this work.
Authors and Affiliations
Google DeepMind, 5 New Street Square, London EC4A 3TW, UK,
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A. Rusu, Joel Veness, Marc G. Bellemare, Alex Graves, Martin Riedmiller, Andreas K. Fidjeland, Georg Ostrovski, Stig Petersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg & Demis Hassabis
You can also search for this author in PubMed Google Scholar
Contributions
V.M., K.K., D.S., J.V., M.G.B., M.R., A.G., D.W., S.L. and D.H. conceptualized the problem and the technical framework. V.M., K.K., A.A.R. and D.S. developed and tested the algorithms. J.V., S.P., C.B., A.A.R., M.G.B., I.A., A.K.F., G.O. and A.S. created the testing platform. K.K., H.K., S.L. and D.H. managed the project. K.K., D.K., D.H., V.M., D.S., A.G., A.A.R., J.V. and M.G.B. wrote the paper.
Corresponding authors
Correspondence to Koray Kavukcuoglu or Demis Hassabis .
Ethics declarations
Competing interests.
The authors declare no competing financial interests.
Extended data figures and tables
Extended data figure 1 two-dimensional t-sne embedding of the representations in the last hidden layer assigned by dqn to game states experienced during a combination of human and agent play in space invaders..
The plot was generated by running the t-SNE algorithm 25 on the last hidden layer representation assigned by DQN to game states experienced during a combination of human (30 min) and agent (2 h) play. The fact that there is similar structure in the two-dimensional embeddings corresponding to the DQN representation of states experienced during human play (orange points) and DQN play (blue points) suggests that the representations learned by DQN do indeed generalize to data generated from policies other than its own. The presence in the t-SNE embedding of overlapping clusters of points corresponding to the network representation of states experienced during human and agent play shows that the DQN agent also follows sequences of states similar to those found in human play. Screenshots corresponding to selected states are shown (human: orange border; DQN: blue border).
Extended Data Figure 2 Visualization of learned value functions on two games, Breakout and Pong.
a , A visualization of the learned value function on the game Breakout. At time points 1 and 2, the state value is predicted to be ∼ 17 and the agent is clearing the bricks at the lowest level. Each of the peaks in the value function curve corresponds to a reward obtained by clearing a brick. At time point 3, the agent is about to break through to the top level of bricks and the value increases to ∼ 21 in anticipation of breaking out and clearing a large set of bricks. At point 4, the value is above 23 and the agent has broken through. After this point, the ball will bounce at the upper part of the bricks clearing many of them by itself. b , A visualization of the learned action-value function on the game Pong. At time point 1, the ball is moving towards the paddle controlled by the agent on the right side of the screen and the values of all actions are around 0.7, reflecting the expected value of this state based on previous experience. At time point 2, the agent starts moving the paddle towards the ball and the value of the ‘up’ action stays high while the value of the ‘down’ action falls to −0.9. This reflects the fact that pressing ‘down’ would lead to the agent losing the ball and incurring a reward of −1. At time point 3, the agent hits the ball by pressing ‘up’ and the expected reward keeps increasing until time point 4, when the ball reaches the left edge of the screen and the value of all actions reflects that the agent is about to receive a reward of 1. Note, the dashed line shows the past trajectory of the ball purely for illustrative purposes (that is, not shown during the game). With permission from Atari Interactive, Inc.
Supplementary information
Supplementary information.
This file contains a Supplementary Discussion. (PDF 110 kb)
Performance of DQN in the Game Space Invaders
This video shows the performance of the DQN agent while playing the game of Space Invaders. The DQN agent successfully clears the enemy ships on the screen while the enemy ships move down and sideways with gradually increasing speed. (MOV 5106 kb)
Demonstration of Learning Progress in the Game Breakout
This video shows the improvement in the performance of DQN over training (i.e. after 100, 200, 400 and 600 episodes). After 600 episodes DQN finds and exploits the optimal strategy in this game, which is to make a tunnel around the side, and then allow the ball to hit blocks by bouncing behind the wall. Note: the score is displayed at the top left of the screen (maximum for clearing one screen is 448 points), number of lives remaining is shown in the middle (starting with 5 lives), and the “1” on the top right indicates this is a 1-player game. (MOV 1500 kb)
PowerPoint slides
Powerpoint slide for fig. 1, powerpoint slide for fig. 2, powerpoint slide for fig. 3, powerpoint slide for fig. 4, rights and permissions.
Reprints and permissions
About this article
Cite this article.
Mnih, V., Kavukcuoglu, K., Silver, D. et al. Human-level control through deep reinforcement learning. Nature 518 , 529–533 (2015). https://doi.org/10.1038/nature14236
Download citation
Received : 10 July 2014
Accepted : 16 January 2015
Published : 25 February 2015
Issue Date : 26 February 2015
DOI : https://doi.org/10.1038/nature14236
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
This article is cited by
Reinforcement learning-based energy management for hybrid power systems: state-of-the-art survey, review, and perspectives.
- Xiaolin Tang
- Jiaxin Chen
Chinese Journal of Mechanical Engineering (2024)
Deep learning models to predict the editing efficiencies and outcomes of diverse base editors
- Sungchul Choi
- Hyongbum Henry Kim
Nature Biotechnology (2024)
Optimizing warfarin dosing for patients with atrial fibrillation using machine learning
- Jeremy Petch
- Walter Nelson
- Stuart J. Connolly
Scientific Reports (2024)
Spectrum-efficient user grouping and resource allocation based on deep reinforcement learning for mmWave massive MIMO-NOMA systems
- Minghao Wang
Assuring Efficient Path Selection in an Intent-Based Networking System: A Graph Neural Networks and Deep Reinforcement Learning Approach
- Javier Jose Diaz Rivera
- Wang-Cheol Song
Journal of Network and Systems Management (2024)
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: AI and Robotics newsletter — what matters in AI and robotics research, free to your inbox weekly.

The Advance of Reinforcement Learning and Deep Reinforcement Learning
Ieee account.
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
Enhancing cut selection through reinforcement learning
- AI Methods for Optimization Problems
- Published: 15 May 2024
Cite this article

- Shengchao Wang 1 ,
- Liang Chen 1 ,
- Lingfeng Niu 2 &
- Yu-Hong Dai 1
Explore all metrics
With the rapid development of artificial intelligence in recent years, applying various learning techniques to solve mixed-integer linear programming (MILP) problems has emerged as a burgeoning research domain. Apart from constructing end-to-end models directly, integrating learning approaches with some modules in the traditional methods for solving MILPs is also a promising direction. The cutting plane method is one of the fundamental algorithms used in modern MILP solvers, and the selection of appropriate cuts from the candidate cuts subset is crucial for enhancing efficiency. Due to the reliance on expert knowledge and problem-specific heuristics, classical cut selection methods are not always transferable and often limit the scalability and generalizability of the cutting plane method. To provide a more efficient and generalizable strategy, we propose a reinforcement learning (RL) framework to enhance cut selection in the solving process of MILPs. Firstly, we design feature vectors to incorporate the inherent properties of MILP and computational information from the solver and represent MILP instances as bipartite graphs. Secondly, we choose the weighted metrics to approximate the proximity of feasible solutions to the convex hull and utilize the learning method to determine the weights assigned to each metric. Thirdly, a graph convolutional neural network is adopted with a self-attention mechanism to predict the value of weighting factors. Finally, we transform the cut selection process into a Markov decision process and utilize RL method to train the model. Extensive experiments are conducted based on a leading open-source MILP solver SCIP. Results on both general and specific datasets validate the effectiveness and efficiency of our proposed approach.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Achterberg T. Constraint integer programming. PhD Thesis. Berlin: Technische Universität Berlin, 2007
Google Scholar
Achterberg T, Wunderling R. Mixed integer programming: Analyzing 12 years of progress. In: Jünger M, Reinelt G, eds. Facets of Combinatorial Optimization: Festschrift for Martin Grötschel. Berlin-Heidelberg: Springer, 2013, 449–481
Chapter Google Scholar
Alvarez A M, Louveaux Q, Wehenkel L. A machine learning-based approximation of strong branching. INFORMS J Comput, 2017, 29: 185–195
Article MathSciNet Google Scholar
Anderson L, Turner M, Koch T. Generative deep learning for decision making in gas networks. Math Methods Oper Res, 2022, 95: 503–532
Andreello G, Caprara A, Fischetti M. Embedding {0, 1/2}-cuts in a branch-and-cut framework: A computational study. INFORMS J Comput, 2007, 19: 229–238
Balcan M F, Dick T, Sandholm T, et al. Learning to branch. In: Proceedings of International Conference on Machine Learning. Ann Arbor: PMLR, 2018, 344–353
Balcan M F, Prasad S, Sandholm T, et al. Sample complexity of tree search configuration: Cutting planes and beyond. In: Proceedings of the 35th International Conference on Neural Information Processing Systems. San Francisco: Curran Associates, 2021, 4015–4027
Baltean-Lugojan R, Bonami P, Misener R, et al. Scoring positive semidefinite cutting planes for quadratic optimization via trained neural networks. https://optimization-online.org/2018/11/6943/ , 2019
Berthold T, Francobaldi M, Hendel G. Learning to use local cuts. arXiv:2206.11618, 2022
Bestuzheva K, Besançon M, Chen W K, et al. The SCIP Optimization Suite 8.0. Berlin: Zuse Institute Berlin, 2021, 21–41
Blieklú C, Bonami P, Lodi A. Solving mixed-integer quadratic programming problems with IBM-CPLEX: A progress report. In: Proceedings of the twenty-sixth RAMP Symposium. Montreal: ACM Press, 2014, 16–17
Bonami P, Cornuéjols G, Dash S, et al. Projected Chvatal-Gomory cuts for mixed integer linear programs. Math Program, 2008, 113: 241–257
Chen W K, Chen L, Dai Y H. Lifting for the integer knapsack cover polyhedron. J Global Optim, 2022: 1–45
Chvátal V. Edmonds polytopes and a hierarchy of combinatorial problems. Discrete Math, 1973, 4: 305–337
Dey S S, Molinaro M. Theoretical challenges towards cutting-plane selection. Math Program, 2018, 170: 237–266
Ding J Y, Zhang C, Shen L, et al. Accelerating primal solution findings for mixed integer programs based on solution prediction. AAAI J, 2020, 34: 1452–1459
Article Google Scholar
Gasse M, Chételat D, Ferroni N, et al. Exact combinatorial optimization with graph convolutional neural networks. In: Proceedings of the 32nd International Conference on Neural Information Processing Systems. San Francisco: Curran Associates, 2019, 15580–15592
Ge D, Huangfu Q, Wang Z, et al. Cardinal Optimizer (COPT) User Guide. arXiv:2208.14314, 2022
Gleixner A, Hendel G, Gamrath G, et al. MIPLIB 2017: Data-driven compilation of the 6th mixed-integer programming library. Math Program Comput, 2021, 13: 443–490
Gomory R. An algorithm for the mixed integer problem. RAND CORP SANTA MONICA CA, 1960
Gupta P, Gasse M, Khalil E, et al. Hybrid models for learning to branch. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. San Francisco: Curran Associates, 2020, 18087–18097
Gurobi Optimization L. Gurobi Optimizer Reference Manual. https://www.gurobi.com , 2023
Huang Z, Wang K, Liu F, et al. Learning to select cuts for efficient mixed-integer programming. Pattern Recogn, 2022, 123: 108353
Jia H, Shen S. Benders cut classification via support vector machines for solving two-stage stochastic programs. INFORMS J Optim, 2021, 3: 278–297
Kallrath J. Modeling Languages in Mathematical Optimization. New York: Springer, 2004
Book Google Scholar
Khalil E, Dilkina B, Nemhauser GL, et al. Learning to run heuristics in tree search. In: Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence. IJCAI, 2017, 659–666
Khalil E, Le Bodic P, Song L, et al. Learning to branch in mixed integer programming. AAAI J, 2016, 30: 724–731
Kingma DP, Ba J. Adam: A method for stochastic optimization. arXiv:1412.6980, 2014
Kool W, van Hoof H, Welling M. Attention, learn to solve routing problems! In: Proceedings of the International Conference on Learning Representations. ICLR, 2019, 3: 5057–5069
Land AH, Doig AG. An automatic method of solving discrete programming problems. Econometrica, 1960, 28: 497–520
Lodi A, Tramontani A. Performance variability in mixed-integer programming. In: Theory Driven by Influential Applications. Annapolis: INFORMS, 2013, 1–12
Marchand H, Martin A, Weismantel R, et al. Cutting planes in integer and mixed integer programming. Discrete Appl Math, 2002, 123: 397–446
Nair V, Bartunov S, Gimeno F, et al. Solving mixed integer programs using neural networks. arXiv:2012.13349, 2020
Nazari M, Oroojlooy A, Snyder L, et al. Reinforcement learning for solving the vehicle routing problem. In: Proceedings of the International Conference on Neural Information Processing Systems. San Francisco: Curran Associates, 2018, 94–99
Nickel S, Steinhardt C, Schlenker H, et al. IBM ILOG CPLEX Optimization Studio: Modellierung von Planungs-und Entscheidungsproblemen des Operations Research mit OPL, 2021, 9–23
Paszke A, Gross S, Massa F, et al. Pytorch: An imperative style, high-performance deep learning library. In: Proceedings of the 33rd International Conference on Neural Information Processing Systems. San Francisco: Curran Associates, 2019, 8026–8037
Paulus MB, Zarpellon G, Krause A, et al. Learning to cut by looking ahead: Cutting plane selection via imitation learning. In: Proceedings of International Conference on Machine Learning. Ann Arbor: PMLR, 2022, 17584–17600
Shen Y, Sun Y, Eberhard A, et al. Learning primal heuristics for mixed integer programs. In: Proceedings of the International Joint Conference on Neural Networks. San Francisco: IEEE, 2021, 1–8
Sutton R S, McAllester D, Singh S, et al. Policy gradient methods for reinforcement learning with function approximation. Adv Neural Inform Process Syst, 2000, 12: 1057–1063
Tang Y, Agrawal S, Faenza Y. Reinforcement learning for integer programming: Learning to cut. In: Proceedings of International Conference on Machine Learning. Ann Arbor: PMLR, 2020, 9367–9376
Turner M, Koch T, Serrano F, et al. Adaptive cut selection in mixed-integer linear programming. arXiv:2202.10962, 2022
Vasilyev I, Boccia M, Hanafi S. An implementation of exact knapsack separation. J Global Optim, 2016, 66: 127–150
Vinyals O, Fortunato M, Jaitly N. Pointer networks. In: Proceedings of the 28th International Conference on Neural Information Processing Systems. San Francisco: Curran Associates, 2015, 2692–2700
Wang Z, Li X, Wang J, et al. Learning cut selection for mixed-integer linear programming via hierarchical sequence model. arXiv:2302.00244, 2023
Wesselmann F, Stuhl U. Implementing cutting plane management and selection techniques. Technical Report. Paderborn: University of Paderborn, 2012
Wolsey LA. Integer Programming. New York: John Wiley & Sons, 2020
Yilmaz K, Yorke-Smith N. Learning efficient search approximation in mixed integer branch and bound. http://www.resolvertudelftnl/uuid:bce72457-108f-4215-b7e4-599866ba52aa , 2020
Download references
Acknowledgements
This work was supported by the National Key R&D Program of China (Grant No. 2022YFB2403400) and National Natural Science Foundation of China (Grant Nos. 11991021 and 12021001).
Author information
Authors and affiliations.
Academy of Mathematics and Systems Science, Chinese Academy of Sciences, Beijing, 100190, China
Shengchao Wang, Liang Chen & Yu-Hong Dai
Research Center on Fictitious Economy and Data Science, Chinese Academy of Sciences, Beijing, 100190, China
Lingfeng Niu
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Yu-Hong Dai .
Rights and permissions
Reprints and permissions
About this article
Wang, S., Chen, L., Niu, L. et al. Enhancing cut selection through reinforcement learning. Sci. China Math. (2024). https://doi.org/10.1007/s11425-023-2294-3
Download citation
Received : 03 August 2023
Accepted : 18 April 2024
Published : 15 May 2024
DOI : https://doi.org/10.1007/s11425-023-2294-3
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- reinforcement learning
- mixed-integer linear programming
- cutting plane method
- cut selection
- Find a journal
- Publish with us
- Track your research
Stanford AI Projects Greenlighted in National AI Research Resource Pilot
Robotics and hospital computer vision projects receive NSF grants as part of an innovative pilot program to democratize AI research.

On May 6, the U.S. National Science Foundation and the Department of Energy awarded grants to 35 research teams for access to advanced computing resources through the National Artificial Intelligence Research Resource (NAIRR) pilot. This initial wave of awarded projects includes scholars from across the U.S. who are working in clinical medicine, agriculture, biochemistry, computer science, informatics, and other interdisciplinary fields. Two Stanford AI projects — from the School of Engineering and School of Medicine — were selected to participate in the pilot.
Part of the 2023 Executive Order on the Safe, Secure, and Trustworthy Development and Use of AI, the NAIRR pilot launched in January 2024 with four stated goals: spur innovation, increase diversity of talent, improve capacity, and advance trustworthy AI. Stakeholders in academia, industry, and government see this program as a critical step toward strengthening U.S. leadership in AI and democratizing AI resources for public sector innovation.
“The NAIRR pilot is a landmark initiative that supports applied AI research and will benefit the entire nation,” said Stanford Institute for Human-Centered AI Deputy Director Russell Wald . “No AI scholar should be constrained by the high cost of compute resources and access to data to train their models.”
Most of the awarded projects are given computational time on NSF-funded supercomputer systems at the University of Illinois Urbana-Champaign, University of Texas at Austin, and Pittsburgh Supercomputing Center; additionally, the DOE will allocate resources at its Summit supercomputer at Oak Ridge National Laboratory and AI Testbed at Argonne National Laboratory to a few of the research teams.
Taking Reinforcement Learning into Visual Environments
A team from the Stanford Intelligent and Interactive Autonomous Systems Group ( ILIAD ), led by HAI Faculty Affiliate Dorsa Sadigh , an assistant professor of computer science and of electrical engineering, submitted a proposal to continue groundbreaking work in the domain of human-robot and human-AI interactions. The project will focus on learning effective reward functions for robotics using large datasets and human feedback.
Reward functions are key to a machine learning technique called reinforcement learning, which works by training a large language model to maximize rewards. When humans provide feedback as part of the training process, the model learns how to make decisions that are aligned with human priorities. Stanford computer science PhD student Joey Hejna says that applying this technique to real-world robotics presents new challenges because it requires understanding the visual world, which is captured by modern visual-language models. Another challenge is that it’s not enough for the model to get the right result; how it arrives at that answer also matters. Researchers will want to make sure the robot operates safely and reliably around people, and they may need to personalize how certain robots interact with humans – in a home-care setting, for example.
“Training robot models that can work in the real world will require a massive amount of compute power," Hejna explains. “High-performing VLMs usually have at least 7 billion parameters. This project would not be possible without access to the GPU hours from the National Science Foundation.”
Autonomous Patient Monitoring in the ICU
The second Stanford project to receive NSF support comes out of the School of Medicine’s Clinical Excellence Research Center (CERC), dedicated to reducing the cost of patient care. Part of a multiyear initiative to enhance healthcare environments by integrating smart sensors and AI algorithms, the awarded project seeks to develop computer vision models that can collect and analyze comprehensive video data from ICU patient rooms to help doctors and nurses better track patients’ health.
A key aspect of the research is to address potential biases in the AI models used for predicting patient status and monitoring clinical activities. By analyzing demographic data from electronic health records, the team aims to identify and correct algorithmic biases that might affect predictions across different ethnicities and sexes. “The ultimate goal is to develop bias-free algorithms and propose interventions to ensure fair and accurate patient monitoring and care in ICUs,” said the team’s lead scholar, Dr. Kevin Schulman .
Leadership from Stanford HAI
HAI’s leadership team has been a driving force behind the creation of a National AI Research Resource since the founding of the institute in 2019. Co-Directors Fei-Fei Li and John Etchemendy started to organize universities and tech companies in 2020, and they initiated the call for a government-led task force to establish the program.
“From our earliest conversations with universities, industry executives, and policymakers, we felt that American innovation was at stake,” said Li. “We knew that support from Congress and the president could have a meaningful impact on the future of AI technology.”
According to Etchemendy, “The start of this pilot program marks a historic moment for U.S. researchers and educators. It will rebalance the AI ecosystem by supporting mission-driven researchers who want AI to serve the public good.”
Reflecting on the years of strategic planning and dedication that have led to this milestone, Wald added, “John and Fei-Fei’s vision, combined with the extraordinary support of the Stanford community and our country’s policymakers, is leading to greater access to AI research not just at Stanford but at all of America’s universities.”
Immediately following the May 6 announcement of initial awards, the NAIRR pilot opened the application window for a second wave of projects. With contributions from industry partners, a wider range of technical resources are going to be available for applicants this round, including access to advanced computing systems, cloud computing platforms, foundation models, software and privacy-enhancing tools, collaborations to train models, and education platforms.
Researchers and educators can apply for access to these resources and view descriptions of the first cohort projects on the NAIRR pilot website .
Stanford HAI’s mission is to advance AI research, education, policy and practice to improve the human condition. Learn more .
More News Topics
Time-Varying Constraint-Aware Reinforcement Learning for Energy Storage Control
Energy storage devices, such as batteries, thermal energy storages, and hydrogen systems, can help mitigate climate change by ensuring a more stable and sustainable power supply. To maximize the effectiveness of such energy storage, determining the appropriate charging and discharging amounts for each time period is crucial. Reinforcement learning is preferred over traditional optimization for the control of energy storage due to its ability to adapt to dynamic and complex environments. However, the continuous nature of charging and discharging levels in energy storage poses limitations for discrete reinforcement learning, and time-varying feasible charge-discharge range based on state of charge (SoC) variability also limits the conventional continuous reinforcement learning. In this paper, we propose a continuous reinforcement learning approach that takes into account the time-varying feasible charge-discharge range. An additional objective function was introduced for learning the feasible action range for each time period, supplementing the objectives of training the actor for policy learning and the critic for value learning. This actively promotes the utilization of energy storage by preventing them from getting stuck in suboptimal states, such as continuous full charging or discharging. This is achieved through the enforcement of the charging and discharging levels into the feasible action range. The experimental results demonstrated that the proposed method further maximized the effectiveness of energy storage by actively enhancing its utilization.
1 Introduction
Energy storage devices, such as batteries, thermal energy storages, and hydrogen systems, play a pivotal role in mitigating the impact of climate change (Aneke & Wang, 2016 ; Jacob et al., 2023 ) . These storage technologies are instrumental in capturing and efficiently storing excess energy generated from renewable sources during peak production periods, such as sunny or windy days. By doing so, they enable the strategic release of stored energy during periods of high demand or when renewable energy production is low, thereby optimizing energy distribution and reducing reliance on traditional fossil fuel-based power generation. It can be utilized in energy arbitrage by attempting to charge when surplus energy is generated and energy prices are low or even negative, and conversely, discharging during periods of energy scarcity when prices are high (Bradbury et al., 2014 ) . The integration of energy storage with arbitrage strategies contributes to grid stability, enhances overall energy reliability, and fosters a more sustainable energy ecosystem. Energy storage devices are utilized in various capacities, ranging from small-scale applications for households to large-scale units for the overall grid operation, contributing to mitigating climate change (Ku et al., 2022 ; Inage, 2019 ) .
To enhance the utility of energy storage devices, determining optimal charge and discharge levels for each time period is crucial. In recent times, reinforcement learning techniques have gained prominence over traditional optimization methods for this purpose (Cao et al., 2020 ; Jeong et al., 2023 ) . Unlike conventional optimization approaches, reinforcement learning allows for dynamic adaptation and decision-making in response to changing conditions, enabling energy storage systems to continuously learn and improve their performance over time. This shift towards reinforcement learning reflects a recognition of its ability to navigate complex and dynamic environments. It offers a more adaptive and effective solution to optimize charging and discharging strategies for energy storage devices across diverse temporal patterns. This transition in methodology underscores the importance of leveraging advanced learning algorithms to maximize the operational efficiency of energy storage systems in real-world, time-varying scenarios.
The continuous nature of energy storage device charge and discharge levels poses a challenge when employing discrete reinforcement learning techniques such as Q-learning. These algorithms operate with a predefined set of discrete actions, e.g., fully or partially charging/discharging (Cao et al., 2020 ; Rezaeimozafar et al., 2024 ) . It limits their suitability for tasks involving continuous variables, and thereby constraining the system’s ability to explore and optimize across a continuous range of charge and discharge values. Consequently, the utilization of these methods may lead to suboptimal solutions, as the algorithms cannot fully capture the intricacies of the continuous action space (Lillicrap et al., 2015 ) . Due to this limitation, continuous reinforcement learning approaches are often employed such as proximal policy optimization (PPO) (Schulman et al., 2017 ) , to better address the need for precise decision-making in the continuous spectrum of charge and discharge levels.
In continuous reinforcement learning, however, challenges also arise when determining charge and discharge levels due to the dynamic nature of the state of charge (SoC) over time. The range of feasible charge and discharge actions varies based on the evolving SoC. For example, setting actions like charging to a negative value (e.g., complete charging to − 1 1 -1 - 1 ) and discharging to a positive value (e.g., complete discharging to 1 1 1 1 ) results in a feasible action range of 0 0 to 1 1 1 1 when the battery is fully charged, and − 1 1 -1 - 1 to 0 0 when the battery is fully discharged. Nevertheless, current approaches often struggle to effectively address such time-varying action ranges. Currently, when actions fall outside the designated range, a common solution involves charging up to the maximum SoC or discharging up to the minimum SoC (Jeong & Kim, 2021 ; Kang et al., 2024 ) . However, this approach introduces a potential challenge wherein the SoC may become stuck in a fully charged or fully discharged state during the learning, limiting its ability to explore within the full spectrum of SoC states. Additionally, there are approaches that assign a cost or negative reward proportional to the extent by which actions deviate outside the designated range (Lee & Choi, 2020 ; Zhang et al., 2023 ) . However, there is a potential for overly conservative learning, as the emphasis leans heavily towards actions that remain within the designated range. Addressing these issues is crucial for adapting to the time-varying action ranges associated with the changing SoC over time.
In this paper, we propose a continuous reinforcement learning approach to address these challenges in energy storage device control. The key innovation lies in augmenting the conventional objective functions of the actor and critic with an additional supervising objective function designed to ensure that the output actions at each time step fall within the feasible action space. In contrast to traditional supervised learning, where the training encourages the output to approach specific values, the introduced supervising objective function focuses on constraining the output within a particular range. This inclusion is pivotal as bringing the output within the feasible action space enables the activation of charging and discharging operations in energy storage devices. This proactive approach helps prevent the energy storage from getting stuck in suboptimal states like complete charge or discharge, facilitating the exploration of more optimal actions. The integration of the supervising objective function enhances the adaptability and efficiency of continuous reinforcement learning in optimizing energy storage operations over changing states. We conducted experiments related to energy arbitrage and found that the addition of the supervising objective function effectively addressed the challenge of the system becoming stuck in suboptimal conditions. This objective function prevents the energy storage device from being trapped in states like complete charge or discharge and promotes continual exploration for optimal energy arbitrage.
In this section, we present a continuous reinforcement learning model combined with a supervising objective function. Modern continuous reinforcement learning comprises actor and critic components, each with distinct objective functions depending on the specific reinforcement learning algorithm employed. In this paper, we adopt the proximal policy optimization (PPO) algorithm, known for its compatibility with long short-term memory (LSTM) (Schulman et al., 2017 ) , to address energy storage device control problems. When tackling control problems associated with energy storage devices, the majority of reinforcement learning states often involve time-series data such as SoC, energy generation, energy demand, and energy prices. Given this temporal nature, combining PPO with LSTM becomes particularly advantageous. This combination facilitates effective learning and decision-making in scenarios where the state representation is composed of sequential data.

𝑡 1 o_{t+1} italic_o start_POSTSUBSCRIPT italic_t + 1 end_POSTSUBSCRIPT are given from the environment.
The actor and critic objective functions in the standard PPO formulation are expressed as follows:
where C 1 subscript 𝐶 1 C_{1} italic_C start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT and C 2 subscript 𝐶 2 C_{2} italic_C start_POSTSUBSCRIPT 2 end_POSTSUBSCRIPT are coefficients of the critic objective function and supervising objective function learning, respectively.
In this section, we evaluate the performance of the proposed method by comparing it with two benchmark cases. Case 1 employed a conventional continuous reinforcement learning approach, excluding the equation ( 3 ), meaning that the output actions were not restricted to be within the feasible action space. Case 2 incorporated the equation ( 3 ) into the reward function. This approach, proposed in (Lee & Choi, 2020 ) , adds negative rewards if the output actions fall outside the feasible action space, rather than explicitly learning the range of output actions. The proposed model is designated as Case 3. We demonstrated the effectiveness of the proposed approach through energy arbitrage experiments based on actual energy price data in 2017 U.K. wholesale market (uk2, 2017 ) . Accordingly, the additional variable x t subscript 𝑥 𝑡 x_{t} italic_x start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT becomes the energy price at time t 𝑡 t italic_t , and the reward r t subscript 𝑟 𝑡 r_{t} italic_r start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT is the total profit at time t 𝑡 t italic_t . We take the first 2000 data points which are sampled every 30 minutes and split the dataset into training set (1000 data points), validation set (500 data points), and test set (500 data points) in chronological order, where the validation set was used for early stopping. We normalize the price data between 0 and 1 by the maximum price $190.81/MWh. We simulate the proposed method using 100MWh battery with the degradation cost of $10/MWh. At time slot t = 0 𝑡 0 t=0 italic_t = 0 , we set SoC t = 0.5 subscript SoC 𝑡 0.5 \text{SoC}_{t}=0.5 SoC start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT = 0.5 , i.e., the half stored energy. We set the minimum and maximum values of the SoC to 0.1 and 0.9, respectively, in order to prevent battery degradation, and the battery charging and discharging model is based on the battery equivalent circuit used in (Cao et al., 2020 ; Jeong et al., 2023 ) . We used a 2-layer LSTM architecture with 16 neurons and trained the model using the Adam optimizer. All PPO-related parameters were adopted from values commonly used in (Schulman et al., 2017 ) .

Figure 2 illustrates the charging and discharging patterns for three cases. Case 1 shows a scenario where all the initially stored energy is discharged (sold out) and no further actions are taken. This suggests a failure in learning to manage the costs associated with charging in energy arbitrage, resulting in suboptimal behavior. Case 2 demonstrates reasonable utilization of energy arbitrage, but the proposed Case 3 engages in more active energy arbitrage. Introducing Equation ( 3 ) as a negative reward makes the agent conservative towards reaching states of complete charge or discharge, leading to reduced utilization of the energy storage. Table 1 presents the 30-minute average of charging cost, discharging revenue, degradation cost, and total profit for the three cases. It is evident that the proposed Case 3 achieves the highest profit.
4 Conclusion
In this paper, we introduce a continuous reinforcement learning approach for energy storage control that considers the dynamically changing feasible charge-discharge range. An additional objective function has been incorporated to learn the feasible action range for each time period. This helps prevent the energy storage from getting stuck in states of complete charge or discharge. Furthermore, the results indicate that supervising the output actions into the feasible action range is more effective in enhancing energy storage utilization than imposing negative rewards when the output actions deviate from the feasible action range. In future research, we will explore combining offline reinforcement learning or multi-agent reinforcement learning to investigate methods for learning a more optimized policy stably.
Acknowledgments
This work was supported by the Korea Institute of Energy Technology and Planning (KETEP) and the Ministry of Trade, Industry & Energy (MOTIE) of Korea (No. 2021202090028C).
- uk2 (2017) The changing price of wholesale UK electricity over more than a decade. https://www.ice.org.uk/knowledge-and-resources/briefing-sheet/the-changing-price-of-wholesale-uk-electricity , 2017. [Online; accessed 30-Jan-2024].
- Aneke & Wang (2016) Mathew Aneke and Meihong Wang. Energy storage technologies and real life applications–a state of the art review. Applied Energy , 179:350–377, 2016.
- Bradbury et al. (2014) Kyle Bradbury, Lincoln Pratson, and Dalia Patiño-Echeverri. Economic viability of energy storage systems based on price arbitrage potential in real-time us electricity markets. Applied Energy , 114:512–519, 2014.
- Cao et al. (2020) Jun Cao, Dan Harrold, Zhong Fan, Thomas Morstyn, David Healey, and Kang Li. Deep reinforcement learning-based energy storage arbitrage with accurate lithium-ion battery degradation model. IEEE Transactions on Smart Grid , 11(5):4513–4521, 2020.
- Inage (2019) Shin-ichi Inage. The role of large-scale energy storage under high shares of renewable energy. Advances in Energy Systems: The Large-scale Renewable Energy Integration Challenge , pp. 221–243, 2019.
- Jacob et al. (2023) Rhys Jacob, Maximilian Hoffmann, Jann Michael Weinand, Jochen Linßen, Detlef Stolten, and Michael Müller. The future role of thermal energy storage in 100% renewable electricity systems. Renewable and Sustainable Energy Transition , 4:100059, 2023.
- Jeong & Kim (2021) Jaeik Jeong and Hongseok Kim. DeepComp: Deep reinforcement learning based renewable energy error compensable forecasting. Applied Energy , 294:116970, 2021.
- Jeong et al. (2023) Jaeik Jeong, Seung Wan Kim, and Hongseok Kim. Deep reinforcement learning based real-time renewable energy bidding with battery control. IEEE Transactions on Energy Markets, Policy and Regulation , 2023.
- Kang et al. (2024) Hyuna Kang, Seunghoon Jung, Hakpyeong Kim, Jaewon Jeoung, and Taehoon Hong. Reinforcement learning-based optimal scheduling model of battery energy storage system at the building level. Renewable and Sustainable Energy Reviews , 190:114054, 2024.
- Ku et al. (2022) Tai-Yeon Ku, Wan-Ki Park, and Hoon Choi. Energy maestro–transactive energy mechanism. In 2022 IEEE International Conference on Big Data (Big Data) , pp. 6727–6729. IEEE, 2022.
- Lee & Choi (2020) Sangyoon Lee and Dae-Hyun Choi. Federated reinforcement learning for energy management of multiple smart homes with distributed energy resources. IEEE Transactions on Industrial Informatics , 18(1):488–497, 2020.
- Lillicrap et al. (2015) Timothy P Lillicrap, Jonathan J Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. arXiv preprint arXiv:1509.02971 , 2015.
- Rezaeimozafar et al. (2024) Mostafa Rezaeimozafar, Maeve Duffy, Rory FD Monaghan, and Enda Barrett. A hybrid heuristic-reinforcement learning-based real-time control model for residential behind-the-meter PV-battery systems. Applied Energy , 355:122244, 2024.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347 , 2017.
- Zhang et al. (2023) Shulei Zhang, Runda Jia, Hengxin Pan, and Yankai Cao. A safe reinforcement learning-based charging strategy for electric vehicles in residential microgrid. Applied Energy , 348:121490, 2023.
- Zimmer & Weng (2019) Matthieu Zimmer and Paul Weng. Exploiting the sign of the advantage function to learn deterministic policies in continuous domains. arXiv preprint arXiv:1906.04556 , 2019.
Microsoft Research AI for Science

AI for Science in Conversation: Chris Bishop and Frank Noé discuss setting up a team in Berlin

Watch Research Summit "Fifth Paradigm of Scientific Discovery" plenary on demand

AI for Science to empower the fifth paradigm of scientific discovery

“Over the coming decade, deep learning looks set to have a transformational impact on the natural sciences. The consequences are potentially far-reaching and could dramatically improve our ability to model and predict natural phenomena over widely varying scales of space and time. Our AI4Science team encompasses world experts in machine learning, quantum physics, computational chemistry, molecular biology, fluid dynamics, software engineering, and other disciplines, who are working together to tackle some of the most pressing challenges in this field.“ 未来十年,深度学习注定将会给自然科学带来变革性的影响。其结果具有潜在的深远意义,可能会极大地提高我们在差异巨大的空间和时间尺度上对自然现象进行建模和预测的能力。为此,微软研究院科学智能中心(AI4Science)集结了机器学习、计算物理、计算化学、分子生物学、软件工程和其他学科领域的世界级专家,共同致力于解决该领域中最紧迫的挑战。 Professor Chris Bishop , Technical Fellow, and Director, AI for Science
Work with us
Senior researcher – machine learning .
Location : Beijing, China
Technical Program Manager 2 – AI for Science
Internship opportunities: ai for science research internship – reinforcement learning & drug discovery .
Locations : Amsterdam, Netherlands; Cambridge, UK
Our locations

Amsterdam, Netherlands

Beijing, China

Berlin, Germany

Cambridge, UK

Redmond, USA

Shanghai, China
- Follow on Twitter
- Like on Facebook
- Follow on LinkedIn
- Subscribe on Youtube
- Follow on Instagram
- Subscribe to our RSS feed
Share this page:
- Share on Twitter
- Share on Facebook
- Share on LinkedIn
- Share on Reddit
IMAGES
VIDEO
COMMENTS
Reinforcement learning (RL) has proven its worth in a series of artificial domains, and is beginning to show some successes in real-world scenarios. However, much of the research advances in RL are hard to leverage in real-world systems due to a series of assumptions that are rarely satisfied in practice. In this work, we identify and formalize a series of independent challenges that embody ...
Reinforcement learning (RL), 1 one of the most popular research fields in the context of machine learning, effectively addresses various problems and challenges of artificial intelligence. It has led to a wide range of impressive progress in various domains, such as industrial manufacturing, 2 board games, 3 robot control, 4 and autonomous driving. 5 Robot has become one of the research hot ...
Reinforcement learning is a vibrant, ongoing area of research, and as such, developers have produced a myriad approaches to reinforcement learning. Nevertheless, three widely discussed and foundational reinforcement learning methods are dynamic programming, monte carlo, and temporal difference learning.
5. Discussion. Reinforcement learning's emergence as a state-of-the-art machine learning framework and concurrently, its promising ability to model several aspects of biological learning and decision making, have enabled research at the intersection of reinforcement learning, neuroscience and psychology.
A long-term, overarching goal of research into reinforcement learning (RL) is to design a single general purpose learning algorithm that can solve a wide array of problems. However, because the RL algorithm taxonomy is quite large, and designing new RL algorithms requires extensive tuning and validation, this goal is a daunting one.
Reinforcement learning (RL) is a concept that has been invaluable to fields including machine learning, neuroscience, and cognitive science. However, what RL entails differs between fields, leading to difficulties when interpreting and translating findings. ... Future research needs to determine whether similar issues arise for other model ...
Because previous research suggests an involvement of the basal ganglia in reinforcement learning 38,39,40 and the cerebellum in sensory error-based learning 24,58, reinforcement learning on motor ...
Reinforcement Learning (RL) is one of the three machine learning paradigms besides supervised learning and unsuper-vised learning. It uses agents acting as human experts in a domain to take actions. RL does not require data with labels; instead, it learns from experiences by interacting with the environment, observing, and responding to results.
Deep reinforcement learning (DRL) is the combination of reinforcement learning (RL) and deep learning. It has been able to solve a wide range of complex decision-making tasks that were previously out of reach for a machine, and famously contributed to the success of AlphaGo. Furthermore, it opens up numerous new applications in domains such as ...
practitioners interested in the broad areas of reinforcement learning (RL) and ed-ucation (ED). This article aims to provide an overview of the workshop activities and summarize the main research directions in the area of RL for ED. 1 Introduction Reinforcement learning (RL) is a computational framework for modeling and automating goal-
Nature 518 , 529-533 ( 2015) Cite this article. The theory of reinforcement learning provides a normative account 1, deeply rooted in psychological 2 and neuroscientific 3 perspectives on animal ...
This article is a gentle discussion about the field of reinforcement learning in practice, about opportunities and challenges, touching a broad range of topics, with perspectives and without technical details. The article is based on both historical and recent research papers, surveys, tutorials, talks, blogs, books, (panel) discussions, and workshops/conferences. Various groups of readers ...
The remainder of this paper is organized as follows. We introduce the related preliminaries of RL and brain neuroscience in the "Reinforcement Learning" and "Brain Neuroscience" sections, respectively. Advanced RL schemes are comprehensively described in the following 3 sections, with the "RL Algorithms Related to Micro-Neural ...
Reinforcement learning is a type of machine learning. An important feature that distinguishes it from other types of learning is that reinforcement learning uses training information to evaluate actions taken. The correct action guides the choice of action. The agent is not told what action to do and what action should not be done. Instead, it tries to discover what action can produce the ...
Reinforcement learning (RL) attempts to overcome the above mentioned performance limit by combining previous ML fields into a unifying algorithm with modifications on the learning process. Ultimately, the goal of RL is to give machines the ability to surpass all known methods. ... State-of-the-art RL research was first applied to near ...
Reinforcement learning is the study of decision making over time with consequences. The field has developed systems to make decisions in complex environments based on external, and possibly delayed, feedback. At Microsoft Research, we are working on building the reinforcement learning theory, algorithms and systems for technology that learns ...
Reinforcement learning (RL) ... Adversarial deep reinforcement learning is an active area of research in reinforcement learning focusing on vulnerabilities of learned policies. In this research area some studies initially showed that reinforcement learning policies are susceptible to imperceptible adversarial manipulations.
Reinforcement learning has gradually become one of the most active research areas in machine learning, arti cial intelligence, and neural net-work research. The eld has developed strong mathematical foundations and impressive applications. The computational study of reinforcement learning is
Reinforcement Learning-An Introduction, a book by the father of Reinforcement Learning- Richard Sutton and his doctoral advisor Andrew Barto. ... DeepMind Lab is an open source 3D game-like platform created for agent-based AI research with rich simulated environments.
The Problem of Optimal Control (Image by Pradyumna Yadav on AnalyticsVidhya)The research in to 'optimal control' began in the 1950's, and is defined as "a controller to minimize a measure of a dynamical system's behaviour over time" (Sutton & Barto 2018).Bellman built upon the work of Hamilton (1833, 1834) and Jacobi to develop a method specific for Reinforcement Learning which ...
Then, we roundly present the main reinforcement learning algorithms, including Sarsa, temporal difference, Q-learning and function approximation. Finally, we briefly introduce some applications of reinforcement learning and point out some future research directions of reinforcement learning.
[email protected]. Abstract — This paper aims to introduce, review, and. summarize several works and research papers on Reinforcement. Learning. Reinforcement learning is an area of ...
Then, this paper discusses the advanced reinforcement learning work at present, including distributed deep reinforcement learning algorithms, deep reinforcement learning methods based on fuzzy theory, Large-Scale Study of Curiosity-Driven Learning, and so on. Finally, this essay discusses the challenges faced by reinforcement learning.
Model-Based Reinforcement Learning <p>Explore a comprehensive and practical approach to reinforcement learning <p>Reinforcement learning is an essential paradigm of machine learning, wherein an intelligent agent performs actions that ensure optimal behavior from devices. While this paradigm of machine learning has gained tremendous success and popularity in recent years, previous ...
With the rapid development of artificial intelligence in recent years, applying various learning techniques to solve mixed-integer linear programming (MILP) problems has emerged as a burgeoning research domain. Apart from constructing end-to-end models directly, integrating learning approaches with some modules in the traditional methods for solving MILPs is also a promising direction. The ...
The project will focus on learning effective reward functions for robotics using large datasets and human feedback. Reward functions are key to a machine learning technique called reinforcement learning, which works by training a large language model to maximize rewards.
In model-free reinforcement learning, an agent learns a policy from scratch and completes a task via episodic interactions with the environment. This problem can be abstracted as a Markov decision process model and described by a 4-tuple S, A, P, R (Sutton and Barto Citation 1998).
In continuous reinforcement learning, however, challenges also arise when determining charge and discharge levels due to the dynamic nature of the state of charge (SoC) over time. The range of feasible charge and discharge actions varies based on the evolving SoC. ... In future research, we will explore combining offline reinforcement learning ...
AI for Science to empower the fifth paradigm of scientific discovery. "Over the coming decade, deep learning looks set to have a transformational impact on the natural sciences. The consequences are potentially far-reaching and could dramatically improve our ability to model and predict natural phenomena over widely varying scales of space ...
Reinforcement learning (RL) is a key enabler for autonomous network optimization. However, large-scale RL is challenged by a lack of software enablers and efficient architectures. In this article, we address RL for the intent-based optimization of radio access network (RAN) functions. We first introduce IBA-RP, our internal emulator that ...